Introduzione agli oggetti dell’area di lavoro
Questo articolo offre un'introduzione generale agli oggetti dell'area di lavoro di Azure Databricks. È possibile creare, visualizzare e organizzare gli oggetti dell'area di lavoro nel visualizzatore area di lavoro tra utenti singoli.
Nota sulla denominazione degli asset dell'area di lavoro
Il nome completo di un asset dell'area di lavoro è costituito dal nome di base e dalla relativa estensione del file. Ad esempio, l'estensione del file di un notebook può essere .py, .sql, .scala, .r e .ipynb a seconda della lingua e del formato del notebook.
Quando si crea un asset del notebook, il nome di base e il nome completo (il nome di base concatenato con l'estensione del file) deve essere univoco all'interno di qualsiasi cartella dell'area di lavoro. Quando si assegna un nome a un asset, Databricks verifica se soddisfa questi criteri aggiungendo l'estensione di file. Se il nome completo corrisponde a un file esistente nella cartella, tale nome non è consentito ed è necessario scegliere un nuovo nome del notebook. Ad esempio, se si tenta di creare un notebook Python (in formato di origine Python) denominato test nella stessa cartella di un file Python denominato test.py, non sarà consentito.
Cluster
I cluster Azure Databricks Data Science & Engineering e Databricks Mosaic AI offrono una piattaforma unificata per diversi casi d'uso, ad esempio l'esecuzione di pipeline ETL di produzione, analisi di streaming, analisi ad hoc e apprendimento automatico. Un cluster è un tipo di risorsa di calcolo di Azure Databricks. Altri tipi di risorse di calcolo includono Azure Databricks Warehouse SQL.
Per informazioni dettagliate sulla gestione e l'uso dei cluster, vedere Calcolo.
Notebook
Un notebook è un'interfaccia basata sul Web per i documenti contenenti una serie di celle eseguibili (comandi) che operano su file e tabelle , visualizzazionie testo narrativo. I comandi possono essere eseguiti in sequenza, facendo riferimento all'output di uno o più comandi eseguiti in precedenza.
I notebook sono un meccanismo per l'esecuzione del codice in Azure Databricks. L'altro meccanismo è costituito dai processi.
Per informazioni dettagliate sulla gestione e l'uso dei notebook, vedere Introduzione ai notebook di Databricks.
Processi
I processi sono un meccanismo per l'esecuzione del codice in Azure Databricks. L'altro meccanismo è notebook.
Per informazioni dettagliate sulla gestione e l'uso dei processi, vedere Pianificare e orchestrare i flussi di lavoro.
Librerie
Una libreria rende disponibile codice di terze parti o personalizzato per i notebook e i processi in esecuzione nei cluster.
Per informazioni dettagliate sulla gestione e l'uso delle librerie, vedere Librerie.
Dati
È possibile importare i dati in un file system distribuito montato in un'area di lavoro di Azure Databricks e lavorare con essi nei notebook e nei cluster di Azure Databricks. È inoltre possibile utilizzare un'ampia gamma di origini dati di Apache Spark per accedere ai dati.
Per informazioni generali sul caricamento dei dati, vedere Inserire dati in un lakehouse di Databricks.
File
Importante
Questa funzionalità è disponibile in anteprima pubblica.
In Databricks Runtime 11.3 LTS e versioni successive è possibile creare e usare file arbitrari nell'area di lavoro di Databricks. I file possono essere di qualsiasi tipo di file. Esempi comuni di tipi di file includono:
- File
.pyusati nei moduli personalizzati. - File
.md, ad esempioREADME.md. -
.csvo altri file di dati di piccole dimensioni. - File
.txt. - File di log.
Per informazioni dettagliate sull'uso dei file, vedere Usare i file in Azure Databricks. Per informazioni su come usare i file per modularizzare il codice durante lo sviluppo con i notebook di Databricks, vedere Condividere il codice tra notebook di Databricks
Cartelle Git
Cartella il cui contenuto viene co-versionato insieme sincronizzandolo con un repository Git remoto. Usando le cartelle Git di Databricks, è possibile sviluppare notebook in Azure Databricks e usare un repository Git remoto per la collaborazione e il controllo della versione.
Per informazioni dettagliate sull'uso dei repository, vedere Integrazione Git per le cartelle Git di Databricks.
Modelli
I modelli vengono registrati nel Registro di sistema dei modelli MLflow. Il Registro modelli è un archivio modelli centralizzato che consente di gestire il ciclo di vita completo dei modelli MLflow. Fornisce una derivazione cronologica del modello, il controllo delle versioni dei modelli, le transizioni di fase e le annotazioni e le descrizioni del modello e della versione del modello.
Per informazioni dettagliate sulla gestione e l'uso dei modelli, vedere Gestire il ciclo di vita del modello in Unity Catalog.
Sperimentazioni
Un esperimento MLflow è l'unità principale per l'organizzazione e il controllo degli accessi delle esecuzioni di addestramento dei modelli di machine learning MLflow. Tutte le esecuzioni MLflow appartengono a un esperimento. Ogni esperimento consente di visualizzare, cercare e confrontare le esecuzioni e scaricare ed eseguire artefatti o metadati per l'analisi in altri strumenti.
Per informazioni dettagliate sulla gestione e l'uso di esperimenti, vedere Organizzare le esecuzioni di training con esperimenti MLflow.
Query
Le query sono istruzioni SQL che consentono di interagire con i dati. Per altre informazioni, vedere Accesso e gestione delle query salvate.
Dashboard
I dashboard sono presentazioni di visualizzazioni di query e commenti. Vedere Dashboard o Dashboard legacy.
Avvisi
Gli avvisi sono notifiche che un campo restituito da una query ha raggiunto una soglia. Per altre informazioni, vedere Che cosa sono gli avvisi di SQL di Databricks?.
Riferimenti agli oggetti dell'area di lavoro
In passato, gli utenti erano tenuti a includere il prefisso del percorso /Workspace per alcune API di Databricks (%sh), ma non per altre (%run, input dell'API REST).
Gli utenti possono usare i percorsi dell'area di lavoro con il prefisso /Workspace ovunque. I riferimenti precedenti ai percorsi senza il prefisso /Workspace vengono reindirizzati e continuano a funzionare. È consigliabile che tutti i percorsi dell'area di lavoro siano preceduti dal prefisso /Workspace per distinguerli dai percorsi Volume e DBFS.
Il prerequisito per il comportamento del prefisso del percorso coerente /Workspace è il seguente: non è possibile creare una cartella /Workspace a livello radice dell'area di lavoro. Se si dispone di una cartella /Workspace a livello radice e si vuole abilitare questo miglioramento dell'esperienza utente, eliminare o rinominare la cartella /Workspace creata e contattare il team dell'account Azure Databricks.
Condividere un file, una cartella o un URL del notebook
Nell'area di lavoro di Azure Databricks gli URL ai file, ai notebook e alle cartelle dell'area di lavoro sono nei formati seguenti:
URL dei file dell’area di lavoro
https://<databricks-instance>/?o=<16-digit-workspace-ID>#files/<16-digit-object-ID>
URL del notebook
https://<databricks-instance>/?o=<16-digit-workspace-ID>#notebook/<16-digit-object-ID>/command/<16-digit-command-ID>
URL di cartelle (area di lavoro e Git)
https://<databricks-instance>/browse/folders/<16-digit-ID>?o=<16-digit-workspace-ID>
Questi collegamenti possono interrompersi se qualsiasi cartella, file o notebook nel percorso corrente viene aggiornato con un comando git pull oppure viene eliminato e ricreato con lo stesso nome. È tuttavia possibile creare un collegamento basato sul percorso dell'area di lavoro da condividere con altri utenti di Databricks con livelli di accesso appropriati modificandolo in un collegamento in questo formato:
https://<databricks-instance>/?o=<16-digit-workspace-ID>#workspace/<full-workspace-path-to-file-or-folder>
I collegamenti a cartelle, notebook e file possono essere condivisi sostituendo tutti gli elementi nell'URL dopo ?o=<16-digit-workspace-ID> con il percorso del file, della cartella o del notebook dalla radice dell'area di lavoro. Se si condivide un URL in una cartella, rimuovere anche /browse/folders/<16-digit-ID> dall'URL originale.
Per ottenere il percorso del file, aprire il menu di scelta rapida facendo clic con il pulsante destro del mouse sulla cartella, sul notebook o sul file nell'area di lavoro che si vuole condividere e selezionare Copia URL/percorso>percorso completo. Anteporre #workspace al percorso del file appena copiato e aggiungere la stringa risultante dopo ?o=<16-digit-workspace-ID> in modo che corrisponda al formato URL di cui sopra.
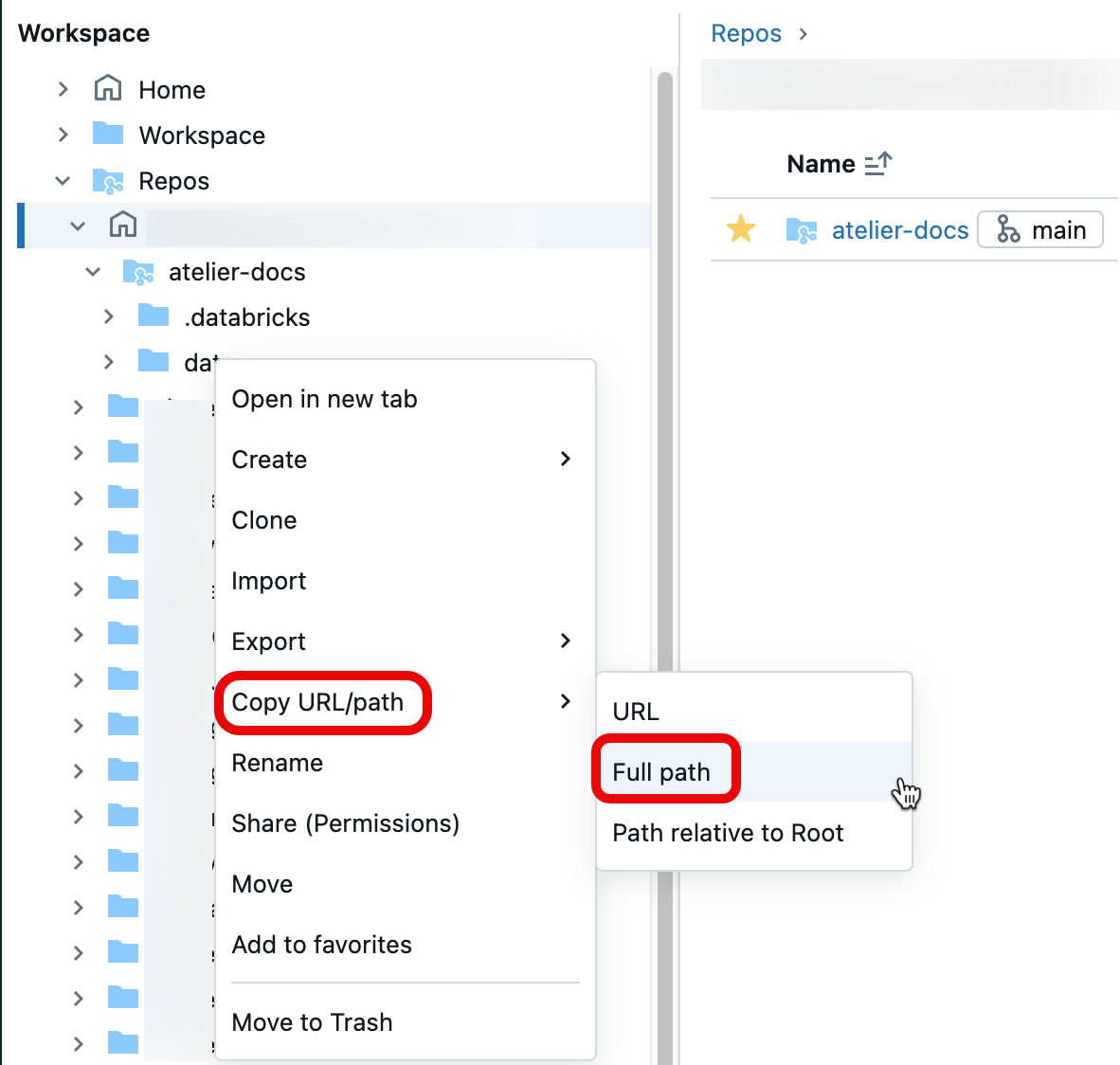
Esempio di formulazione URL n. 1: URL cartella
Per condividere l'URL della cartella dell'area di lavoro https://<databricks-instance>/browse/folders/1111111111111111?o=2222222222222222, rimuovere la sottostringa browse/folders/1111111111111111 dall'URL. Aggiungere #workspace seguito dal percorso della cartella o dell'oggetto dell'area di lavoro da condividere.
In questo caso, il percorso dell'area di lavoro si trova in una cartella, /Workspace/Users/user@example.com/team-git/notebooks. Dopo aver copiato il percorso completo dall'area di lavoro, è ora possibile costruire il collegamento condivisibile:
https://<databricks-instance>/?o=2222222222222222#workspace/Workspace/Users/user@example.com/team-git/notebooks
Esempio di formulazione URL n. 2: URL del notebook
Per condividere l'URL del notebook https://<databricks-instance>/?o=1111111111111111#notebook/2222222222222222/command/3333333333333333, rimuovere #notebook/2222222222222222/command/3333333333333333. Aggiungere #workspace seguito dal percorso della cartella o dell'oggetto dell’area di lavoro.
In questo caso, il percorso dell'area di lavoro punta a un notebook, /Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook. Dopo aver copiato il percorso completo dall'area di lavoro, è ora possibile costruire il collegamento condivisibile:
https://<databricks-instance>/?o=1111111111111111#workspace/Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook
Ora è disponibile un URL stabile per un file, una cartella o un percorso del notebook da condividere! Per altre informazioni su URL e identificatori, vedere Ottenere gli identificatori per gli oggetti dell'area di lavoro.