Esegui il benchmarking del tuo endpoint LLM
Questo articolo fornisce un esempio di notebook consigliato di Databricks per il benchmarking di un endpoint LLM. Comprende anche una breve introduzione al modo in cui Databricks esegue l'inferenza LLM e calcola la latenza e il throughput come metriche delle performance degli endpoint.
L'inferenza LLM su Databricks misura i token al secondo nella modalità di throughput provisionato per le API del Modello Foundation. Consulta Cosa significano gli intervalli di token al secondo nel throughput di provisioning?.
Esempio di notebook di benchmarking
È possibile importare il notebook seguente nell'ambiente Databricks e specificare il nome dell'endpoint LLM per eseguire un test di carico.
Valutazione delle prestazioni di un endpoint LLM
Prendere notebook
introduzione all'inferenza LLM
Il LLMs eseguono l'inferenza in un processo in due passaggi:
- Prefill, in cui i token del prompt di input vengono elaborati in parallelo.
- decodifica, dove il testo viene generato un token alla volta in modo regreditivo automatico. Ogni token generato viene aggiunto all'input e restituito al modello per generare il token successivo. La generazione si arresta quando l'LLM restituisce un token di arresto speciale o quando viene soddisfatta una condizione definita dall'utente.
La maggior parte delle applicazioni di produzione ha un budget di latenza e Databricks consiglia di ottimizzare la velocità effettiva in base al budget di latenza.
- Il numero di token di input ha un impatto significativo sulla memoria necessaria per elaborare le richieste.
- Il numero di token generati nell'output domina la latenza complessiva della risposta.
Databricks divide l'inferenza LLM nelle metriche secondarie seguenti:
- Time to first token (TTFT): questo rappresenta la rapidità con cui gli utenti iniziano a visualizzare l'output del modello dopo aver immesso la query. I tempi di attesa ridotti per una risposta sono essenziali nelle interazioni in tempo reale, ma meno importanti nei carichi di lavoro offline. Questa metrica è basata sul tempo necessario per elaborare la richiesta e quindi generare il primo token di output.
- Tempo per Token di Output (TPOT): Tempo per generare un token di output per ogni utente che interroga il sistema. Questa metrica corrisponde al modo in cui ogni utente percepisce la "velocità" del modello. Ad esempio, un TPOT di 100 millisecondi per token corrisponderebbe a 10 token al secondo o circa 450 parole al minuto, che è più veloce di quanto una persona tipica possa leggere.
In base a queste metriche, la latenza totale e la velocità effettiva possono essere definite come segue:
- latenza = TTFT + (TPOT) * (numero di token da generare)
- Larghezza di banda = numero di token di output al secondo per tutte le richieste simultanee
Su Databricks, gli endpoint di servizio LLM sono in grado di adattarsi al carico inviato dai client con più richieste simultanee. Esiste un compromesso tra latenza e velocità effettiva. Ciò è dovuto al fatto che, in LLM che gestisce gli endpoint, le richieste simultanee possono essere e vengono elaborate contemporaneamente. In caso di bassi carichi di richieste simultanee, la latenza è la più bassa possibile. Tuttavia, se si aumenta il carico della richiesta, la latenza potrebbe aumentare, ma anche la velocità effettiva aumenta. Ciò è dovuto al fatto che due richieste con un valore di token per secondo possono essere elaborate in meno del doppio del tempo.
Di conseguenza, il controllo del numero di richieste parallele nel sistema è fondamentale per bilanciare la latenza con la velocità effettiva. Se si ha un caso d'uso a bassa latenza, si vuole inviare meno richieste simultanee all'endpoint per mantenere bassa la latenza. Se si ha un caso d'uso con velocità effettiva elevata, si vuole saturare l'endpoint con molte richieste di concorrenza, poiché vale la pena una velocità effettiva più elevata anche a scapito della latenza.
- I casi d'uso con velocità effettiva elevata possono includere inferenze batch e altre attività non rivolte all'utente.
- I casi d'uso a bassa latenza possono includere applicazioni in tempo reale che richiedono risposte immediate.
Databricks benchmarking harness
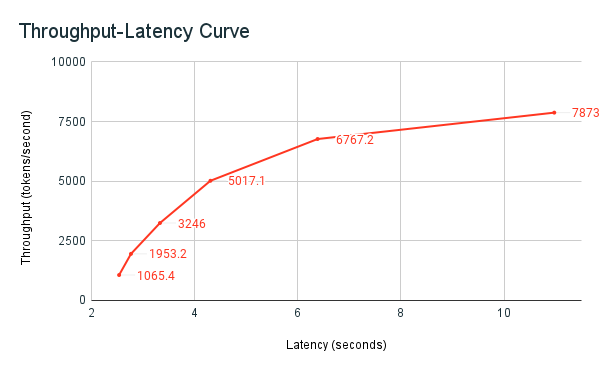
Il notebook di esempio di benchmarking , precedentemente condiviso, è l'harness di benchmarking di Databricks. Il notebook visualizza il totale latenza tra tutte le richieste e le metriche di velocità effettiva e traccia la curva di velocità effettiva rispetto alla curva di latenza tra diversi numeri di richieste parallele. La strategia di scalabilità automatica degli endpoint di Databricks bilancia la latenza e la velocità effettiva. Nel notebook, si osserva che la latenza e il throughput aumentano al crescere del numero di utenti simultanei che eseguono query sull'endpoint.
Tuttavia, si inizia anche a vedere che quando il numero di richieste parallele aumenta, la velocità effettiva inizia a stabilizzarsi, raggiungendo un limite di circa 8000 token al secondo. Questo plateau delle prestazioni si verifica perché la velocità di throughput provisionata per l'endpoint limita il numero di lavoratori e le richieste parallele che è possibile effettuare. Man mano che vengono effettuate più richieste oltre a ciò che l'endpoint può gestire contemporaneamente, la latenza totale continua ad aumentare man mano che le richieste aggiuntive attendono nella coda.
Altri dettagli sulla filosofia di Databricks in merito al benchmarking delle prestazioni LLM sono descritti nel blog LLM Inference Performance Engineering: Best Practices.