Esegui il tuo processo di Azure Databricks con calcolo serverless per i workflow.
Il calcolo serverless per i flussi di lavoro consente di eseguire il processo di Azure Databricks senza configurare e distribuire l’infrastruttura. Con il calcolo serverless, ci si concentra sull'implementazione delle pipeline di elaborazione e analisi dei dati, mentre Databricks gestisce in modo efficiente le risorse di calcolo, tra cui l'ottimizzazione e il ridimensionamento del calcolo per i carichi di lavoro. La scalabilità automatica e Photon vengono abilitate automaticamente per le risorse di calcolo che eseguono il processo.
Il calcolo serverless per i flussi di lavoro ottimizza automaticamente e continuamente l'infrastruttura, ad esempio i tipi di istanza, la memoria e i motori di elaborazione, per garantire prestazioni ottimali in base ai requisiti di elaborazione specifici dei carichi di lavoro.
Databricks aggiorna automaticamente la versione di Databricks Runtime per supportare miglioramenti e aggiornamenti alla piattaforma garantendo al tempo stesso la stabilità dei processi di Azure Databricks. Per visualizzare la versione corrente di Databricks Runtime utilizzata dal calcolo serverless per i flussi di lavoro, vedere Note sulla versione di calcolo serverless.
Poiché non è necessaria l'autorizzazione di creazione del cluster, tutti gli utenti dell'area di lavoro possono usare il calcolo serverless per eseguire i flussi di lavoro.
Questo articolo descrive l'uso dell'interfaccia utente dei processi di Azure Databricks per creare ed eseguire processi che usano calcolo serverless. È anche possibile automatizzare la creazione e l'esecuzione di processi che usano il calcolo serverless con l'API Processi, i bundle di asset di Databricks e Databricks SDK per Python.
- Per informazioni sull'uso dell'API Processi per creare ed eseguire processi che usano calcoli serverless, vedere Processi nelle informazioni di riferimento sull'API REST.
- Per informazioni sull'uso dei bundle di asset di Databricks per creare ed eseguire processi che usano il calcolo serverless, vedere Sviluppare un processo in Azure Databricks usando i bundle di asset di Databricks.
- Per informazioni sull'uso di Databricks SDK per Python per creare ed eseguire processi che usano calcolo serverless, vedere Databricks SDK per Python.
Requisiti
- L'area di lavoro Azure Databricks deve avere Unity Catalog abilitato.
- Poiché l'elaborazione serverless per i flussi di lavoro utilizza la modalità di accesso standard , i carichi di lavoro devono supportare questa modalità di accesso.
- L'area di lavoro di Databricks deve trovarsi in un'area supportata. Vedi Funzionalità con disponibilità regionale limitata.
- L'account Azure Databricks deve avere un ambiente di calcolo serverless abilitato. Consultare la sezione Abilitare l’elaborazione serverless.
Creare un lavoro utilizzando l'elaborazione serverless
Nota
Poiché il calcolo serverless per i flussi di lavoro garantisce che venga effettuato il provisioning di risorse sufficienti per eseguire i carichi di lavoro, è possibile che si verifichi un aumento dei tempi di avvio quando si esegue un processo di Azure Databricks che richiede grandi quantità di memoria o include molte attività.
Il calcolo serverless è supportato con attività di tipo notebook, script Python, dbt e Python wheel. Per impostazione predefinita, il calcolo serverless viene selezionato come tipo di calcolo quando si crea un nuovo processo e si aggiunge uno di questi tipi di attività supportati.
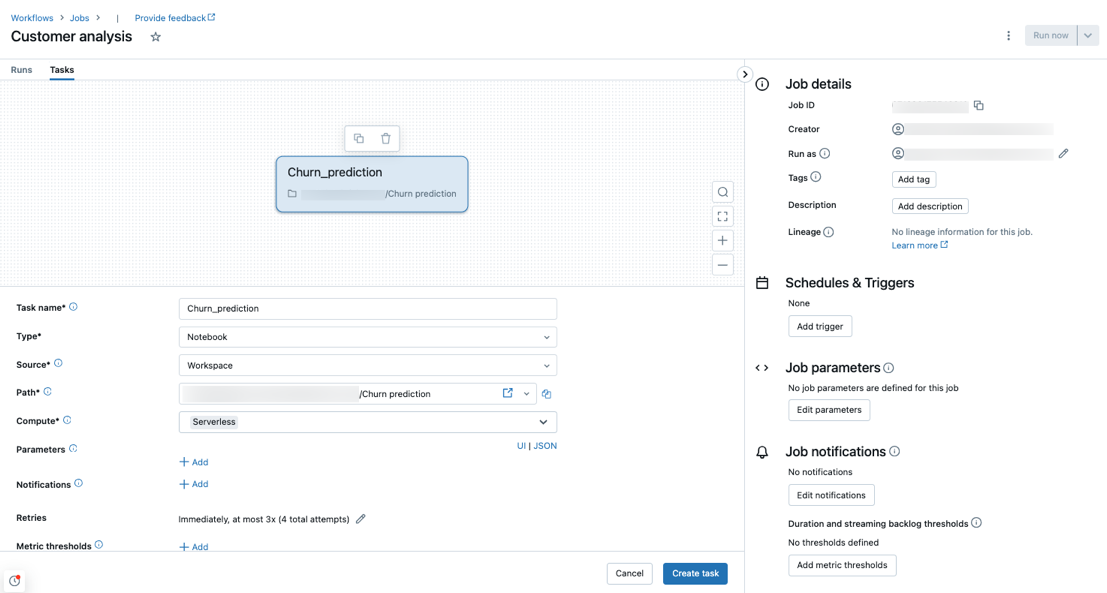
Databricks consiglia di usare l'elaborazione serverless per tutte le attività del lavoro. È anche possibile specificare tipi di calcolo diversi per i task in un processo, che potrebbero essere necessarie se un tipo di attività non è supportato dall'elaborazione serverless per i flussi di lavoro.
Per gestire le connessioni di rete in uscita per i lavori, vedere Che cos'è il controllo del traffico in uscita serverless?
Configurare un processo esistente per utilizzare il calcolo serverless
È possibile modificare un processo esistente per utilizzare l'elaborazione serverless per i compiti supportati quando si modifica il processo. Per passare all'elaborazione serverless, segui una di queste operazioni:
- Nel pannello laterale Dettagli del processo cliccare Scambia in Calcolo, cliccare Nuovo, immettere o aggiornare le impostazioni e cliccare Aggiorna.
- Cliccare
 nel menu a discesa Compute e selezionare Serverless.
nel menu a discesa Compute e selezionare Serverless.

Programmare un notebook usando l'elaborazione serverless
Oltre a usare l'interfaccia utente Processi per creare e pianificare un processo usando il calcolo serverless, è possibile creare ed eseguire un processo che usa l'elaborazione serverless direttamente da un notebook di Databricks. Vedere Creare e gestire processi di notebook pianificati.
Seleziona un criterio di budget per l'utilizzo serverless
Importante
Questa funzionalità è disponibile in anteprima pubblica.
I criteri di budget consentono all'organizzazione di applicare tag personalizzati all'utilizzo serverless per l'attribuzione granulare della fatturazione.
Se l'area di lavoro utilizza politiche di budget per attribuire l'uso serverless, puoi selezionare la politica di budget del tuo lavoro usando l'impostazione Politica di budget nell'interfaccia utente dei dettagli del lavoro. Se si è assegnati solo a una politica di budget, la politica viene selezionata automaticamente per i nuovi incarichi.
Nota
Dopo che ti è stato assegnato un criterio di budget, i processi esistenti non vengono contrassegnati automaticamente con il tuo criterio. È necessario aggiornare manualmente i processi esistenti se si desidera associare una politica.
Per ulteriori informazioni sui criteri di budget, vedere Attribuire l'utilizzo serverless con i criteri di budget.
Impostare i parametri di configurazione Spark
Per automatizzare la configurazione di Spark nell'elaborazione serverless, Databricks consente di impostare solo parametri di configurazione Spark specifici. Per l'elenco dei parametri consentiti, vedere Parametri di configurazione di Spark supportati.
È possibile impostare i parametri di configurazione di Spark solo a livello di sessione. A tale scopo, impostali in un notebook e aggiungi il notebook a un'attività inclusa nel medesimo incarico che usa i parametri. Vedere Ottenere e impostare le proprietà di configurazione di Apache Spark in un notebook.
Configurare ambienti e dipendenze
Per sapere come installare librerie e dipendenze utilizzando il calcolo serverless, consulta Installa le dipendenze del notebook.
Configurare memoria elevata per le attività del notebook
Importante
Questa funzionalità è disponibile in anteprima pubblica.
È possibile configurare le attività del notebook per usare una dimensione di memoria superiore. Per fare ciò, configurare l'impostazione memoria nel pannello laterale dell'ambiente del notebook. Vedi Configura memoria elevata per i carichi di lavoro serverless.
Memoria elevata è disponibile solo per i tipi di attività notebook.
Configurare l'ottimizzazione automatica dell'elaborazione serverless per impedire le ripetizioni
L'elaborazione serverless per l'ottimizzazione automatica dei flussi di lavoro ottimizza automaticamente l'ambiente di calcolo usato per eseguire i processi e ritenta di eseguire i task non riusciti. L'ottimizzazione automatica è abilitata per impostazione predefinita e Databricks consiglia di lasciare abilitata per garantire che i carichi di lavoro critici vengano eseguiti correttamente almeno una volta. Tuttavia, se si dispone di carichi di lavoro che devono essere eseguiti contemporaneamente, ad esempio processi che non sono idempotenti, è possibile disattivare l'ottimizzazione automatica durante l'aggiunta o la modifica di un task:
- Accanto a Nuovi tentativi, cliccare Aggiungi (o
 se esiste già un criterio di ripetizione dei tentativi).
se esiste già un criterio di ripetizione dei tentativi). - Nella finestra di dialogo dei Criteri di ripetizione, deselezionare Abilita ottimizzazione automatica senza server (potrebbe includere tentativi aggiuntivi).
- Cliccare Conferma.
- Se si sta aggiungendo un task, cliccare Crea task. Se si sta modificando un task, cliccare Salva task.
Monitorare il costo delle attività che usano l'elaborazione serverless per flussi di lavoro
È possibile monitorare il costo dei processi che usano l'elaborazione serverless per i flussi di lavoro eseguendo una query sulla tabella del sistema di utilizzo fatturabile. Questa tabella viene aggiornata per includere attributi dell’utente e del carico di lavoro relativi ai costi serverless. Consultare Informazioni di riferimento sulla tabella del sistema di utilizzo fatturabile.
Per informazioni sui prezzi correnti e sulle promozioni, vedere la pagina dei prezzi dei flussi di lavoro.
Visualizzare i dettagli delle query per l'esecuzione dei processi
È possibile visualizzare informazioni dettagliate sul runtime per le istruzioni Spark, ad esempio metriche e piani di query.
Per accedere ai dettagli delle query dall'interfaccia utente dei processi, seguire questa procedura:
Cliccare
 Flussi di lavoro nella barra laterale.
Flussi di lavoro nella barra laterale.Clicca sul nome del lavoro che vuoi visualizzare.
Fare clic sull'esecuzione specifica che si desidera visualizzare.
Fare clic su Sequenza temporale per visualizzare l'esecuzione come sequenza temporale, suddivisa in singole attività.
Fare clic sulla freccia accanto al nome dell'attività per visualizzare le istruzioni di query e i relativi runtime.
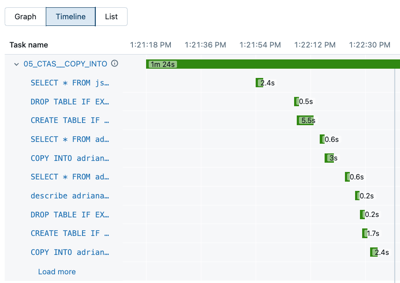
Fare clic su un'istruzione per aprire il pannello dei dettagli della query. Per altre informazioni sulle informazioni disponibili in questo pannello, vedere Visualizzare i dettagli delle query.
Per visualizzare la cronologia delle query per un'attività:
- Nella sezione Calcolo del pannello laterale Esecuzione task, fare clic su Cronologia query.
- Vieni reindirizzato alla Cronologia delle query, prefiltrata in base all'ID di esecuzione dell'attività in cui eri coinvolto.
Per informazioni sull'uso della cronologia delle query, consulta Cronologia delle query di accesso per le pipeline DLT e Cronologia delle query.
Limiti
Per un elenco delle limitazioni del calcolo serverless per i flussi di lavoro, vedere Limitazioni dell'elaborazione serverless nelle note sulla versione dell'elaborazione serverless.