Creare il primo flusso di lavoro con un lavoro di Azure Databricks
Questo articolo illustra un lavoro di Azure Databricks che orchestra le task per leggere ed elaborare un set di dati di esempio. Questa guida introduttiva spiega come:
- Creare un nuovo notebook e aggiungere codice per riprendere un set di dati di esempio contenente i nomi di bambini più diffusi in base all'anno.
- Salvare il set di dati di esempio in Unity Catalog.
- Creare un nuovo notebook e aggiungere codice per leggere il set di dati dal catalogo unity, filtrarlo in base all'anno e visualizzare i risultati.
- Creare un nuovo lavoro e configurare due task usando i notebook.
- Eseguire il processo e visualizzare i risultati.
Requisiti
Se l'area di lavoro è abilitata per Unity Catalog e Serverless Jobs è abilitato, per impostazione predefinita, il job viene eseguito su infrastruttura serverless. Non è necessaria l'autorizzazione di creazione del cluster per eseguire il lavoro con Elaborazione serverless.
In caso contrario, è necessario disporre di autorizzazione di creazione del cluster per creare il calcolo processi o delle autorizzazioni per tutte le risorse di calcolo multiuso.
È necessario disporre di un volume in Unity Catalog. Questo articolo usa un volume denominato my-volume in uno schema denominato default all'interno di un catalogo denominato main. Inoltre, è necessario disporre delle autorizzazioni seguenti in Unity Catalog:
-
READ VOLUMEeWRITE VOLUME, oALL PRIVILEGESper il volumemy-volume. -
USE SCHEMAoALL PRIVILEGESper lo schemadefault. -
USE CATALOGoALL PRIVILEGESper il catalogomain.
Per impostare queste autorizzazioni, vedere l'amministratore di Databricks o i privilegi di Unity Catalog e gli oggetti a protezione diretta.
Creare i notebook
Riprendere e salvare i dati
Per creare un notebook per recuperare il set di dati di esempio e salvarlo in Unity Catalog:
Passare alla pagina di destinazione di Azure Databricks e fare clic su
 Nuovo nella barra laterale e selezionare Notebook. Databricks crea e apre un nuovo notebook vuoto nella cartella predefinita. Il linguaggio predefinito è quello usato di recente e il notebook viene collegato automaticamente alla risorsa di calcolo usata di recente.
Nuovo nella barra laterale e selezionare Notebook. Databricks crea e apre un nuovo notebook vuoto nella cartella predefinita. Il linguaggio predefinito è quello usato di recente e il notebook viene collegato automaticamente alla risorsa di calcolo usata di recente.Se necessario, modificare il linguaggio predefinito in Python.
Copiare il seguente codice Python e incollarlo nella prima cella del notebook.
import requests response = requests.get('https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv') csvfile = response.content.decode('utf-8') dbutils.fs.put("/Volumes/main/default/my-volume/babynames.csv", csvfile, True)
Leggere e visualizzare i dati filtrati
Per creare un notebook per leggere e presentare i dati per eseguire il filtro:
Passare alla pagina di destinazione di Azure Databricks e fare clic su
Nuovo nella barra laterale e selezionare Notebook. Databricks crea e apre un nuovo notebook vuoto nella cartella predefinita. Il linguaggio predefinito è quello usato di recente e il notebook viene collegato automaticamente alla risorsa di calcolo usata di recente.Se necessario, modificare il linguaggio predefinito in Python.
Copiare il seguente codice Python e incollarlo nella prima cella del notebook.
babynames = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/Volumes/main/default/my-volume/babynames.csv") babynames.createOrReplaceTempView("babynames_table") years = spark.sql("select distinct(Year) from babynames_table").toPandas()['Year'].tolist() years.sort() dbutils.widgets.dropdown("year", "2014", [str(x) for x in years]) display(babynames.filter(babynames.Year == dbutils.widgets.get("year")))
Creare un processo
Cliccare
 Flussi di lavoro nella barra laterale.
Flussi di lavoro nella barra laterale.Cliccare
 .
.Viene visualizzata la scheda Tasks con la finestra di dialogo Crea task.
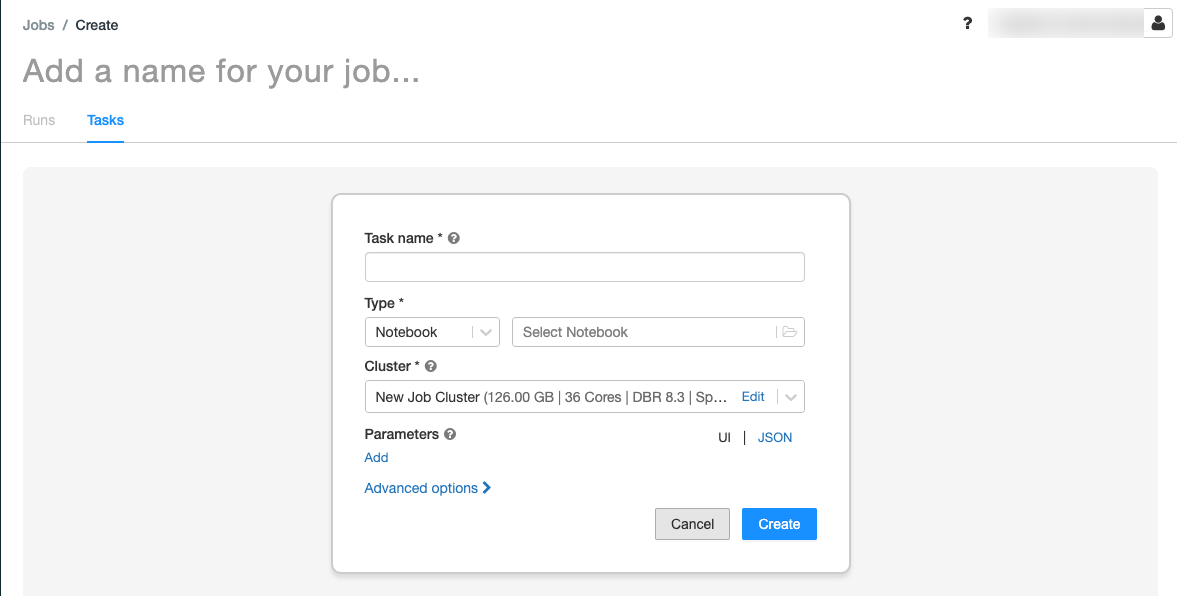
Sostituire Aggiungi un nome per il processo… con il nome del processo.
Nel campo Nome task immettere un nome per il task, ad esempio retrieve-baby-names.
Nel menu a tendina Tipo selezionare Notebook.
Utilizzare il browser dei file per trovare il notebook creato, cliccare sul nome del notebook e poi su Conferma.
Cliccare Crea task.
Cliccare
 sotto la task appena creata per aggiungere un'altra task.
sotto la task appena creata per aggiungere un'altra task.Nel campo Nome task immettere un nome per il task, ad esempio filter-baby-names.
Nel menu a tendina Tipo selezionare Notebook.
Utilizzare il browser dei file per trovare il secondo notebook creato, cliccare sul nome del notebook e poi su Conferma.
Fare clic su Aggiungi sotto Parametri. Nel campo Chiave immettere
year. Nel campo Valore immettere2014.Cliccare Crea task.
Eseguire il processo
Per eseguire immediatamente il lavoro, cliccare  nell'angolo in alto a destra. È anche possibile eseguire il processo facendo clic sulla scheda Esecuzioni e facendo clic su Esegui ora nella tabella Esecuzioni attive.
nell'angolo in alto a destra. È anche possibile eseguire il processo facendo clic sulla scheda Esecuzioni e facendo clic su Esegui ora nella tabella Esecuzioni attive.
Visualizzare i dettagli dell'esecuzione
Fare clic sulla scheda Esecuzioni
e fare clic sul collegamento per l'esecuzione nella tabella Esecuzioni attive o nella tabella Esecuzioni completate (ultimi 60 giorni) tabella.Fare clic su una delle task per visualizzare l'output e i dettagli. Ad esempio, cliccare sulla task filter-baby-names per visualizzare l'output ed eseguire i dettagli per la task di filtro:
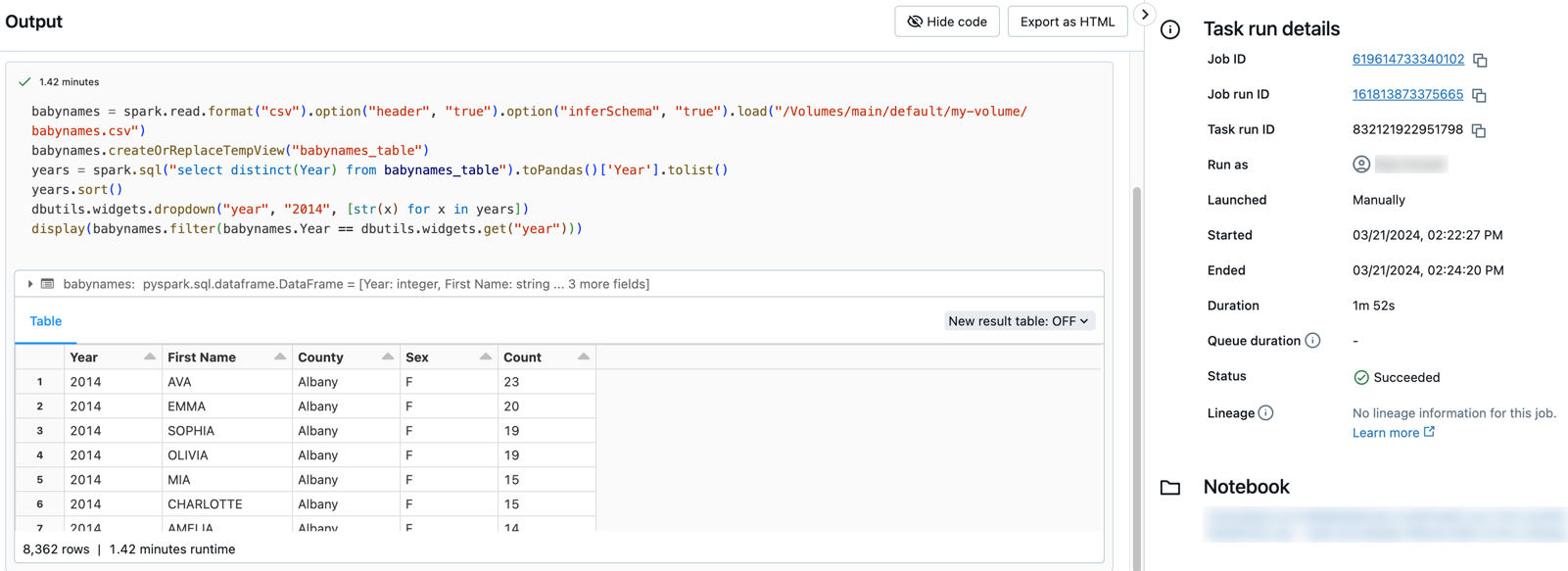
Esegui utilizzando parametri diversi
Per eseguire di nuovo il lavoro e filtrare i nomi dei bambini per un anno diverso:
- Fare clic su
 accanto a Esegui ora e selezionare Esegui ora con parametri diversi oppure fare clic su Esegui ora con parametri diversi nella tabella Esecuzioni Attive.
accanto a Esegui ora e selezionare Esegui ora con parametri diversi oppure fare clic su Esegui ora con parametri diversi nella tabella Esecuzioni Attive. - Nel campo Valore immettere
2015. - Fare clic su Esegui.