Tecniche CI/CD con Git e le cartelle Git di Databricks (Repository)
Informazioni sulle tecniche per l'uso delle cartelle Git di Databricks nei flussi di lavoro CI/CD. Configurando le cartelle Git di Databricks nell'area di lavoro, è possibile usare il controllo del codice sorgente per i file di progetto nei repository Git ed è possibile integrarli nelle pipeline di progettazione dei dati.
La figura seguente illustra una panoramica delle tecniche e del flusso di lavoro.
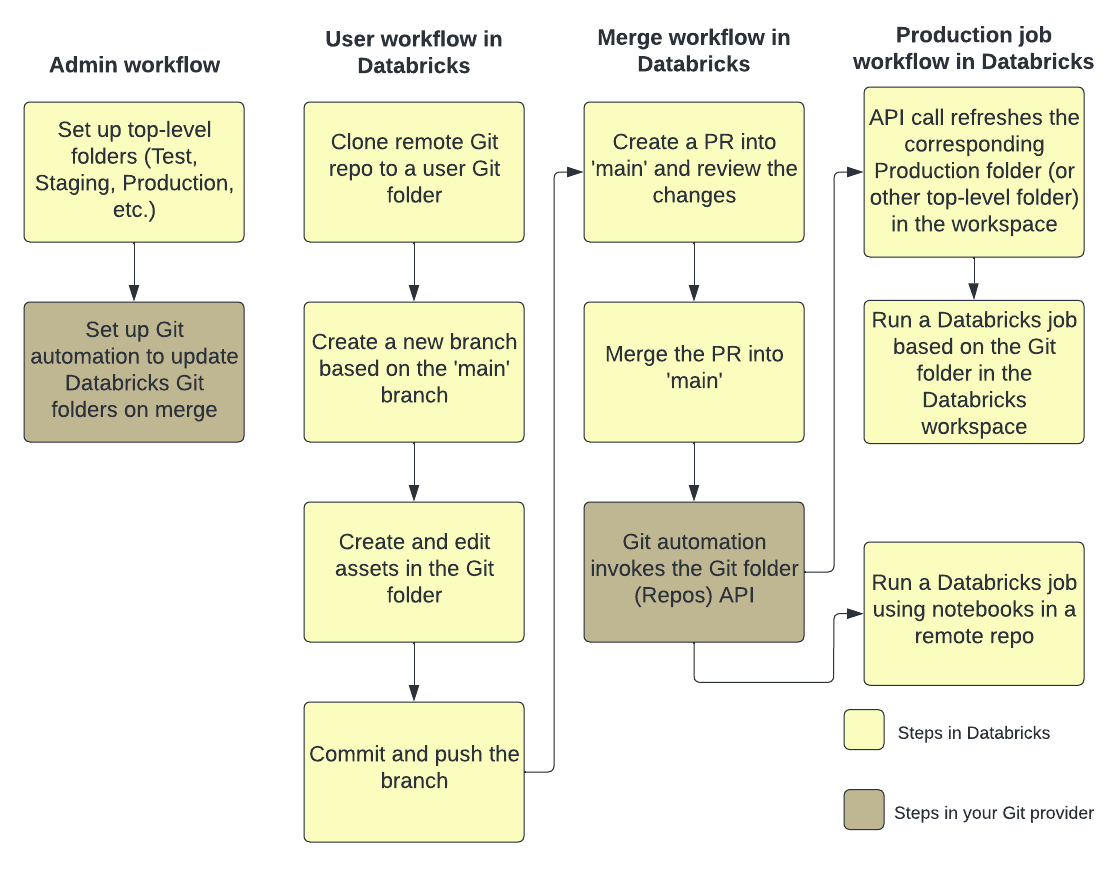
Per una panoramica di CI/CD con Azure Databricks, vedere Che cos'è CI/CD su Azure Databricks?.
Flusso di sviluppo
Le cartelle Git di Databricks hanno cartelle a livello di utente. Le cartelle a livello di utente vengono create automaticamente quando gli utenti clonano per la prima volta un repository remoto. È possibile considerare le cartelle Git di Databricks nelle cartelle utente come "checkout locali" individuali per ogni utente e dove gli utenti apportano modifiche al codice.
Nella cartella utente nelle cartelle Git di Databricks clonare il repository remoto. È una buona pratica creare un nuovo ramo delle funzionalità o selezionare un ramo creato in precedenza per il tuo lavoro, anziché effettuare direttamente il commit e il push delle modifiche nel ramo principale. È possibile apportare modifiche, eseguire il commit e il push delle modifiche in tale ramo. Quando si è pronti per unire il codice, è possibile farlo nell'interfaccia utente delle cartelle Git.
Requisiti
Questo flusso di lavoro richiede già configurare l'integrazione git.
Nota
Databricks consiglia a ogni sviluppatore di funzionare nel proprio ramo di funzionalità. Per informazioni su come risolvere i conflitti di merge, vedere Risolvere i conflitti di merge.
Collaborare in cartelle Git
Il flusso di lavoro seguente usa un ramo denominato feature-b basato sul ramo principale.
- Clonare il repository Git esistente nell'area di lavoro di Databricks.
- Usare l'interfaccia utente delle cartelle Git per creare un ramo di funzionalità dal ramo principale. In questo esempio viene usato un singolo ramo di funzionalità
feature-bper semplicità. È possibile creare e usare più rami di funzionalità per svolgere il proprio lavoro. - Apportare le modifiche ai notebook di Azure Databricks e ad altri file nel repository.
- Eseguire il commit e il push delle modifiche nel provider Git.
- I collaboratori possono ora clonare il repository Git nella propria cartella utente.
- Lavorando a un nuovo ramo, un collega apporta modifiche ai notebook e ad altri file nella cartella Git.
- Il collaboratore esegue il commit e inserisce le modifiche nel provider Git.
- Per unire le modifiche da altri rami o riassegnare il ramo feature-b in Databricks, nell'interfaccia utente delle cartelle Git usare uno dei flussi di lavoro seguenti:
-
Eseguire il merge dei rami. Se non è presente alcun conflitto, viene eseguito il push dell'unione nel repository Git remoto usando
git push. - Eseguire nuovamente il database in un altro ramo.
-
Eseguire il merge dei rami. Se non è presente alcun conflitto, viene eseguito il push dell'unione nel repository Git remoto usando
- Quando si è pronti per unire il lavoro al repository Git remoto e
mainal ramo, usare l'interfaccia utente delle cartelle Git per unire le modifiche da feature-b. Se si preferisce, è invece possibile unire le modifiche direttamente al repository Git che esegue il backup della cartella Git.
Flusso di lavoro del processo di produzione
Le cartelle Git di Databricks offrono due opzioni per l'esecuzione dei processi di produzione:
-
Opzione 1: specificare un riferimento Git remoto nella definizione del processo. Ad esempio, eseguire un notebook specifico nel
mainramo di un repository Git. - opzione 2: configurare un repository Git di produzione e chiamare API Repos per aggiornarla a livello di codice. Eseguire processi nella cartella Git di Databricks che clona questo repository remoto. La chiamata API Repos deve essere la prima attività del processo.
Opzione 1: eseguire processi usando notebook in un repository remoto
Semplificare il processo di definizione del processo e mantenere un'unica origine di verità eseguendo un processo di Azure Databricks usando i notebook che si trovano in un repository Git remoto. Questo riferimento Git può essere un commit Git, un tag o un ramo e viene fornito dall'utente nella definizione del processo.
Ciò consente di evitare modifiche involontarie al processo di produzione, ad esempio quando un utente apporta modifiche locali in un repository di produzione o cambia rami. Automatizza anche il passaggio CD perché non è necessario creare una cartella Git di produzione separata in Databricks, gestirla e mantenerla aggiornata.
Vedere Usare Git con i processi.
opzione 2: Configurare una cartella Git di produzione e l'automazione Git
In questa opzione si configura una cartella Git di produzione e l'automazione per aggiornare la cartella Git in fase di unione.
Passaggio 1: Configurare le cartelle di primo livello
L'amministratore crea cartelle di primo livello non utente. Il caso d'uso più comune per queste cartelle di primo livello consiste nel creare cartelle di sviluppo, gestione temporanea e produzione contenenti cartelle Git di Databricks per le versioni o i rami appropriati per lo sviluppo, la gestione temporanea e la produzione. Ad esempio, se la società usa il ramo main per la produzione, la cartella Git “production” deve avere il ramo main estratto.
In genere le autorizzazioni per queste cartelle di primo livello sono di sola lettura per tutti gli utenti non amministratori all'interno dell'area di lavoro. Per tali cartelle di primo livello, è consigliabile fornire solo le entità servizio con le autorizzazioni CAN EDIT e CAN MANAGE per evitare modifiche accidentali al codice di produzione da parte degli utenti dell'area di lavoro.
Passaggio 2: Configurare gli aggiornamenti automatizzati per le cartelle Git di Databricks con l'API delle cartelle Git
Per mantenere una cartella Git in Databricks alla versione più recente, è possibile configurare l'automazione Git per chiamare l'API Repos. Nel fornitore Git, configura l'automazione che, dopo ogni unione riuscita di una pull request nel ramo principale, chiama l'endpoint dell'API Repos nella cartella Git appropriata per aggiornarla all'ultima versione.
Ad esempio, in GitHub questa operazione può essere ottenuta con GitHub Actions. Per ulteriori informazioni, vedere API Repos.
Usare un'entità servizio per l'automazione con le cartelle Git di Databricks
È possibile usare la console dell'account Azure Databricks o l'interfaccia della riga di comando di Databricks per creare un'entità servizio autorizzata ad accedere alle cartelle Git dell'area di lavoro.
Per creare una nuova entità servizio, vedere Gestire le entità servizio. Quando hai un principale del servizio nell'area di lavoro, puoi collegarvi le credenziali Git in modo che possa accedere alle cartelle Git dell'area di lavoro come parte della tua automazione.
Autorizzare un principale del servizio ad accedere alle cartelle Git
Per fornire l'accesso autorizzato alle cartelle Git per un'entità di servizio tramite la console dell'account di Azure Databricks:
Accedere all'area di lavoro di Azure Databricks. Per completare questi passaggi, è necessario disporre dei privilegi di amministratore per l'area di lavoro. Nel caso in cui non si disponga dei privilegi di amministratore per l'area di lavoro, richiedili oppure contatta l'amministratore dell'account.
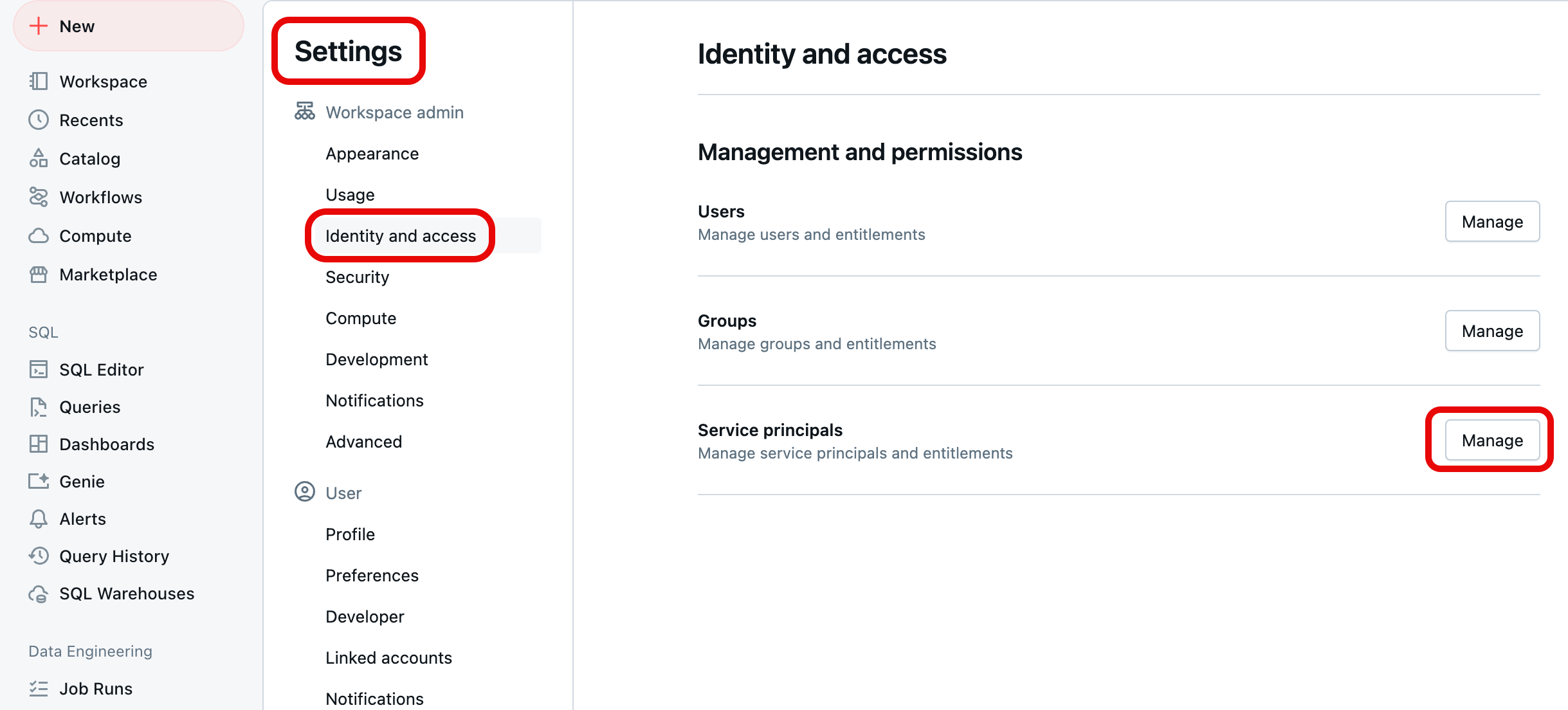
Nell'angolo superiore destro di qualsiasi pagina fare clic sul nome utente e quindi selezionare Impostazioni.
Selezionare Identity and access sotto Workspace admin nel riquadro di navigazione a sinistra, quindi selezionare il pulsante Gestisci per i Principali di Servizio.
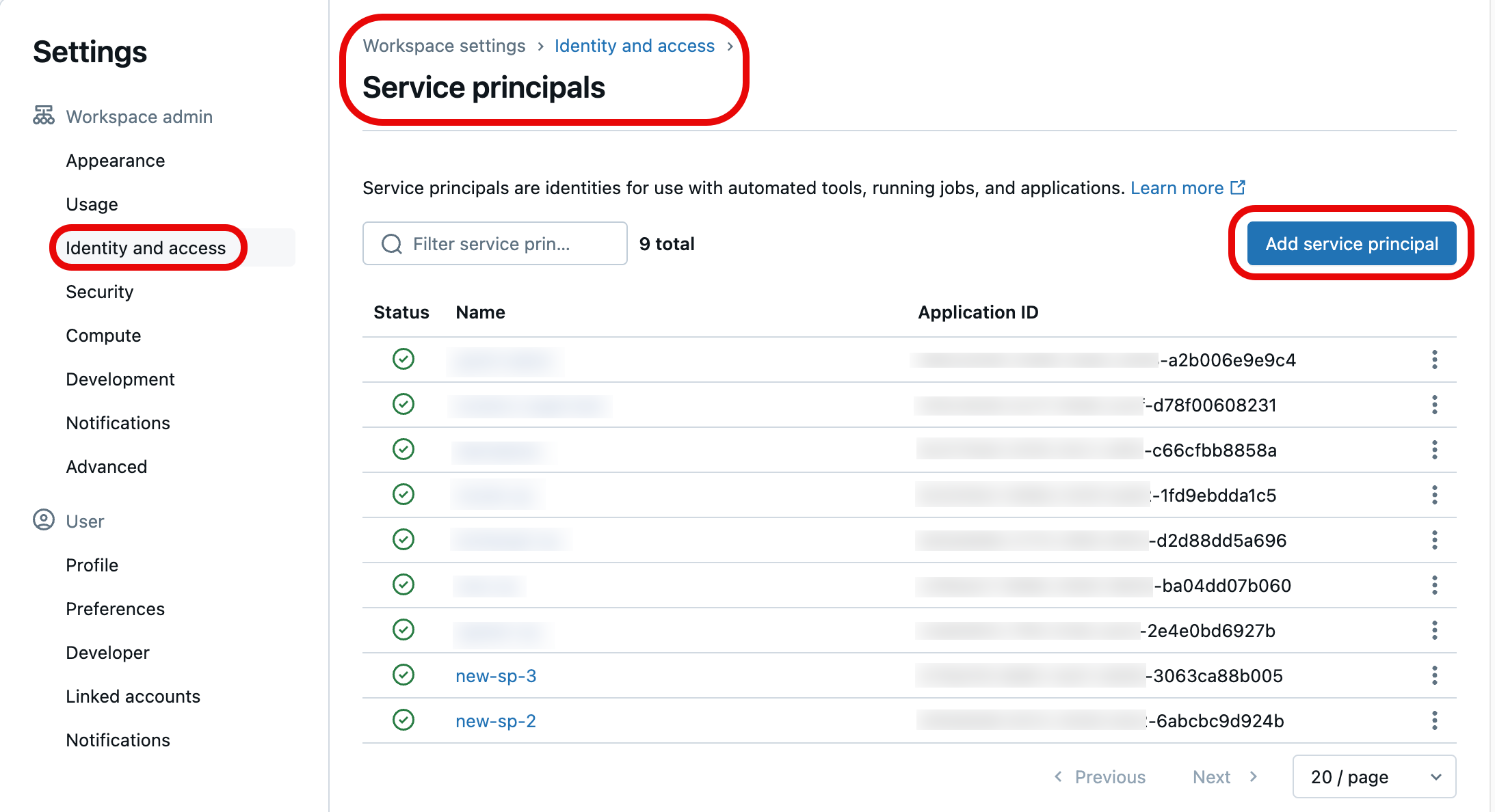
Nella lista dei principali del servizio, selezionare quello che si vuole aggiornare con le credenziali Git. È anche possibile creare una nuova entità servizio selezionando Aggiungi entità servizio.
Selezionare la scheda integrazione Git. Se non è stata creata l'entità servizio o non è stato assegnato il privilegio di gestione dell'entità servizio, sarà disattivata. Sotto, scegliere il provider Git per le credenziali (ad esempio GitHub), selezionare Collega account Gite quindi selezionare Collega.
È anche possibile usare un token di accesso personale Git se non si vogliono collegare le proprie credenziali Git. Per usare invece un token di accesso personale, selezionare token di accesso personale e fornire le informazioni sul token per l'account Git da usare durante l'autenticazione per l'accesso dell'entità servizio. Per altre informazioni sull'acquisizione di un token di accesso personale da un provider Git, vedere Configurare le credenziali Git & connettere un repository remoto ad Azure Databricks.
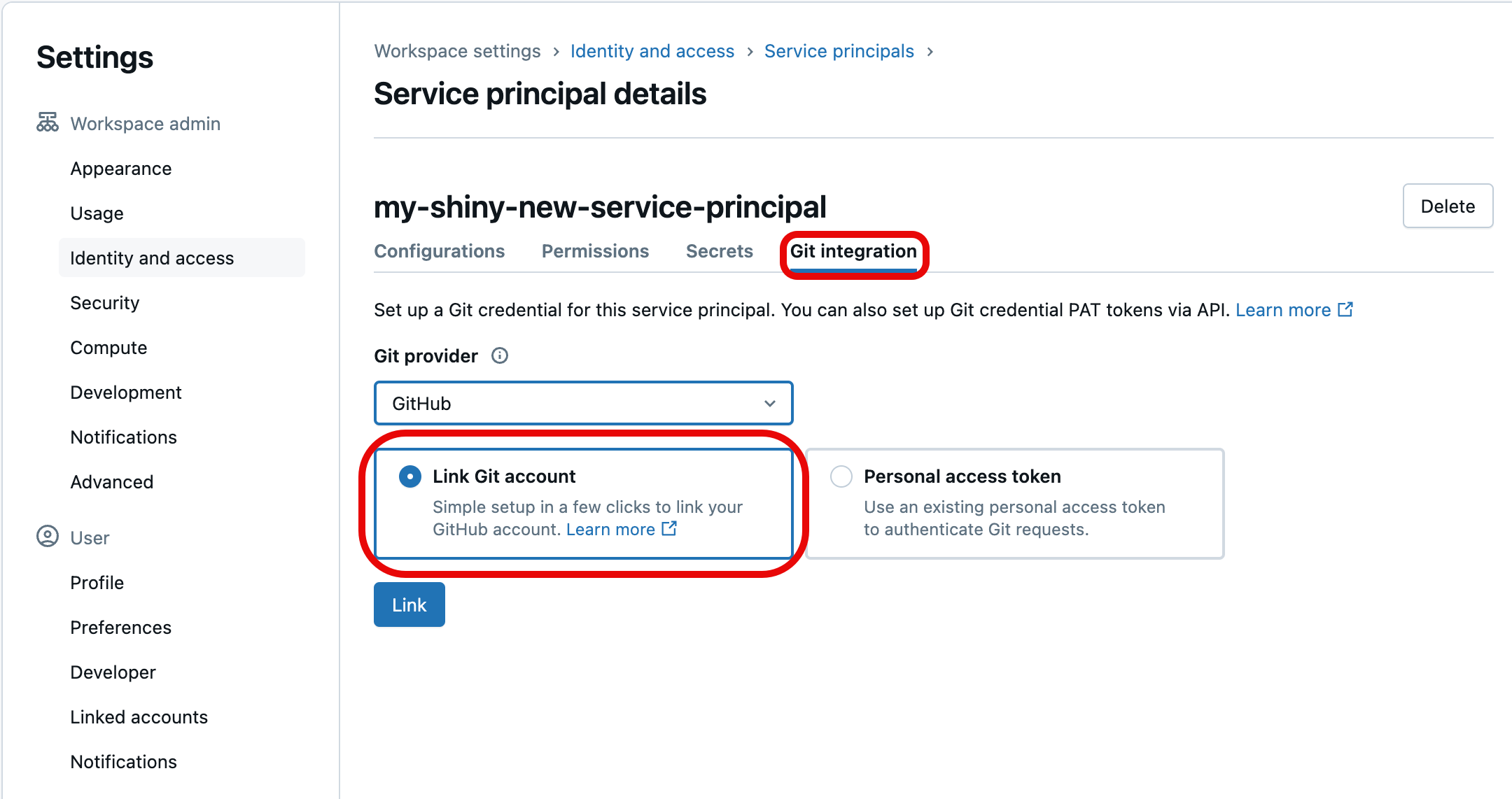
Verrà richiesto di selezionare l'account utente Git da collegare. Scegliere l'account utente Git che verrà usato dal principale del servizio per l'accesso e selezionare Continua. Se non viene visualizzato l'account utente che si vuole usare, selezionare Usa un account diverso.)
Nella finestra di dialogo successiva selezionare Autorizza Databricks. Verrà visualizzato brevemente il messaggio "Collegamento dell'account..." e quindi i dettagli dell'entità servizio aggiornati.
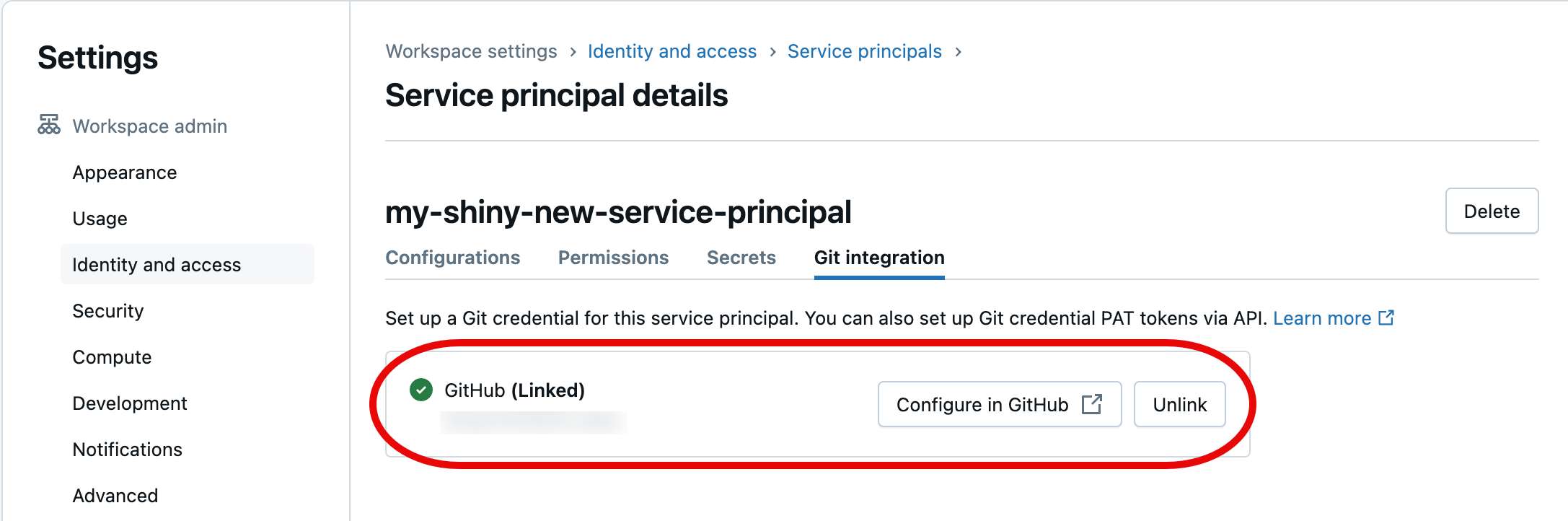
L'entità servizio scelta applicherà ora le credenziali Git collegate quando si accede alle risorse della cartella Git dell'area di lavoro di Azure Databricks come parte dell'automazione.
Integrazione di Terraform
È anche possibile gestire le cartelle Git di Databricks in una configurazione completamente automatizzata usando Terraform e databricks_repo:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Per usare Terraform per aggiungere credenziali Git a un'entità servizio, aggiungere la configurazione seguente:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Configurare una pipeline CI/CD automatizzata con le cartelle Git di Databricks
Ecco una semplice automazione che può essere eseguita come GitHub Action.
Requisiti
- È stata creata una cartella Git in un'area di lavoro di Databricks che monitora il ramo di base in cui viene eseguito il merge.
- Si dispone di un pacchetto Python che crea gli artefatti da inserire in un percorso DBFS. Il codice deve:
- Aggiorna il repository associato al tuo ramo preferito, come ad esempio
development, per contenere le versioni più recenti dei tuoi notebook. - Compilare tutti gli artefatti e copiarli nel percorso della libreria.
- Sostituire le versioni più recenti degli artefatti di compilazione per evitare di dover aggiornare manualmente le versioni degli artefatti nel tuo processo.
- Aggiorna il repository associato al tuo ramo preferito, come ad esempio
Creare un flusso di lavoro CI/CD automatizzato
Configurare segreti in modo che il codice possa accedere all'area di lavoro di Databricks. Aggiungere i segreti seguenti al repository Github:
-
DEPLOYMENT_TARGET_URL: impostare questa opzione nell'URL dell'area di lavoro. Non includere la
/?osottostringa. - DEPLOYMENT_TARGET_TOKEN: impostare questa opzione su un token di accesso personale (PAT) di Databricks. È possibile generare un token di accesso personale di Databricks seguendo le istruzioni descritte in l'autenticazione tramite token di accesso personale di Azure Databricks.
-
DEPLOYMENT_TARGET_URL: impostare questa opzione nell'URL dell'area di lavoro. Non includere la
Passare alla scheda Azioni del repository Git e fare clic sul pulsante Nuovo flusso di lavoro. Nella parte superiore della pagina selezionare Configurare manualmente un flusso di lavoro e incollare questo script:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: paths-ignore: - .github branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest environment: development env: DATABRICKS_HOST: ${{ secrets.DEPLOYMENT_TARGET_URL }} DATABRICKS_TOKEN: ${{ secrets.DEPLOYMENT_TARGET_TOKEN }} REPO_PATH: /Workspace/Users/someone@example.com/workspace-builder DBFS_LIB_PATH: dbfs:/path/to/libraries/ LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v3 - name: Setup Python uses: actions/setup-python@v3 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 # Download the Databricks CLI. See https://github.com/databricks/setup-cli - uses: databricks/setup-cli@main - name: Install mods run: | pip install pytest setuptools wheel - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks DBFS workspace location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itAggiornare i valori delle variabili di ambiente seguenti con i propri:
-
DBFS_LIB_PATH: il percorso in DBFS alle librerie (ruote) che verranno usate in questa automazione, che inizia con
dbfs:. Ad esempio,dbfs:/mnt/myproject/libraries. - REPO_PATH: il percorso nel tuo spazio di lavoro Databricks alla cartella Git dove i notebook verranno aggiornati.
-
LATEST_WHEEL_NAME: nome del file wheel Python compilato (
.whl). Viene usato per evitare di aggiornare manualmente le versioni delle ruote nei processi di Databricks. Ad esempio:your_wheel-latest-py3-none-any.whl.
-
DBFS_LIB_PATH: il percorso in DBFS alle librerie (ruote) che verranno usate in questa automazione, che inizia con
Selezionare Eseguire il commit delle modifiche... per eseguire il commit dello script come flusso di lavoro di GitHub Actions. Dopo aver unito la richiesta pull per questo flusso di lavoro, passare alla scheda Azioni del repository Git e confermare che le azioni siano riuscite.