febbraio 2019
Queste funzionalità e i miglioramenti della piattaforma Azure Databricks sono stati rilasciati a febbraio 2019.
Nota
Le versioni vengono gestite in staging. L'account Azure Databricks potrebbe non essere aggiornato fino a una settimana dopo la data di rilascio iniziale.
Databricks Light disponibile a livello generale
26 febbraio - 5 marzo 2019: versione 2.92
Databricks Light (noto anche come Ingegneria dei dati Light) è ora disponibile. Databricks Light è il packaging Databricks del runtime Apache Spark open source. Offre un'opzione di runtime per i processi che non richiedono i vantaggi in termini prestazioni avanzate, affidabilità o scalabilità automatica offerti da Databricks Runtime. È possibile selezionare Databricks Light solo quando si crea un cluster per eseguire un processo JAR, Python o spark-submit; non è possibile selezionare questo runtime per i cluster in cui si eseguono carichi di lavoro di processi interattivi o notebook. Vedere Databricks Light.
MLflow gestito nell’anteprima pubblica di Azure Databricks
26 febbraio - 5 marzo 2019: versione 2.92
MLflow è una piattaforma open source per la gestione del ciclo di vita end-to-end di Machine Learning. Affronta tre funzioni principali:
- Rilevamento degli esperimenti per registrare e confrontare parametri e risultati.
- Gestione e distribuzione di modelli da un'ampia gamma di librerie di ML a una serie di piattaforme Model Serving e di inferenza.
- Creazione di pacchetti del codice di ML in un modulo riutilizzabile e riproducibile per condividerlo con altri data scientist o trasferirlo alla produzione.
Azure Databricks fornisce ora una versione completamente gestita e ospitata di MLflow, integrata con funzionalità di sicurezza aziendali, disponibilità elevata e altre funzionalità dell'area di lavoro di Azure Databricks, ad esempio la gestione di esperimenti, la gestione di esecuzioni e l'acquisizione di revisioni di notebook. MLflow in Azure Databricks offre un'esperienza integrata per il rilevamento e la protezione delle esecuzioni di training dei modelli di Machine Learning e l'esecuzione dei progetti di Machine Learning. Usando MLflow gestito in Azure Databricks, si ottengono i vantaggi di entrambe le piattaforme, tra cui:
- Aree di lavoro: rilevare e organizzare in modo collaborativo esperimenti e risultati all'interno delle aree di lavoro di Azure Databricks, con un server di rilevamento MLflow ospitato e un'interfaccia utente dell'esperimento integrata. Quando si usa MLflow nei notebook, Azure Databricks acquisisce automaticamente le revisioni dei notebook in modo da poter riprodurre lo stesso codice e le stesse esecuzioni in un secondo momento.
- Sicurezza: sfruttare un modello di sicurezza comune per l'intero ciclo di vita di ML tramite ACL.
- Processi: eseguire progetti MLflow come processi di Azure Databricks in modalità remota e direttamente dai notebook di Azure Databricks.
Ecco una demo di un flusso di lavoro di rilevamento in un'area di lavoro di Azure Databricks:
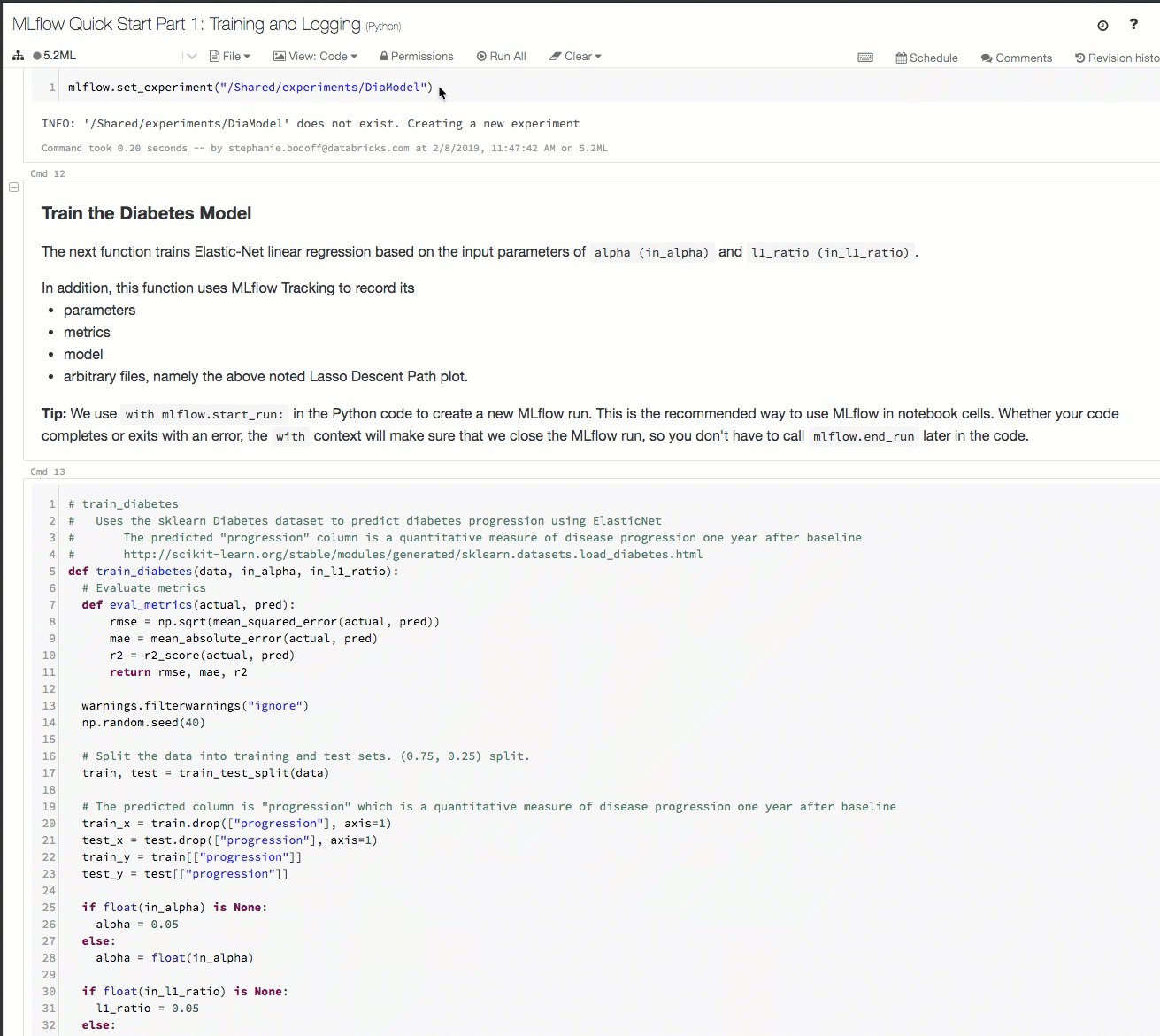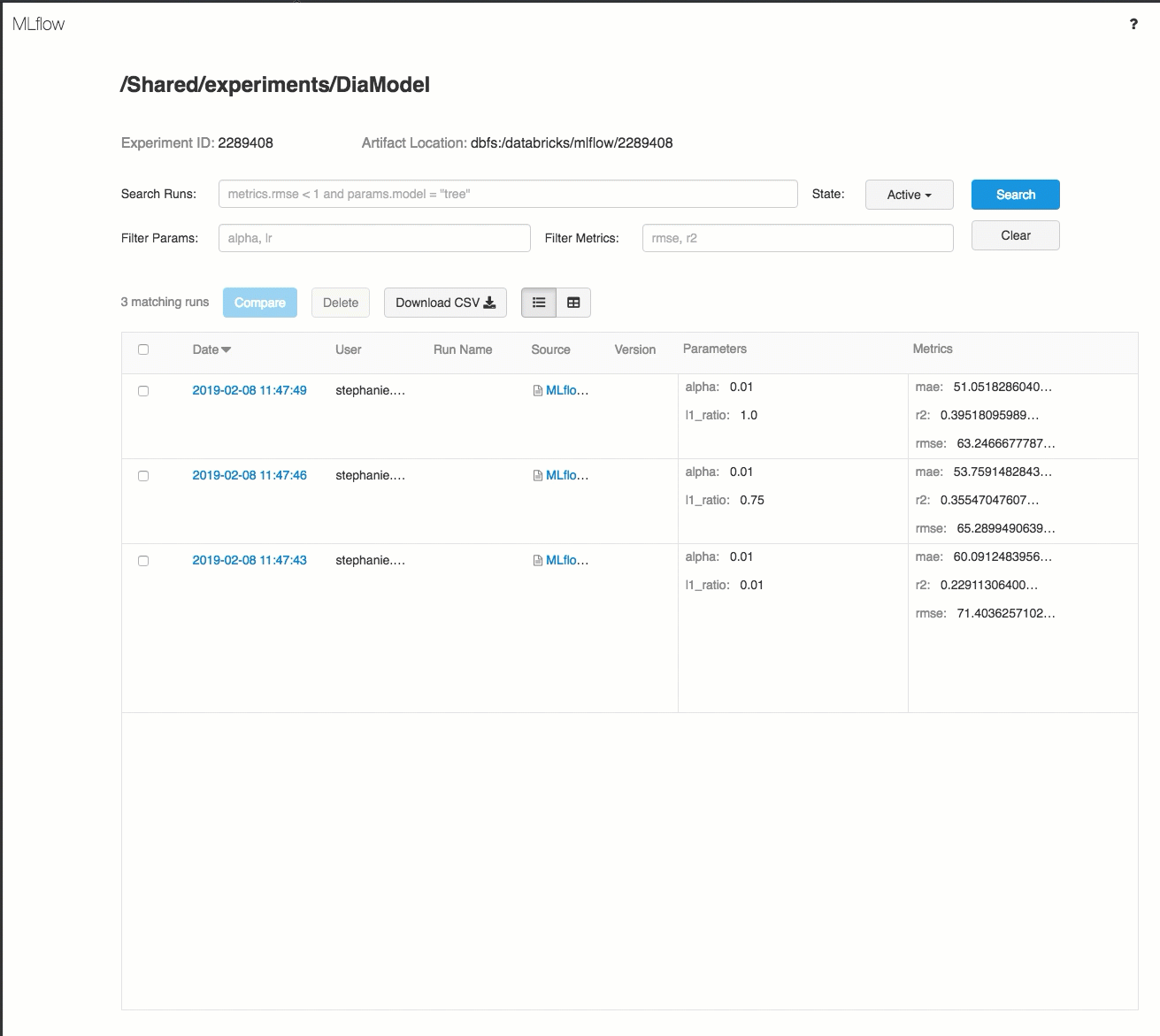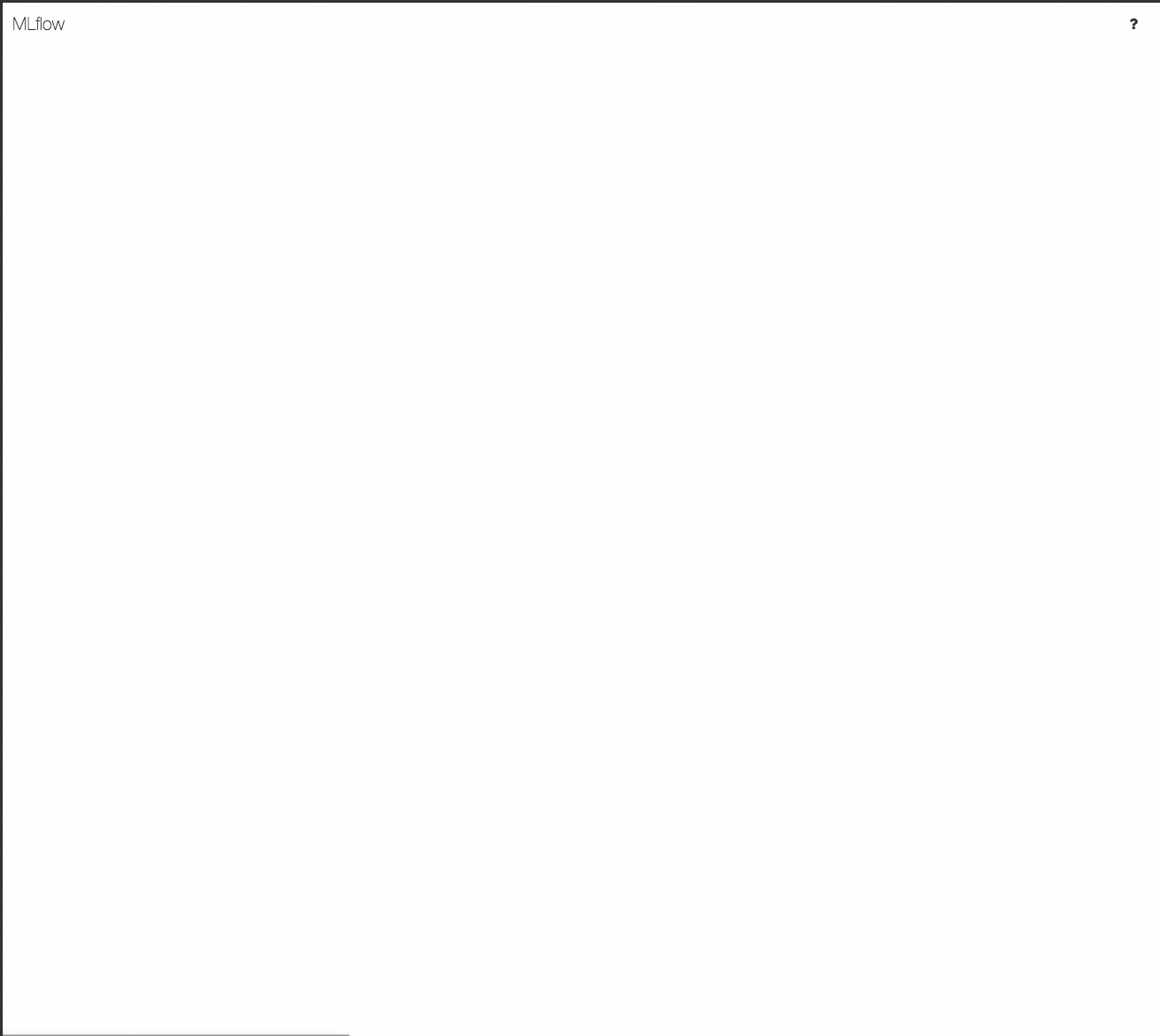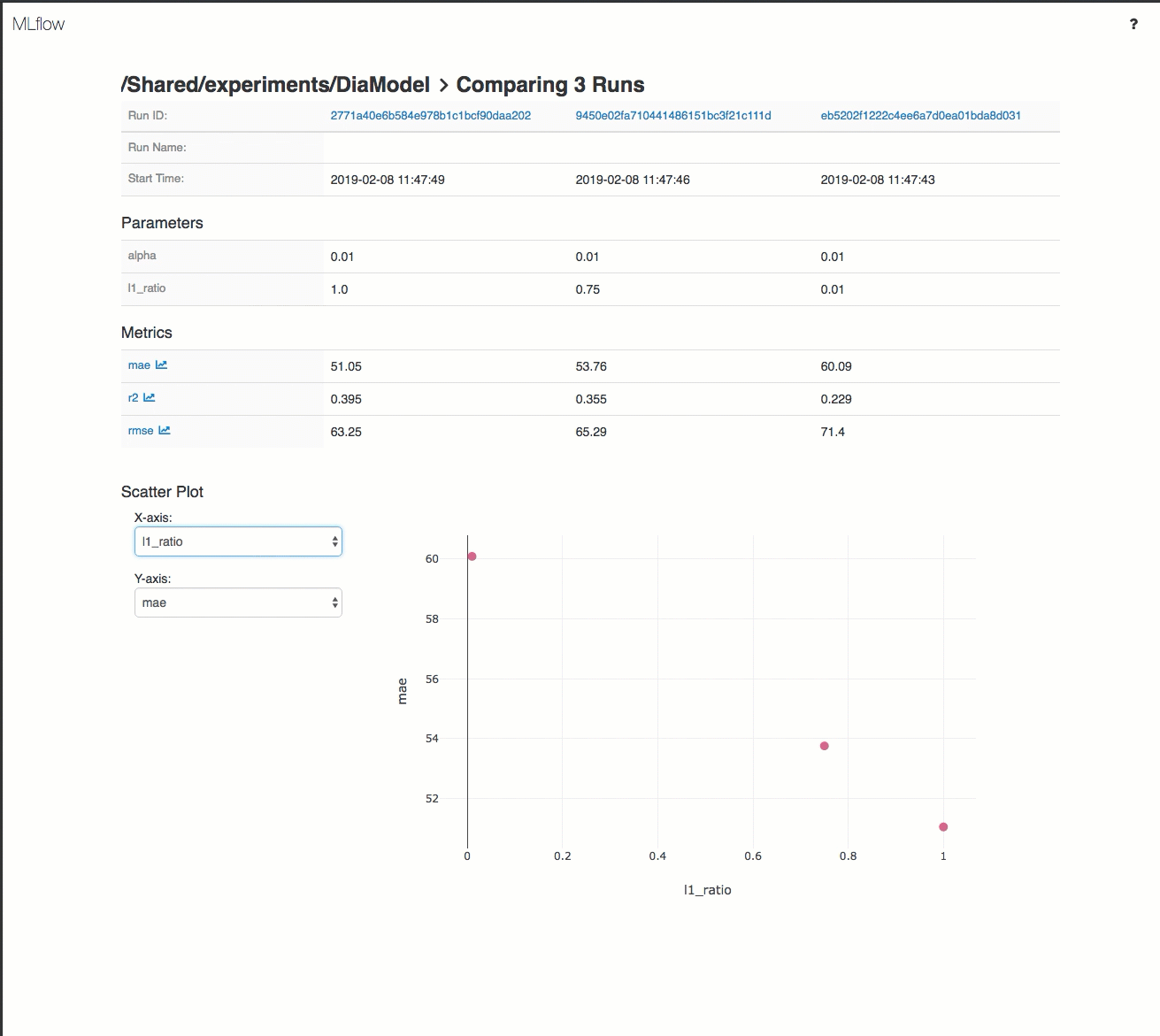
Per informazioni dettagliate, vedere Tenere traccia dello sviluppo di modelli con MLflow.
Il connettore Azure Data Lake Storage Gen2 è disponibile a livello generale
15 febbraio 2019
Azure Data Lake Storage Gen2 (ADLS Gen2), la soluzione Data Lake di nuova generazione per l'analisi dei Big Data, è ora disponibile a livello generale, come è il connettore ADLS Gen2 per Azure Databricks. Siamo anche lieti di annunciare che ADLS Gen2 supporta Databricks Delta quando si eseguono cluster in Databricks Runtime 5.2 e versioni successive.
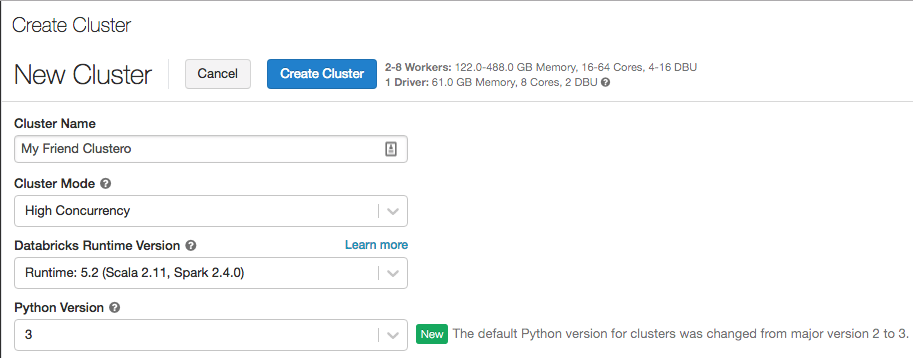
Python 3 ora è la versione predefinita quando si creano cluster
12-19 febbraio 2019: versione 2.91
La versione predefinita di Python per i cluster creati con l'interfaccia utente è passata da Python 2 a Python 3. L'impostazione predefinita per i cluster creati usando l'API REST è ancora Python 2.
I cluster esistenti non modificheranno le rispettive versioni di Python. Tuttavia, se si ha l'abitudine di prendere l'impostazione predefinita di Python 2 quando si creano nuovi cluster, è necessario iniziare a prestare attenzione alla selezione della versione di Python.
Delta Lake disponibile a livello generale
1 febbraio 2019
Ora tutti possono sfruttare i vantaggi del potente livello di archiviazione transazionale di Databricks Delta e delle letture super veloci: a partire dal 1° febbraio Delta Lake è disponibile a livello generale e disponibile in tutte le versioni supportate di Databricks Runtime. Per altre informazioni su Delta, vedere Che cos'è Delta Lake?.