identificatori Get per gli oggetti dell'area di lavoro
Questo articolo illustra come get'area di lavoro, cluster, dashboard, directory, modello, notebook e URL di processo in Azure Databricks.
URL, ID e nomi di istanza dell'area di lavoro
Un nome di istanza univoco, noto anche come URL per area di lavoro, viene assegnato a ogni distribuzione di Azure Databricks. Si tratta del nome di dominio completo usato per accedere alla distribuzione di Azure Databricks ed effettuare richieste API.
Un'area di lavoro di Azure Databricks è where la piattaforma Azure Databricks viene eseguita e where è possibile creare cluster Spark e pianificare i carichi di lavoro. Un'area di lavoro ha un ID univoco dell'area di lavoro numerica.
URL per area di lavoro
Questo URL di singole aree di lavoro ha il formato seguente adb-<workspace-id>.<random-number>.azuredatabricks.net. L'ID dell'area di lavoro viene visualizzato immediatamente dopo adb- e prima del “punto” (.). Per l'URL per area di lavoro https://adb-5555555555555555.19.azuredatabricks.net/:
- Il nome dell'istanza è
adb-5555555555555555.19.azuredatabricks.net. - L’ID dell’area di lavoro è
5555555555555555.
Determinare l'URL per area di lavoro
È possibile determinare l'URL per area di lavoro:
Nel browser al momento dell'accesso:

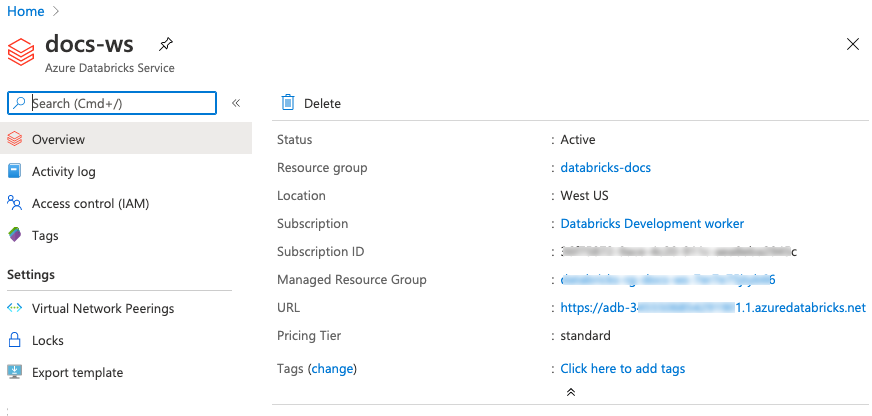
Nel portale di Azure, selezionando la risorsa e notando il valore nel campo URL:
Uso dell'API di Azure. Visualizza Get un URL per area di lavoro usando l'API di Azure.
URL di area legacy
Importante
Evitare di usare URL regionali legacy. Potrebbe non funzionare per le nuove aree di lavoro, sarà meno affidabile e offrirà prestazioni ridotte rispetto agli URL per area di lavoro.
L'URL regionale legacy è composto dalla regione where in cui viene distribuita l'area di lavoro di Azure Databricks e dal dominio azuredatabricks.net, ad esempio https://westus.azuredatabricks.net/.
- Se si accede a un URL di area legacy come
https://westus.azuredatabricks.net/, il nome dell'istanza èwestus.azuredatabricks.net. - L'ID dell'area di lavoro viene visualizzato nell'URL solo dopo aver eseguito l'accesso usando un URL di area legacy. Viene visualizzato dopo
o=. Nell'URLhttps://<databricks-instance>/?o=6280049833385130, l'ID dell'area di lavoro è6280049833385130.
ID e URL del cluster
Un cluster di Azure Databricks offre una piattaforma unificata per diversi casi d'uso, ad esempio l'esecuzione di pipeline ETL di produzione, analisi di streaming, analisi ad hoc e Machine Learning. Ogni cluster ha un ID univoco denominato ID cluster. Questo vale sia per i cluster di tutti gli scopi che per i cluster di processi. Per get i dettagli di un cluster usando l'API REST, l'ID cluster è essenziale.
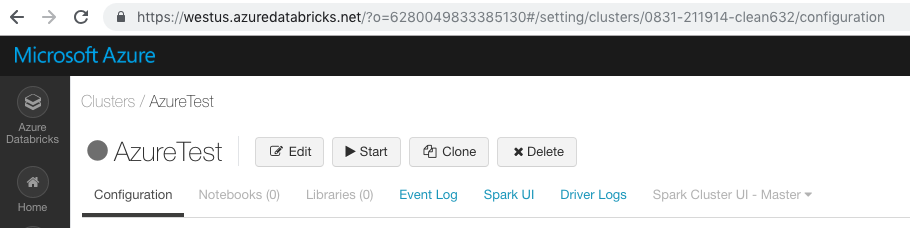
Per /clusters/ componente nell'URL di questa pagina
https://<databricks-instance>/#/setting/clusters/<cluster-id>
Nello screenshot seguente l'ID cluster è 0831-211914-clean632.
URL e ID del dashboard
Un dashboard di intelligenza artificiale/BI è una presentazione di visualizzazioni e commenti dei dati. Ogni dashboard ha un ID univoco. È possibile usare questo ID per creare collegamenti diretti che includono il filtro predefinito e il parametro valuesoppure accedere al dashboard usando l'API REST.
URL del dashboard di esempio:
https://adb-62800498333851.30.azuredatabricks.net/sql/dashboardsv3/01ef9214fcc7112984a50575bf2b460fID dashboard di esempio:
01ef9214fcc7112984a50575bf2b460f
ID e URL del notebook
Un notebook è un'interfaccia basata sul web per un documento che contiene codice eseguibile, visualizzazioni e testo descrittivo. I notebook sono un'interfaccia per interagire con Azure Databricks. Ogni notebook ha un ID univoco. L'URL del notebook ha l'ID del notebook, quindi l'URL del notebook è univoco per un notebook. Può essere condiviso con chiunque nella piattaforma Azure Databricks con l'autorizzazione per visualizzare e modificare il notebook. Inoltre, ogni comando notebook (cella) ha un URL diverso.
Per trovare un URL o un ID del notebook, aprire un notebook. Per trovare un URL di cella, fare clic sul contenuto del comando.
URL di notebook di esempio:
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342`ID di notebook di esempio:
1940481404050342.URL del comando di esempio (cella):
https://adb-62800498333851.30.azuredatabricks.net/?o=6280049833385130#notebook/1940481404050342/command/2432220274659491
ID cartella
Una cartella è una directory usata per archiviare i file che possono essere usati nell'area di lavoro di Azure Databricks. Questi file possono essere notebook, librerie o sottocartelle. È presente un ID specifico associato a ogni cartella e a ogni singola sottocartella. L'API Autorizzazioni fa riferimento a questo ID come directory_id e viene usato per impostare e aggiornare le autorizzazioni per una cartella.
Per recuperare il directory_id , usare l'API dell'area di lavoro:
curl -n -X GET -H 'Content-Type: application/json' -d '{"path": "/Users/me@example.com/MyFolder"}' \
https://<databricks-instance>/api/2.0/workspace/get-status
Di seguito è riportato un esempio della risposta di chiamata API:
{
"object_type": "DIRECTORY",
"path": "/Users/me@example.com/MyFolder",
"object_id": 123456789012345
}
Model ID
Un modello fa riferimento a un modello registrato MLflow, che consente di gestire i modelli MLflow nell'ambiente di produzione tramite transizioni di fase e controllo delle versioni. L'ID modello registrato è necessario per modificare le autorizzazioni per il modello a livello di codice tramite l’API Autorizzazioni.
Per get l'ID di un modello registrato, è possibile usare l'API dell'area di lavoro endpoint mlflow/databricks/registered-models/get. Ad esempio, il codice seguente restituisce l'oggetto modello registrato con le relative proprietà, incluso il relativo ID:
curl -n -X GET -H 'Content-Type: application/json' -d '{"name": "model_name"}' \
https://<databricks-instance>/api/2.0/mlflow/databricks/registered-models/get
Il valore restituito ha il formato:
{
"registered_model_databricks": {
"name":"model_name",
"id":"ceb0477eba94418e973f170e626f4471"
}
}
ID e URL del processo
Un processo è un modo per eseguire un notebook o un file JAR immediatamente o in base a una pianificazione.
Per get un URL di processo, fare clic sull'icona ![]() flussi di lavoro nella barra laterale e fare clic sul nome di un processo. L'ID processo è dopo il testo
flussi di lavoro nella barra laterale e fare clic sul nome di un processo. L'ID processo è dopo il testo #job/ nell'URL. L'URL del processo è necessario per risolvere la causa radice delle esecuzioni del processo non riuscite.
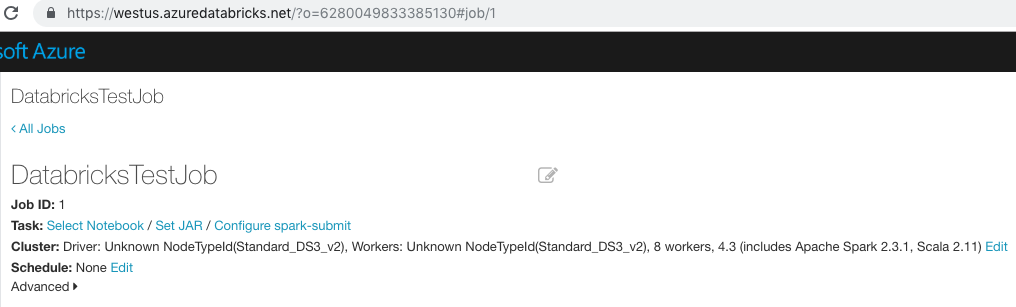
Nello screenshot seguente l'URL è:
https://westus.azuredatabricks.net/?o=6280049833385130#job/1
In questo esempio, l'ID è 1.