Eseguire operazioni Git nelle cartelle Git di Databricks (Repository)
L'articolo descrive come eseguire operazioni Git comuni nell'area di lavoro di Databricks usando cartelle Git, tra cui clonazione, diramazione, commit e push.
Clonare un repository connesso a un repository Git remoto
Nella barra laterale, selezionare Workspace e quindi navigare alla cartella in cui si desidera creare il clone del repository Git.
Fare clic sulla freccia verso il basso a destra della Aggiungi in alto a destra dell'area di lavoro e selezionare cartella Git dall'elenco a discesa.
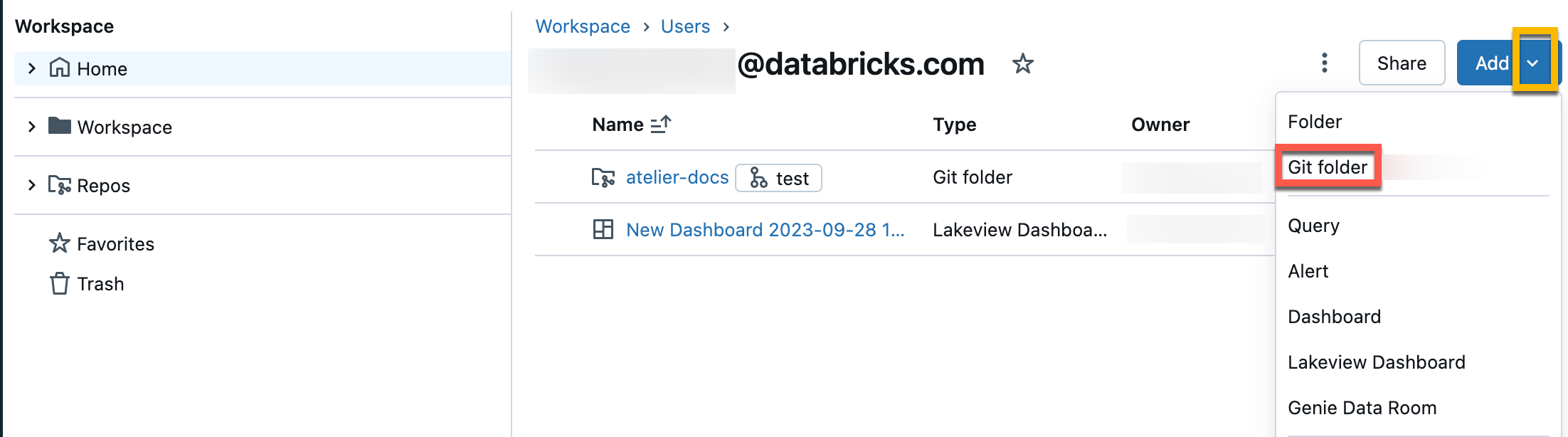
Nella finestra di dialogo Crea cartella Git specificare le informazioni seguenti:
- URL del repository Git da clonare nel formato
https://example.com/organization/project.git - Provider Git per il repository da clonare. Le opzioni includono GitHub, GitHub Enterprise, GitLab e Azure DevOps (Azure Repos)
- Nome della cartella nell'area di lavoro che conterrà il contenuto del repository clonato
- Che tu utilizzi o meno il checkout sparse , in cui viene clonato solo un sottoinsieme delle directory del repository, specificato utilizzando un modello a cono. Ciò è utile se il tuo repository è più grande dei limiti supportati da Databricks .
- URL del repository Git da clonare nel formato
Cliccare Crea cartella Git. Il contenuto del repository remoto viene clonato nel repository Databricks ed è possibile iniziare a usarli usando le operazioni Git supportate tramite l'area di lavoro.
Procedura consigliata: Collaborazione in cartelle Git
Le cartelle Git di Databricks si comportano in modo efficace come client Git incorporati nell'area di lavoro in modo che gli utenti possano collaborare usando il controllo del codice sorgente basato su Git e il controllo delle versioni. Per rendere più efficace la collaborazione del team, usare una cartella Git di Databricks separata mappata a un repository Git remoto per ogni utente che lavora nel proprio ramo di sviluppo. Anche se più utenti possono contribuire al contenuto in una cartella Git, solo un utente designato deve eseguire operazioni Git, ad esempio pull, push, commit e cambio di ramo. Se più utenti eseguono operazioni Git in una cartella Git, la gestione dei rami può diventare difficile e soggetta a errori, ad esempio quando un utente cambia un ramo e lo cambia involontariamente per tutti gli altri utenti di tale cartella.
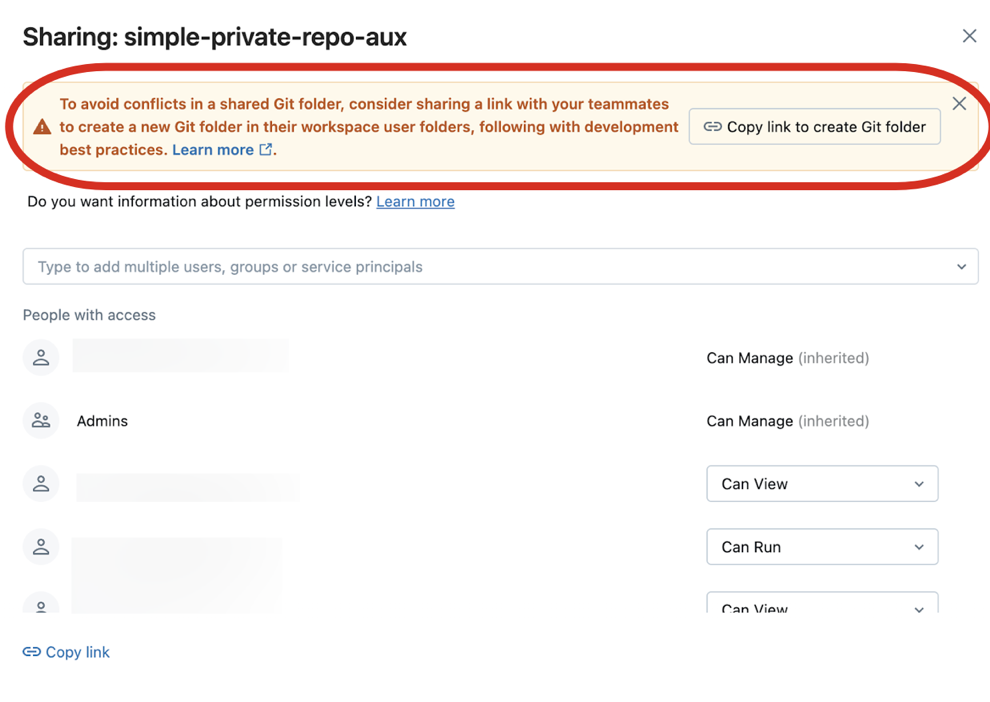
Per condividere una cartella Git con un collaboratore, fare clic su Copia collegamento per creare una cartella Git nel banner nella parte superiore dell'area di lavoro di Databricks. Questa azione copia un URL negli Appunti locali che è possibile inviare a un altro utente. Quando l'utente destinatario carica l'URL in un browser, verrà portato all'area di lavoro in cui può creare la propria cartella Git clonata dallo stesso repository Git remoto. Verrà visualizzata una finestra di dialogo modale Crea cartella Git nell'interfaccia utente, prepopolata con i valori ricavati dalla tua cartella Git. Quando fanno clic sul pulsante blu Crea cartella Git nel modale, il repository Git viene clonato nell'area di lavoro sotto la cartella di lavoro corrente, dove ora possono usarla direttamente.
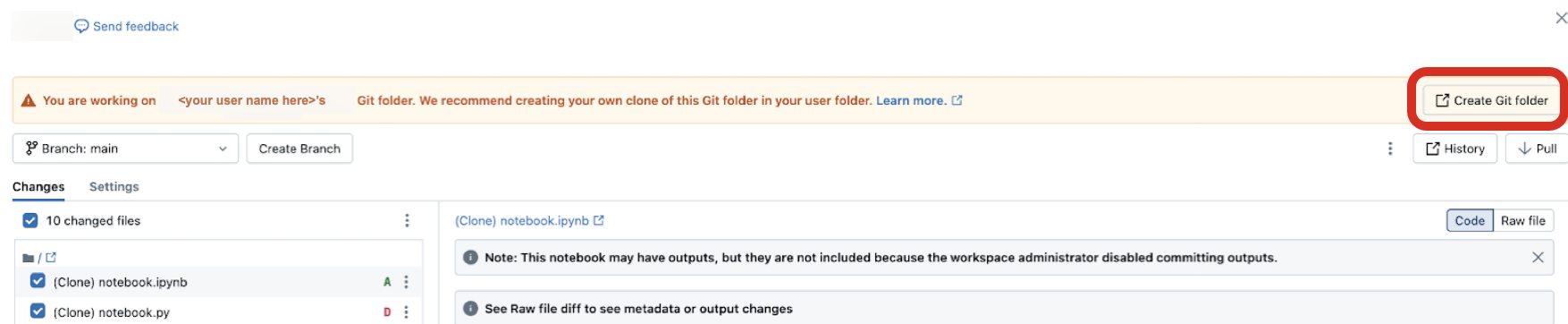
Quando si accede alla cartella Git di un altro utente in un'area di lavoro condivisa, fare clic su Crea cartella Git nel banner nella parte superiore. Questa azione apre la finestra di dialogo Crea cartella Git, prepopolato con la configurazione per il repository Git che lo esegue di nuovo.
Importante
Attualmente non è possibile usare l'interfaccia della riga di comando di Git per eseguire operazioni Git in una cartella Git. Se si clona un repository Git usando l'interfaccia della riga di comando tramite il terminale Web di un cluster, i file non verranno visualizzati nell'interfaccia utente di Azure Databricks.
Accedere alla finestra di dialogo Git
È possibile accedere alla finestra di dialogo Git da un notebook o dal browser delle cartelle Git di Databricks.
Da un notebook fare clic sul pulsante accanto al nome del notebook che identifica il ramo Git corrente.

Dal browser delle cartelle Git di Databricks fare clic sul pulsante a destra del nome del repository. È anche possibile fare clic con il pulsante destro del mouse sul nome del repository e scegliere Git... dal menu.
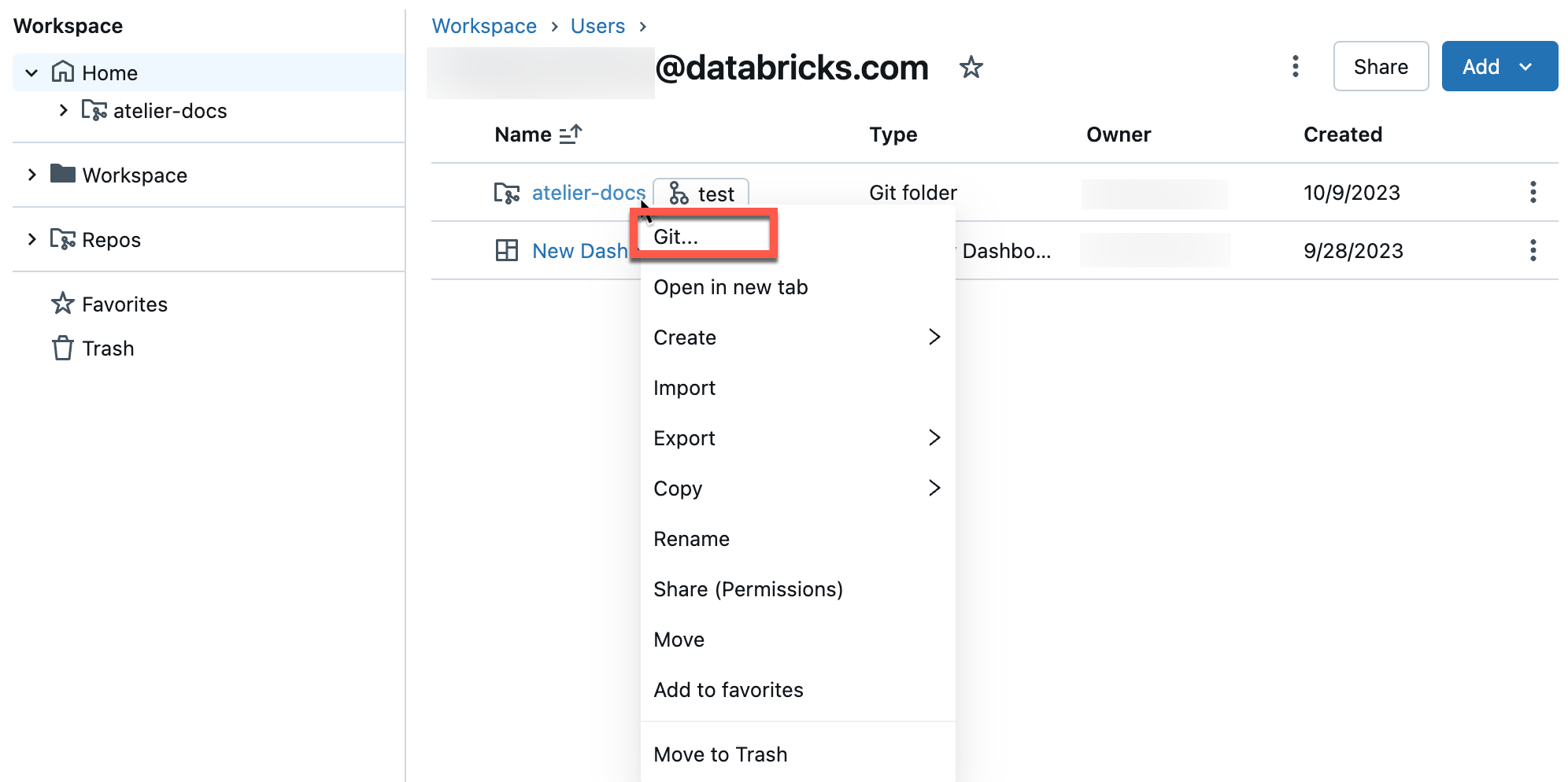
Verrà visualizzata una finestra di dialogo a schermo intero in cui è possibile eseguire operazioni Git.

- Ramo di lavoro corrente. Qui è possibile selezionare altri rami. Se altri utenti hanno accesso a questa cartella Git, la modifica del ramo modificherà anche il ramo se condividono la stessa area di lavoro. Vedere una procedura consigliata per evitare questo problema.
- Pulsante per creare un nuovo ramo.
- L'elenco delle risorse di file e delle sottocartelle registrate nel tuo ramo attuale.
- Pulsante che consente di accedere al provider Git e di visualizzare la cronologia current branch.
- Pulsante per eseguire il pull del contenuto dal repository Git remoto.
- Casella di testo in cui si aggiunge un messaggio di commit e una descrizione espansa facoltativa per le modifiche.
- Pulsante per eseguire il commit del lavoro nel ramo di lavoro ed eseguire il push del ramo aggiornato nel repository Git remoto.
Fare clic sul menu kebab ![]() nell'angolo in alto a destra per scegliere tra ulteriori operazioni di branch Git, come un hard reset, un merge o un rebase.
nell'angolo in alto a destra per scegliere tra ulteriori operazioni di branch Git, come un hard reset, un merge o un rebase.

Questa è la home page per l'esecuzione di operazioni Git nella cartella Git dell'area di lavoro. Le operazioni Git presentate nell'interfaccia utente sono limitate.
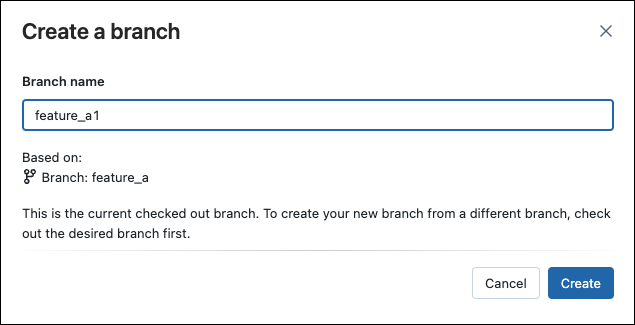
Creare un nuovo ramo
È possibile creare un nuovo ramo basato su un ramo esistente dalla finestra di dialogo Git:
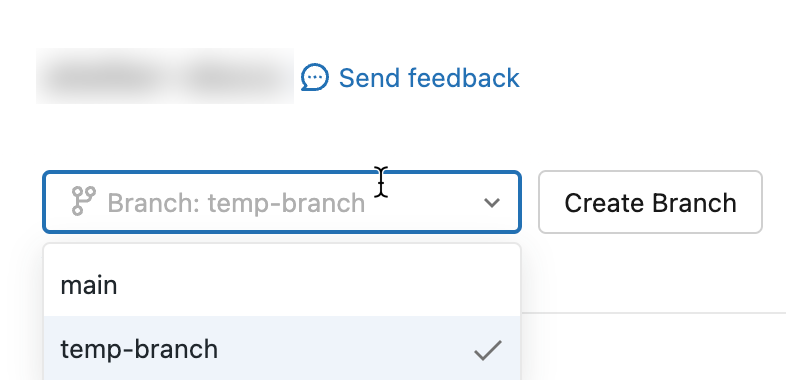
Passare a un ramo diverso
È possibile passare a (checkout) a un ramo diverso usando l'elenco a discesa ramo nella finestra di dialogo Git:
Importante
Dopo aver eseguito il checkout di un ramo in una cartella Git, è sempre possibile che il ramo venga eliminato nel repository Git remoto da un altro utente. Se un ramo viene eliminato nel repository remoto, la versione locale può rimanere presente nella cartella Git associata per un massimo di 7 giorni. I rami locali in Databricks non possono essere eliminati, quindi se è necessario rimuoverli, è necessario eliminare e rilone il repository.
Eseguire il commit e il push delle modifiche nel repository Git remoto
Quando sono stati aggiunti nuovi notebook o file o sono state apportate modifiche a notebook o file esistenti, l'interfaccia utente della cartella Git evidenzia le modifiche.

Aggiungere un messaggio di commit necessario per le modifiche e fare clic su Commit & Push per eseguire il push di queste modifiche nel repository Git remoto.
Se non si dispone dell'autorizzazione per eseguire il commit nel ramo predefinito (ad esempio il main ramo), creare un nuovo ramo e usare l'interfaccia del provider Git per creare una richiesta pull (PR) per unirla nel ramo predefinito.
Nota
- Gli output dei notebook non sono inclusi nei commit per impostazione predefinita quando i notebook vengono salvati nei formati di file di origine (
.py,.scala,.sql,.r). Per informazioni sul commit degli output dei notebook con il formato IPYNB, vedere Controllare i commit degli artefatti di output del notebook IPYNB
Eseguire il pull delle modifiche dal repository Git remoto
Per eseguire il pull delle modifiche dal repository Git remoto, fare clic su Pull nella finestra di dialogo Operazioni Git. I notebook e gli altri file vengono aggiornati automaticamente alla versione più recente nel repository Git remoto. Se le modifiche estratte dal repository remoto sono in conflitto con le modifiche locali in Databricks, è necessario risolvere i conflitti di merge.
Importante
Le operazioni Git che estraggono upstream cancellano lo stato del notebook. Per altre informazioni, vedere Modifiche in ingresso cancellano lo stato del notebook.
Eseguire il merge dei rami
Accedere all'operazione Git Merge selezionandola dal ![]() kebab in alto a destra nella finestra di dialogo Operazioni Git.
kebab in alto a destra nella finestra di dialogo Operazioni Git.
La funzione di merge nelle cartelle Git di Databricks unisce un ramo a un altro usando git merge. Un'operazione di merge è un modo per combinare la cronologia dei commit da un ramo a un altro ramo; l'unica differenza è la strategia usata per ottenere questo risultato. Per i principianti di Git, è consigliabile usare merge (over rebase) perché non richiede il push forzato in un ramo e pertanto non riscrive la cronologia dei commit.
- Se si verifica un conflitto di merge, risolverlo nell'interfaccia utente delle cartelle Git.
- Se non è presente alcun conflitto, viene eseguito il push dell'unione nel repository Git remoto usando
git push.
Rebase un ramo in un altro ramo
Accedere all'operazione Git Rebase selezionandola dal ![]() menu kebab in alto a destra nella finestra di dialogo Operazioni Git.
menu kebab in alto a destra nella finestra di dialogo Operazioni Git.
La ribasatura modifica la cronologia dei commit di un ramo. Analogamente git mergea , git rebase integra le modifiche da un ramo a un altro. Rebase esegue le operazioni seguenti:
- Salva i commit nel ramo corrente in un'area temporanea.
- Reimposta il ramo corrente sul ramo scelto.
- Riapplica ogni singolo commit salvato in precedenza nel ramo corrente, generando una cronologia lineare che combina le modifiche di entrambi i rami.
Avviso
L'uso della rebase può causare problemi di controllo delle versioni per i collaboratori che lavorano nello stesso repository.
Un flusso di lavoro comune consiste nel ribase di un ramo di funzionalità nel ramo principale.
Per ribasere un ramo in un altro ramo:
Dal menu ramo nell'interfaccia utente delle cartelle Git, selezionare il ramo da ribasare.
Selezionare Rebase dal menu kebab.

Seleziona il ramo su cui vuoi fare il rebase.
L'operazione di ribase integra le modifiche dal ramo scelto qui nel ramo current branch.
Le esecuzioni git commit e git push --force delle cartelle Git di Databricks vengono effettuate per aggiornare il repository Git remoto.
Risolvere i conflitti di unione
I conflitti di merge si verificano quando 2 o più utenti Git tentano di unire le modifiche alle stesse righe di un file in un ramo comune e Git non può scegliere le modifiche "giuste" da applicare. I conflitti di merge possono verificarsi anche quando un utente tenta di eseguire il pull o l'unione di modifiche da un altro ramo in un ramo con modifiche di cui non è stato eseguito il commit.
Se un'operazione come pull, rebase o merge causa un conflitto di merge, l'interfaccia utente delle cartelle Git mostra un elenco di file con conflitti e opzioni per la risoluzione dei conflitti.
Sono disponibili due opzioni principali:
- Usare l'interfaccia utente delle cartelle Git per risolvere il conflitto.
- Interrompere l'operazione Git, rimuovere manualmente le modifiche nel file in conflitto e ritentare l'operazione Git.
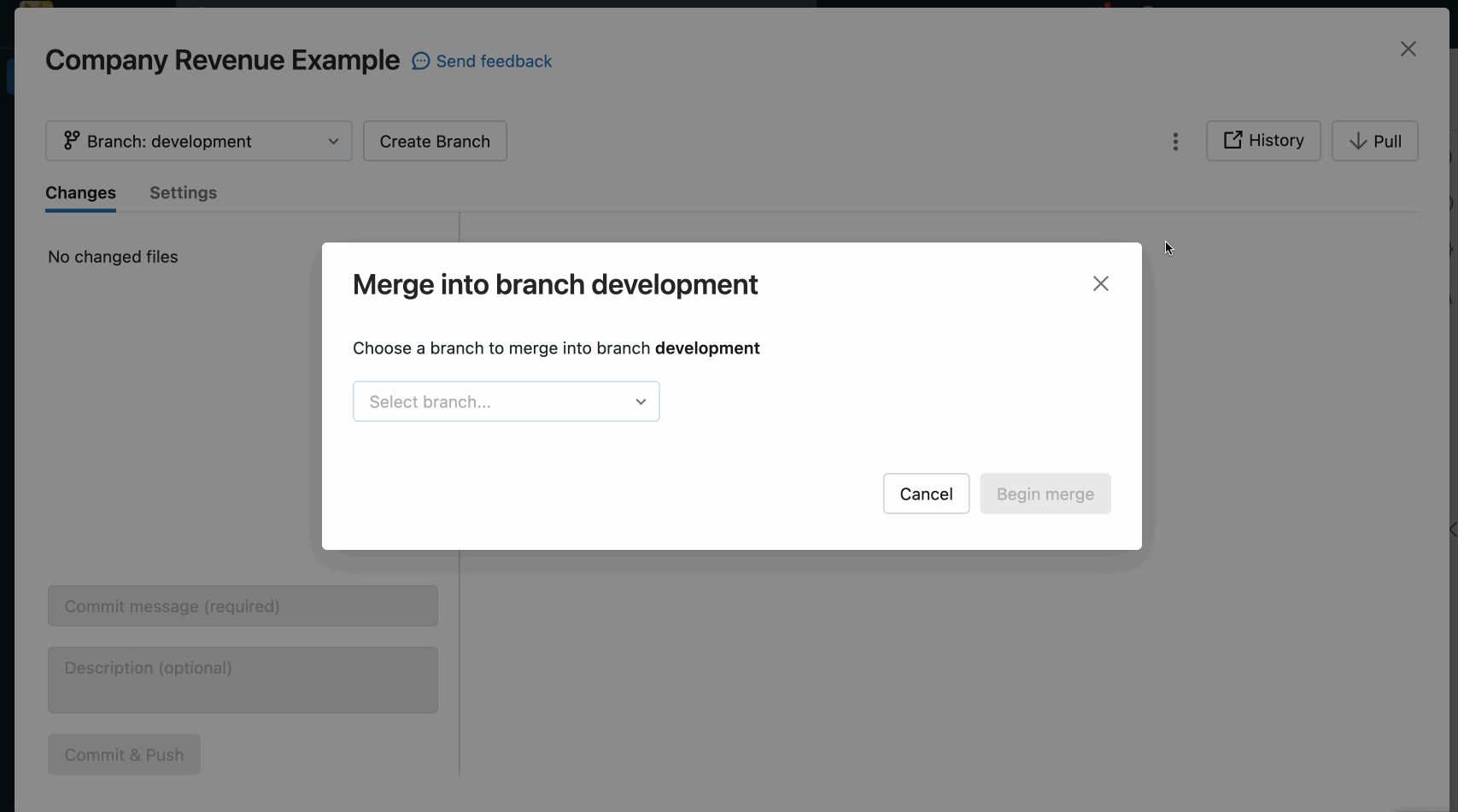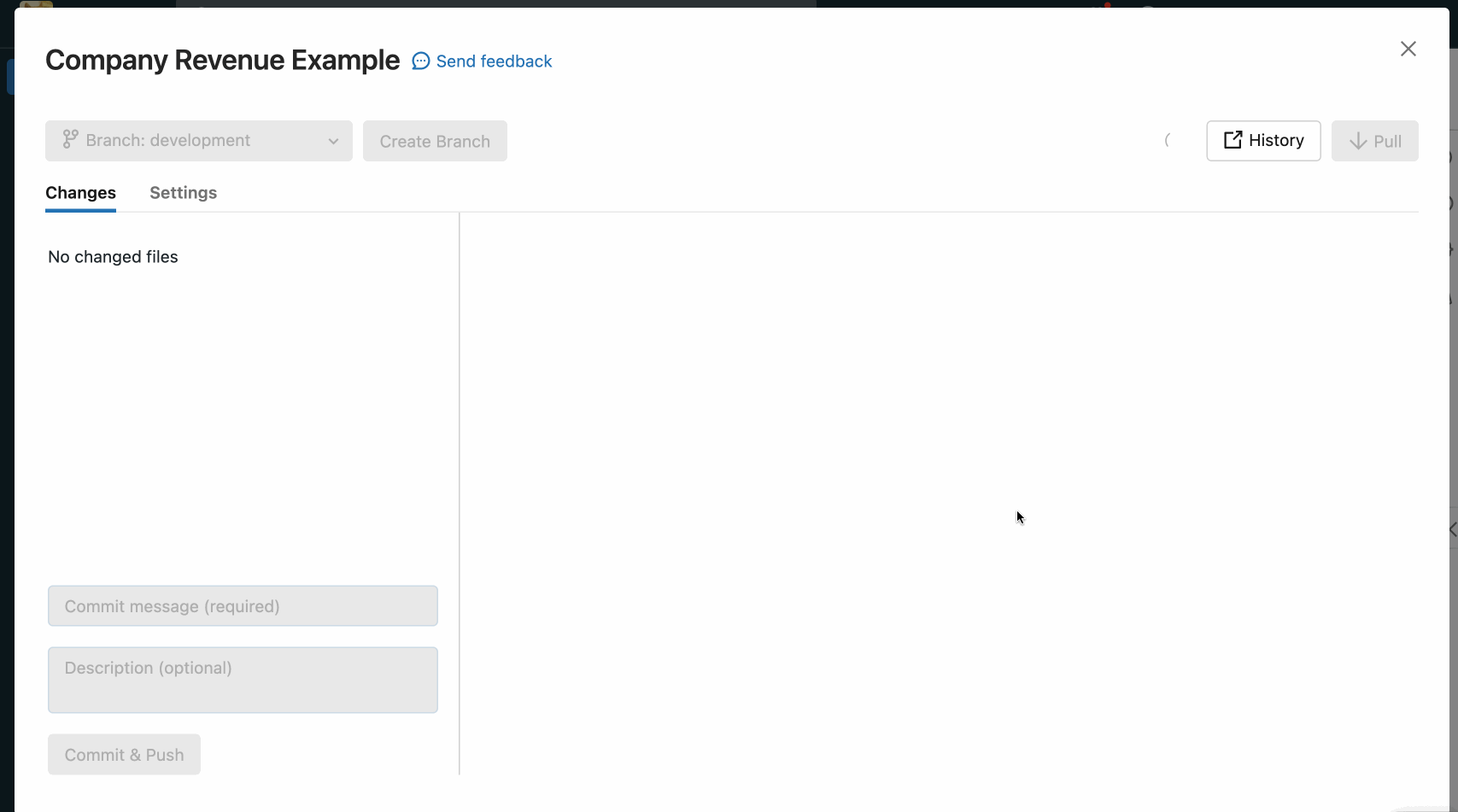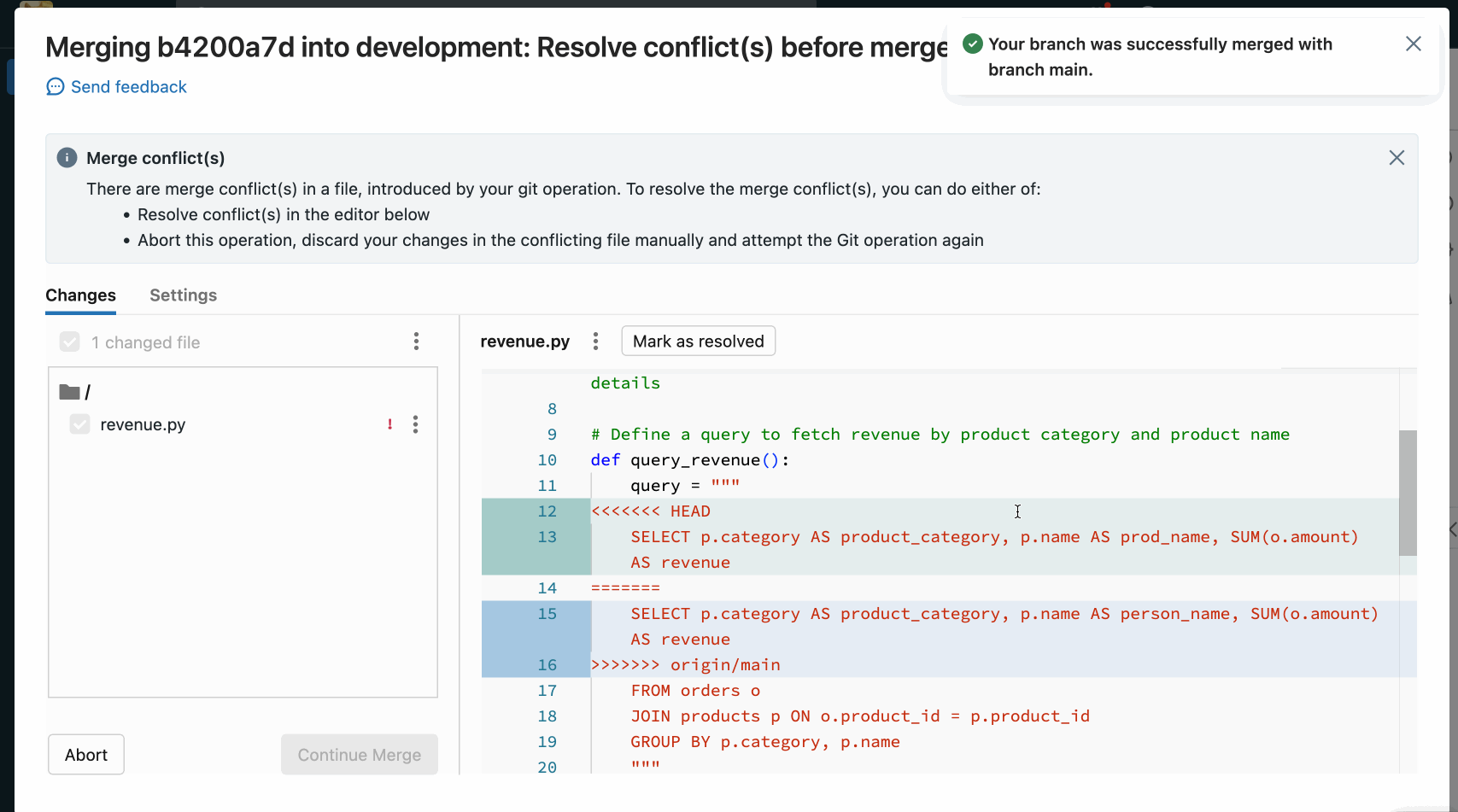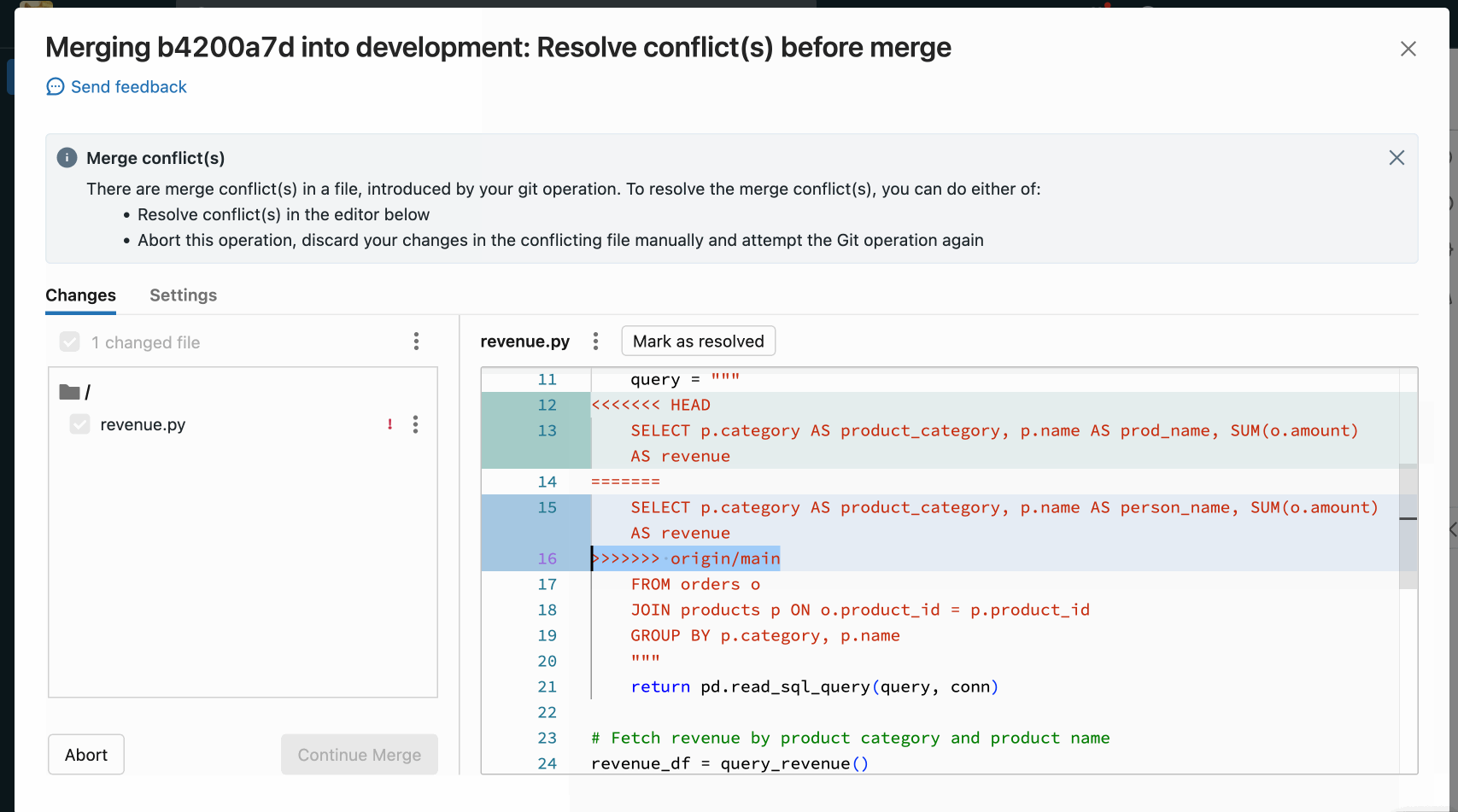
Quando si risolve unisci conflitti con l'interfaccia utente delle cartelle Git, è necessario scegliere tra risolvere manualmente i conflitti nell'editor o mantenere tutte le modifiche in ingresso o correnti.
Mantenere tutte le modifiche correnti o apportare modifiche in ingresso
Se si è certi di solo si desidera mantenere tutte le modifiche correnti o in ingresso, fare clic sul kebab a destra del nome del file nel riquadro del notebook e selezionare Mantieni tutte le modifiche correnti o Accetta tutte le modifiche in ingresso. Fare clic sul pulsante con la stessa etichetta per eseguire il commit delle modifiche e risolvere il conflitto.
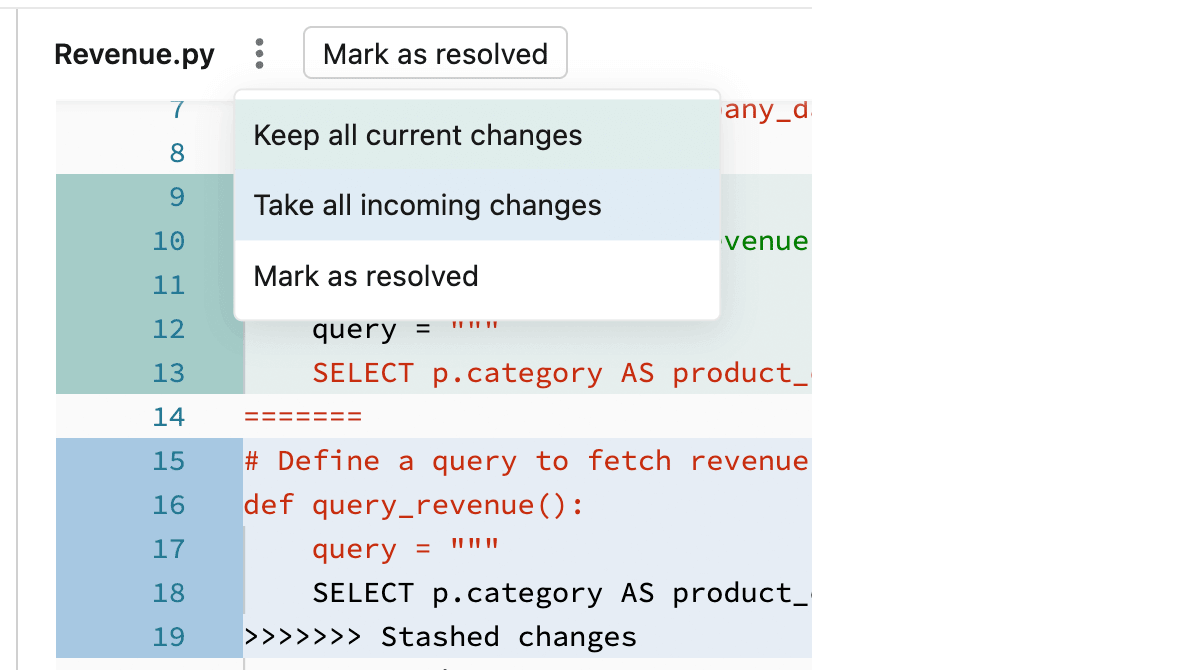
Suggerimento
Confusa su quale opzione scegliere? Il colore di ogni opzione corrisponde alle rispettive modifiche al codice che manterrà nel file.
Risoluzione manuale dei conflitti
La risoluzione manuale dei conflitti consente di determinare quali righe in conflitto devono essere accettate nell'unione. Per i conflitti di unione, è possibile risolvere il conflitto modificando direttamente il contenuto del file con i conflitti.
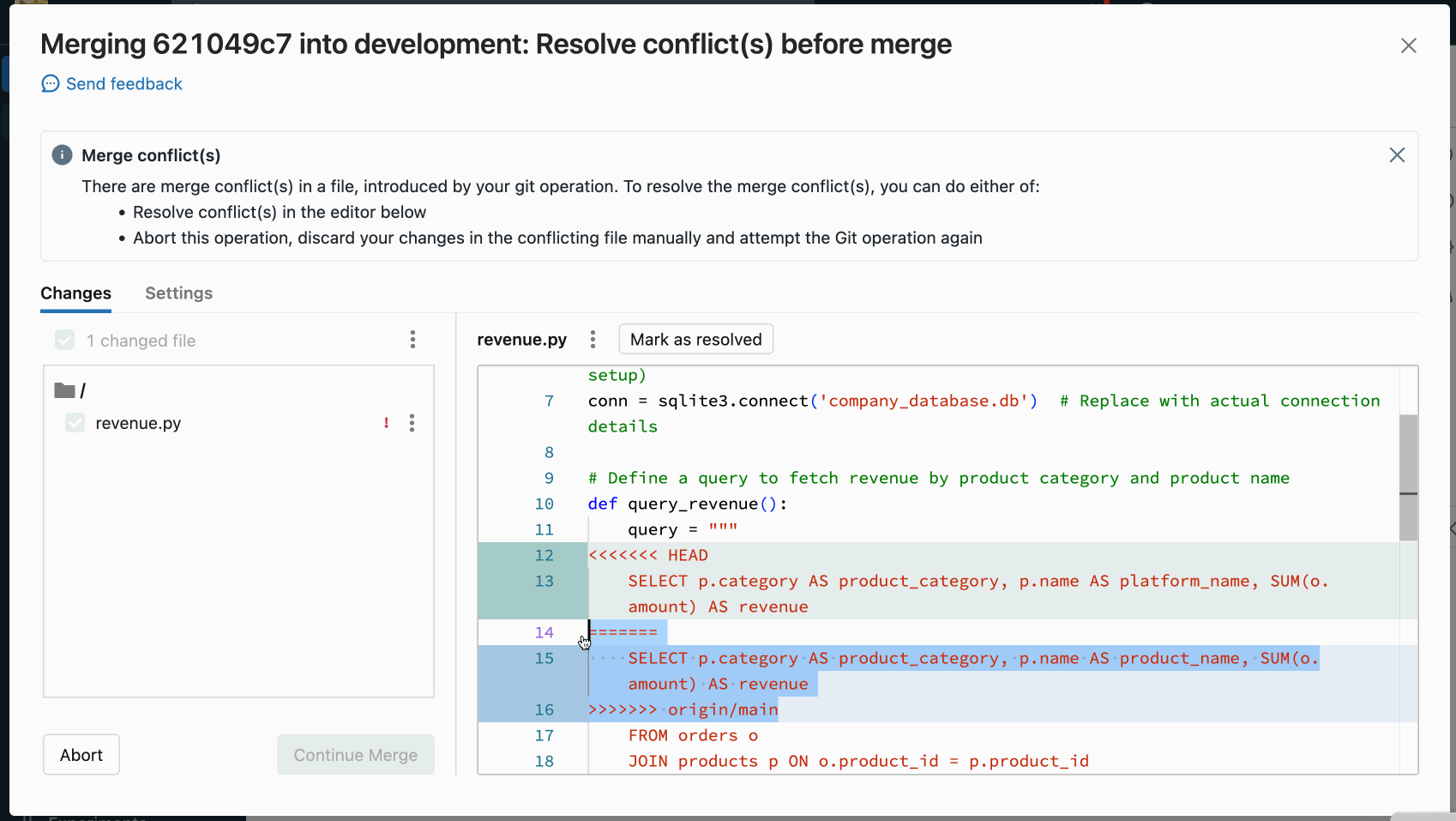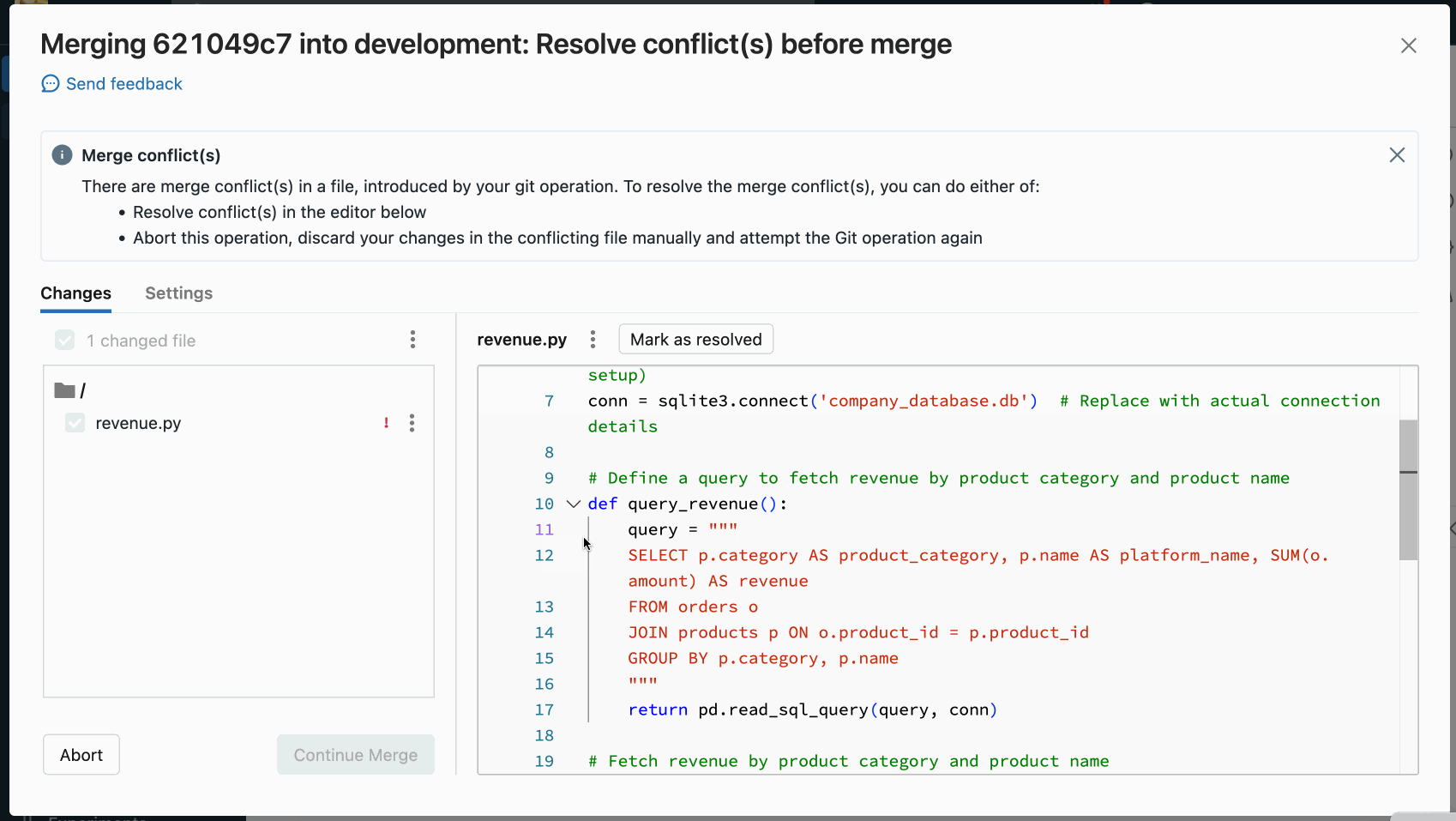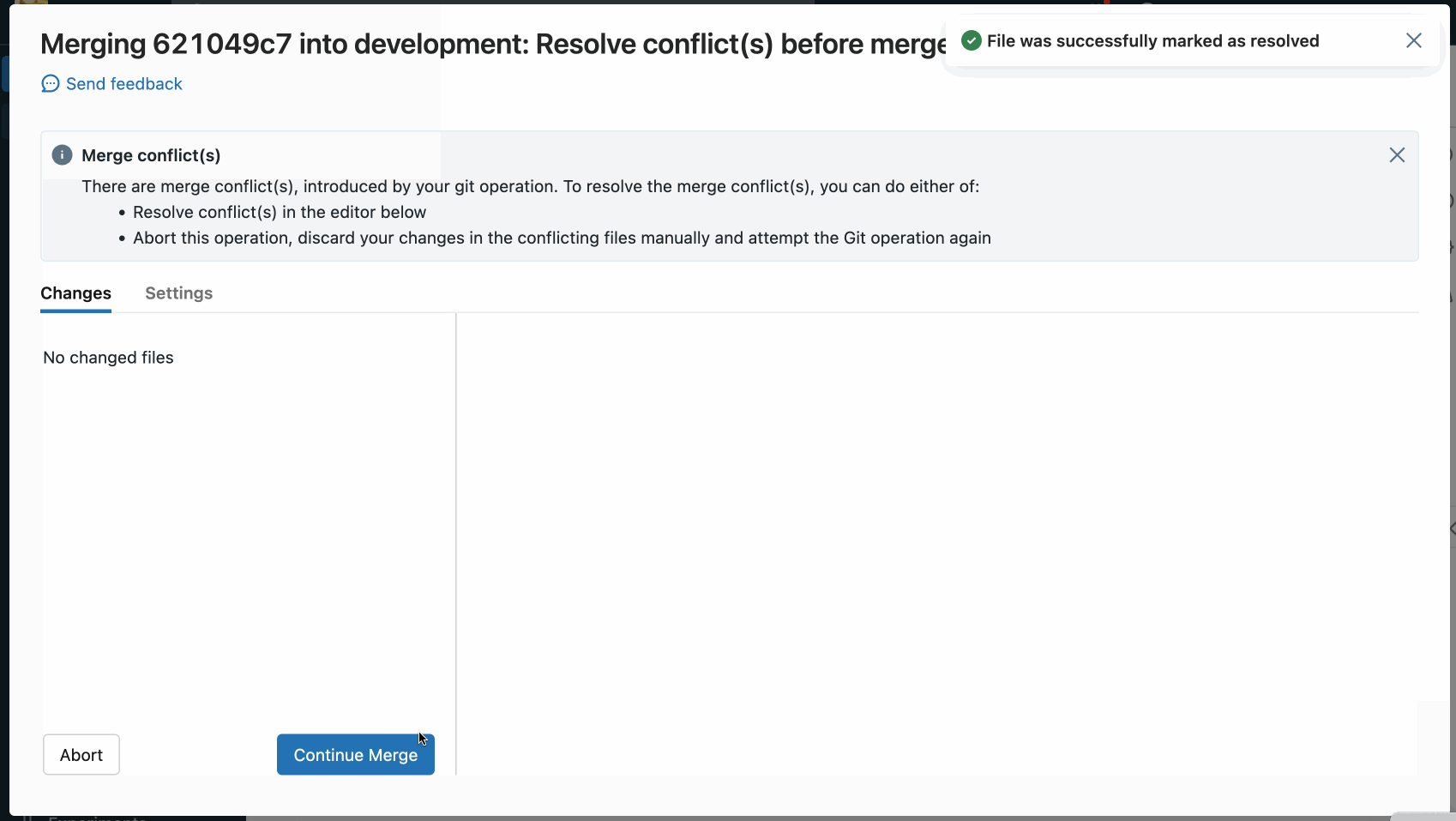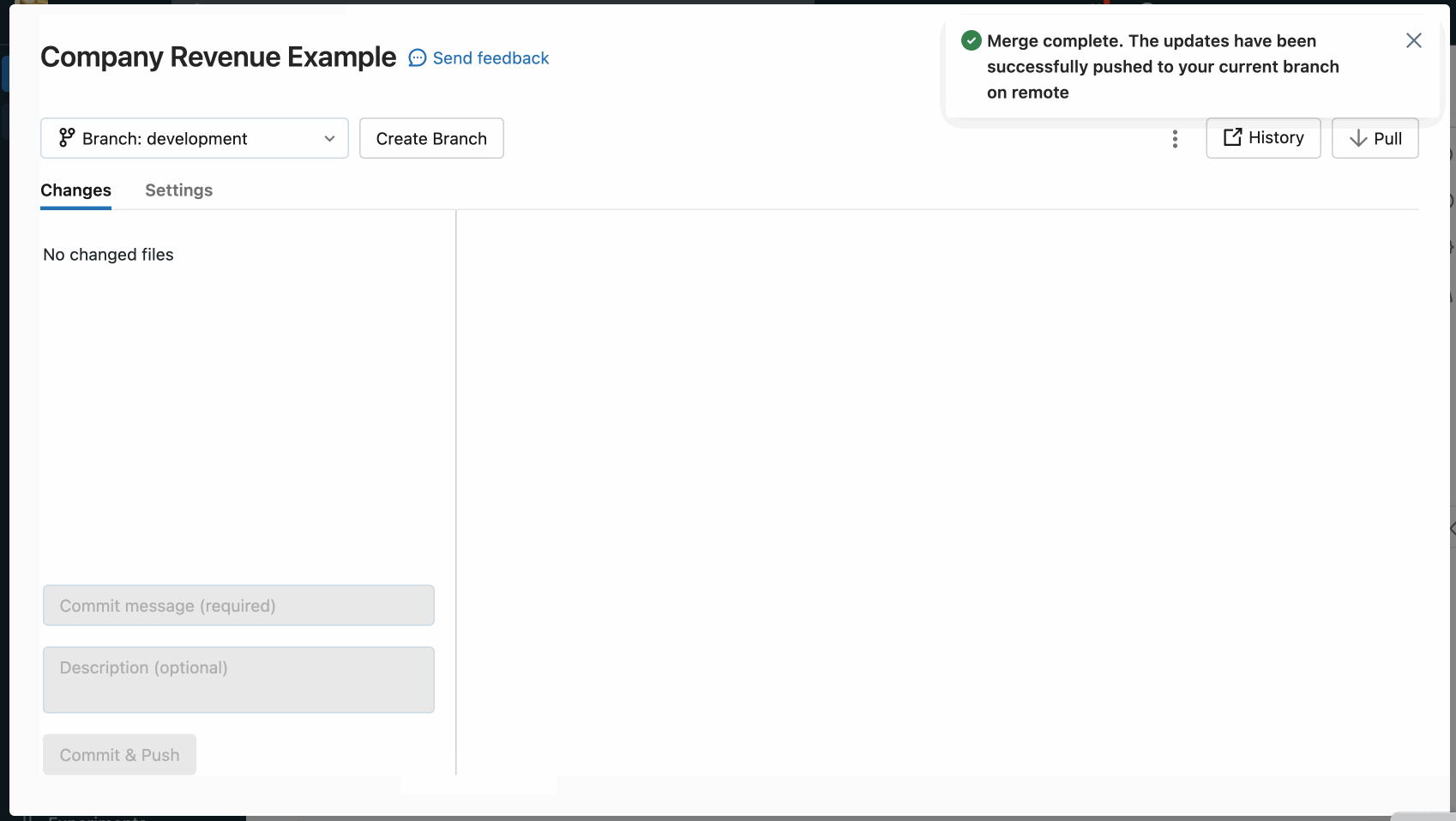
Per risolvere il conflitto, selezionare le righe di codice da conservare ed eliminare tutto il resto, inclusi i marcatori di conflitto di unione Git. Al termine, seleziona Contrassegna come risolto.
Se si decide di effettuare le scelte sbagliate durante la risoluzione dei conflitti di unione, fare clic sul pulsante Interrompi per interrompere il processo e annullare tutto. Dopo aver risolto tutti i conflitti, fare clic sull'opzione Continua unione o Continua rebase per risolvere il conflitto e completare l'operazione.
Git reset
Nelle cartelle Git di Databricks è possibile eseguire un git reset nell'interfaccia utente di Azure Databricks. La reimpostazione git nelle cartelle Git di Databricks equivale a git reset --hard combinata con git push --force.
La reimpostazione di Git sostituisce il contenuto e la cronologia dei rami con lo stato più recente di un altro ramo. È possibile usarlo quando le modifiche sono in conflitto con il ramo upstream e non è consigliabile perdere tali modifiche quando si reimposta il ramo upstream.
Altre informazioni su git reset –hard.
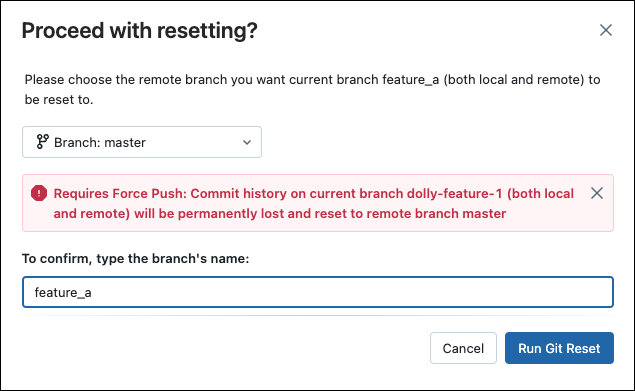
Reimpostare un ramo di origine (remoto)
Con git reset in questo scenario:
- È possibile reimpostare il ramo selezionato ( ad esempio,
feature_a) in un ramo diverso ( ad esempio,main). - È anche possibile reimpostare il ramo upstream (remoto)
feature_asu main.
Importante
Quando si reimposta, si perdono tutte le modifiche non confermate e confermate sia nella versione locale che remota del ramo.
Per reimpostare un ramo a un ramo remoto:
Nell'interfaccia delle cartelle Git dal menu ramo , scegli il ramo che vuoi reimpostare.
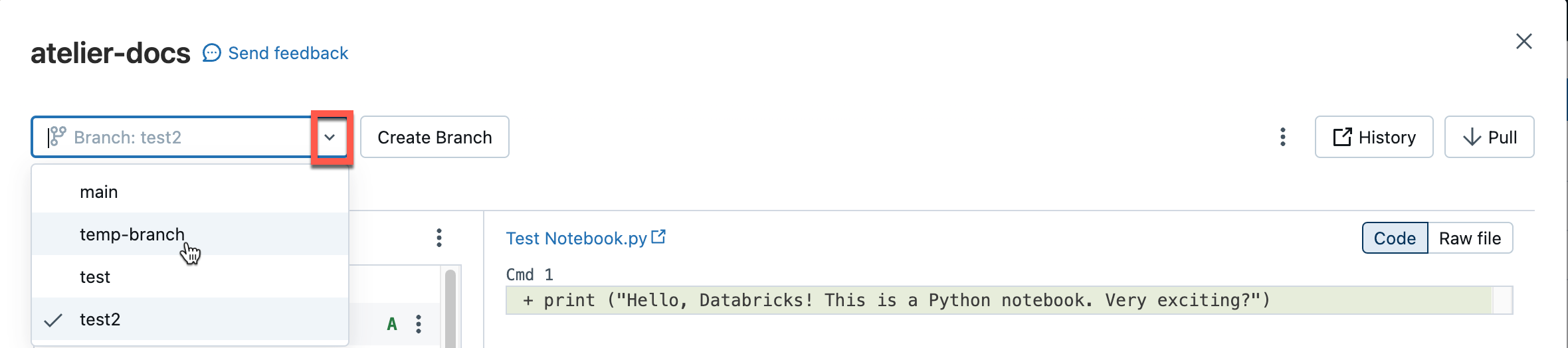
Selezionare Reimposta dal menu kebab.

Selezionare il ramo da reimpostare.
Configurare la modalità di estrazione di tipo sparse
Estrazione di tipo sparse è un'impostazione lato client che consente di clonare e usare solo un subset delle directory dei repository remoti in Databricks. Ciò è particolarmente utile se le dimensioni del repository superano i limiti supportati da Databricks.
È possibile usare la modalità Estrazione sparse quando si aggiunge (clonazione) un nuovo repository.
Nella finestra di dialogo Aggiungi cartella Git aprire Avanzate.
Selezionare modalità sparse di estrazione.
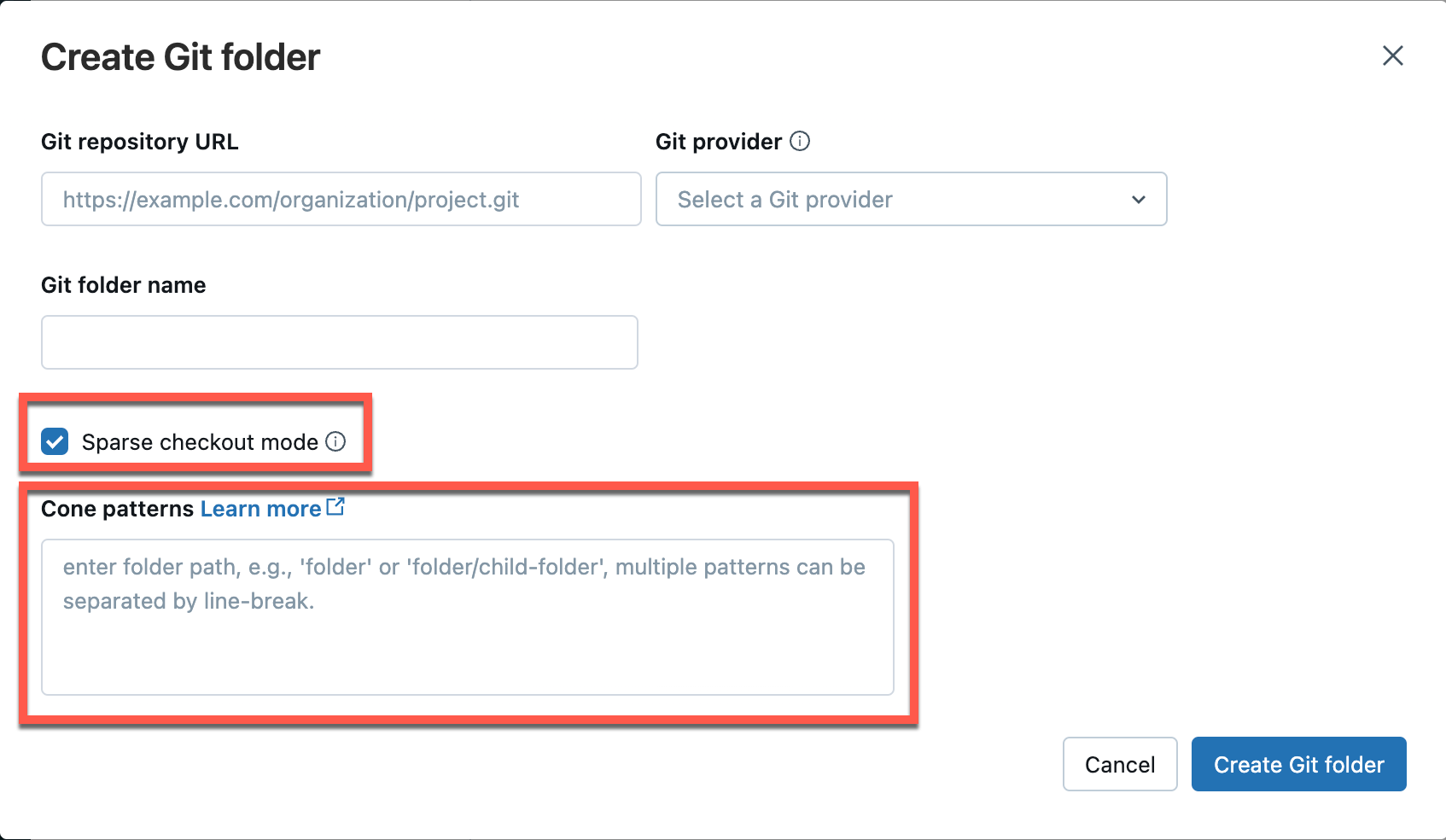
Nella casella Modelli coni specificare i modelli di estrazione dei coni desiderati. Separare più modelli per interruzioni di riga.
Al momento, non è possibile disabilitare il checkout di tipo sparse per un repository in Azure Databricks.
Funzionamento dei modelli coni
Per comprendere il funzionamento del modello cono nella modalità di estrazione di tipo sparse, vedere il diagramma seguente che rappresenta la struttura del repository remoto.
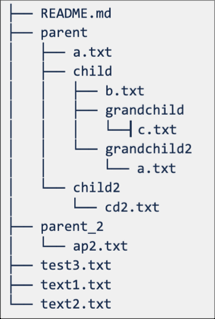
Se si seleziona modalità di estrazione sparse, ma non si specifica un modello cono, viene applicato il modello di cono predefinito. Sono inclusi solo i file nella radice e nessuna sottodirectory, con conseguente struttura di repository come indicato di seguito:

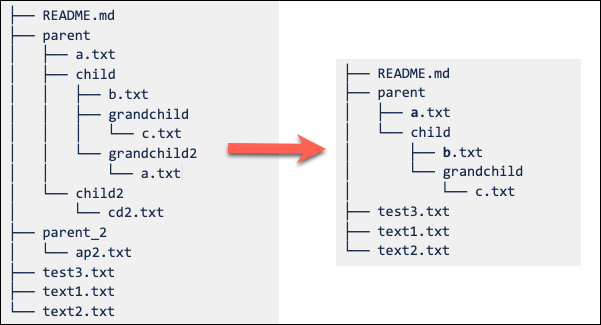
L'impostazione del modello di cono di estrazione di tipo sparse comporta parent/child/grandchild l'inserimento ricorsivo di tutti i contenuti della grandchild directory. Sono inclusi anche i file immediatamente nella /parentdirectory radice /parent/child e . Vedere la struttura di directory nel diagramma seguente:
È possibile aggiungere più modelli separati da interruzioni di riga.
Nota
I comportamenti di esclusione (!) non sono supportati nella sintassi del modello di cono Git.
Modificare le impostazioni di estrazione di tipo sparse
Dopo aver creato un repository, il modello di cono di estrazione sparse può essere modificato da > avanzati>.
Nota il seguente comportamento:
La rimozione di una cartella dal modello cono lo rimuove da Databricks se non sono presenti modifiche di cui non è stato eseguito il commit.
L'aggiunta di una cartella tramite la modifica del modello di cono di estrazione sparse lo aggiunge a Databricks senza richiedere un pull aggiuntivo.
I modelli di estrazione di tipo sparse non possono essere modificati per rimuovere una cartella quando sono presenti modifiche di cui non è stato eseguito il commit in tale cartella.
Ad esempio, un utente modifica un file in una cartella e non esegue il commit delle modifiche. Tenta quindi di modificare il modello di estrazione sparse in modo da non includere questa cartella. In questo caso, il modello viene accettato, ma la cartella effettiva non viene eliminata. Deve ripristinare il modello per includere tale cartella, eseguire il commit delle modifiche e quindi riapplicare il nuovo modello.
Nota
Non è possibile disabilitare il checkout di tipo sparse per un repository creato con la modalità Estrazione sparse abilitata.
Apportare ed eseguire il push delle modifiche con estrazione di tipo sparse
È possibile modificare i file esistenti ed eseguirne il commit ed eseguirne il push dalla cartella Git. Quando si creano nuove cartelle di file, includerli nel modello cono specificato per tale repository.
L'inclusione di una nuova cartella all'esterno del modello cono genera un errore durante l'operazione di commit e push. Per correggerlo, modificare il modello di cono per includere la nuova cartella che si sta tentando di eseguire il commit e il push.
Criteri per un file config del repository
Il file di configurazione degli output commit usa modelli simili ai modelli gitignore ed esegue le operazioni seguenti:
- I criteri positivi consentono l'inclusione degli output per i notebook corrispondenti.
- I criteri negativi disabilitano l'inclusione degli output per i notebook corrispondenti.
- I criteri vengono valutati in ordine per tutti i notebook.
- I percorsi o i percorsi non validi che non risolvono ai notebook
.ipynbvengono ignorati.
Modello positivo: per includere output da un percorso folder/innerfolder/notebook.ipynbdel notebook, usare i modelli seguenti:
**/*
folder/**
folder/innerfolder/note*
Modello negativo: per escludere gli output per un notebook, verificare che nessuno dei modelli positivi corrisponda o aggiungere un criterio negativo in un punto corretto del file di configurazione. I criteri negativi (escludi) iniziano con !:
!folder/innerfolder/*.ipynb
!folder/**/*.ipynb
!**/notebook.ipynb
Limitazione di estrazione di tipo sparse
Il checkout di tipo sparse attualmente non funziona per i repository di Azure DevOps di dimensioni superiori a 4 GB.
Aggiungere un repository e connettersi in remoto in un secondo momento
Per gestire e usare cartelle Git a livello di codice, usare l'API REST delle cartelle Git.