Che cosa significano gli intervalli di token al secondo nella capacità di throughput fornita?
Questo articolo descrive come e perché Databricks misura i token al secondo per i carichi di lavoro con throughput assegnato per le API del modello Foundation .
Le prestazioni per i modelli di linguaggio di grandi dimensioni vengono spesso misurate in termini di token al secondo. Quando si configura il modello di produzione che gestisce gli endpoint, è importante considerare il numero di richieste inviate dall'applicazione all'endpoint. In questo modo è possibile comprendere se l'endpoint deve essere configurato per la scalabilità in modo da non influire sulla latenza.
Quando si configurano gli intervalli di scalabilità orizzontale per gli endpoint distribuiti con velocità effettiva fornita, Databricks ha rilevato che è più semplice analizzare gli input destinati al sistema usando i token.
Che cosa sono i token?
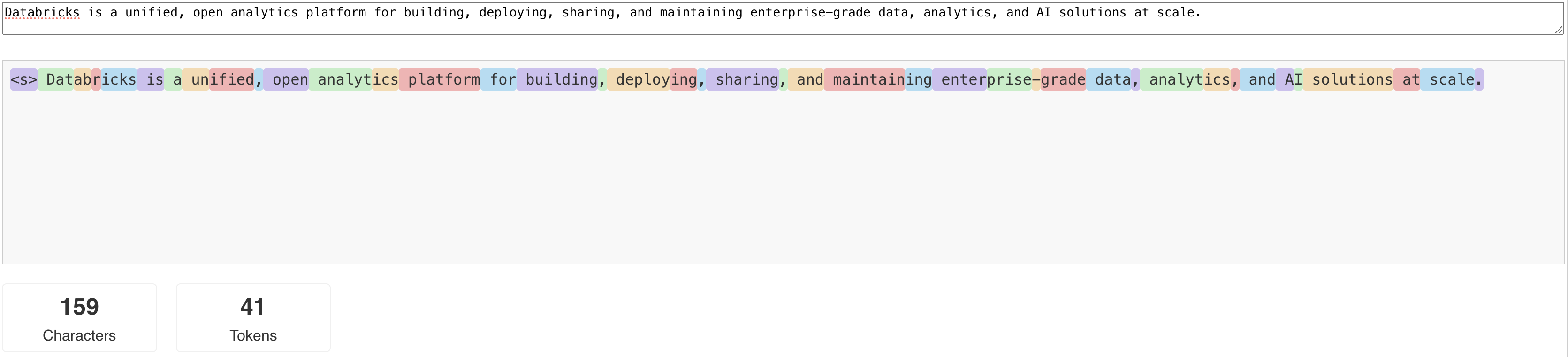
Llms legge e genera testo in termini di ciò che viene chiamato token . I token possono essere parole o parole secondarie e le regole esatte per la suddivisione del testo in token variano da modello a modello. Ad esempio, è possibile usare gli strumenti online per vedere come il tokenizer di Llama converte le parole in token.
Il diagramma seguente mostra un esempio di come il tokenizer Llama suddivide il testo:
Perché misurare le prestazioni LLM in termini di token al secondo?
Tradizionalmente, la gestione degli endpoint viene configurata in base al numero di richieste simultanee al secondo (RPS). Tuttavia, una richiesta di inferenza LLM richiede un tempo diverso a seconda del numero di token inseriti e del numero di token generati, il che può causare uno squilibrio tra le richieste. Pertanto, decidere quanto scalare l'endpoint richiede effettivamente la misurazione della scalabilità degli endpoint in termini di contenuto della richiesta: token.
Casi d'uso diversi presentano rapporti di input e token di output diversi:
- lunghezze variabili dei contesti di input: mentre alcune richieste potrebbero includere solo alcuni token di input, ad esempio una breve domanda, altre possono includere centinaia o persino migliaia di token, ad esempio un lungo documento per il riepilogo. Questa variabilità rende difficile la configurazione di un endpoint di gestione basato solo su RPS, perché non tiene conto delle diverse richieste di elaborazione delle diverse richieste.
- lunghezza variabile dell'output a seconda del caso d'uso: casi d'uso diversi per i moduli APM possono portare a lunghezze di token di output molto diverse. La generazione di token di output è la parte che richiede più tempo durante l'inferenza di un LLM, quindi ciò può influire notevolmente sul throughput. Ad esempio, il riepilogo implica risposte più brevi e incisive, mentre la generazione di testo, come la scrittura di articoli o descrizioni di prodotti, può produrre risposte molto più lunghe.
Come si seleziona l'intervallo di token al secondo per il mio endpoint?
Il throughput fornito degli endpoint è configurato attraverso un intervallo di token al secondo che è possibile inviare all'endpoint. L'endpoint scala verso l'alto e verso il basso per gestire il carico di lavoro dell'applicazione di produzione. I costi vengono addebitati all'ora in base all'intervallo di token al secondo a cui viene ridimensionato l'endpoint.
Il modo migliore per conoscere l'intervallo di token al secondo del tuo endpoint di servizio con throughput provvisto, adatto al tuo caso d'uso, consiste nell'eseguire un test di carico con un set di dati rappresentativo. Consulta Esegui il benchmarking personalizzato degli endpoint LLM.
Esistono due fattori importanti da considerare:
- In che modo Databricks misura le prestazioni in termini di token al secondo dell'LLM.
- Funzionamento della scalabilità automatica.
Come Databricks misura le prestazioni dei token al secondo di LLM
Databricks valuta gli endpoint rispetto a un carico di lavoro che rappresenta le attività di riepilogo comuni per i casi d'uso di generazione ottimizzati per il recupero. In particolare, il carico di lavoro è costituito da:
- 2048 token di input
- 256 token di output
Gli intervalli di token visualizzati combinano velocità effettiva dei token di input e output e, per impostazione predefinita, ottimizzano per il bilanciamento della velocità effettiva e della latenza.
I benchmark di Databricks indicano che gli utenti possono inviare simultaneamente un certo numero di token al secondo all'endpoint, con una dimensione batch di 1 per richiesta. In questo modo si simulano più richieste che colpiscono l'endpoint contemporaneamente, che rappresentano in modo più accurato il modo in cui si userebbe effettivamente l'endpoint nell'ambiente di produzione.
- Ad esempio, se un endpoint di throughput fornito ha un tasso fissato di 2304 token al secondo (2048 + 256), una singola richiesta con un input di 2048 token e un output previsto di 256 token si prevede che impieghi circa un secondo per essere eseguita.
- Analogamente, se la frequenza è impostata su 5600, ci si può aspettare che una singola richiesta, con il numero di token di input e output menzionato sopra, impieghi circa 0,5 secondi per l'esecuzione; vale a dire che l'endpoint può elaborare due richieste simili in circa un secondo.
Se il carico di lavoro varia da quello sopra indicato, ci si può aspettare che la latenza varierà rispetto al tasso di throughput provisionato elencato. Come indicato in precedenza, la generazione di più token di output richiede più tempo rispetto all'inclusione di più token di input. Se si esegue l'inferenza batch e si desidera stimare la quantità di tempo necessario per completare, è possibile calcolare il numero medio di token di input e di output e confrontare i carichi di lavoro del benchmark di Databricks sopra indicati.
- Ad esempio, se sono presenti 1000 righe, con un numero medio di token di input pari a 3000 e un numero medio di token di output pari a 500 e una velocità effettiva con provisioning di 3500 token al secondo, potrebbe essere necessario più lungo di 1000 secondi (un secondo per riga) a causa del numero medio di token maggiore rispetto al benchmark di Databricks.
- Analogamente, se si dispone di 1000 righe, un input medio di 1500 token, un output medio di 100 token e una velocità effettiva con provisioning di 1600 token al secondo, potrebbe essere necessario meno di 1000 secondi totali (un secondo per riga) a causa del numero medio di token meno rispetto al benchmark di Databricks.
Per stimare il throughput provisionato ideale necessario per completare il lavoro di inferenza batch, è possibile usare il notebook nella eseguire l'inferenza LLM batch usando ai_query
Funzionamento della scalabilità automatica
Model Serving offre un sistema di scalabilità automatica rapida che ridimensiona il calcolo sottostante per soddisfare le richieste di token al secondo dell'applicazione. Databricks scala la velocità effettiva fornita in blocchi di token al secondo, quindi vieni addebitato per unità aggiuntive di velocità effettiva fornita soltanto quando le utilizzi.
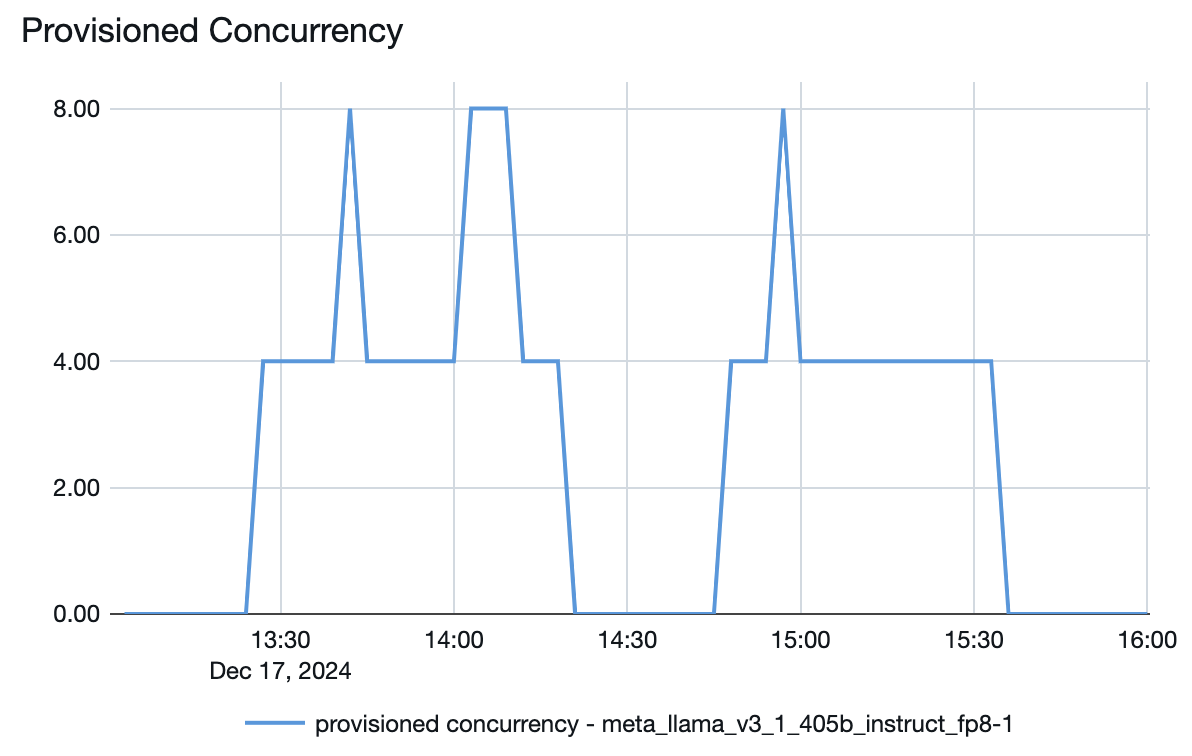
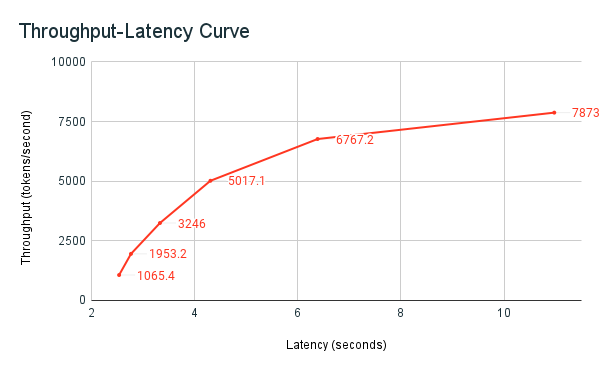
Il grafico della latenza del throughput seguente mostra un endpoint di throughput con provisioning testato con un numero crescente di richieste parallele. Il primo punto rappresenta 1 richiesta, la seconda, 2 richieste parallele, la terza, 4 richieste parallele e così via. Man mano che il numero di richieste aumenta e di conseguenza la domanda di token al secondo, si può osservare che anche il throughput fornito aumenta. Questo aumento indica che la scalabilità automatica aumenta il calcolo disponibile. Tuttavia, si potrebbe iniziare a vedere che il throughput inizia a stabilizzarsi, raggiungendo un limite di circa 8000 token al secondo man mano che vengono effettuate più richieste parallele. La latenza totale aumenta man mano che più richieste devono attendere in coda prima di essere elaborate perché il calcolo allocato viene usato contemporaneamente.
Nota
È possibile mantenere la velocità effettiva coerente disattivando la scalabilità a zero e configurando una velocità effettiva minima nell'endpoint di gestione. In questo modo si evita la necessità di attendere l'aumento delle prestazioni dell'endpoint.
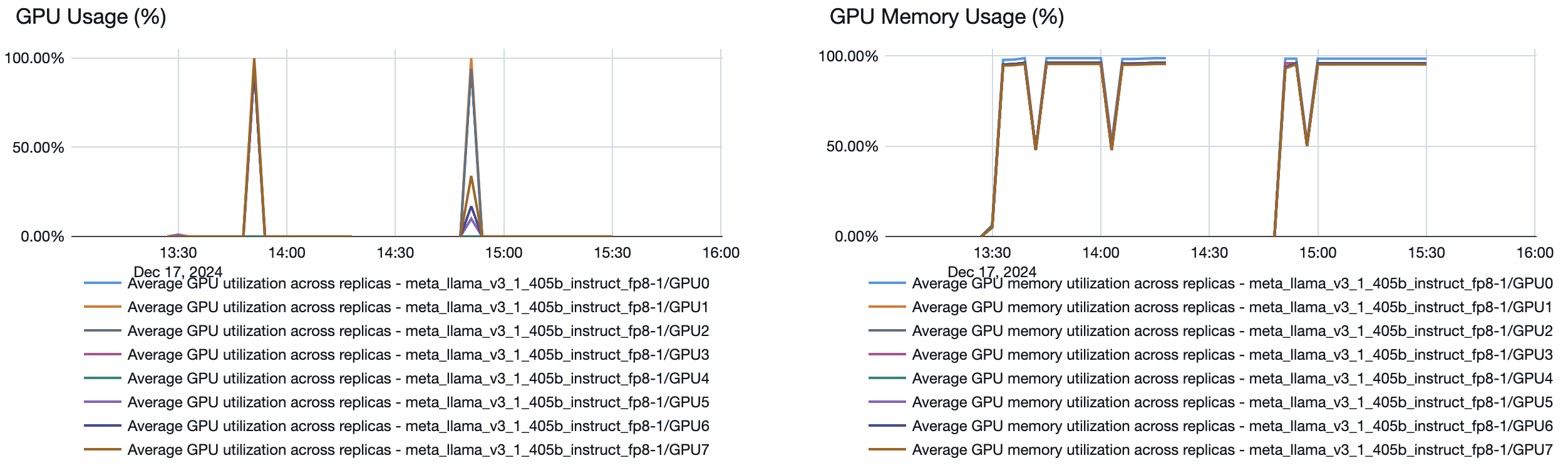
È anche possibile vedere dal modello che gestisce l'endpoint come vengono attivate o disattivate le risorse a seconda della domanda: