Eseguire una query Apache Hive tramite il driver JDBC in HDInsight
Informazioni su come usare il driver JDBC da un'applicazione Java. Per inviare query Apache Hive ad Apache Hadoop in Azure HDInsight. Le informazioni contenute in questo documento illustrano come connettersi a livello di codice e dal SQuirreL SQL client.
Per altre informazioni sull'interfaccia Hive JDBC, vedere HiveJDBCInterface.
Prerequisiti
- Un cluster in HDInsight Hadoop. Per crearne uno, vedere Introduzione all'uso di Hadoop in HDInsight. Assicurarsi che il servizio HiveServer2 sia in esecuzione.
- Java Developer Kit (JDK) versione 11 o successiva.
- SQuirreL SQL. SQuirreL è un'applicazione client JDBC.
Stringa di connessione JDBC
Le connessioni JDBC a un cluster HDInsight in Azure vengono effettuate sulla porta 443. Il traffico è protetto tramite TLS/SSL. Il gateway pubblico dietro cui si trovano i cluster reindirizza il traffico alla porta su cui HiveServer2 è attualmente in ascolto. La stringa di connessione seguente mostra il formato da usare per HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Sostituire CLUSTERNAME con il nome del cluster HDInsight.
Nome host in stringa di connessione
Il nome host 'CLUSTERNAME.azurehdinsight.net' nella stringa di connessione corrisponde all'URL del cluster. È possibile ottenerlo tramite portale di Azure.
Porta in stringa di connessione
È possibile usare solo la porta 443 per connettersi al cluster da alcune posizioni esterne alla rete virtuale di Azure. HDInsight è un servizio gestito, ovvero tutte le connessioni al cluster vengono gestite tramite un gateway sicuro. Non è possibile connettersi direttamente a HiveServer 2 sulle porte 10001 o 10000. Queste porte non sono esposte all'esterno.
Autenticazione
Quando si stabilisce la connessione, usare il nome amministratore del cluster HDInsight e la password per l'autenticazione. Dai client JDBC, ad esempio SQuirreL SQL, immettere il nome amministratore e la password nelle impostazioni client.
Da un'applicazione Java è necessario usare il nome e la password quando viene stabilita una connessione. Ad esempio, il codice Java seguente apre una nuova connessione:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Connettersi con il client SQuirreL SQL
SQuirreL SQL è un client JDBC che può essere usato per eseguire in modalità remota query Hive con il cluster HDInsight. I passaggi seguenti presuppongono che sia già stato installato SQuirreL SQL.
Creare una directory per contenere determinati file da copiare dal cluster.
Nello script seguente sostituire
sshusercon il nome dell'account utente SSH per il cluster. SostituireCLUSTERNAMEcon il nome del cluster HDInsight. Da una riga di comando modificare la directory di lavoro con quella creata nel passaggio precedente e quindi immettere il comando seguente per copiare i file da un cluster HDInsight:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Avviare l'applicazione SQuirreL SQL. Nella parte sinistra della finestra selezionare Drivers (Driver).

Nella parte superiore della finestra di dialogo Drivers (Driver) selezionare l'icona + per creare un driver.
Nella finestra di dialogo Aggiunta driver aggiungere le informazioni seguenti:
Proprietà valore Name Hive URL di esempio jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Percorso classe aggiuntivo Usare il pulsante Aggiungi per aggiungere tutti i file jar scaricati in precedenza. Nome della classe org.apache.hive.jdbc.HiveDriver 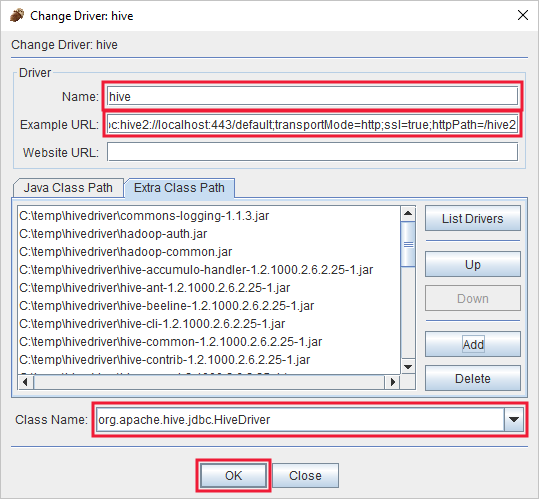
Selezionare OK per salvare queste impostazioni.
Nella parte sinistra della finestra di SQL SQuirreL selezionare Aliases (Alias). Selezionare quindi l'icona + per creare un alias di connessione.
Usare i valori seguenti per la finestra di dialogo Aggiungi alias :
Proprietà valore Name Hive in HDInsight Driver Usare l'elenco a discesa per selezionare il driver Hive . URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Sostituire CLUSTERNAME con il nome del cluster HDInsight.Nome utente nome dell'account di accesso per il cluster HDInsight. Il valore predefinito è admin. Password password per l'account di accesso del cluster. 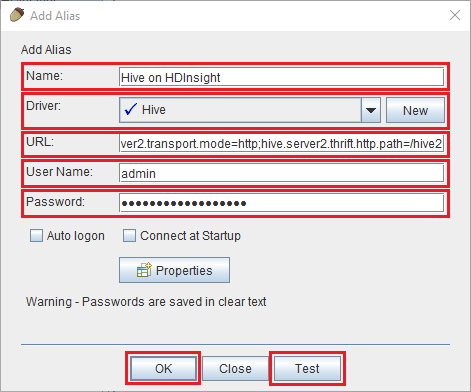
Importante
Usare il pulsante Test per verificare il funzionamento della connessione. Quando viene visualizzata la finestra di dialogo Connect to: Hive on HDInsight (Connetti a: Hive in HDInsight), selezionare Connect (Connetti) per eseguire il test. Se il test ha esito positivo, verrà visualizzata la finestra di dialogo Connection successful (Connessione riuscita). Se si verifica un errore, vedere Risoluzione dei problemi.
Usare il pulsante OK nella parte inferiore della finestra di dialogo Add Alias (Aggiungi alias) per salvare l'alias di connessione.
Nell'elenco a discesa Connect to (Connetti a) nella parte superiore di SQL SQuirreL selezionare Hive on HDInsight (Hive in HDInsight). Quando richiesto, selezionare Connetti.
Dopo la connessione, immettere la query seguente nella finestra di dialogo query SQL e quindi selezionare l'icona Esegui (una persona in esecuzione). Nell'area dei risultati dovrebbero comparire i risultati della query.
select * from hivesampletable limit 10;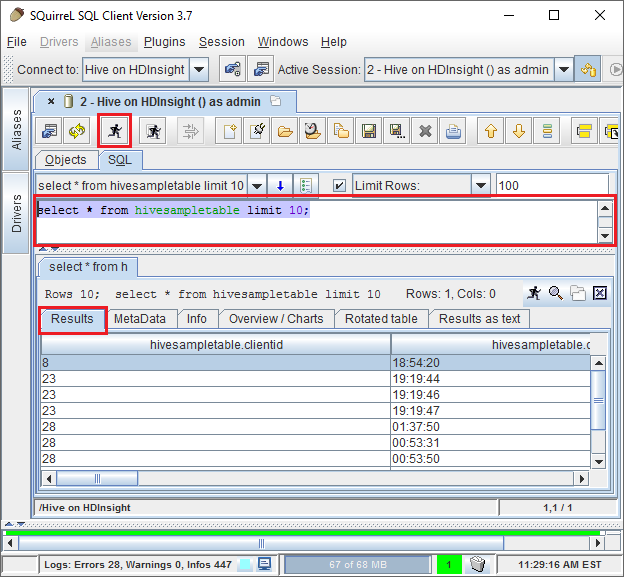
Connettersi da un'applicazione Java di esempio
Un esempio dell'uso di un client Java per query Hive in HDInsight è disponibile all'indirizzo https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Seguire le istruzioni del repository per compilare ed eseguire l'esempio.
Risoluzione dei problemi
Errore imprevisto durante il tentativo di aprire una connessione SQL
Sintomi: quando ci si connette a un cluster HDInsight versione 3.3 o superiore, un errore potrebbe segnalare che si è verificato un errore imprevisto. L'analisi dello stack dell'errore inizia con le righe seguenti:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Causa: questo errore è causato da una versione precedente del file commons-codec.jar incluso con SQuirreL.
Soluzione: per risolvere l'errore eseguire questa procedura:
Uscire da SQuirreL e quindi passare alla directory in cui SQuirreL è installato nel sistema, ad esempio
C:\Program Files\squirrel-sql-4.0.0\lib. Nella directorylibdella directory di SquirreL sostituire il file commons-codec.jar esistente con quello scaricato dal cluster HDInsight.Riavviare SQuirreL. L'errore non dovrebbe più verificarsi quando ci si connette a Hive in HDInsight.
Connessione interrotta da HDInsight
Sintomi: HDInsight disconnette in modo imprevisto la connessione quando si tenta di scaricare una grande quantità di dati (ad esempio diversi GB) tramite JDBC/ODBC.
Causa: la limitazione nei nodi del gateway causa questo errore. Quando si ottengono dati da JDBC/ODBC, tutti i dati devono passare attraverso il nodo Gateway. Tuttavia, un gateway non è progettato per scaricare una grande quantità di dati, quindi il gateway potrebbe chiudere la connessione se non riesce a gestire il traffico.
Soluzione: evitare di usare il driver JDBC/ODBC per scaricare grandi quantità di dati. Copiare i dati direttamente dall'archivio BLOB.
Passaggi successivi
Dopo aver appreso come usare JDBC per usare Hive, usare i collegamenti seguenti per esplorare altri modi per usare Azure HDInsight.
- Visualizzare i dati Apache Hive con Microsoft Power BI in Azure HDInsight.
- Visualize Interactive Query Hive data with Power BI in Azure HDInsight (Visualizzare i dati Hive di Interactive Query con Power BI in Azure HDInsight).
- Connettere Excel a HDInsight mediante Microsoft Hive ODBC Driver.
- Connettere Excel ad Apache Hadoop mediante Power Query.
- Usare Apache Hive con HDInsight
- Usare Apache Pig con HDInsight
- Usare processi MapReduce con HDInsight