Calcolo serverless per notebook
Questo articolo illustra come usare il calcolo serverless per i notebook. Per informazioni sull'uso del calcolo serverless per i processi, vedere Eseguire il processo di Azure Databricks con calcolo serverless per i flussi di lavoro.
Per informazioni sui prezzi, vedere Prezzi di Databricks.
Requisiti
- L'area di lavoro deve essere abilitata per Unity Catalog.
- L’area di lavoro si trova in una regione supportata. Vedere Aree di Azure Databricks.
- L'account deve essere abilitato per il calcolo serverless. Consultare la sezione Abilitare l’elaborazione serverless.
Collegare un notebook a un ambiente di calcolo serverless
Se l'area di lavoro è abilitata per il calcolo serverless interattivo per i notebook, tutti gli utenti dell'area di lavoro hanno accesso al calcolo serverless per i notebook. Non sono necessarie autorizzazioni aggiuntive.
Per connettersi all'ambiente di calcolo serverless, fare clic sul menu a discesa Connetti nel notebook e selezionare Serverless. Per i nuovi notebook, per impostazione predefinita il calcolo collegato viene impostato automaticamente su serverless durante l'esecuzione del codice se non è stata selezionata alcuna altra risorsa.
Selezionare un criterio di budget per l'utilizzo serverless
Importante
Questa funzionalità è disponibile in anteprima pubblica.
I criteri di budget consentono all'organizzazione di applicare tag personalizzati all'utilizzo serverless per l'attribuzione granulare della fatturazione.
Se l'area di lavoro usa criteri di budget per attribuire l'utilizzo serverless, è possibile selezionare i criteri di budget da applicare al notebook. Se un utente viene assegnato a un solo criterio di budget, tale criterio verrà selezionato per impostazione predefinita.
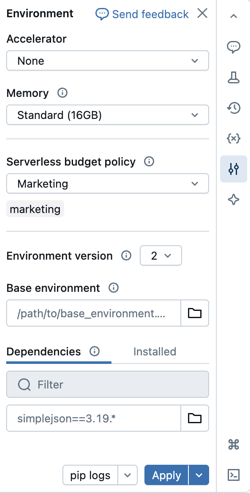
È possibile selezionare i criteri di budget dopo che il notebook è connesso al calcolo serverless usando il pannello laterale Ambiente
- Nell'interfaccia utente del notebook fare clic sul Environment side panelpannello laterale Ambiente .
- In Criteri budget selezionare i criteri di budget da applicare al notebook.
- Fare clic su Applica.
Da questo punto in poi, tutti gli utilizzi del notebook erediteranno i tag personalizzati dei criteri di budget.
Nota
Se il notebook ha origine da un repository Git o non dispone di criteri di budget assegnati , per impostazione predefinita verrà applicato l'ultimo criterio di budget scelto al successivo collegamento all'ambiente di calcolo serverless.
Configurare memoria elevata per i carichi di lavoro serverless
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Se è necessaria più memoria per eseguire i carichi di lavoro serverless, è possibile configurare il notebook in modo da usare una dimensione di memoria superiore. L'utilizzo serverless con memoria elevata ha una velocità di emissione DBU superiore rispetto alla memoria standard.
- Nell'interfaccia utente del notebook fare clic sul Environment side panelpannello laterale Ambiente .
- Nella sezione Memoria, selezionare Memoria alta.
- Fare clic su Applica.
Questa impostazione si applica anche alle attività del processo notebook, eseguite usando le preferenze di memoria del notebook. L'aggiornamento delle preferenze di memoria nel notebook influisce sull'esecuzione successiva del processo.
Visualizzare informazioni dettagliate sulle query
Il calcolo serverless per notebook e processi usa informazioni dettagliate sulle query per valutare le prestazioni di esecuzione di Spark. Dopo aver eseguito una cella in un notebook, è possibile visualizzare informazioni dettagliate correlate alle query SQL e Python facendo clic sul collegamento Visualizza prestazioni .
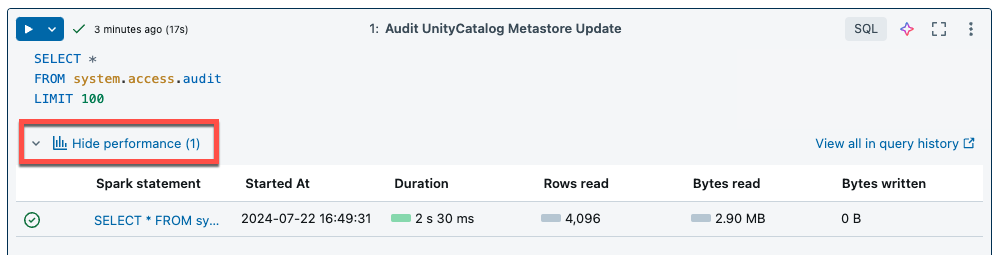
È possibile fare clic su una qualsiasi istruzione Spark per visualizzare le metriche di query. Da qui è possibile fare clic su Visualizza profilo di query per visualizzare una visualizzazione dell'esecuzione della query. Per altre informazioni sui profili di query, vedere Profilo di query.
Nota
Per visualizzare informazioni dettagliate sulle prestazioni per le esecuzioni del processo, vedere Visualizzare informazioni dettagliate sulle query di esecuzione del processo.
Cronologia delle query
Tutte le query eseguite nel calcolo serverless verranno registrate anche nella pagina della cronologia delle query dell'area di lavoro. Per informazioni sulla cronologia delle query, vedere Cronologia query.
Limitazioni delle informazioni dettagliate sulle query
- Il profilo di query è disponibile solo dopo il termine dell'esecuzione della query.
- Le metriche vengono aggiornate in tempo reale anche se il profilo di query non viene visualizzato durante l'esecuzione.
- Vengono trattati solo gli stati di query seguenti: RUNNING, CANCELED, FAILED, FINISHED.
- L'esecuzione di query non può essere annullata dalla pagina della cronologia query. Possono essere annullati nei notebook o nei processi.
- Le metriche verbose non sono disponibili.
- Download del profilo di query non disponibile.
- L'accesso all'interfaccia utente di Spark non è disponibile.
- Il testo dell'istruzione contiene solo l'ultima riga eseguita. Tuttavia, potrebbero essere presenti diverse righe che precedono questa riga che sono state eseguite come parte della stessa istruzione.