2019 ottobre
Queste funzionalità e i miglioramenti della piattaforma Azure Databricks sono stati rilasciati a ottobre 2019.
Nota
Le versioni vengono gestite in staging. L'account Azure Databricks potrebbe non essere aggiornato fino a una settimana dopo la data di rilascio iniziale.
Metriche di supportabilità spostate in Hub eventi di Azure
22-29 ottobre 2019
Le metriche di supporto che consentono ad Azure Databricks di monitorare l'integrità del cluster sono state migrate dall'archiviazione BLOB di Azure agli endpoint di Hub eventi. Ciò consente ad Azure Databricks di fornire risposte a una latenza inferiore per risolvere gli eventi imprevisti dei clienti. Per le aree di lavoro di inserimento della rete virtuale, è stata aggiunta una regola aggiuntiva al gruppo di sicurezza di rete per l'endpoint del EventHub servizio. I dettagli sono disponibili nella tabella Regole del gruppo di sicurezza di rete. Non è necessaria alcuna azione per garantire la disponibilità continua dei servizi.
Per un elenco delle metriche di supporto di Hub eventi di Azure Databricks in base all'area, vedere Metastore, artifact Blob storage, system tables storage, log BLOB storage e event Hubs endpoint IP addresses ( Metastore, artifact Blob storage, log BLOB storage e endpoint di Hub eventi).
Passthrough di credenziali di Azure Data Lake Storage in cluster standard e Scala ora disponibile a livello generale
22 ottobre 29, 2019: versione 3.5
Il pass-through delle credenziali per Python, SQL e Scala nei cluster standard che eseguono Databricks Runtime 5.5 e versioni successive, nonché SparkR in Databricks Runtime 6.0 e versioni successive è disponibile a livello generale. Vedere Abilitare il pass-through delle credenziali di Azure Data Lake Storage per un cluster Standard.
Disponibilità a livello generale di Databricks Runtime 6.1 per Genomica
22 ottobre 2019
Databricks Runtime 6.1 per Genomica è disponibile a livello generale.
Disponibilità generale di Databricks Runtime 6.1 per Machine Learning
22 ottobre 2019
Databricks Runtime 6.1 ML è disponibile a livello generale. Include il supporto per i cluster GPU e gli aggiornamenti alle librerie di Machine Learning seguenti:
- TensorFlow a 1.14.0
- Da PyTorch a 1.2.0
- Torchvision a 0.4.0
- Da MLflow a 1.3.0
Per altre informazioni, vedere le note sulla versione completa di Databricks Runtime 6.1 per ML (EoS).
Chiamate API MLflow ora con limite di frequenza
22 ottobre 29, 2019: versione 3.5
Per garantire un'elevata qualità del servizio con carico elevato, Azure Databricks applica ora limiti di frequenza API per tutte le chiamate API MLflow. I limiti sono impostati per account per garantire un utilizzo equo e una disponibilità elevata per tutte le organizzazioni che condividono un'area di lavoro.
I client MLflow con tentativi automatici sono disponibili in MLflow 1.3.0 e si trovano in Databricks Runtime 6.1 per ML (EoS). È consigliabile che tutti i clienti passino alla versione più recente del client MLflow.
Per informazioni dettagliate, vedere API Experiments.
Pool di istanze per l’avvio rapido di un cluster disponibili a livello generale
22 ottobre 29, 2019: versione 3.5
La funzionalità di Azure Databricks che supporta il collegamento di un cluster a un pool predefinito di istanze inattive è ora disponibile a livello generale.
Azure Databricks non addebita unità DBU quando le istanze sono inattive nel pool. Viene applicata la fatturazione del provider di istanze. Vedere Prezzi.
Per informazioni dettagliate, vedere Guida di riferimento per la configurazione del pool.
Disponibilità a livello generale di Databricks Runtime 6.1
16 ottobre 2019
Databricks Runtime 6.1 offre diversi miglioramenti a Delta Lake:
- Convertire facilmente le tabelle in formato Delta Lake
- API Python per le tabelle Delta (anteprima pubblica)
- Eliminazione file dinamica (DFP) abilitata per impostazione predefinita
Databricks Runtime 6.1 rimuove anche diverse limitazioni nel pass-through delle credenziali.
Nota
A partire dalla versione 6.1, Databricks Runtime supporta solo i cluster CPU. Se si vogliono usare cluster GPU, è necessario usare Databricks Runtime ML.
Per altre informazioni, vedere le note sulla versione complete di Databricks Runtime 6.1 (EoS).
Disponibilità a livello generale di Databricks Runtime 6.0 per Genomica
16 ottobre 2019
Databricks Runtime per Genomica (Genomica di Databricks Runtime) è una variante di Databricks Runtime ottimizzata per l'uso di dati genomici e biomedici. A partire dalla versione 6.0, Databricks Runtime per Genomica è disponibile a livello generale.
Disponibilità a livello generale della possibilità di distribuire un’area di lavoro di Azure Databricks nella propria rete virtuale, nota anche come aggiunta nella rete virtuale
9 ottobre 2019
Siamo molto lieti di annunciare la disponibilità generale della possibilità di distribuire un'area di lavoro di Azure Databricks nella propria rete virtuale, nota anche come inserimento di reti virtuali. Questa opzione è destinata a coloro che richiedono la personalizzazione di rete e pertanto non vogliono usare la rete virtuale predefinita creata quando si distribuisce un'area di lavoro di Azure Databricks nel modo standard. Con l'inserimento di reti virtuali, è possibile:
- Connettere Azure Databricks ad altri servizi di Azure (ad esempio Archiviazione di Azure) in modo più sicuro usando endpoint servizio.
- Connettersi alle origini dati locali per l'uso con Azure Databricks sfruttando i percorsi definiti dall'utente.
- Connettere Azure Databricks a un'appliance virtuale di rete per ispezionare tutto il traffico in uscita e intraprendere azioni a seconda delle regole di autorizzazione e negazione.
- Configurare Azure Databricks in modo che usi DNS personalizzato.
- Configurare le regole del gruppo di sicurezza di rete (NSG) in modo che specifichino le restrizioni del traffico in uscita.
- Distribuire i cluster di Azure Databricks nella rete virtuale esistente.
La distribuzione di Azure Databricks nella propria rete virtuale consente anche di sfruttare gli intervalli CIDR flessibili (ovunque tra /16-/24 per la rete virtuale e fino a /26 per le subnet).
La configurazione con l'interfaccia utente di portale di Azure è rapida e semplice: quando si crea un'area di lavoro, è sufficiente selezionare Distribuisci l'area di lavoro di Azure Databricks nella Rete virtuale, selezionare la rete virtuale e fornire intervalli CIDR per due subnet. Azure Databricks aggiorna la rete virtuale con le due nuove subnet e i gruppi di sicurezza di rete, consente l'accesso al traffico subnet in ingresso e in uscita e distribuisce l'area di lavoro alla rete virtuale aggiornata.
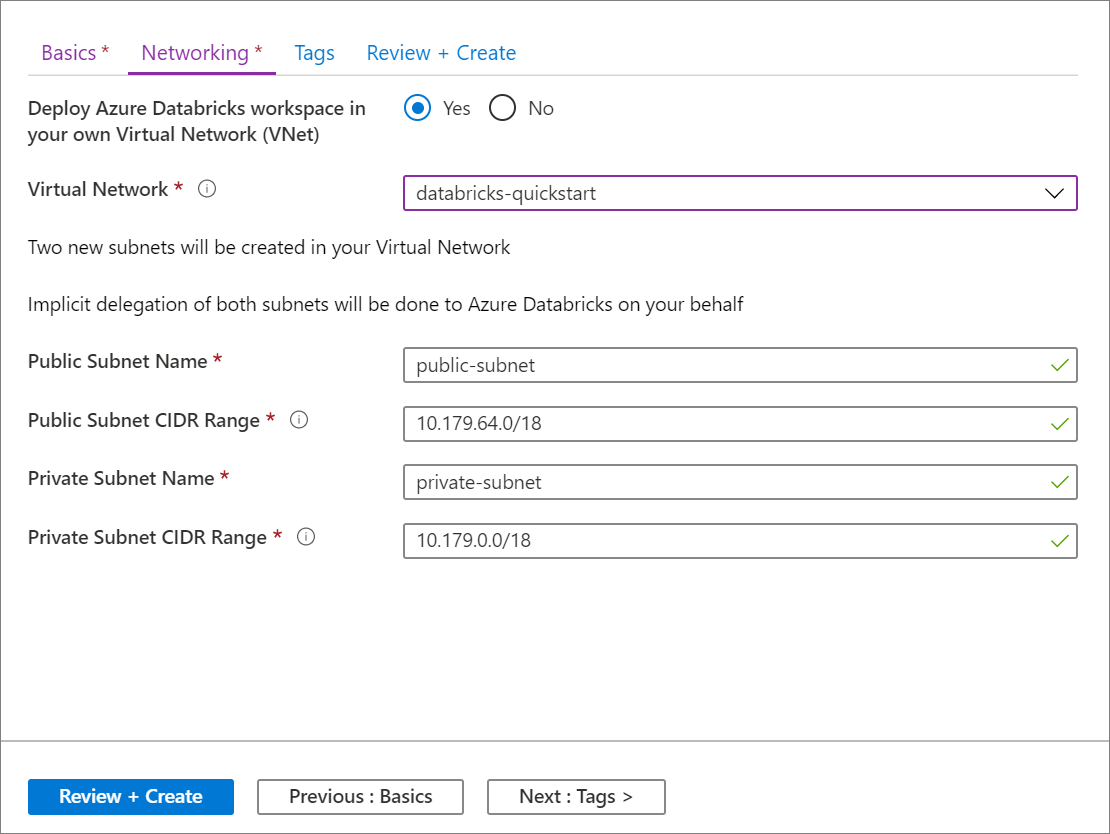
Se si preferisce configurare manualmente la rete virtuale per l'aggiunta nella reti virtuale, se ad esempio si vogliono usare subnet o gruppi di sicurezza di rete esistenti o creare regole di sicurezza personalizzate, è possibile usare modelli ARM forniti da Azure-Databricks anziché l'interfaccia utente del portale.
Nota
Se si è partecipato all'anteprima di inserimento della rete virtuale, è necessario aggiornare l'area di lavoro di anteprima alla versione disponibile a livello generale prima del 31 gennaio 2020 per continuare a ricevere supporto.
Per informazioni dettagliate, vedere Distribuire Azure Databricks nella rete virtuale di Azure (aggiunta nella rete virtuale) e Connettere l'area di lavoro di Azure Databricks alla rete locale.
Gli utenti di Azure Databricks non amministratori possono leggere i nomi e gli ID di utenti e gruppi usando l’API SCIM
8 ottobre - 15, 2019: versione 3.4
Gli utenti non amministratori possono ora richiamare l'API Gruppi Get Users e Get Groups endpoints (Ottieni utenti e gruppi) per leggere solo nomi e ID visualizzati di utenti e gruppi. Tutte le altre operazioni DELL'API SCIM continuano a richiedere l'accesso amministratore.
L’API Area di lavoro restituisce gli ID oggetto di notebook e cartelle
8 ottobre - 15, 2019: versione 3.4
Gli get-status endpoint e list dell'API Workspace restituiscono ora ID oggetto notebook e cartella, offrendo la possibilità di fare riferimento a tali oggetti in altre chiamate API.
Disponibilità a livello generale di Databricks Runtime 6.0 ML
4 ottobre 2019
Databricks Runtime 6.0 ML include gli aggiornamenti seguenti:
- MLflow
- Una nuova origine dati Spark per gli esperimenti MLflow offre ora un'API standard per caricare i dati di esecuzione dell'esperimento MLflow.
- Aggiunta del client Java MLflow
- MLflow è ora promosso a libreria di livello superiore
- Hyperopt GA: miglioramenti significativi dall'anteprima pubblica includono il supporto per la registrazione di MLflow nei ruoli di lavoro Spark, la corretta gestione delle variabili di trasmissione PySpark e una nuova guida sulla selezione del modello tramite Hyperopt.
- Librerie Horovod e MLflow aggiornate e distribuzione di Anaconda.
Nota
In questa versione sono supportati solo i cluster CPU.
Per altre informazioni, vedere le note sulla versione completa di Databricks Runtime 6.0 per ML (EoS).
Nuove regioni: Brasile meridionale e Francia centrale
1 ottobre 2019
Azure Databricks è ora disponibile in Brasile meridionale (Stato di San Paolo) e francia centrale (Parigi).
Disponibilità a livello generale di Databricks Runtime 6.0
1 ottobre 2019
Databricks Runtime 6.0 offre numerosi aggiornamenti della libreria e nuove funzionalità, tra cui:
- Nuove API Scala e Java per i comandi DML di Delta Lake, nonché i comandi dell'utilità vacuum e history.
- Client FUSE DBFS avanzato per letture e scritture più veloci e affidabili durante il training del modello.
- Supporto per più tracciati matplotlib per cella del notebook.
- Eseguire l'aggiornamento a Python 3.7, oltre a numpy, pandas, matplotlib e altre librerie.
- Tramonto del supporto di Python 2.
Nota
In questa versione sono supportati solo i cluster CPU.
Per altre informazioni, vedere le note sulla versione complete di Databricks Runtime 6.0 (EoS).