Osservabilità dell'agente con tracciamento MLflow
Questo articolo descrive come aggiungere osservabilità alle applicazioni di intelligenza artificiale generative con MLflow Tracing in Databricks.
Che cos'è MLflow Tracing?
MLflow Tracing offre un'osservabilità end-to-end per le applicazioni di intelligenza artificiale generative dallo sviluppo alla distribuzione. Il monitoraggio è completamente integrato con il set di strumenti di intelligenza artificiale generativa di Databricks, acquisendo informazioni dettagliate sull'intero ciclo di vita di sviluppo e produzione.
Di seguito sono riportati i casi d'uso principali per la traccia nelle applicazioni di intelligenza artificiale di generazione:
Debugging semplificato: Il tracciamento offre visibilità su ogni passaggio della tua applicazione di intelligenza artificiale generativa, rendendo più facile diagnosticare e risolvere i problemi.
Valutazione offline: Il tracciamento genera dati preziosi per la valutazione degli agenti, consentendo di misurare e migliorare la qualità degli agenti nel tempo.
Monitoraggio produzione: la traccia offre visibilità sul comportamento dell'agente e sui passaggi dettagliati di esecuzione, consentendo di monitorare e ottimizzare le prestazioni dell'agente nell'ambiente di produzione.
log di controllo: MLflow Tracing genera log di controllo completi e dettagliati delle azioni e decisioni dell'agente. Questo è fondamentale per garantire la conformità e il supporto del debug quando si verificano problemi imprevisti.
Requisiti
MLflow Tracing è disponibile nelle versioni MLflow 2.13.0 e successive. Databricks consiglia di installare la versione più recente di MLflow per accedere alle funzionalità e ai miglioramenti più recenti.
%pip install mlflow>=2.13.0 -qqqU
%restart_python
tracciamento automatico
MLflow autologging ti permette di strumentare rapidamente il tuo agente aggiungendo una singola riga al tuo codice, mlflow.<library>.autolog().
MLflow supporta la registrazione automatica per le librerie più comuni per la creazione di agenti. Per altre informazioni su ogni libreria di creazione, vedere documentazione sull'aggiunta automatica di MLflow:
| Biblioteca | Supporto della versione di autologging | Comando di registrazione automatica |
|---|---|---|
| LangChain | 0.1.0 ~ Più recente | mlflow.langchain.autolog() |
| Langgraph | 0.1.1 ~ Più recente | mlflow.langgraph.autolog() |
| OpenAI | 1.0.0 ~ Più recente | mlflow.openai.autolog() |
| LlamaIndex | 0.10.44 ~ Ultima versione | mlflow.llamaindex.autolog() |
| DSPy | 2.5.17 ~ Più recente | mlflow.dspy.autolog() |
| Amazon Bedrock | 1.33.0 ~ Più Recente (boto3) | mlflow.bedrock.autolog() |
| Anthropic | 0.30.0: Più recente | mlflow.anthropic.autolog() |
| AutoGen | 0.2.36 ~ 0.2.40 | mlflow.autogen.autolog() |
| Google Gemini | 1.0.0 ~ Più recente | mlflow.gemini.autolog() |
| CrewAI | 0.80.0 ~ Più recente | mlflow.crewai.autolog() |
| LiteLLM | 1.52.9 ~ Ultima versione | mlflow.litellm.autolog() |
| Groq | 0.13.0 ~ Più recente | mlflow.groq.autolog() |
| Mistral | 1.0.0 ~ Più recente | mlflow.mistral.autolog() |
Disabilitare l'autoregistrazione
Il tracciamento automatico è attivo per impostazione predefinita in Databricks Runtime 15.4 ML e versioni successive per le seguenti librerie:
- LangChain
- Langgraph
- OpenAI
- LlamaIndex
Per disabilitare il tracciamento automatico del logging per queste librerie, eseguire il comando seguente in un notebook.
`mlflow.<library>.autolog(log_traces=False)`
Aggiungere tracce manualmente
Anche se l'autologging offre un modo pratico per instrumentare gli agenti, potresti voler instrumentare il tuo agente in modo più dettagliato o aggiungere tracce aggiuntive che l'autologging non riesce a catturare. In questi casi, usare le API di traccia MLflow per aggiungere manualmente tracce.
API di traccia MLflow sono API a basso codice per l'aggiunta di tracce senza doversi preoccupare della gestione della struttura ad albero della traccia. MLflow determina automaticamente le relazioni di intervallo padre-figlio appropriate usando lo stack Python.
Combinare l'autologging e il tracciamento manuale
Le API di tracciamento manuale possono essere usate con la registrazione automatica. MLflow combina i segmenti creati tramite la registrazione automatica e la tracciatura manuale per creare una panoramica completa dell'esecuzione dell'agente. Per un esempio di combinazione di autologging e tracciamento manuale, vedere Strumentazione di uno strumento agente chiamante con MLflow Tracing.
Funzioni di tracciamento usando il decoratore @mlflow.trace
Il modo più semplice per instrumentare manualmente il codice consiste nel decorare una funzione con l'@mlflow.trace decorator. L'decorator di traccia MLflow crea un "span" con l'ambito della funzione decorata, che rappresenta un'unità di esecuzione in una traccia e viene visualizzata come una singola riga nella visualizzazione della traccia. L'intervallo acquisisce l'input, l'output, la latenza e eventuali eccezioni generate dalla funzione.
Ad esempio, il seguente codice crea uno span denominato my_function che raccoglie gli argomenti di input x e y e l'output.
import mlflow
@mlflow.trace
def add(x: int, y: int) -> int:
return x + y
È anche possibile personalizzare il nome dell'intervallo, il tipo di intervallo e aggiungere attributi personalizzati all'intervallo:
from mlflow.entities import SpanType
@mlflow.trace(
# By default, the function name is used as the span name. You can override it with the `name` parameter.
name="my_add_function",
# Specify the span type using the `span_type` parameter.
span_type=SpanType.TOOL,
# Add custom attributes to the span using the `attributes` parameter. By default, MLflow only captures input and output.
attributes={"key": "value"}
)
def add(x: int, y: int) -> int:
return x + y
Tracciare blocchi di codice arbitrari usando gestione contesto
Per creare un intervallo per un blocco arbitrario di codice, non solo una funzione, usare mlflow.start_span() come gestore del contesto che esegue il wrapping del blocco di codice. L'intervallo inizia quando si entra nel contesto e termina quando si esce dal contesto. L'input e l'output dello span devono essere forniti manualmente utilizzando i metodi setter dell'oggetto span fornito dal gestore di contesto. Per altre informazioni, vedere documentazione di MLflow - Gestore del contesto.
with mlflow.start_span(name="my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Librerie di tracciamento di livello basso
MLflow fornisce anche API di basso livello per controllare in modo esplicito la struttura ad albero di traccia. Consultare la documentazione di MLflow - Strumentazione manuale.
Esempio di traccia : combinare la registrazione automatica e le tracce manuali
L'esempio seguente combina l'autologging di OpenAI e il tracciamento manuale per instrumentare completamente un agente che chiama strumenti.
import json
from openai import OpenAI
import mlflow
from mlflow.entities import SpanType
client = OpenAI()
# Enable OpenAI autologging to capture LLM API calls
# (*Not necessary if you are using the Databricks Runtime 15.4 ML and above, where OpenAI autologging is enabled by default)
mlflow.openai.autolog()
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
},
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool-calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
tools=tools,
)
ai_msg = response.choices[0].message
messages.append(ai_msg)
# If the model requests tool calls, invoke the function(s) with the specified arguments
if tool_calls := ai_msg.tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
if tool_func := _tool_functions.get(function_name):
args = json.loads(tool_call.function.arguments)
tool_result = tool_func(**args)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result,
}
)
# Send the tool results to the model and get a new response
response = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
return response.choices[0].message.content
# Run the tool calling agent
question = "What's the weather like in Paris today?"
answer = run_tool_agent(question)
Annotare le tracce con tag
Tag traccianti di MLflow sono coppie chiave-valore che consentono di aggiungere metadati personalizzati ai tracciati, ad esempio un ID conversazione, un ID utente, un hash di commit Git e così via. I tag vengono visualizzati nell'interfaccia utente di MLflow per permettere di filtrare e cercare tracciati.
I tag possono essere impostati su una traccia in corso o completata usando le API MLflow o l'interfaccia utente di MLflow. L'esempio seguente illustra l'aggiunta di un tag a una traccia in corso usando l'API mlflow.update_current_trace().
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
Per altre informazioni sull'assegnazione di tag alle tracce e su come usarle per filtrare e cercare tracce, vedere documentazione di MLflow - Impostazione dei tag di traccia.
Esaminare le tracce
Per esaminare le tracce dopo aver eseguito l'agente, utilizzare una delle seguenti opzioni:
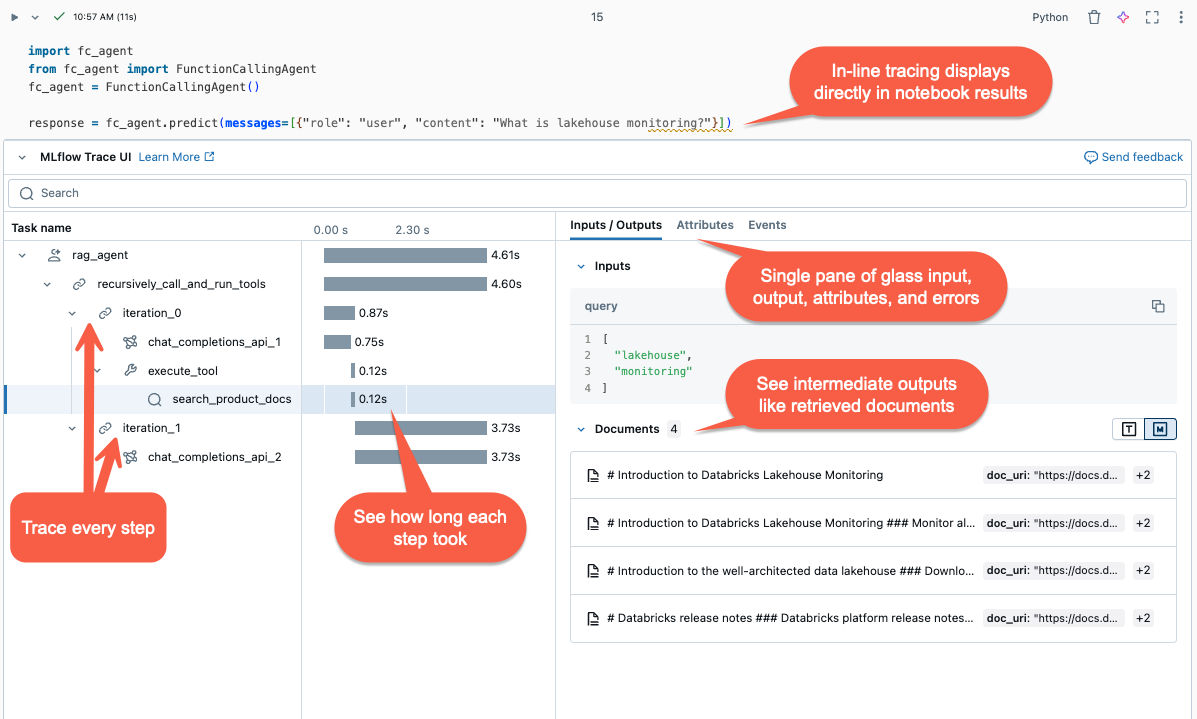
- Visualizzazione inline: Nei notebook di Databricks, le tracce vengono visualizzate inline nell'output della cella.
- esperimento di MLflow: in Databricks passare a Esperimenti> Selezionare un esperimento >Tracce per visualizzare e cercare tutte le tracce di un esperimento.
- Esecuzione di MLflow: quando l'agente è in esecuzione durante un MLflow Run attivo, le tracce vengono visualizzate nella pagina dell'esecuzione dell'interfaccia utente di MLflow.
- 'interfaccia utente di valutazione agente: nella valutazione dell'agente di Mosaic AI è possibile esaminare le tracce per ogni esecuzione dell'agente facendo clic su Visualizza visualizzazione di traccia dettagliata nel risultato della valutazione.
- Trace Search API: per recuperare le tracce tramite programmazione, utilizzare l'API di ricerca di traccia .
Valutare gli agenti usando tracce
I dati di traccia fungono da risorsa preziosa per la valutazione degli agenti. Acquisendo informazioni dettagliate sull'esecuzione dei modelli, MLflow Tracing è fondamentale per la valutazione offline. È possibile usare i dati di traccia per valutare le prestazioni dell'agente rispetto a un set di dati golden, identificare i problemi e migliorare le prestazioni dell'agente.
%pip install -U mlflow databricks-agents
%restart_python
import mlflow
# Get the recent 50 successful traces from the experiment
traces = mlflow.search_traces(
max_results=50,
filter_string="status = 'OK'",
)
traces.drop_duplicates("request", inplace=True) # Drop duplicate requests.
traces["trace"] = traces["trace"].apply(lambda x: x.to_json()) # Convert the trace to JSON format.
# Evaluate the agent with the trace data
mlflow.evaluate(data=traces, model_type="databricks-agent")
Per altre informazioni sulla valutazione dell'agente, vedere Eseguire una valutazione e visualizzare i risultati.
Monitorare gli agenti distribuiti con tabelle di inferenza
Dopo aver distribuito un agente in Mosaic AI Model Serving, è possibile usare tabelle di inferenza per monitorare l'agente. Le tabelle di inferenza contengono log dettagliati di richieste, risposte, tracce dell'agente e feedback dell'agente dall'app di revisione. Queste informazioni consentono di eseguire il debug di problemi, monitorare le prestazioni e creare un set di dati golden per la valutazione offline.
Per abilitare le tabelle di inferenza per le distribuzioni degli agenti, vedere Abilitare le tabelle di inferenza per gli agenti di intelligenza artificiale.
Consultare tracce online
Usare un notebook per eseguire una query sulla tabella di inferenza e analizzare i risultati.
Per visualizzare le tracce, eseguire display(<the request logs table>) e selezionare le righe da esaminare:
# Query the inference table
df = spark.sql("SELECT * FROM <catalog.schema.my-inference-table-name>")
display(df)
Monitorare gli agenti
Consulta Come monitorare l'app di intelligenza artificiale generativa.
Latenza dell'overhead di traccia
Le tracce vengono scritte in modo asincrono per ridurre al minimo l'impatto sulle prestazioni. Tuttavia, la traccia aggiunge comunque la latenza alla velocità di risposta dell'endpoint, in particolare quando le dimensioni della traccia per ogni richiesta di inferenza sono elevate. Databricks consiglia di testare l'endpoint per comprendere l'impatto della latenza di traccia prima della distribuzione nell'ambiente di produzione.
La tabella seguente fornisce stime approssimative per l'impatto della latenza in base alle dimensioni della traccia:
| Dimensione della traccia per richiesta | Impatto sulla latenza della velocità di risposta (ms) |
|---|---|
| Circa 10 KB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
Risoluzione dei problemi
Per la risoluzione dei problemi e le domande comuni, vedere la documentazione di MLflow: Guida pratica alla traccia e documentazione di MLflow : Domande frequenti