Che cos'è Apache Flink® su Azure HDInsight su AKS? (Anteprima)
Importante
Azure HDInsight su AKS è stato ritirato il 31 gennaio 2025. Scopri di più con questo annuncio.
È necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare la chiusura brusca dei carichi di lavoro.
Importante
Questa funzionalità è attualmente in anteprima. Le condizioni supplementari per l'utilizzo per le anteprime di Microsoft Azure includono termini legali più validi applicabili alle funzionalità di Azure in versione beta, in anteprima o altrimenti non ancora rilasciate nella disponibilità generale. Per informazioni su questa anteprima specifica, vedere informazioni sull'anteprima di Azure HDInsight su AKS. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti su Community di Azure HDInsight.
apache Flink è un framework e un motore di elaborazione distribuito per calcoli con stato su flussi di dati non associati e delimitati. Flink è stato progettato per essere eseguito in tutti gli ambienti cluster comuni, eseguire le computazioni e le applicazioni di streaming con stato a velocità di elaborazione in memoria e su qualsiasi scala. Le applicazioni vengono parallelizzate in migliaia di attività distribuite e eseguite simultaneamente in un cluster. Pertanto, un'applicazione può usare quantità illimitate di vCPU, memoria principale, disco e I/O di rete. Inoltre, Flink mantiene facilmente lo stato dell'applicazione di grandi dimensioni. L'algoritmo di checkpointing asincrono e incrementale assicura un'influenza minima sulle latenze di elaborazione, garantendo al contempo la consistenza dello stato esattamente una volta.
Apache Flink è un motore di analisi altamente scalabile per l'elaborazione dei flussi.
Alcune delle principali funzionalità offerte da Flink sono:
- Operazioni su flussi delimitati e non associati
- Prestazioni in memoria
- Possibilità sia per i calcoli di streaming che per i calcoli batch
- Bassa latenza, operazioni ad alta velocità effettiva
- Elaborazione eseguita esattamente una volta
- Disponibilità elevata
- Stato e tolleranza di errore
- Completamente compatibile con l'ecosistema Hadoop
- Le API SQL unificate sia per il flusso che per il batch
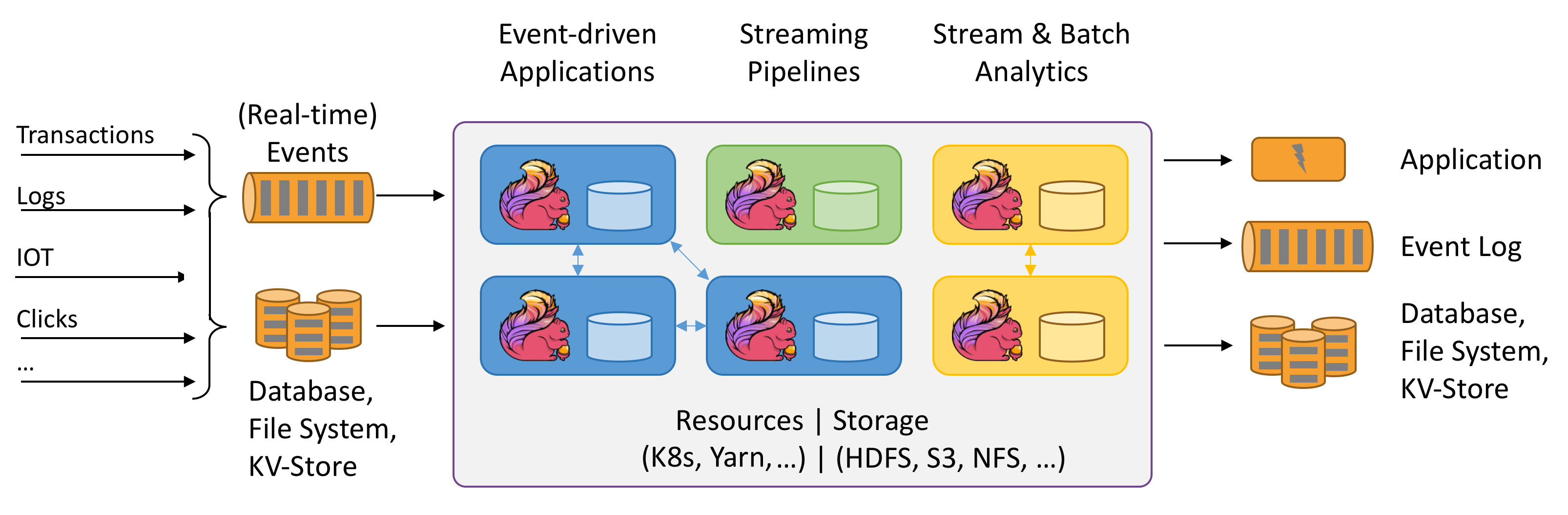
Perché Apache Flink?
Apache Flink è un'ottima scelta per sviluppare ed eseguire molti tipi diversi di applicazioni grazie al set di funzionalità completo. Le funzionalità di Flink includono il supporto per l'elaborazione di flussi e batch, la gestione sofisticata dello stato, la semantica di elaborazione basata sul tempo degli eventi e garanzie di coerenza esattamente una volta per lo stato. Flink non ha un singolo punto di errore. Flink si è dimostrato capace di scalare fino a migliaia di core e terabyte di stato dell'applicazione, offre alta capacità di elaborazione e bassa latenza, e supporta alcune delle applicazioni di elaborazione dei flussi più impegnative al mondo.
- rilevamento delle frodi: Flink può essere usato per rilevare transazioni o attività fraudolente in tempo reale applicando regole complesse e modelli di apprendimento automatico sui dati in streaming.
- Rilevamento anomalie: Flink può essere usato per identificare outlier o modelli anomali nei dati di streaming, ad esempio letture dei sensori, traffico di rete o comportamento dell'utente.
- Avvisi Basati su Regole: Flink può essere usato per generare avvisi o notifiche basati su condizioni o soglie predefinite nei flussi di dati, ad esempio temperatura, pressione o prezzi azionari.
- il monitoraggio dei processi aziendali: È possibile usare Flink per tenere traccia e analizzare lo stato e le prestazioni dei processi aziendali o dei flussi di lavoro in tempo reale, ad esempio l'evasione degli ordini, la consegna o il servizio clienti.
- Web application (social network): Flink può essere usato per alimentare applicazioni Web che richiedono l'elaborazione in tempo reale dei dati generati dagli utenti, ad esempio messaggi, mi piace, commenti o raccomandazioni.
Altre informazioni sui casi d'uso comuni descritti in casi d'uso di Apache Flink
I cluster Apache Flink di HDInsight su AKS sono un servizio completamente gestito. I vantaggi della creazione di un cluster Flink in HDInsight su AKS sono elencati qui.
| Caratteristica | Descrizione |
|---|---|
| Facilità di creazione | È possibile creare un nuovo cluster Flink in HDInsight in pochi minuti usando il portale di Azure, Azure PowerShell o l'SDK. Vedere Inizia con il cluster Apache Flink in HDInsight su Azure Kubernetes Service. |
| Facilità d'uso | I cluster Flink in HDInsight su AKS includono la gestione della configurazione tramite portale e il ridimensionamento. Oltre a questo con l'API di gestione dei processi, si usa l'API REST o il portale di Azure per la gestione dei processi. |
| API REST | I cluster Flink in HDInsight nel servizio Azure Kubernetes includono API di gestione dei processi, un metodo di invio di processi Flink basato sull'API REST per inviare e monitorare in remoto i processi nel portale di Azure. |
| Tipo di distribuzione | Flink può eseguire applicazioni in modalità sessione o in modalità applicazione. Attualmente HDInsight nel servizio Azure Kubernetes supporta solo i cluster di sessione. È possibile eseguire più processi Flink in un cluster di sessione. La modalità app è nella roadmap per HDInsight nei cluster AKS |
| Supporto per metastore | I cluster Flink in HDInsight su Azure Kubernetes Service (AKS) possono supportare cataloghi con metastore Hive in diversi formati di file aperti con posizioni di controllo remoto su Azure Data Lake Storage Gen2. |
| Supporto per Archiviazione di Azure | I cluster Flink in HDInsight possono usare Azure Data Lake Storage Gen2 come sink di file. Per altre informazioni su Data Lake Storage Gen2, vedere Azure Data Lake Storage Gen2. |
| Integrazione con i servizi di Azure | Il cluster Flink in HDInsight su AKS è integrato con Kafka insieme a Azure Event Hubs e Azure HDInsight. È possibile creare applicazioni di streaming utilizzando gli Event Hubs o HDInsight. |
| Adattabilità | HDInsight su AKS consente di ridimensionare i nodi del cluster Flink in base alla pianificazione con la funzionalità di scalabilità automatica. Vedi Ridimensionare automaticamente Azure HDInsight sui cluster AKS. |
| Gestione dello stato di back-end | HDInsight su AKS utilizza RocksDB come StateBackend predefinito. RocksDB è un archivio chiave-valore permanente incorporabile per l'archiviazione veloce. |
| Punti di controllo | Il checkpoint è abilitato in HDInsight sui cluster AKS per impostazione predefinita. Le impostazioni predefinite su HDInsight su AKS mantengono gli ultimi cinque checkpoint nell'archiviazione permanente. In caso di errore del lavoro, il lavoro può essere riavviato dal checkpoint più recente. |
| Checkpoint incrementali | RocksDB supporta checkpoint incrementali. È consigliabile usare checkpoint incrementali per stati di grandi dimensioni; è necessario abilitare questa funzionalità manualmente. L'impostazione di un valore predefinito nel flink-conf.yaml: state.backend.incremental: true abilita i checkpoint incrementali, a meno che l'applicazione non esegua l'override di questa impostazione nel codice. Questa affermazione è vera per impostazione predefinita. In alternativa, è possibile configurare questo valore direttamente nel codice (sostituisce il valore predefinito della configurazione) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); . Di default, conserviamo gli ultimi cinque checkpoint nella directory del checkpoint configurata. Questo valore può essere modificato modificando la configurazione nella sezione gestione della configurazione state.checkpoints.num-retained: 5 |
I cluster Apache Flink in HDInsight su AKS includono i seguenti componenti, disponibili nei cluster per impostazione predefinita.
- DataStreamAPI
- TableAPI & SQL.
Fare riferimento alla roadmap per vedere le novità in arrivo!
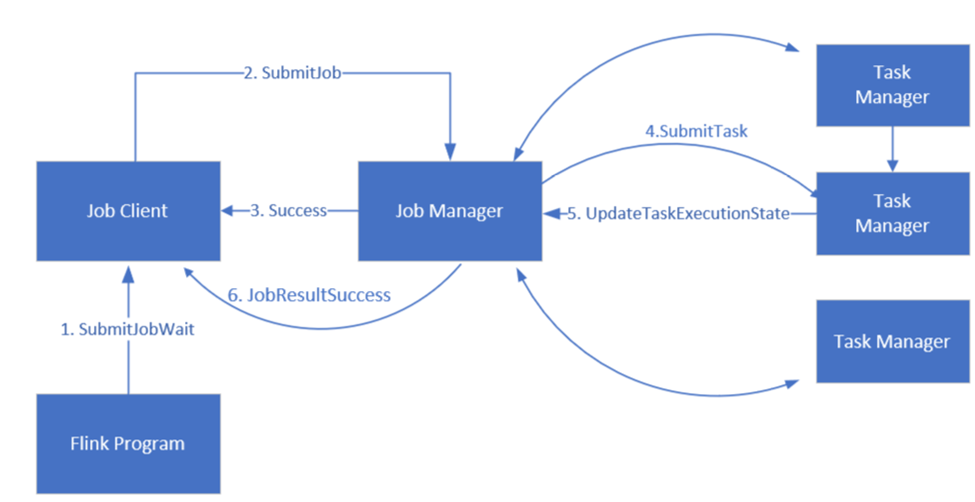
Gestione lavori Apache Flink
Flink pianifica i lavori usando tre componenti distribuiti: Job manager, Task manager e Job Client, che vengono impostati in un modello di Leader-Follower.
Job Flink: Un job o programma Flink è costituito da più attività. Le attività sono l'unità di base dell'esecuzione in Flink. Ogni attività Flink ha più istanze a seconda del livello di parallelismo e ogni istanza viene eseguita su un TaskManager.
Job manager: Il Job Manager funge da pianificatore e pianifica i compiti sui gestori delle attività.
Gestione attività: i gestori di attività sono dotati di uno o più slot per eseguire attività in parallelo.
client di lavoro: il client comunica con il gestore di lavori per sottomettere lavori Flink
L'interfaccia utente Web Flink: Flink include un'interfaccia utente Web per controllare, monitorare ed eseguire il debug delle applicazioni in esecuzione.
Riferimento
- sito Web Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi della Fondazione Apache Software (ASF).