Come monitorare la qualità dell'agente nel traffico di produzione
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Questo articolo descrive come monitorare la qualità degli agenti distribuiti nel traffico di produzione usando La valutazione dell'agente di intelligenza artificiale Mosaic.
Il monitoraggio online è un aspetto fondamentale per garantire che l'agente funzioni come previsto con richieste reali. Usando il notebook riportato di seguito, è possibile eseguire la valutazione dell'agente in modo continuo sulle richieste gestite tramite un endpoint di gestione degli agenti. Il notebook genera un dashboard che visualizza le metriche di qualità, nonché il feedback degli utenti (pollici su 👍 o pollice verso il basso 👎) per gli output dell'agente nelle richieste di produzione. Questo feedback può arrivare tramite l'app di revisione da parte degli stakeholder o l'API di feedback sugli endpoint di produzione che consente di acquisire le reazioni dell'utente finale. Il dashboard consente di sezionare le metriche in base a dimensioni diverse, tra cui in base al tempo, commenti e suggerimenti degli utenti, stato di superamento/esito negativo e argomento della richiesta di input( ad esempio, per comprendere se argomenti specifici sono correlati a output di qualità inferiore). Inoltre, è possibile approfondire le singole richieste con risposte di bassa qualità per eseguirne il debug. Tutti gli artefatti, ad esempio il dashboard, sono completamente personalizzabili.
Requisiti
- Per l'area di lavoro è necessario abilitare le funzionalità di assistenza AI di Azure basato su intelligenza artificiale.
- le tabelle di inferenza devono essere abilitate nell'endpoint che gestisce l'agente.
Elaborare continuamente il traffico di produzione tramite la valutazione dell'agente
Il notebook di esempio seguente illustra come eseguire La valutazione dell'agente nei log delle richieste da un endpoint di gestione dell'agente. Per eseguire il notebook, seguire questa procedura:
- Importare il notebook nell'area di lavoro (istruzioni). Per ottenere un URL per l'importazione, fare clic sul pulsante "Copia collegamento per l'importazione".
- Compilare i parametri obbligatori nella parte superiore del notebook importato.
- Nome dell'endpoint di gestione dell'agente distribuito.
- Frequenza di campionamento compresa tra 0,0 e 1,0 per le richieste di campionamento. Usare una frequenza inferiore per gli endpoint con quantità elevate di traffico.
- (Facoltativo) Cartella dell'area di lavoro in cui archiviare gli artefatti generati, ad esempio i dashboard. Il valore predefinito è la home folder.
- (Facoltativo) Elenco di argomenti per classificare le richieste di input. Il valore predefinito è un elenco costituito da un singolo argomento onnicomprensivo.
- Fare clic su Esegui tutto nel notebook importato. Verrà eseguita un'elaborazione iniziale dei log di produzione all'interno di una finestra di 30 giorni e verrà inizializzato il dashboard che riepiloga le metriche di qualità.
- Fare clic su Pianifica per creare un processo per eseguire periodicamente il notebook. Il processo elabora in modo incrementale i log di produzione e mantiene aggiornato il dashboard.
Il notebook richiede un ambiente di calcolo serverless o un cluster che esegue Databricks Runtime 15.2 o versione successiva. Quando si monitora continuamente il traffico di produzione sugli endpoint con un numero elevato di richieste, è consigliabile impostare una pianificazione più frequente. Ad esempio, una pianificazione oraria funziona correttamente per un endpoint con più di 10.000 richieste all'ora e una frequenza di campionamento del 10%.
Eseguire la valutazione dell'agente nel notebook del traffico di produzione
Ottieni notebook
Implementare le linee guida per le risposte dell'Agente
Il giudice di conformità delle linee guida garantisce che gli output del modello siano conformi alle linee guida fornite. È possibile scrivere queste linee guida globali come illustrato nel notebook fornito in precedenza o come indicato di seguito:
mlflow.evaluate(
...,
evaluator_config={
"databricks-agent": {
"global_guidelines": [
"The response must be in English",
"The response must be clear, coherent, and concise",
],
}
}
)
I risultati di questo giudice verranno inseriti nella tabella dei log delle richieste valutate generata dal notebook di esempio (eval_requests_log_table_name nel notebook) e il dashboard può essere personalizzato per visualizzare i risultati dei giudici nel tempo.
Creare avvisi sulle metriche di valutazione
Dopo aver pianificato l'esecuzione periodica del notebook, è possibile aggiungere avvisi per ricevere una notifica quando le metriche di qualità diminuiscono del previsto. Questi avvisi vengono creati e usati allo stesso modo degli altri avvisi SQL di Databricks. Creare prima di tutto un query SQL di Databricks nella tabella di log delle richieste di valutazione generata dal notebook di esempio. Il codice seguente mostra una query di esempio sulla tabella delle richieste di valutazione, filtrando le richieste dall'ultima ora:
SELECT
`date`,
AVG(pass_indicator) as avg_pass_rate
FROM (
SELECT
*,
CASE
WHEN `response/overall_assessment/rating` = 'yes' THEN 1
WHEN `response/overall_assessment/rating` = 'no' THEN 0
ELSE NULL
END AS pass_indicator
-- The eval requests log table is generated by the example notebook
FROM {eval_requests_log_table_name}
WHERE `date` >= CURRENT_TIMESTAMP() - INTERVAL 1 DAY
)
GROUP BY ALL
Creare quindi un avviso SQL di Databricks per valutare la query con una frequenza desiderata e inviare una notifica se viene attivato l'avviso. L'immagine seguente mostra una configurazione di esempio per l'invio di un avviso quando il tasso di passaggio complessivo scende al di sotto dell'80%.
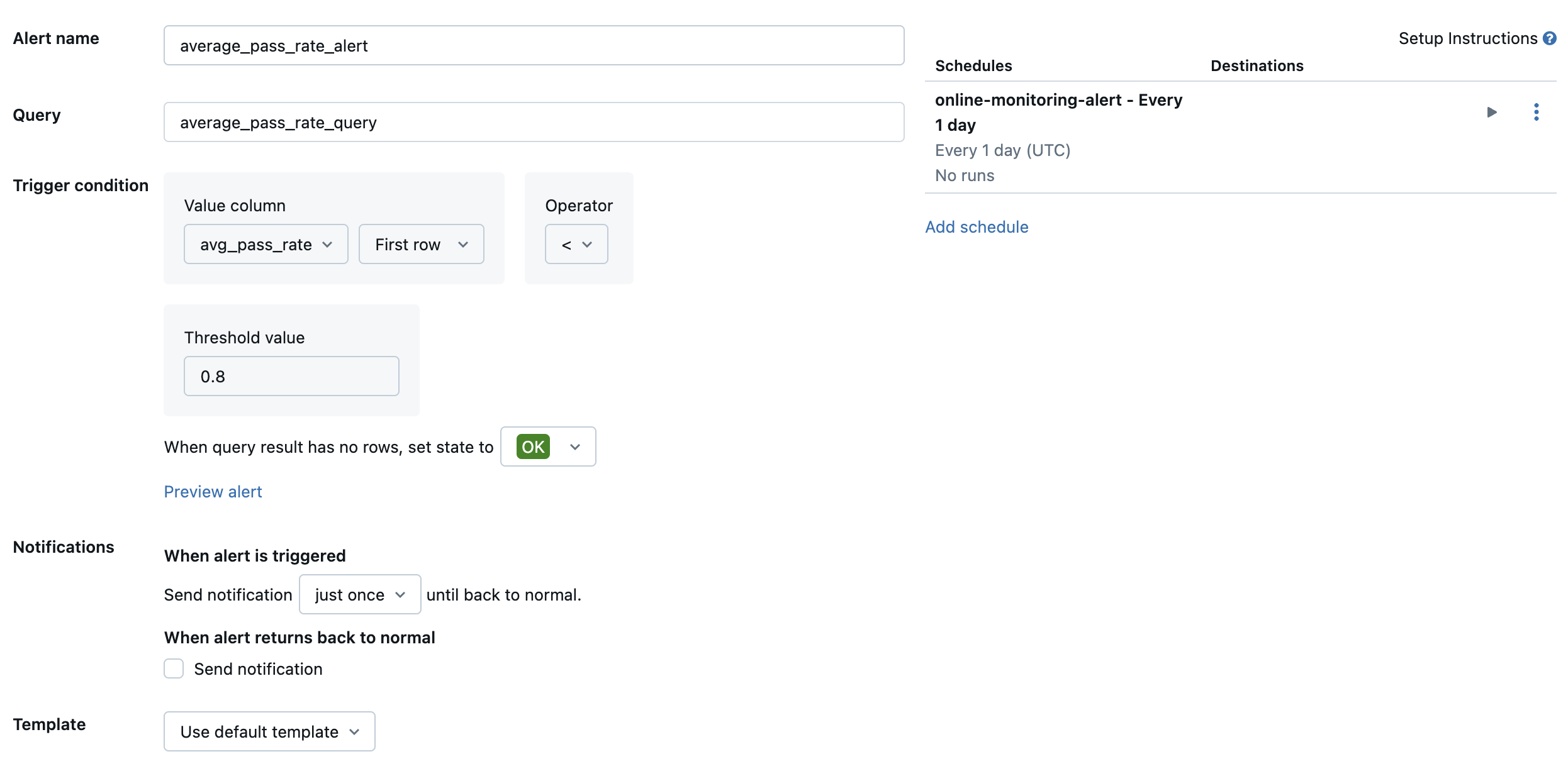
Per impostazione predefinita, viene inviata una notifica tramite posta elettronica. È anche possibile configurare un webhook o inviare notifiche ad altre applicazioni, ad esempio Slack o PagerDuty.
Aggiungere i log di produzione selezionati all'app di revisione per la revisione umana
Quando gli utenti forniscono commenti e suggerimenti sulle richieste, è possibile richiedere agli esperti dell'argomento di esaminare le richieste con feedback negativo (richieste con pollici in giù sulla risposta o sul recupero). A tale scopo, aggiungi log specifici all'app di revisione per richiedere una revisione dell'esperto.
Il codice seguente mostra una query di esempio sulla tabella dei log di valutazione per recuperare la valutazione umana più recente per ID richiesta e ID origine:
with ranked_logs as (
select
`timestamp`,
request_id,
source.id as source_id,
text_assessment.ratings["answer_correct"]["value"] as text_rating,
retrieval_assessment.ratings["answer_correct"]["value"] as retrieval_rating,
retrieval_assessment.position as retrieval_position,
row_number() over (
partition by request_id, source.id, retrieval_assessment.position order by `timestamp` desc
) as rank
from {assessment_log_table_name}
)
select
request_id,
source_id,
text_rating,
retrieval_rating
from ranked_logs
where rank = 1
order by `timestamp` desc
Nel codice seguente sostituire ... nella riga human_ratings_query = "..." con una query simile a quella precedente. Il codice seguente estrae quindi le richieste con feedback negativo e le aggiunge all'app di revisione:
from databricks import agents
human_ratings_query = "..."
human_ratings_df = spark.sql(human_ratings_query).toPandas()
# Filter out the positive ratings, leaving only negative and "IDK" ratings
negative_ratings_df = human_ratings_df[
(human_ratings_df["text_rating"] != "positive") | (human_ratings_df["retrieval_rating"] != "positive")
]
negative_ratings_request_ids = negative_ratings_df["request_id"].drop_duplicates().to_list()
agents.enable_trace_reviews(
model_name=YOUR_MODEL_NAME,
request_ids=negative_ratings_request_ids,
)
Per altri dettagli sull'app di revisione, vedere Ottenere commenti e suggerimenti sulla qualità di un'applicazione agente.