Databricks Light
Importante
Questa documentazione è stata ritirata e potrebbe non essere aggiornata. Il prodotto, il servizio o la tecnologia citati in questo contenuto non sono più supportati. Vedere Databricks Light 2.4 supporto Extended (EoS).
Databricks Light è il packaging Databricks del runtime Apache Spark open source. Offre un'opzione di runtime per i processi che non richiedono i vantaggi in termini prestazioni avanzate, affidabilità o scalabilità automatica offerti da Databricks Runtime. In particolare, Databricks Light non supporta:
- Delta Lake
- Le funzionalità di Autopilot, ad esempio la scalabilità automatica
- I cluster con simultaneità elevata e per tutti gli scopi
- Notebook, dashboard e funzionalità di collaborazione
- Connettori a varie origini dati e strumenti BI
Databricks Light è un ambiente di runtime per i lavori (o "carichi di lavoro automatizzati"). I lavori eseguiti nei cluster di Databricks Light sono soggetti a prezzi di calcolo processi light. È possibile selezionare Databricks Light solo quando si crea o si pianifica un lavoro JAR, Python o spark-submit e si collega un cluster a tale lavoro. Non è possibile usare Databricks Light per eseguire lavori di notebook o carichi di lavoro interattivi.
Databricks Light può essere usato nella stessa area di lavoro con i cluster in esecuzione in altri Databricks Runtime e piani tariffari. Per le attività iniziali non è necessario richiedere un'area di lavoro separata.
Che cosa c'è in Databricks Light?
La pianificazione di rilascio del runtime di Databricks Light segue quella di Apache Spark. Qualsiasi versione di Databricks Light si basa su una versione specifica di Apache Spark. Per altre informazioni vedere le note sulla versione seguenti:
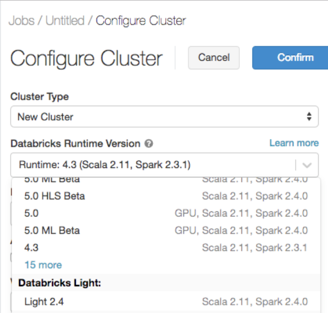
Creare un cluster usando Databricks Light
Quando si crea un cluster del lavoro, selezionare una versione light di Databricks dal menu a discesa della Versione di Databricks Runtime.
Importante
Il supporto per Databricks Light nei cluster di lavoro supportati dal pool è disponibile in Anteprima pubblica.