Creare un cluster Apache Flink® in HDInsight su AKS con il portale di Azure
Nota
Azure HDInsight su AKS verrà ritirato il 31 gennaio 2025. Prima del 31 gennaio 2025, sarà necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare interruzioni improvvise dei carichi di lavoro. I cluster rimanenti nella sottoscrizione verranno arrestati e rimossi dall’host.
Solo il supporto di base sarà disponibile fino alla data di ritiro.
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le Condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti nella Community di Azure HDInsight.
Completare la procedura seguente per creare un cluster Apache Flink nel portale di Azure.
Prerequisiti
Completare i prerequisiti nelle sezioni seguenti:
Importante
- Per creare un cluster in un nuovo pool di cluster, assegnare il ruolo Operatore identità gestita del pool di agenti del servizio Azure Kubernetes nell'identità gestita assegnata dall'utente creata come parte del prerequisito della risorsa. Se si dispone delle autorizzazioni necessarie, questo passaggio viene automatizzato durante la creazione.
- L'identità gestita del pool di agenti del servizio Azure Kubernetes viene creata durante la creazione del pool di cluster. È possibile identificare l'identità gestita dell'agentpool del servizio Azure Kubernetes tramite (nome del clusterpool)-agentpool. Seguire questa procedura per assegnare il ruolo.
Creare un cluster Apache Flink
I cluster Flink possono essere creati una volta completata la distribuzione del pool di cluster, è possibile eseguire i passaggi nel caso in cui si inizi a usare un pool di cluster esistente
Nel portale di Azure digitare Pool di cluster HDInsight/HDInsight/HDInsight su AKS e selezionare Pool di cluster Azure HDInsight su AKS per aprire la pagina Pool di cluster. Nella pagina Pool di cluster HDInsight su AKS selezionare il pool di cluster in cui si vuole creare un nuovo cluster Fink.

Nella pagina del pool di cluster specifico fare clic su + Nuovo cluster e specificare le informazioni seguenti:
Proprietà Descrizione Abbonamento Questo campo viene popolato automaticamente con la sottoscrizione di Azure registrata per il pool di cluster. Gruppo di risorse Questo campo viene popolato automaticamente e mostra il gruppo di risorse nel pool di cluster. Area Questo campo viene popolato automaticamente e mostra l'area selezionata nel pool di cluster. Pool di cluster Questo campo viene popolato automaticamente e mostra il nome del pool di cluster in cui viene creato il cluster stesso. Per creare un cluster in un pool diverso, individuare il pool di cluster nel portale e fare clic su + Nuovo cluster. HDInsight nella versione pool del servizio Azure Kubernetes Questo campo viene popolato automaticamente e mostra la versione del pool di cluster in cui viene creato il cluster. HDInsight nella versione del servizio Azure Kubernetes Selezionare la versione secondaria o patch di HDInsight nel servizio Azure Kubernetes del nuovo cluster. Tipo di cluster Nell'elenco a discesa selezionare Flink. Nome cluster Immettere il nome del nuovo cluster. Identità gestita assegnata dall'utente Nell'elenco a discesa, selezionare l'identità gestita da usare con il cluster. Se si è il proprietario dell'identità del servizio gestito e quest'ultima non ha il ruolo Operatore identità gestita nel cluster, fare clic sul collegamento seguente per assegnare l'autorizzazione necessaria dall'identità del servizio gestito del pool di agenti del servizio Azure Kubernetes. Se l'identità del servizio gestito dispone già delle autorizzazioni corrette, non viene visualizzato alcun collegamento. Per altre assegnazioni di ruolo necessarie per l'identità del servizio gestito, vedere i Prerequisiti. Account di archiviazione Nell'elenco a discesa selezionare l'account di archiviazione da associare al cluster Flink e specificare il nome del contenitore. All'identità gestita viene ulteriormente concesso l'accesso all'account di archiviazione specificato usando il ruolo "Proprietario dati BLOB di archiviazione", durante la creazione del cluster. Rete virtuale Rete virtuale per il cluster. Subnet Subnet virtuale per il cluster. Abilitazione di Hive Catalog per Flink SQL.
Proprietà Descrizione Usare catalogo Hive Abilitare questa opzione per usare un metastore Hive esterno. Database SQL per Hive Nell'elenco a discesa, selezionare il database SQL in cui aggiungere tabelle hive-metastore. Nome utente amministratore SQL Immettere il nome utente dell'amministratore di SQL Server. Questo account viene usato dal metastore per comunicare con il database SQL. Key Vault Nell'elenco a discesa, selezionare l'insieme di credenziali delle chiavi, che contiene un segreto con password per il nome utente amministratore di SQL Server. È necessario configurare un criterio di accesso con tutte le autorizzazioni necessarie, ad esempio autorizzazioni chiave, autorizzazioni segrete e autorizzazioni del certificato per l'identità del servizio gestito, che viene usata per la creazione del cluster. L'identità del servizio gestito richiede un ruolo di amministratore dell'insieme di credenziali delle chiavi, aggiungere le autorizzazioni necessarie usando IAM. Nome del segreto password SQL Immettere il nome del segreto dall'insieme di credenziali delle chiavi in cui è archiviata la password del database SQL. 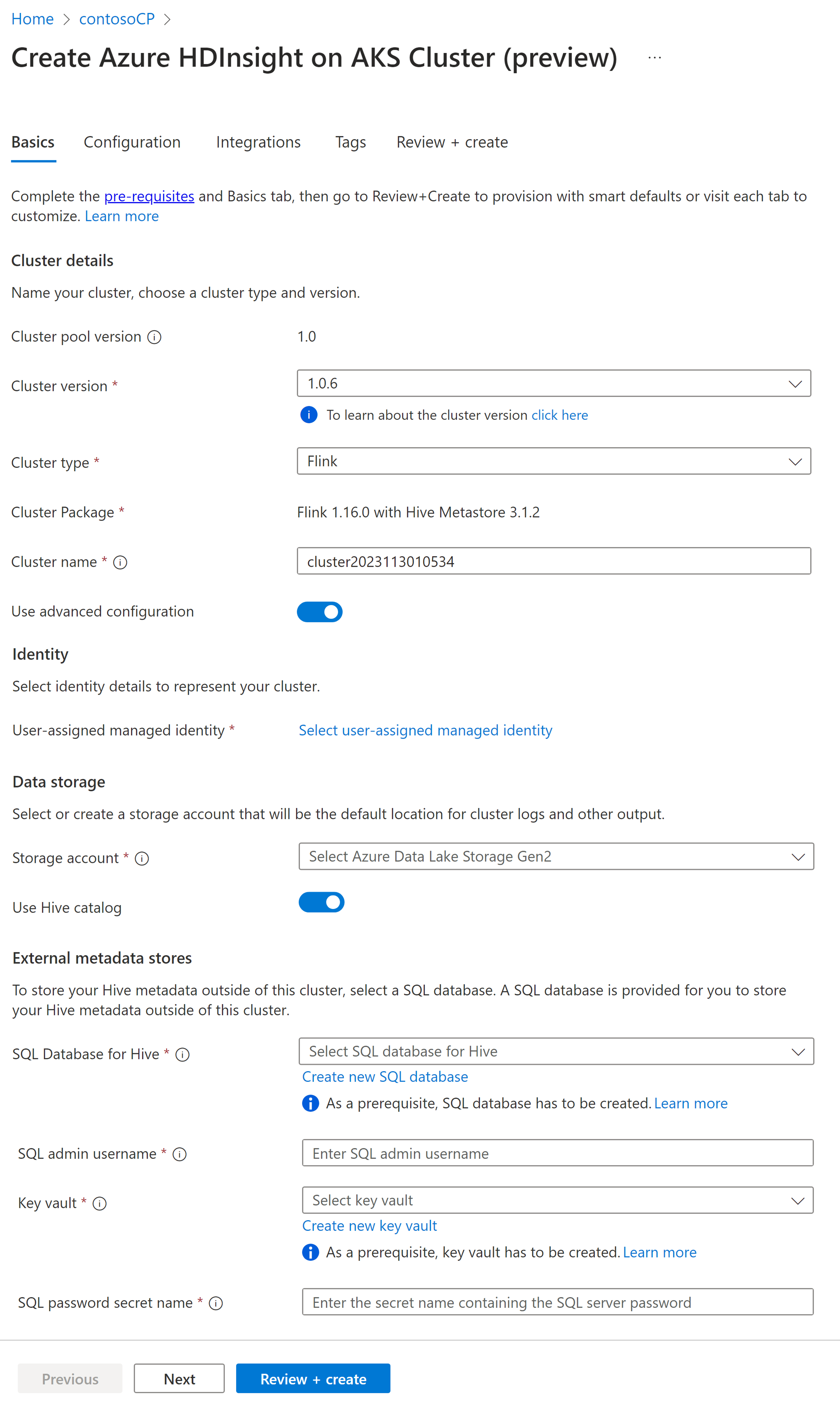
Nota
Per impostazione predefinita si usa l'account di archiviazione per il catalogo Hive come l'account di archiviazione e il contenitore usati durante la creazione del cluster.
Selezionare Avanti: Configurazione per continuare.
Nella pagina Configurazione, specificare le informazioni seguenti:
Proprietà Descrizione Dimensioni nodo Selezionare le dimensioni del nodo da usare per i nodi Flink sia per i nodi head che per i nodi di lavoro. Numero di nodi Selezionare il numero di nodi per il cluster Flink; per impostazione predefinita, i nodi head sono due. Il ridimensionamento dei nodi di lavoro consente di determinare le configurazioni di Gestione attività per Flink. Gestione processi e il server di cronologia si trovano nei nodi head. Nella sezione Configurazione del servizio specificare le informazioni seguenti:
Proprietà Descrizione CPU di Gestione attività Integer. Immettere le dimensioni delle CPU di Gestione attività (in core). Memoria in MB di Gestione attività Immettere le dimensioni della memoria di Gestione attività in MB. Minimo 1800 MB. CPU di Gestione processi Integer. Immettere il numero di CPU per Gestione processi (in core). Memoria di Gestione processi in MB Immettere le dimensioni della memoria in MB. Minimo 1800 MB. CPU del server di cronologia Integer. Immettere il numero di CPU per Gestione processi (in core). Memoria del server di cronologia in MB Immettere le dimensioni della memoria in MB. Minimo 1800 MB. 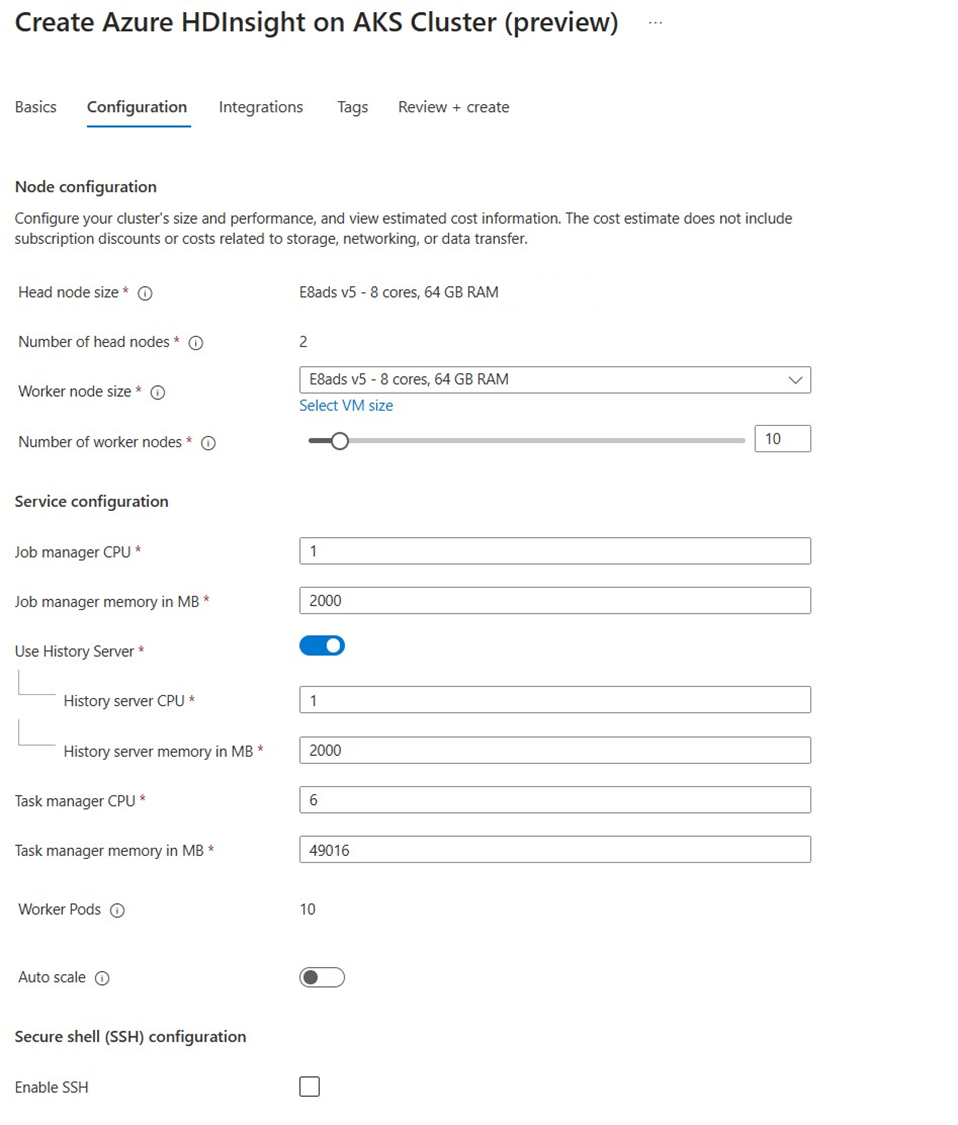
Nota
- Il server cronologico può essere abilitato/disabilitato in base alle esigenze.
- La scalabilità automatica basata su pianificazione è supportata in Flink. È possibile pianificare il numero di nodi di lavoro in base alle esigenze. Ad esempio, è abilitata una scalabilità automatica basata su pianificazione con il numero di nodi di lavoro predefinito pari a 3. E, durante i giorni feriali dalle 9.00 UTC alle 20.00 UTC, i nodi di lavoro devono essere 10. Nel corso della giornata, deve essere impostato come predefinito su 3 nodi (tra le 20.00 UTC e le 09.00 UTC del giorno successivo). Durante i fine settimana dalle 9.00 UTC alle 20.00 UTC, i nodi di lavoro sono 4.
Nella sezione Scalabilità automatica e SSH aggiornare quanto segue:
Proprietà Descrizione Scalabilità automatica Dopo la selezione, è possibile scegliere la scalabilità automatica basata sulla pianificazione per configurare la pianificazione per le operazioni di ridimensionamento. Abilitare SSH Dopo la selezione, è possibile scegliere il numero totale di nodi SSH necessari, ovvero i punti di accesso per l'interfaccia della riga di comando Flink, usando Secure Shell. Il numero massimo di nodi SSH consentiti è 5. 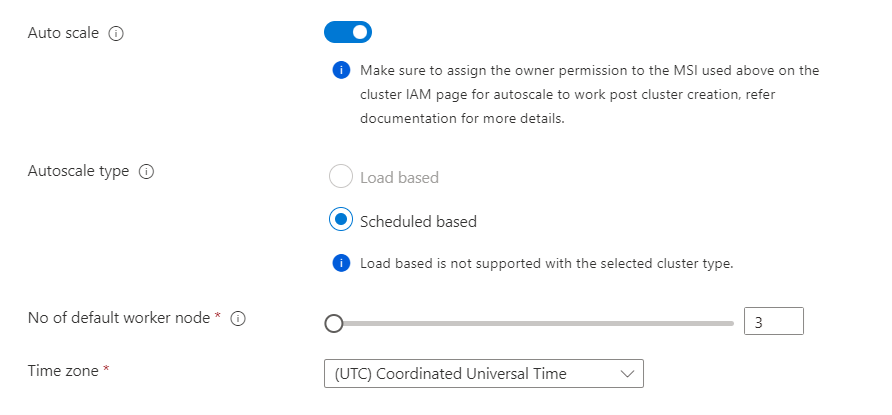

Fare clic sul pulsante Avanti: Integrazione per passare alla pagina successiva.
Nella pagina Integrazione specificare le informazioni seguenti:
Proprietà Descrizione Log Analytics Questa funzionalità è disponibile solo se il pool di cluster ha associato l'area di lavoro Log Analytics, dopo aver abilitato i log da raccogliere può essere selezionato. Azure Prometheus Questa funzionalità è utile per visualizzare le informazioni dettagliate e i log direttamente nel cluster inviando metriche e log a un'area di lavoro Monitoraggio di Azure. 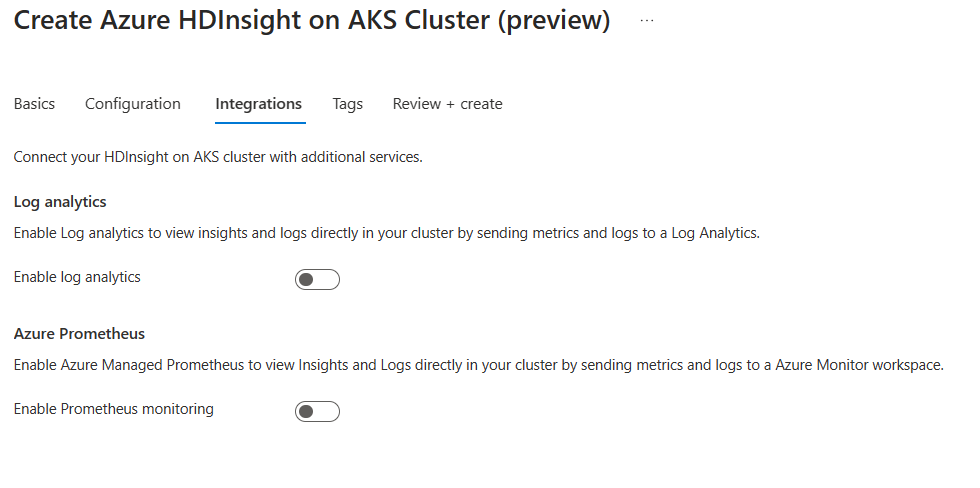
Fare clic sul pulsante Avanti: Tag per passare alla pagina successiva.
Nella pagina Tag specificare le informazioni seguenti:
Proprietà Descrizione Name Facoltativo. Immettere un nome, ad esempio HDInsight nel servizio Azure Kubernetes, per identificare facilmente tutte le risorse associate alle risorse del cluster. Valore È possibile lasciare vuoto questo campo. Conto risorse Selezionare Tutte le risorse selezionate. Selezionare Avanti: Rivedi e crea per continuare.
Nella pagina Rivedi e crea cercare il messaggio Convalida completata nella parte superiore della pagina e quindi fare clic su Crea.
Viene visualizzata la pagina Distribuzione in corso relativa alla creazione del cluster. La creazione del cluster richiede 5-10 minuti. Dopo aver creato il cluster, viene visualizzato il messaggio "La distribuzione è stata completata". Se si esce dalla pagina, è possibile controllare lo stato corrente delle notifiche.
Nota
Apache, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi di Apache Software Foundation (ASF).