RAG (Retrieval Augmented Generation) su Azure Databricks
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Agent Framework comprende un set di strumenti su Databricks progettato per aiutare gli sviluppatori a creare, distribuire e valutare agenti di intelligenza artificiale di qualità produttiva come le applicazioni di Generazione Aumentata dal Recupero (RAG).
Questo articolo illustra RAG e i vantaggi dello sviluppo di applicazioni RAG in Azure Databricks.
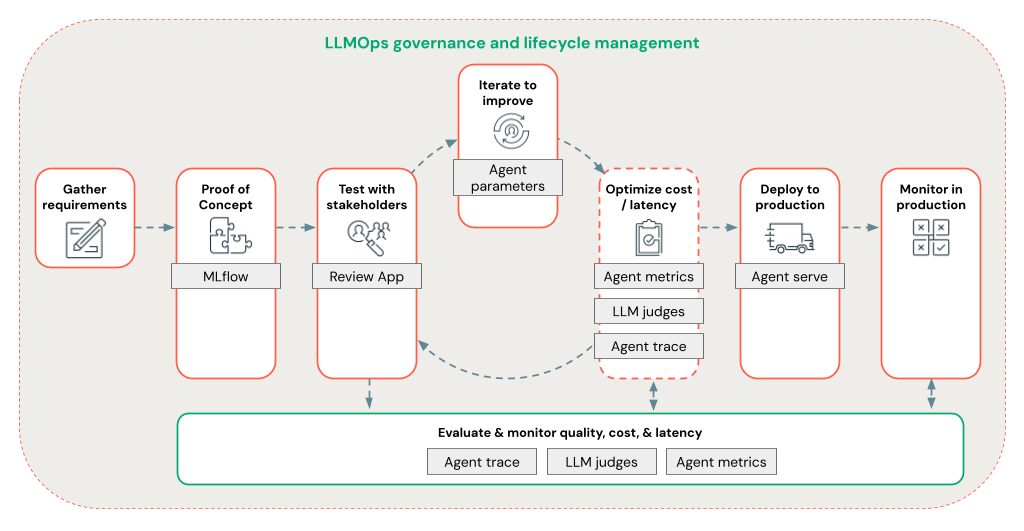
Agent Framework consente agli sviluppatori di iterare rapidamente su tutti gli aspetti dello sviluppo RAG usando un flusso di lavoro LLMOps completo.
Requisiti
- Per l'area di lavoro è necessario abilitare le funzionalità assistive di Azure AI.
- Tutti i componenti di un'agentic application devono trovarsi in una singola area di lavoro. Ad esempio, nel caso di un'applicazione RAG, il modello di servizio e l'istanza di ricerca vettoriale devono trovarsi nella stessa area di lavoro.
Informazioni su RAG
RAG è una tecnica di progettazione di intelligenza artificiale generativa che migliora i modelli linguistici di grandi dimensioni (LLM) con conoscenze esterne. Questa tecnica migliora gli LLM nei modi seguenti:
- Conoscenza proprietaria: RAG può includere informazioni proprietarie non usate inizialmente per eseguire il training dell'LLM, ad esempio promemoria, messaggi di posta elettronica e documenti per rispondere a domande specifiche del dominio.
- Informazioni aggiornate: un'applicazione RAG può fornire all'LLM informazioni provenienti da origini dati aggiornate.
- Citazione delle fonti: RAG consente agli LLM di citare fonti specifiche, permettendo agli utenti di verificare l'accuratezza delle risposte.
- Elenchi di controllo di accesso e sicurezza dei dati: Il passaggio di recupero può essere progettato per recuperare in modo selettivo le informazioni personali o proprietarie in base alle credenziali utente.
Sistemi AI composti
Un'applicazione RAG è un esempio di sistema di intelligenza artificiale composto: si espande sulle funzionalità del linguaggio dell'LLM combinandola con altri strumenti e procedure.
Nel formato più semplice, un'applicazione RAG esegue le operazioni seguenti:
- Recupero: la richiesta dell'utente viene usata per eseguire query su un archivio dati esterno, ad esempio un archivio vettoriale, una ricerca di parole chiave di testo o un database SQL. L'obiettivo è ottenere dati di supporto per la risposta del LLM.
- Incremento: i dati recuperati vengono combinati con la richiesta dell'utente, spesso usando un modello con formattazione e istruzioni aggiuntive, per creare uno stimolo.
- Generazione: il prompt viene passato all'LLM, che genera quindi una risposta alla domanda.
Dati RAG non strutturati e strutturati
L'architettura RAG può funzionare con sia dati di supporto non strutturati che strutturati. I dati usati con il RAG dipendono dal caso d'uso.
Dati non strutturati: dati senza una struttura o un'organizzazione specifica. Documenti che includono testo e immagini o contenuti multimediali, ad esempio audio o video.
- Documenti di Google/Office
- Wiki
- Immagini
- Video
Dati strutturati: dati tabulari disposti in righe e colonne con uno schema specifico, ad esempio tabelle in un database.
- Record dei clienti in un sistema BI o data warehouse
- Dati della transazione da un database SQL
- Dati dalle API dell'applicazione (ad esempio, SAP, Salesforce e così via)
Le sezioni seguenti descrivono un'applicazione RAG per i dati non strutturati.
Pipeline dei dati RAG
La pipeline di dati RAG preelabora e indicizza i documenti per un recupero rapido e accurato.
Il diagramma seguente mostra una pipeline di dati di esempio per un set di dati non strutturato usando un algoritmo di ricerca semantica. I Job di Databricks orchestrano ogni passaggio.
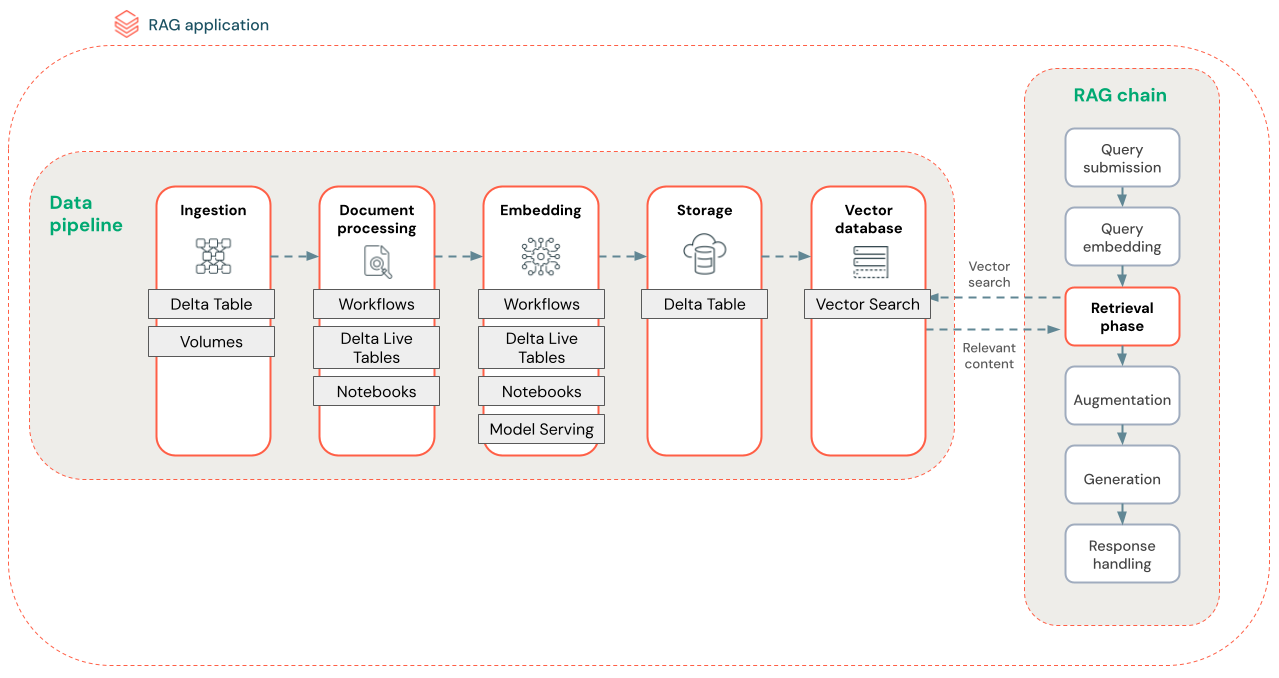
- Inserimento dati: inserire dati dall'origine proprietaria. Archiviare questi dati in una tabella Delta o in un volume del catalogo Unity.
-
di elaborazione dei documenti: è possibile eseguire queste attività usando Processi Databricks, Notebook di Databricks e DLT.
- Analizzare i documenti grezzi: trasformare i dati non elaborati in un formato utilizzabile. Ad esempio, estrarre il testo, le tabelle e le immagini da una raccolta di PDF o usare tecniche di riconoscimento ottico dei caratteri per estrarre testo dalle immagini.
- Estrazione metadati: estrai i metadati del documento, ad esempio, titoli di documenti, numeri di pagina e URL per facilitare il processo di recupero delle query più accuratamente.
- Documenti a blocchi: Dividere i dati in blocchi che rientrano nella finestra di contesto dell'LLM. Il recupero di blocchi specifici, anziché interi documenti, fornisce al LLM contenuti più mirati per generare risposte.
- Incorporamento di blocchi: un modello di incorporamento utilizza i blocchi per creare rappresentazioni numeriche delle informazioni denominate incorporamenti vettoriali. I vettori rappresentano il significato semantico del testo, non solo parole chiave a livello di superficie. In questo scenario si calcolano gli incorporamenti e si usa Model Serving per gestire il modello di incorporamento.
- Archiviazione di incorporamenti - Archiviare gli incorporamenti vettoriali e il testo del blocco in una tabella Delta sincronizzata con la Ricerca Vettoriale.
- Database vettoriale: come parte della ricerca vettoriale, gli incorporamenti e i metadati vengono indicizzati e archiviati in un database vettoriale per eseguire facilmente query tramite l'agente RAG. Quando un utente effettua una query, la richiesta viene incorporata in un vettore. Il database usa quindi l'indice vettoriale per trovare e restituire i blocchi più simili.
Ogni passaggio implica decisioni di progettazione che influiscono sulla qualità dell'applicazione RAG. Ad esempio, scegliendo la dimensione corretta del blocco nel passaggio (3) si garantisce che l’LLM riceva informazioni specifiche ma contestualizzate, mentre la selezione di un modello di incorporamento appropriato nel passaggio (4) determina l'accuratezza dei blocchi restituiti durante il recupero.
Ricerca Vettoriale Databricks
Calcolare la somiglianza è spesso computazionalmente costoso, ma gli indici vettoriali come Databricks Vector Search ottimizzano questo processo organizzando in modo efficiente gli incorporamenti. Le ricerche vettoriali classificano rapidamente i risultati più rilevanti senza confrontare singolarmente ogni incorporamento con la query dell'utente.
Ricerca vettoriale sincronizza automaticamente i nuovi incorporamenti aggiunti alla tabella Delta e aggiorna l'indice di Ricerca vettoriale.
Che cos'è un agente RAG?
Un agente di generazione aumentata di recupero (RAG) è una parte fondamentale di un'applicazione RAG che migliora le funzionalità dei modelli di linguaggio di grandi dimensioni integrando il recupero di dati esterni. L'agente RAG elabora le query degli utenti, recupera i dati pertinenti da un database vettoriale e passa questi dati a un LLM per generare una risposta.
Gli strumenti come LangChain o Pyfunc collegano questi passaggi connettendo gli input e gli output.
Il diagramma seguente mostra un agente RAG per un chatbot e le funzionalità di Databricks usate per compilare ogni agente.
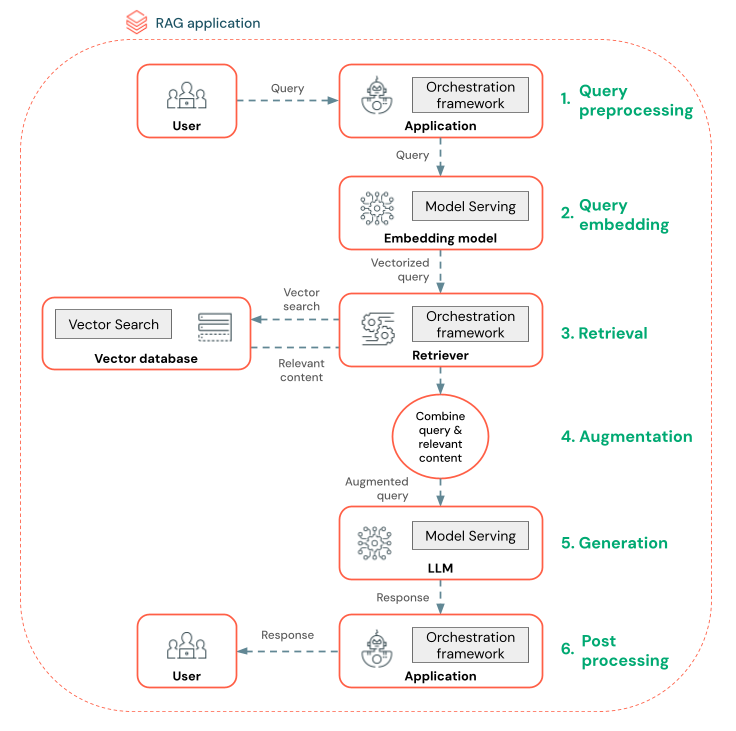
- Pre-elaborazione delle query: un utente invia una query, che viene quindi pre-elaborata per renderla adatta per l'esecuzione di query sul database vettoriale. Ciò può comportare l'inserimento della richiesta in un modello o l'estrazione di parole chiave.
- Vettorizzazione delle query: usare Model Serving per incorporare la richiesta usando lo stesso modello di incorporamento impiegato per incorporare i blocchi nella pipeline di dati. Questi incorporamenti consentono il confronto della somiglianza semantica tra la richiesta e i blocchi pre-elaborati.
- Fase di recupero: il retriever, un'applicazione responsabile del recupero di informazioni pertinenti, accetta la query vettorializzata ed esegue una ricerca di somiglianza vettoriale usando Vector Search. I blocchi di dati più rilevanti vengono classificati e recuperati in base alla somiglianza con la query.
- Accrescimento della richiesta: il retriever combina i blocchi di dati recuperati con la query originale per fornire contesto supplementare all'LLM. La richiesta è strutturata attentamente per assicurare che l'LLM comprenda il contesto della domanda. Spesso, l'LLM ha un modello per la formattazione della risposta. Questo processo di regolazione del prompt è noto come ingegneria dei prompt.
- Fase di generazione LLM: l'LLM genera una risposta usando la query aumentata arricchita dai risultati del recupero. L’LLM può essere un modello personalizzato o un modello di base.
- Post-elaborazione: la risposta dell'LLM può essere elaborata per applicare logica di business aggiuntiva, aggiungere citazioni o perfezionare il testo generato in base a regole o vincoli predefiniti
In questo processo possono essere applicate varie protezioni al fine di garantire la conformità ai criteri aziendali. Ciò potrebbe comportare l’applicazione di filtri delle richieste appropriate, la verifica delle autorizzazioni degli utenti prima di accedere alle origini dati e l'utilizzo di tecniche di moderazione dei contenuti sulle risposte generate.
Lo sviluppo dell'agente RAG a livello di produzione
Iterare rapidamente lo sviluppo degli agenti usando le funzionalità seguenti:
Creare e registrare agenti usando qualsiasi libreria e MLflow. Parametrizza i tuoi agenti per sperimentare e iterare rapidamente sullo sviluppo degli agenti.
Distribuire gli agenti nell'ambiente di produzione con supporto nativo per lo streaming di token e la registrazione delle richieste/risposte, oltre a un'app di revisione predefinita per raccogliere feedback degli utenti per l'agente.
Il tracciamento dell'agente consente di registrare, analizzare e confrontare tracce nel codice dell'agente per eseguire il debug e comprendere in che modo l'agente risponde alle richieste.
Valutazione e monitoraggio
La valutazione e il monitoraggio consentono di determinare se l'applicazione RAG soddisfi i requisiti di qualità, costi e latenza. La valutazione viene eseguita durante lo sviluppo, mentre il monitoraggio avviene dopo l’implementazione dell'applicazione nell'ambiente di produzione.
Il RAG su dati non strutturati ha molti componenti che influiscono sulla qualità. Ad esempio, le modifiche alla formattazione dei dati possono influenzare i blocchi recuperati e la capacità dell'LLM di generare risposte pertinenti. È quindi importante valutare i singoli componenti, oltre all'applicazione complessiva.
Per altre informazioni, consultare Che cos’è alla Mosaic AI Agent Evaluation?.
Aree di disponibilità
Per la disponibilità a livello di area di Agent Framework, vedere Funzionalità con disponibilità a livello di area a disponibilità limitata