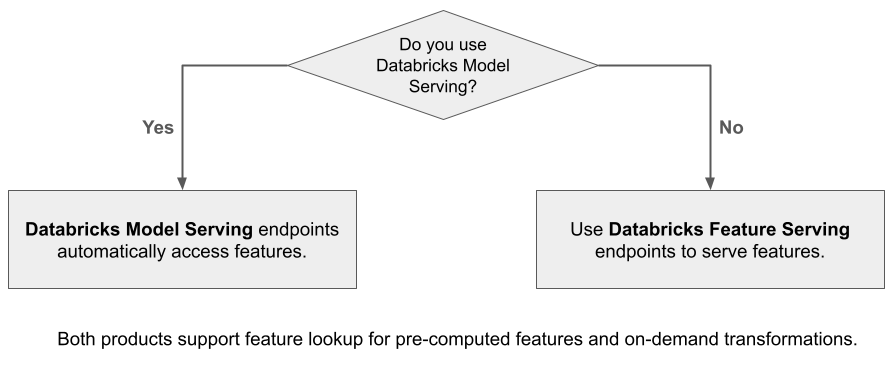
Che cos'è Databricks Feature Serving?
Databricks Feature Serving rende disponibili i dati nella piattaforma Databricks per i modelli o le applicazioni distribuite all'esterno di Azure Databricks. Gli endpoint di gestione delle funzionalità vengono ridimensionati automaticamente per adattarsi al traffico in tempo reale e fornire un servizio a disponibilità elevata e a bassa latenza per la gestione delle funzionalità. Questa pagina descrive come configurare e utilizzare il servizio di funzionalità. Per un'esercitazione dettagliata, vedere Distribuire ed eseguire query su un endpoint di gestione delle funzionalità.
Quando si usa Mosaic AI Model Serving per gestire un modello creato usando le funzionalità di Databricks, il modello cerca e trasforma automaticamente le funzionalità per le richieste di inferenza. Con Databricks Feature Serving è possibile gestire dati strutturati per il recupero di applicazioni di generazione aumentata (RAG) e funzionalità necessarie per altre applicazioni, ad esempio modelli serviti all'esterno di Databricks o qualsiasi altra applicazione che richiede funzionalità basate sui dati in Unity Catalog.
Perché usare Feature Serving?
Databricks Feature Serving offre una singola interfaccia che fornisce funzionalità pre-materializzate e su richiesta. Comprende anche i seguenti vantaggi:
- Semplicità. Databricks gestisce l'infrastruttura. Con una singola chiamata API, Databricks crea un ambiente di gestione pronto per la produzione.
- Disponibilità elevata e scalabilità. Gli endpoint di gestione delle funzionalità aumentano e si riducendo automaticamente per adattarsi al volume di richieste di gestione.
- Protezione. Gli endpoint vengono distribuiti in un limite di rete sicuro e usano calcolo dedicato che termina quando l'endpoint viene eliminato o ridimensionato su zero.
Requisiti
- Databricks Runtime 14.2 ML o versione successiva.
- Per usare l'API Python, Feature Serving richiede la versione
databricks-feature-engineering0.1.2 o successiva, integrata in Databricks Runtime 14.2 ML. Per le versioni precedenti di Databricks Runtime ML, installare manualmente la versione richiesta usando%pip install databricks-feature-engineering>=0.1.2. Se si usa un notebook di Databricks, è necessario riavviare il kernel Python eseguendo questo comando in una nuova cella:dbutils.library.restartPython(). - Per usare Databricks SDK, Feature Serving richiede la versione
databricks-sdk0.18.0 o successiva. Per installare manualmente la versione richiesta, usare%pip install databricks-sdk>=0.18.0. Se si usa un notebook di Databricks, è necessario riavviare il kernel Python eseguendo questo comando in una nuova cella:dbutils.library.restartPython().
Databricks Feature Serving offre un'interfaccia utente e diverse opzioni a livello di codice per la creazione, l'aggiornamento, l'esecuzione di query e l'eliminazione di endpoint. Questo articolo include istruzioni per ognuna delle opzioni seguenti:
- Interfaccia utente Databricks
- REST API
- API Python
- SDK Databricks
Per usare l'API REST o MLflow Deployments SDK, è necessario disporre di un token API databricks.
Importante
Come buona prassi di sicurezza per scenari di produzione, Databricks consiglia di utilizzare token OAuth da macchina a macchina per l'autenticazione durante la produzione.
Per il test e lo sviluppo, Databricks consiglia di usare un token di accesso personale appartenente alle entità servizio anziché agli utenti dell'area di lavoro. Per creare token per le entità servizio, vedere Gestire i token per un'entità servizio.
Autenticazione per la gestione delle funzionalità
Per informazioni sull'autenticazione, vedere Autorizzazione dell'accesso alle risorse di Azure Databricks.
Creare un FeatureSpec
Un FeatureSpec è un set definito dall'utente di funzionalità e funzioni. È possibile combinare funzionalità e funzioni in un oggetto FeatureSpec.
FeatureSpecs vengono archiviati e gestiti dal Catalogo Unity e visualizzati in Esplora Cataloghi.
Le tabelle specificate in un FeatureSpec devono essere pubblicate in una tabella online o in un archivio online di terze parti. Vedi Utilizza tabelle online per la gestione delle funzionalità in tempo reale o negozi online di terze parti.
È necessario usare il pacchetto databricks-feature-engineering per creare un oggetto FeatureSpec.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates a - b.
input_bindings={"a": "ytd_spend", "b": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Creare un endpoint
FeatureSpec definisce l'endpoint. Per altre informazioni, vedere Creare endpoint personalizzati per la gestione di modelli, la documentazione dell'API Python o la documentazione di Databricks SDK.
Nota
Per i carichi di lavoro sensibili alla latenza o che richiedono query elevate al secondo, Model Serving offre l'ottimizzazione della route sugli endpoint personalizzati che servono i modelli, vedere Configurare l'ottimizzazione della route per la gestione degli endpoint.
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
SDK Databricks - Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
API Python
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
Per visualizzare l'endpoint, fare clic su Servizio nella barra laterale sinistra dell'interfaccia utente di Databricks. Quando lo stato è Pronto, l'endpoint è pronto per rispondere alle query. Per altre informazioni su Mosaic AI Model Serving, vedere Mosaic AI Model Serving.
Ottenere un endpoint
È possibile usare Databricks SDK o l'API Python per ottenere i metadati e lo stato di un endpoint.
SDK Databricks - Python
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
API Python
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Ottenere lo schema di un endpoint
È possibile usare l'API REST per ottenere lo schema di un endpoint. Per altre informazioni sullo schema dell'endpoint, vedere Ottenere uno schema dell'endpoint che gestisce un modello.
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Eseguire una query su un endpoint
È possibile usare l'API REST, MLflow Deployments SDK o l'interfaccia utente di gestione per eseguire query su un endpoint.
Il codice seguente illustra come configurare le credenziali e creare il client quando si usa MLflow Deployments SDK.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Nota
Come procedura consigliata per la sicurezza, quando si esegue l'autenticazione con strumenti automatizzati, sistemi, script e app, Databricks consiglia di usare token di accesso personali appartenenti alle entità servizio, anziché agli utenti dell'area di lavoro. Per creare token per le entità servizio, vedere Gestire i token per un'entità servizio.
Eseguire query su un endpoint usando le API
Questa sezione include esempi di esecuzione di query su un endpoint usando l'API REST o MLflow Deployments SDK.
REST API
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
MLflow Deployments SDK
Importante
Il seguente esempio usa l'API predict() di MLflow Implementazioni SDK. Questa API è Sperimentale e la definizione dell'API potrebbe cambiare.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
Eseguire query su un endpoint usando l'interfaccia utente
È possibile eseguire una query su un endpoint di servizio direttamente dall'interfaccia utente Di servizio. L'interfaccia utente include esempi di codice generati che è possibile usare per eseguire query sull'endpoint.
Nella barra laterale sinistra dell'area di lavoro di Databricks fare clic su Servizio.
Fare clic sull'endpoint su cui eseguire la query.
In alto a destra della schermata fare clic su Query per endpoint.
Nella casella Richiesta digitare il corpo della richiesta in formato JSON.
Fare clic su Invia richiesta.
// Example of a request body.
{
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]
}
La finestra di dialogo Query per endpoint include codice di esempio generato in curl, Python e SQL. Fare clic sulla scheda e copiare il codice di esempio.
Per copiare il codice, fare clic sull'icona di copia in alto a destra della casella di testo.
Aggiornare un endpoint
È possibile aggiornare un endpoint usando l'API REST, Databricks SDK o l'interfaccia utente di gestione.
Aggiornare un endpoint usando le API
REST API
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
SDK Databricks - Python
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
Aggiornare un endpoint usando l'interfaccia utente
Per usare l’interfaccia utente di servizio, seguire questa procedura:
- Nella barra laterale sinistra dell'area di lavoro di Databricks fare clic su Servizio.
- Nella tabella fare clic sul nome dell'endpoint da aggiornare. Viene visualizzata la schermata dell'endpoint.
- In alto a destra della schermata fare clic su Modifica endpoint.
- Nella finestra di dialogo Modifica endpoint di gestione modificare le impostazioni dell'endpoint in base alle esigenze.
- Fare clic su Aggiorna per salvare le modifiche.

Eliminare un endpoint
Avviso
Questa azione è irreversibile.
È possibile eliminare un endpoint usando l'API REST, Databricks SDK, l'API Python o l'interfaccia utente di gestione.
Eliminare un endpoint usando le API
REST API
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
SDK Databricks - Python
workspace.serving_endpoints.delete(name="customer-features")
API Python
fe.delete_feature_serving_endpoint(name="customer-features")
Eliminare un endpoint usando l'interfaccia utente
Seguire questa procedura per eliminare un endpoint usando l'interfaccia utente di gestione:
- Nella barra laterale sinistra dell'area di lavoro di Databricks fare clic su Servizio.
- Nella tabella fare clic sul nome dell'endpoint da eliminare. Viene visualizzata la schermata dell'endpoint.
- Nello schermo in alto a destra, fare clic sul Menu Kebab
 e selezionare Elimina.
e selezionare Elimina.

Monitorare l'integrità di un endpoint
Per informazioni sui log e le metriche disponibili per gli endpoint di gestione delle funzionalità, vedere Monitorare la qualità del modello e l'integrità degli endpoint.
Controllo di accesso
Per informazioni sulle autorizzazioni per gli endpoint di gestione delle funzionalità, vedere Gestire le autorizzazioni per l'endpoint di gestione del modello.
Notebook di esempio
Questo notebook illustra come usare Databricks SDK per creare un endpoint di gestione delle funzionalità usando tabelle online di Databricks.
Notebook di esempio per il servizio di funzionalità con tabelle online
Prendi notebook