Funzionalità di calcolo su richiesta utilizzando funzioni definite dall'utente Python
Questo articolo descrive come creare e utilizzare funzionalità su richiesta in Azure Databricks.
Per usare le funzionalità su richiesta, l'area di lavoro deve essere abilitata per Unity Catalog ed è necessario usare Databricks Runtime 13.3 LTS ML o versione successiva.
Che cosa sono le funzionalità “on demand”?
"On demand" si riferisce alle funzionalità i cui valori non sono noti in anticipo, ma vengono calcolati al momento dell'inferenza. In Azure Databricks si usano funzioni definite dall'utente Python per specificare come calcolare le funzionalità on demand. Queste funzioni sono regolate dal Unity Catalog e individuabili tramite Catalog Explorer .
Requisiti
- Per usare una funzione definita dall'utente per creare un set di training o per creare un endpoint Feature Serving, è necessario disporre del privilegio
USE CATALOGper il catalogosystemin Unity Catalog.
Workflow
Per calcolare le caratteristiche su richiesta, si specifica una funzione definita dall'utente in Python che descrive come calcolare i valori delle caratteristiche.
- Durante il training, questa funzione e le relative associazioni di input vengono fornite nel parametro
feature_lookupsdell'APIcreate_training_set. - È necessario registrare il modello sottoposto a training usando il metodo
log_modeldi Feature Store . In questo modo il modello valuta automaticamente le funzionalità su richiesta quando viene usato per l'inferenza. - Per l'assegnazione dei punteggi in batch, l'API
score_batchcalcola e restituisce automaticamente tutti i valori delle funzionalità, incluse le funzionalità su richiesta. - Quando si gestisce un modello con Mosaic AI Model Serving, il modello usa automaticamente la funzione definita dall'utente Python per calcolare le funzionalità on demand per ogni richiesta di assegnazione dei punteggi.
Creare una funzione definita dall’utente di Python
Si può creare una funzione definita dall'utente Python in un notebook o in Databricks SQL.
Ad esempio, l'esecuzione del codice seguente in una cella del notebook crea l'UDF Python example_feature nel catalogo main e nello schema default.
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Dopo aver eseguito il codice, è possibile spostarsi nello spazio dei nomi a tre livelli in Esplora cataloghi per visualizzare la definizione della funzione:
funzione 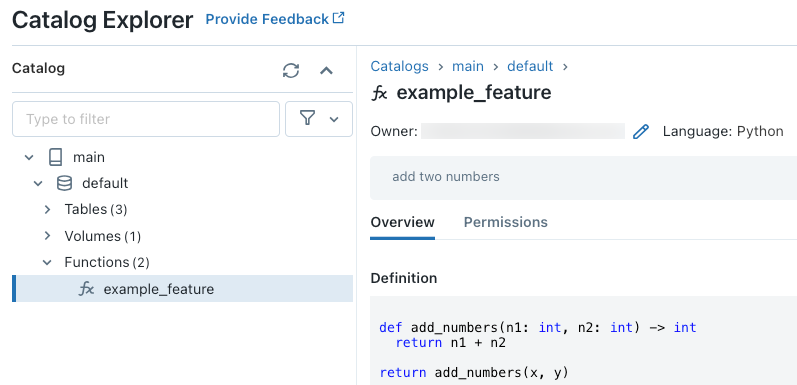
Per ulteriori dettagli sulla creazione di UDF Python, consultare Registrare una UDF Python in Unity Catalog e il manuale del linguaggio SQL.
Come gestire i valori delle funzionalità mancanti
Quando una funzione definita dall'utente Python dipende dal risultato di un FeatureLookup, il valore restituito se la chiave di ricerca richiesta non viene trovata dipende dall'ambiente. Quando si usa score_batch, il valore restituito è None. Quando si usa la gestione online, il valore restituito è float("nan").
Il seguente codice è un esempio di come gestire entrambi i casi.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Eseguire il training di un modello usando funzionalità on demand
Per eseguire il training del modello, usare un oggetto FeatureFunction, che viene passato all'API create_training_set nel parametro feature_lookups.
Il seguente codice di esempio usa la funzione main.default.example_feature definita dall'utente Python della sezione precedente.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Registrare il modello e iscriverlo in Unity Catalog
I modelli in pacchetto con metadati delle funzionalità possono essere registrati in Unity Catalog. Le tabelle delle funzionalità usate per creare il modello devono essere archiviate nel catalogo unity.
Per assicurarsi che il modello valuti automaticamente le funzionalità su richiesta quando viene usato per l'inferenza, è necessario impostare l'URI del Registro di sistema e quindi registrare il modello, come indicato di seguito:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Se la funzione definita dall'utente Python che definisce le funzionalità su richiesta importa tutti i pacchetti Python, è necessario specificare i pacchetti usando l'argomento extra_pip_requirements. Ad esempio:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Limitazione
Le funzionalità on demand possono restituire tutti i tipi di dati supportati da Feature Store, ad eccezione di MapType e ArrayType.
Esempi di notebook: funzionalità on demand
Il seguente notebook illustra un esempio di come eseguire il training e assegnare un punteggio a un modello che usa una funzionalità on demand.
Notebook demo delle funzionalità on demand di base
Ottieni notebook
Il seguente notebook illustra un esempio di modello di raccomandazione di un ristorante. La posizione del ristorante viene ricavata da una tabella online di Databricks. La posizione corrente dell'utente viene inviata come parte della richiesta di assegnazione dei punteggi. Il modello usa una funzionalità on demand per calcolare la distanza in tempo reale dall'utente al ristorante. La distanza viene poi usata come input per il modello.
Funzionalità di raccomandazione per i ristoranti a richiesta con il notebook dimostrativo delle tabelle online
Ottieni notebook