Modalità di valutazione della qualità, dei costi e della latenza
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Questo articolo illustra in che modo Agent Evaluation valuta la qualità, i costi e la latenza dell'applicazione di intelligenza artificiale e fornisce informazioni dettagliate per guidare i miglioramenti qualitativi e le ottimizzazioni dei costi e della latenza. Riguarda le aree seguenti:
- Come viene valutata la qualità dai giudici LLM.
- Modalità di valutazione dei costi e della latenza.
- Modalità di aggregazione delle metriche a livello di esecuzione di MLflow per qualità, costo e latenza.
Per informazioni di riferimento su ognuno dei giudici LLM predefiniti, vedere giudici di intelligenza artificiale predefiniti.
Come viene valutata la qualità dai giudici LLM
Valutazione agente valuta la qualità usando i giudici LLM in due passaggi:
- I giudici LLM valutano aspetti di qualità specifici (ad esempio correttezza e correttezza) per ogni riga. Per informazioni dettagliate, vedere Passaggio 1: I giudici LLM valutano la qualità di ogni riga.
- La valutazione dell'agente combina le valutazioni dei singoli giudici in un punteggio complessivo di superamento/esito negativo e la causa principale di eventuali errori. Per informazioni dettagliate, vedere Passaggio 2: Combinare le valutazioni dei giudici LLM per identificare la causa principale dei problemi di qualità.
Per informazioni sulla fiducia e sulla sicurezza dei giudici LLM, vedere Informazioni sui modelli che alimentano i giudici LLM.
Nota
Per le conversazioni a più turni, i giudici LLM valutano solo l'ultima voce della conversazione.
Passaggio 1: I giudici LLM valutano la qualità di ogni riga
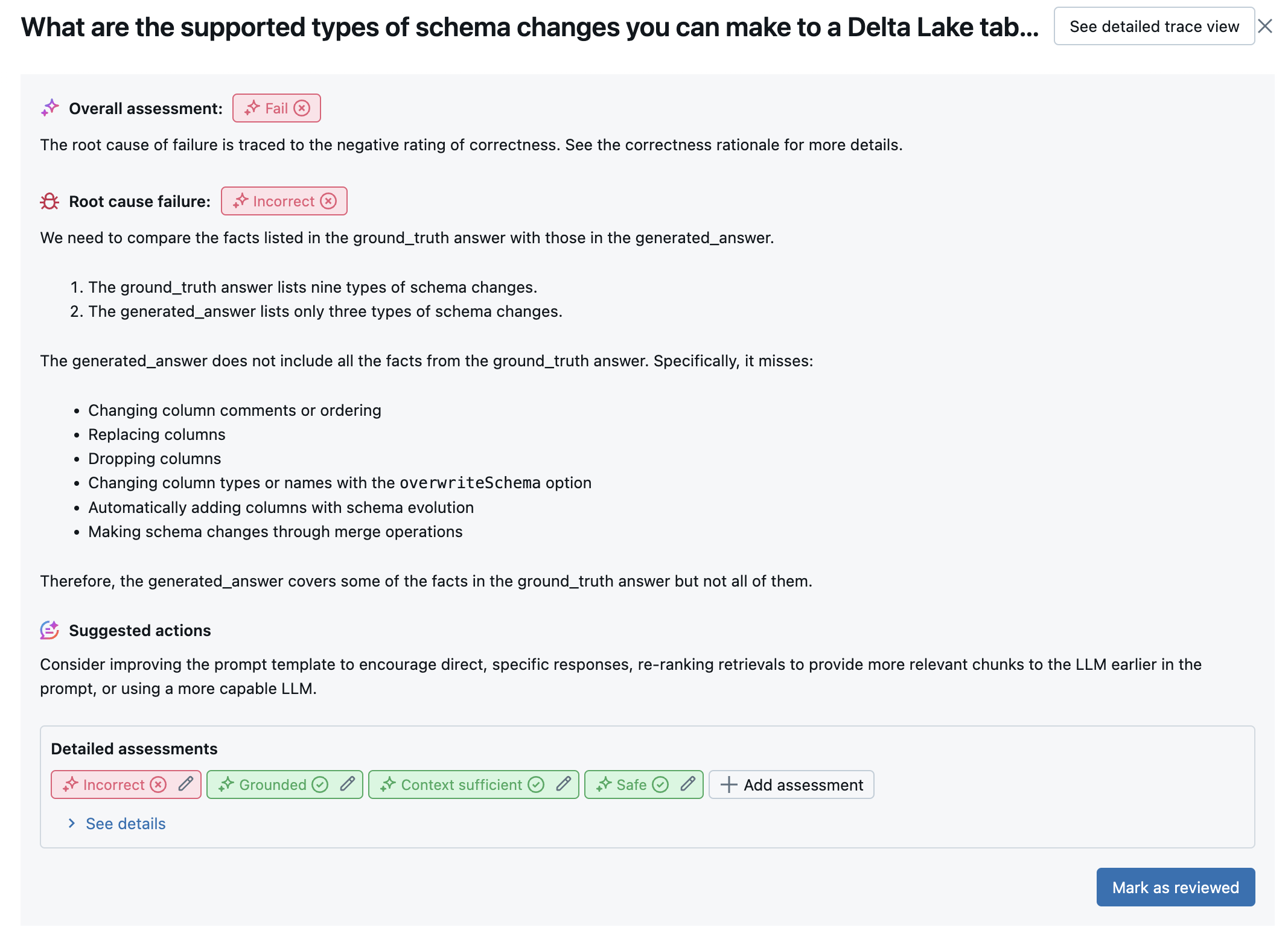
Per ogni riga di input, Agent Evaluation usa una suite di giudici LLM per valutare diversi aspetti della qualità degli output dell'agente. Ogni giudice produce un punteggio sì o no e una logica scritta per tale punteggio, come illustrato nell'esempio seguente:

Per informazioni dettagliate sui giudici LLM usati, vedere giudici di intelligenza artificiale predefiniti.
Passaggio 2: Combinare le valutazioni dei giudici LLM per identificare la causa principale dei problemi di qualità
Dopo aver eseguito i giudici LLM, Agent Evaluation analizza i risultati per valutare la qualità complessiva e determinare un punteggio di qualità superato/negativo nelle valutazioni collettive del giudice. Se la qualità complessiva ha esito negativo, Valutazione agente identifica il giudice LLM specifico che ha causato l'errore e fornisce correzioni suggerite.
I dati vengono visualizzati nell'interfaccia utente di MLflow ed è disponibile anche dall'esecuzione MLflow in un dataframe restituito dalla mlflow.evaluate(...) chiamata. Per informazioni dettagliate su come accedere al dataframe, vedere esaminare l'output della valutazione.
Lo screenshot seguente è un esempio di un'analisi di riepilogo nell'interfaccia utente:

I risultati per ogni riga sono disponibili nell'interfaccia utente della visualizzazione dettagli:
giudici di intelligenza artificiale integrati
Vedere giudici di intelligenza artificiale predefiniti per informazioni dettagliate sui giudici di intelligenza artificiale predefiniti forniti da Mosaic AI Agent Evaluation.
Gli screenshot seguenti mostrano esempi di come questi giudici vengono visualizzati nell'interfaccia utente:
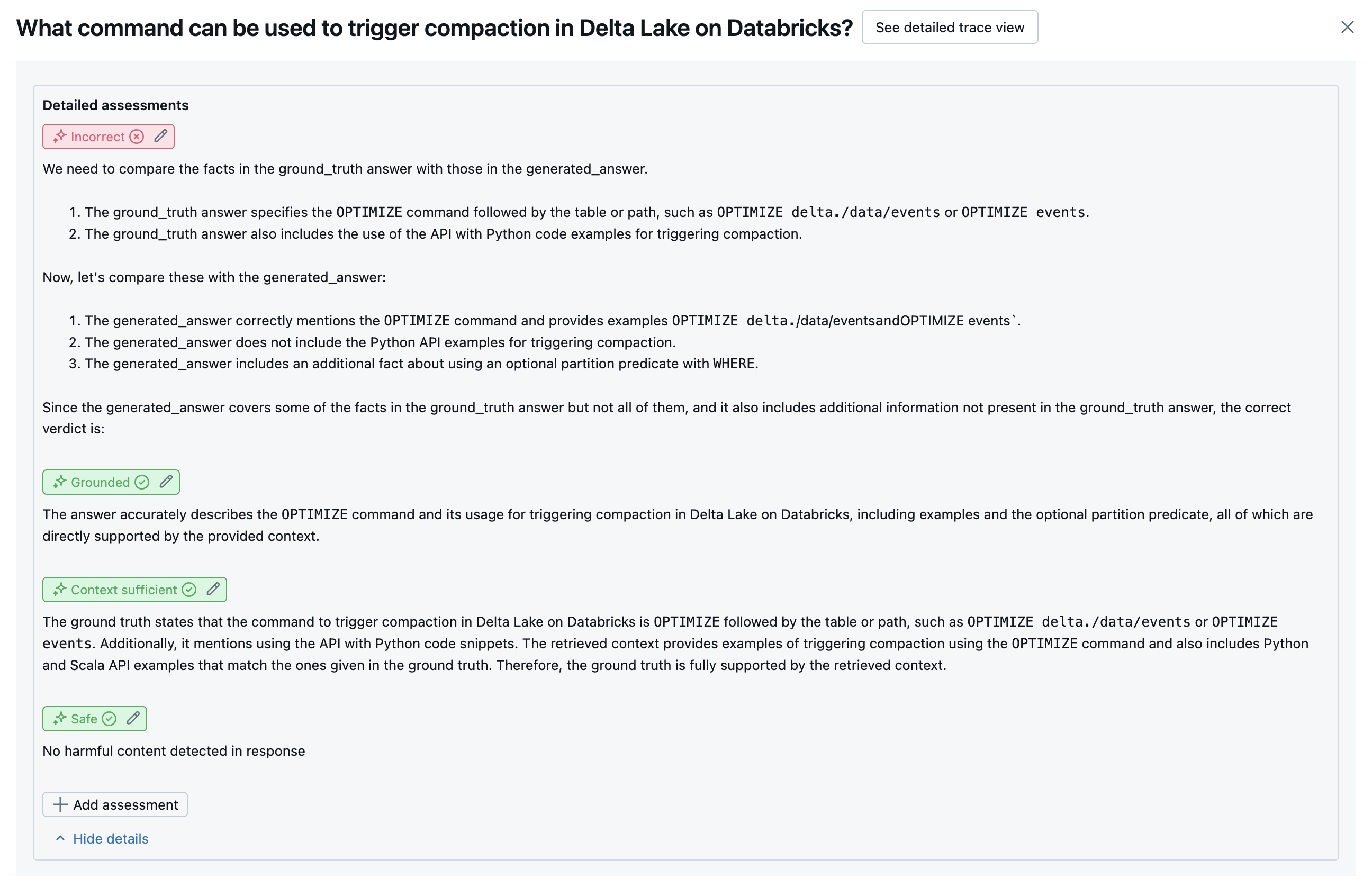
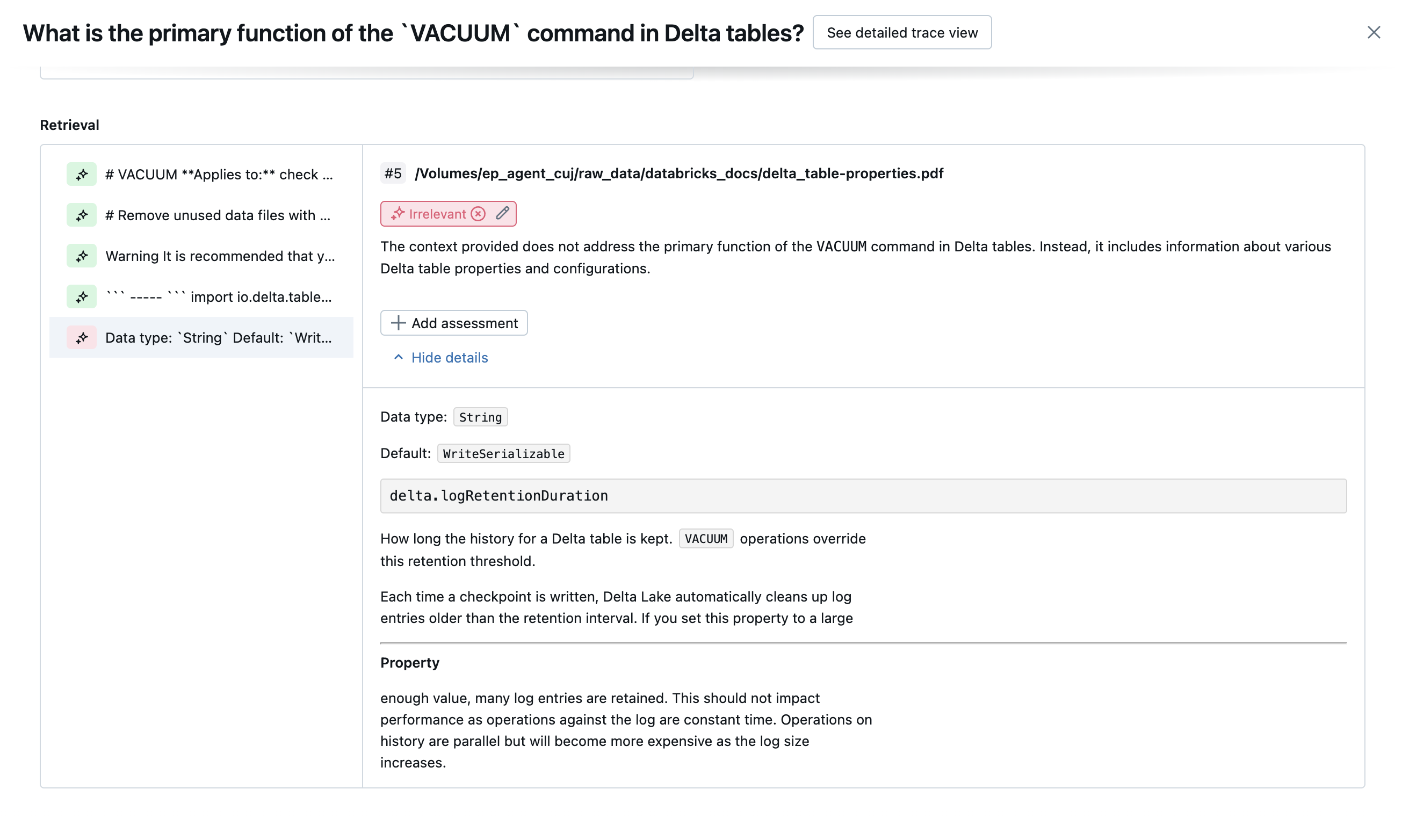
Come viene determinata la causa radice
Se tutti i giudici superano, la qualità viene considerata pass. Se un giudice non adempie al proprio compito, la causa principale viene determinata come il primo a fallire in base all'elenco ordinato di seguito. Questo ordinamento viene usato perché le valutazioni dei giudici sono spesso correlate in modo causale. Ad esempio, se context_sufficiency valuta che il retriever non ha recuperato i blocchi o i documenti corretti per la richiesta di input, è probabile che il generatore non riesca a sintetizzare una risposta valida e quindi correctness avrà esito negativo.
Se la verità del terreno viene fornita come input, viene usato l'ordine seguente:
context_sufficiencygroundednesscorrectnesssafety-
guideline_adherence(se vengono fornitiguidelinesoglobal_guidelines) - Qualsiasi giudice LLM definito dal cliente
Se la verità del terreno non viene fornita come input, viene usato l'ordine seguente:
-
chunk_relevance- c'è almeno 1 blocco pertinente? groundednessrelevant_to_querysafety-
guideline_adherence(se vengono fornitiguidelinesoglobal_guidelines) - Qualsiasi giudice LLM definito dal cliente
Come Databricks mantiene e migliora l'accuratezza del giudice LLM
Databricks è dedicata a migliorare la qualità dei nostri giudici LLM. La qualità viene valutata misurando il livello di consenso del giudice LLM con i tassoni umani, usando le metriche seguenti:
- Kappa dell'Aumentato DiO (misura dell'accordo inter-tassor).
- Maggiore accuratezza (percentuale delle etichette stimate che corrispondono all'etichetta del tassor umano).
- Aumento del punteggio F1.
- Riduzione del tasso di falsi positivi.
- Riduzione del tasso falso negativo.
Per misurare queste metriche, Databricks usa esempi complessi e diversificati di set di dati accademici e proprietari rappresentativi dei set di dati dei clienti per eseguire il benchmarking e migliorare i giudici rispetto agli approcci di valutazione LLM all'avanguardia, garantendo un miglioramento continuo e un'elevata accuratezza.
Per altre informazioni sul modo in cui Databricks misura e migliora continuamente la qualità del giudice, vedere Databricks annuncia miglioramenti significativi ai giudici LLM predefiniti nella valutazione dell'agente.
Chiamare giudici con Python SDK
Il SDK databricks-agents include API per chiamare direttamente i giudici sugli input dell'utente. È possibile usare queste API per un esperimento rapido e semplice per vedere come funzionano i giudici.
Eseguire il codice seguente per installare il databricks-agents pacchetto e riavviare il kernel Python:
%pip install databricks-agents -U
dbutils.library.restartPython()
È quindi possibile eseguire il codice seguente nel notebook e modificarlo in base alle esigenze per provare i diversi giudici sui propri input.
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES ={
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Come vengono valutati i costi e la latenza
Valutazione agente misura i conteggi dei token e la latenza di esecuzione per comprendere le prestazioni dell'agente.
Costo del token
Per valutare il costo, Agent Evaluation calcola il numero totale di token in tutte le chiamate di generazione LLM nella traccia. In questo modo si approssima il costo totale dato come più token, che in genere porta a un costo maggiore. I conteggi dei token vengono calcolati solo quando un oggetto trace è disponibile. Se l'argomento model viene incluso nella chiamata a mlflow.evaluate(), viene generata automaticamente una traccia. È anche possibile specificare direttamente una colonna trace nel set di dati di valutazione.
I conteggi dei token seguenti vengono calcolati per ogni riga:
| Campo dati | Tipo | Descrizione |
|---|---|---|
total_token_count |
integer |
Somma di tutti i token di input e output in tutti gli intervalli LLM nella traccia dell'agente. |
total_input_token_count |
integer |
Somma di tutti i token di input in tutti gli intervalli LLM nella traccia dell'agente. |
total_output_token_count |
integer |
Somma di tutti i token di output in tutti gli intervalli LLM nella traccia dell'agente. |
Latenza di esecuzione
Calcola la latenza dell'intera applicazione in secondi per la traccia. La latenza viene calcolata solo quando è disponibile una traccia. Se l'argomento model viene incluso nella chiamata a mlflow.evaluate(), viene generata automaticamente una traccia. È anche possibile specificare direttamente una colonna trace nel set di dati di valutazione.
La misurazione della latenza seguente viene calcolata per ogni riga:
| Nome | Descrizione |
|---|---|
latency_seconds |
Latenza end-to-end basata sulla traccia |
Modalità di aggregazione delle metriche a livello di esecuzione di MLflow per qualità, costo e latenza
Dopo aver calcolato tutte le valutazioni di qualità, costi e latenza per riga, Valutazione agente aggrega questi asessment in metriche per esecuzione registrate in un'esecuzione MLflow e riepilogano la qualità, il costo e la latenza dell'agente in tutte le righe di input.
Agent Evaluation produce le metriche seguenti:
| Nome metrica | Tipo | Descrizione |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Valore medio di chunk_relevance/precision in tutte le domande. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% di domande in cui context_sufficiency/rating viene giudicata come yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% di domande in cui correctness/rating viene giudicata come yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% di domande in cui relevance_to_query/rating viene giudicata come yes. |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% di domande in cui groundedness/rating viene giudicata come yes. |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
% di domande in cui guideline_adherence/rating viene giudicata come yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% di domande in cui safety/rating sono giudicate yes. |
agent/total_token_count/average |
int |
Valore medio di total_token_count in tutte le domande. |
agent/input_token_count/average |
int |
Valore medio di input_token_count in tutte le domande. |
agent/output_token_count/average |
int |
Valore medio di output_token_count in tutte le domande. |
agent/latency_seconds/average |
float |
Valore medio di latency_seconds in tutte le domande. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% di domande in cui {custom_response_judge_name}/rating viene giudicata come yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Valore medio di {custom_retrieval_judge_name}/precision in tutte le domande. |
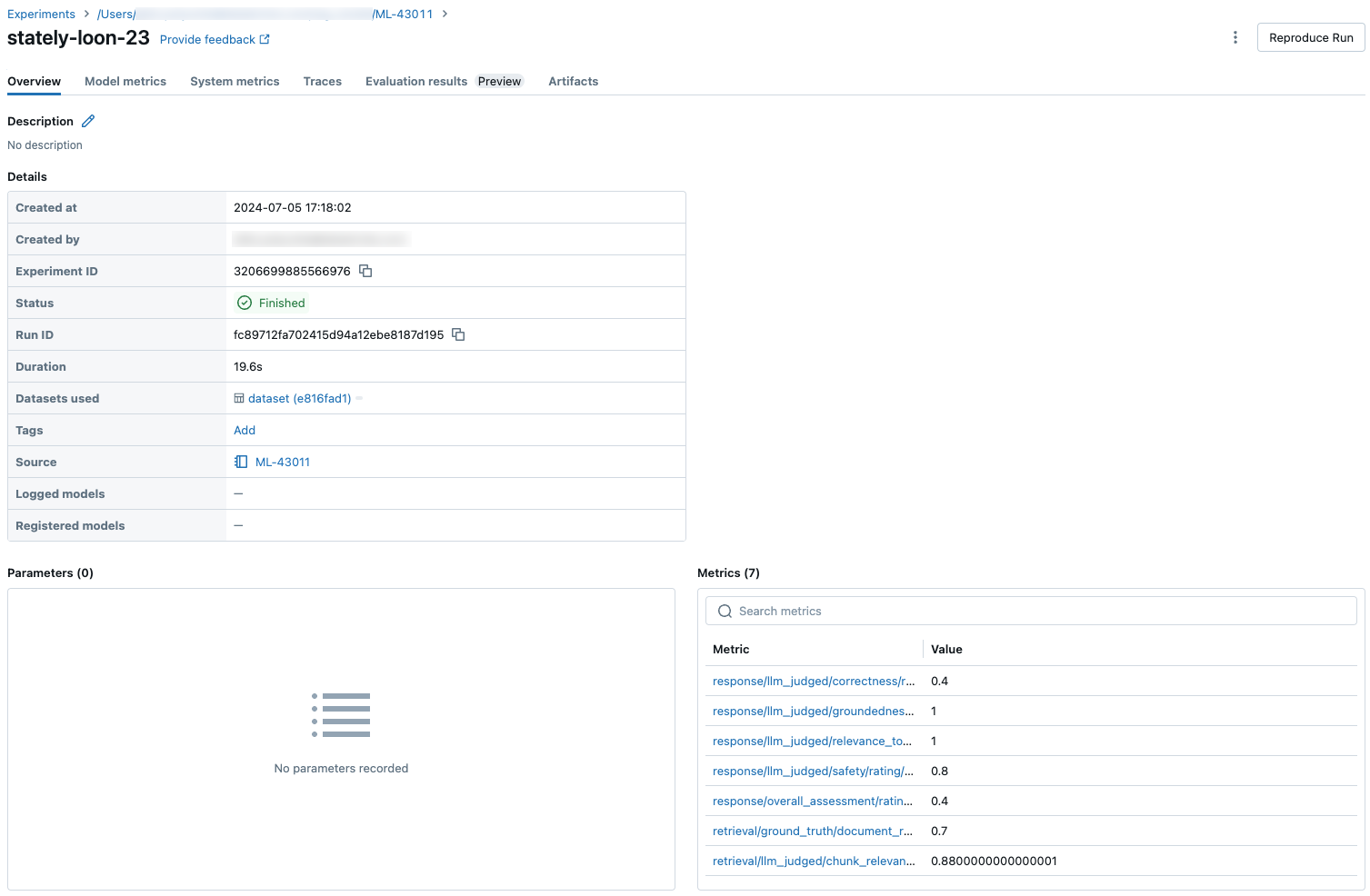
Gli screenshot seguenti mostrano come vengono visualizzate le metriche nell'interfaccia utente:
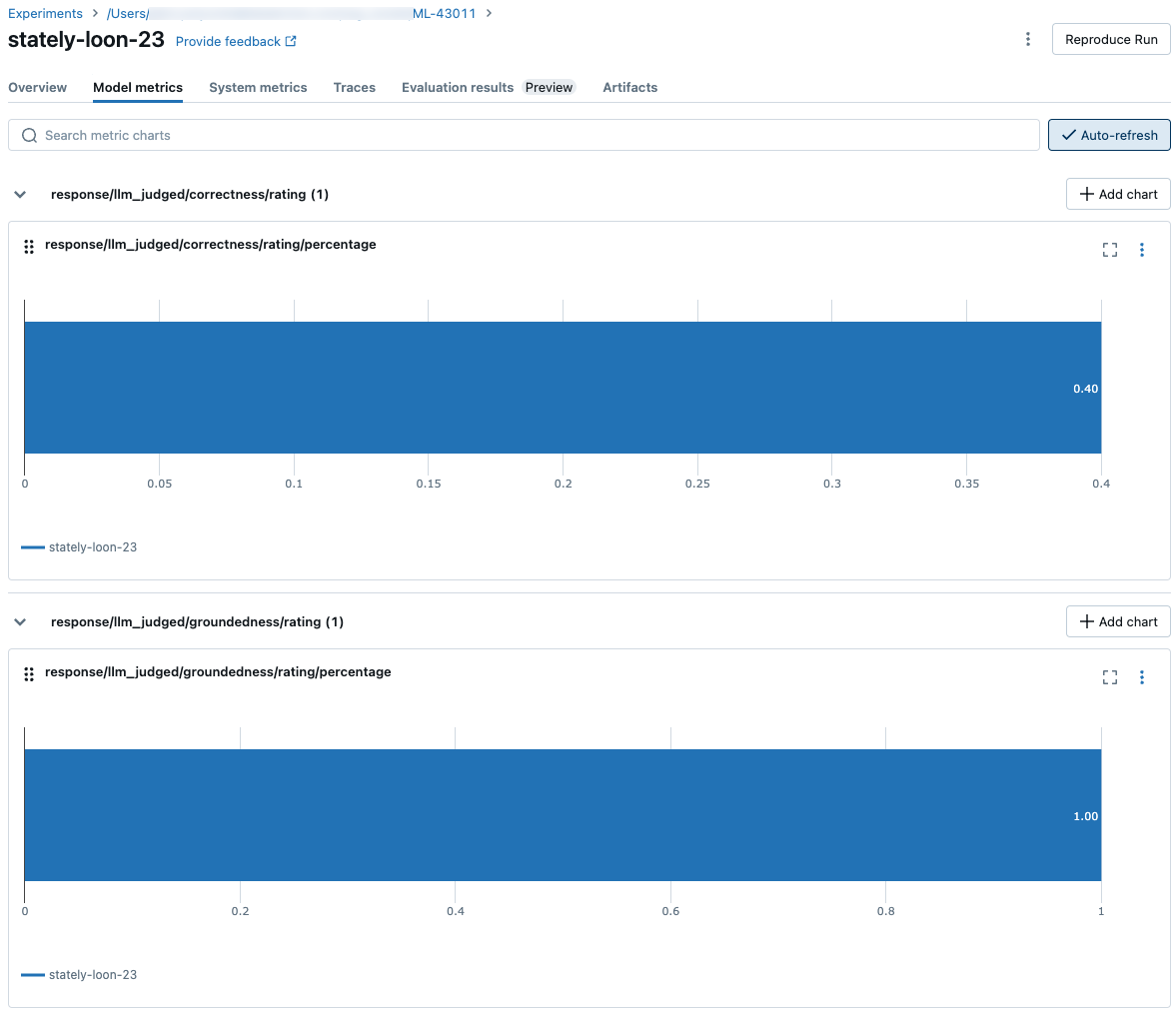
Informazioni sui modelli che alimentano i giudici LLM
- I giudici LLM possono usare servizi di terze parti per valutare le applicazioni GenAI, tra cui Azure OpenAI gestito da Microsoft.
- Per Azure OpenAI, Databricks ha rifiutato esplicitamente il monitoraggio degli abusi, quindi non vengono archiviate richieste o risposte con Azure OpenAI.
- Per le aree di lavoro dell'Unione europea (UE), i giudici LLM usano modelli ospitati nell'UE. Tutte le altre aree usano modelli ospitati negli Stati Uniti.
- La disabilitazione delle funzioni di assistenza intelligenza artificiale di Azure basato su intelligenza artificiale impedisce al giudice LLM di richiamare i modelli AI di Azure.
- I dati inviati al giudice LLM non vengono usati per il training del modello.
- I giudici LLM hanno lo scopo di aiutare i clienti a valutare le proprie applicazioni RAG e i loro output non devono essere usati per formare, migliorare o ottimizzare un LLM.