Usare le trasformazioni dbt in un processo di Azure Databricks
È possibile eseguire i progetti dbt Core come attività in un processo di Azure Databricks. Eseguendo il progetto dbt Core come attività di processo, è possibile trarre vantaggio dalle seguenti funzionalità dei processi di Azure Databricks:
- Automatizzare le attività dbt e pianificare i flussi di lavoro che includono attività dbt.
- Monitorare le trasformazioni dbt e inviare notifiche sullo stato delle trasformazioni.
- Includere il progetto dbt in un flusso di lavoro con altre attività. Ad esempio, il flusso di lavoro consente di inserire dati con il caricatore automatico, trasformare i dati con dbt e analizzare i dati con un task notebook.
- Archiviazione automatica degli artefatti dalle esecuzioni del processo, inclusi log, risultati, manifesti e configurazione.
Per altre informazioni su dbt Core, vedere la documentazione di dbt.
Flusso di lavoro di sviluppo e produzione
Databricks consiglia di sviluppare progetti dbt in un databricks SQL Warehouse. Usando un data warehouse SQL di Databricks, è possibile testare il codice SQL generato da dbt e usare la cronologia delle query del data warehouse SQL per eseguire il debug delle query generate da dbt.
Per eseguire le trasformazioni dbt nell'ambiente di produzione, Databricks consiglia di usare l'attività dbt in un processo di Databricks. Per impostazione predefinita, l'attività dbt eseguirà il processo dbt Python usando il calcolo di Azure Databricks e il databaset generato da SQL nel data warehouse selezionato.
È possibile eseguire trasformazioni dbt in un'istanza serverless di SQL Warehouse o pro SQL Warehouse, in un ambiente di calcolo di Azure Databricks o in qualsiasi altro warehouse supportato da dbt. Questo articolo illustra le prime due opzioni con esempi.
Se l'area di lavoro abilitata è Unity Cataloge i processi serverless sono abilitati, per impostazione predefinita, il processo viene eseguito su risorse di calcolo serverless.
Nota
Lo sviluppo di modelli dbt in un'istanza di SQL Warehouse e l'esecuzione nell'ambiente di produzione nel calcolo di Azure Databricks possono causare piccole differenze nelle prestazioni e nel supporto del linguaggio SQL. Databricks consiglia di usare la stessa versione di Databricks Runtime per il calcolo e sql warehouse.
Requisiti
Per informazioni su come usare dbt Core e il
dbt-databrickspacchetto per creare ed eseguire progetti dbt nell'ambiente di sviluppo, vedere Connettersi a dbt Core.Databricks consiglia il pacchetto dbt-databricks , non il pacchetto dbt-spark. Il pacchetto dbt-databricks è un fork di dbt-spark ottimizzato per Databricks.
Per utilizzare i progetti dbt in un processo di Azure Databricks, è necessario configurare l'integrazione di Git per le cartelle Git di Databricks set. Non è possibile eseguire un progetto dbt da DBFS.
È necessario che siano abilitati serverless o pro SQL Warehouse.
È necessario avere il diritto SQL di Databricks.
Creare ed eseguire il primo processo dbt
Nell'esempio seguente viene usato il progetto jaffle_shop , un progetto di esempio che illustra i concetti principali di dbt. Per creare un processo che esegue il progetto jaffle shop, seguire questa procedura.
Passare alla pagina di destinazione di Azure Databricks ed eseguire una delle operazioni seguenti:
- Fare clic su
 Flussi di lavoro nella barra laterale e fare clic su
Flussi di lavoro nella barra laterale e fare clic su  .
. - Nella barra laterale, fare clic su
 Nuovo e selectLavoro.
Nuovo e selectLavoro.
- Fare clic su
Nella casella di testo dell'attività della scheda Attività sostituire Aggiungi un nome per il processo con il nome del processo.
In Nome attività immettere un nome per l'attività.
In
Tipo , tipo di attività dbt. 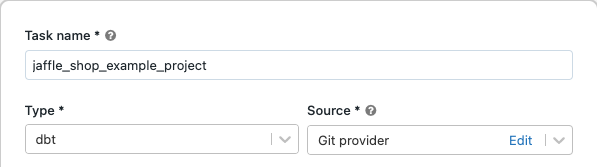
Nel menu a discesa origine, è possibile selectselezionareun'area di lavoro per usare un progetto dbt che si trova in una cartella dell'area di lavoro di Azure Databricks o un provider Git per un progetto che si trova in un repository Git remoto. Poiché questo esempio utilizza il progetto Jaffle Shop che si trova in un repository Git, selectprovider Git, cliccare su Modificae immettere i dettagli per il repository GitHub di Jaffle Shop.
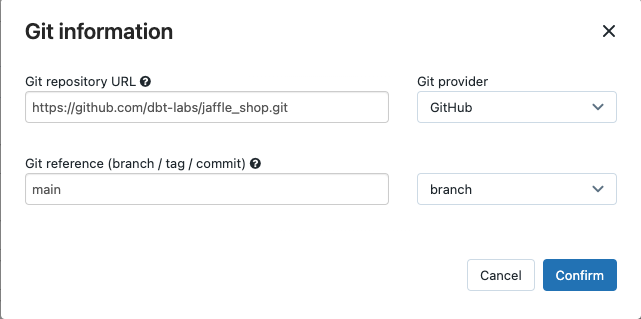
- In URL del repository Git immettere l'URL del progetto jaffle shop.
- In Riferimento Git (ramo/tag/commit)immettere
main. È anche possibile usare un tag o SHA.
Cliccare Conferma.
Nelle caselle di testo dei comandi dbt specificare i comandi dbt da eseguire (deps, seed ed run). È necessario anteporre a ogni comando
dbt. I comandi vengono eseguiti nell'ordine specificato.
In SQL Warehouse, select un SQL warehouse per eseguire le query SQL generate da dbt. Il menu a discesa SQL Warehouse mostra solo i warehouse serverless e SQL PRO.
(Facoltativo) È possibile specificare un schema per l'output dell'attività. Per impostazione predefinita, viene usato il schema
default.(Facoltativo) Se si vuole modificare la configurazione di calcolo che esegue dbt Core, fare clic su dbt CLI compute (Calcolo dell'interfaccia della riga di comando dbt).
(Facoltativo) È possibile specificare una versione dbt-databricks per l'attività. Ad esempio, per aggiungere l'attività dbt a una versione specifica per lo sviluppo e la produzione:
- In Librerie dipendenti fare clic su
 accanto alla versione corrente di dbt-databricks.
accanto alla versione corrente di dbt-databricks. - Fare clic su Aggiungi.
- Nella finestra di dialogo
Aggiungi libreria dipendente PyPI e immettere la versione dbt-package nella casella di testo pacchetto (ad esempio, ). - Fare clic su Aggiungi.

Nota
Databricks consiglia di associare le attività dbt a una versione specifica del pacchetto dbt-databricks per assicurarsi che la stessa versione venga usata per le esecuzioni di sviluppo e produzione. Databricks consiglia la versione 1.6.0 o successiva del pacchetto dbt-databricks.
- In Librerie dipendenti fare clic su
Cliccare su Crea.
Per eseguire il processo, fare clic su
 .
.
Visualizzare i risultati dell'attività del processo dbt
Al termine del processo, è possibile testare i risultati eseguendo query SQL da un notebook o eseguendo query nel databricks warehouse. Ad esempio, vedere le query di esempio seguenti:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Sostituire <schema> con il nome schema configurato nella configurazione dell'attività.
Esempio di API
È anche possibile usare l'API Processi per creare e gestire processi che includono attività dbt. L'esempio seguente crea un processo con una singola attività dbt:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Avanzate) Eseguire dbt con un profilo personalizzato
Per eseguire l'attività dbt con un'istanza di SQL Warehouse (scelta consigliata) o un calcolo a tutti gli scopi, usare una definizione personalizzata profiles.yml del warehouse o dell'ambiente di calcolo di Azure Databricks a cui connettersi. Per creare un processo che esegue il progetto jaffle shop con un magazzino o un calcolo tutto scopo, seguire questa procedura.
Nota
Come destinazione per un'attività dbt è possibile usare solo un'istanza di SQL Warehouse o di calcolo tutto scopo. Non è possibile usare il calcolo del processo come destinazione per dbt.
Creare un fork del repository jaffle_shop .
Clonare il repository con fork nel desktop. Ad esempio, è possibile eseguire un comando simile al seguente:
git clone https://github.com/<username>/jaffle_shop.gitSostituire
<username>con l'handle GitHub.Creare un nuovo file denominato
profiles.ymlnellajaffle_shopdirectory con il contenuto seguente:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Sostituire
<schema>con un nome di schema per il progetto tables. - Per eseguire l'attività dbt con un'istanza di SQL Warehouse, sostituire
<http-host>con il valore Nome host server dalla scheda Dettagli connessione per SQL Warehouse. Per eseguire l'attività dbt con calcolo all-purpose, sostituire<http-host>con il valore Nome host server dalla scheda Opzioni avanzate, JDBC/ODBC per il calcolo di Azure Databricks. - Per eseguire l'attività dbt con un'istanza di SQL Warehouse, sostituire
<http-path>con il valore percorso HTTP della scheda Dettagli connessione per SQL Warehouse. Per eseguire l'attività dbt con calcolo all-purpose, sostituire<http-path>con il valore percorso HTTP dalla scheda Opzioni avanzate, JDBC/ODBC per il calcolo di Azure Databricks.
Non si specificano segreti, ad esempio i token di accesso, nel file perché il file verrà archiviato nel controllo del codice sorgente. Invece, questo file usa la funzionalità di templating di dbt per insertcredentials in modo dinamico durante l'esecuzione.
Nota
I credentials generati sono validi per tutta la durata dell'esecuzione, fino a un massimo di 30 giorni, e vengono revocati automaticamente al termine.
- Sostituire
Controllare questo file in Git ed eseguirne il push nel repository con fork. Ad esempio, è possibile eseguire comandi come il seguente:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushFare clic su
Flussi di lavoro nella barra laterale dell'interfaccia utente di Databricks.Select la procedura dbt e fare clic sulla scheda attività.
In Source (Origine) fare clic su Edit (Modifica ) e immettere i dettagli del repository GitHub shop con fork.
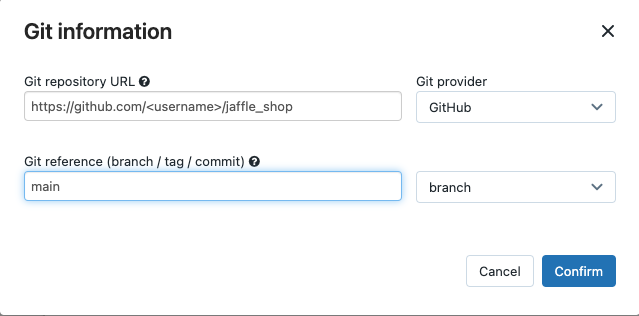
In SQL warehouse, selectNessuno (Manuale).
In Directory profili immettere il percorso relativo della directory contenente il
profiles.ymlfile. Lasciare vuoto il valore del percorso per usare l'impostazione predefinita della radice del repository.
(Avanzate) Usare modelli Python dbt in un flusso di lavoro
Nota
Il supporto dbt per i modelli Python è in versione beta e richiede dbt 1.3 o versione successiva.
dbt supporta ora modelli Python in data warehouse specifici, tra cui Databricks. Con i modelli python dbt è possibile usare gli strumenti dell'ecosistema Python per implementare trasformazioni difficili da implementare con SQL. È possibile creare un processo di Azure Databricks per eseguire una singola attività con il modello dbt Python oppure includere l'attività dbt come parte di un flusso di lavoro che include più attività.
Non è possibile eseguire modelli Python in un'attività dbt usando un'istanza di SQL Warehouse. Per altre informazioni sull'uso di modelli Python dbt con Azure Databricks, vedere Data warehouse specifici nella documentazione di dbt.
Errori e risoluzione dei problemi
Errore del file di profilo non esistente
Messaggio di errore:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Possibili cause:
Il profiles.yml file non è stato trovato nella $PATH specificata. Assicurarsi che la radice del progetto dbt contenga il file profiles.yml.