Ripristino di emergenza
Un modello chiaro di ripristino di emergenza è fondamentale per una piattaforma di analisi dei dati nativa del cloud, ad esempio Azure Databricks. È fondamentale che i team di dati possano usare la piattaforma Azure Databricks anche nel raro caso di un'interruzione del provider di servizi cloud a livello di area, a causa di un'emergenza a livello di area, ad esempio un uragano o un terremoto o un'altra origine.
Azure Databricks è spesso una parte fondamentale di un ecosistema di dati complessivo che include molti servizi, tra cui servizi di inserimento dati upstream (batch/streaming), archiviazione nativa del cloud come ADLS gen2 (per le aree di lavoro create prima del 6 marzo 2023, Archiviazione BLOB di Azure), strumenti e servizi downstream come app di business intelligence e strumenti di orchestrazione. Alcuni casi d'uso potrebbero essere particolarmente sensibili a un'interruzione del servizio a livello di area.
Questo articolo descrive i concetti e le procedure consigliate per una soluzione ottimale di ripristino di emergenza interregionale per la piattaforma Databricks.
Garanzie di disponibilità elevata all'interno dell'area
Mentre il resto di questo argomento è incentrato sull'implementazione del ripristino di emergenza tra aree, è importante comprendere le garanzie di disponibilità elevata fornite da Azure Databricks all'interno della singola area. Le garanzie di disponibilità elevata all'interno dell'area coprono i componenti seguenti:
Disponibilità del piano di controllo di Azure Databricks
- La maggior parte dei servizi del piano di controllo sono in esecuzione nei cluster Kubernetes e gestirà automaticamente la perdita di macchine virtuali nello specifico AZ.
- I dati dell'area di lavoro vengono archiviati nei database con archiviazione premium, replicati nell'area. L'archiviazione del database (server singolo) non viene replicata in aree o AZ diverse. Se l'interruzione della zona influisce sull'archiviazione del database, il database viene ripristinato mediante la preparazione di una nuova istanza dal backup.
- Anche gli account di archiviazione usati per gestire le immagini DBR sono ridondanti all'interno dell'area e tutte le aree hanno account di archiviazione secondari usati quando quello primario è inattivo. Vedere Aree di Azure Databricks.
- In generale, la funzionalità del piano di controllo deve essere ripristinata entro circa 15 minuti dopo il ripristino della zona di disponibilità.
Disponibilità del piano di calcolo
- La disponibilità dell'area di lavoro dipende dalla disponibilità del piano di controllo (come descritto in precedenza).
- I dati nella radice DBFS non sono interessati se l'account di archiviazione per la radice DBFS è configurato con ZRS o archiviazione con ridondanza geografica della zona (l'impostazione predefinita è archiviazione con ridondanza geografica).
- I nodi per i cluster vengono estratti dalle diverse zone di disponibilità richiedendo nodi dal provider di calcolo di Azure (supponendo che la capacità delle zone rimanenti sia sufficiente a soddisfare la richiesta.). Se un nodo viene perso, la gestione dei cluster richiede nodi sostitutivi dal provider di calcolo di Azure, che li estrae dalle zone di disponibilità disponibili. L'unica eccezione è quando il nodo driver viene perso. In questo caso, il processo o il gestore cluster li riavvia.
Panoramica del ripristino di emergenza
Il ripristino di emergenza prevede un set di criteri, strumenti e procedure che consentono il ripristino o la continuazione di infrastrutture e sistemi tecnologici vitali in seguito a un disastro naturale o indotto dall'uomo. Un servizio cloud di grandi dimensioni, come Azure, serve molti clienti e dispone di guard predefiniti per un singolo errore. Ad esempio, un'area è un gruppo di edifici collegati a diverse fonti di energia per garantire che una singola perdita di energia non arresti un'area. Tuttavia, gli errori dell'area cloud possono verificarsi e il grado di interruzione e il suo impatto sull'organizzazione possono variare.
Prima di implementare un piano di ripristino di emergenza, è importante comprendere la differenza tra il ripristino di emergenza (DR) e la disponibilità elevata (HA).
La disponibilità elevata è una caratteristica di resilienza di un sistema. La disponibilità elevata garantisce un livello minimo di prestazioni operative generalmente definite in termini di tempo di attività coerente o percentuale di tempo di attività. La disponibilità elevata viene implementata sul luogo (nella stessa area del sistema primario) progettandola come funzionalità del sistema primario. Ad esempio, i servizi cloud come Azure hanno servizi a disponibilità elevata, come ADLS Gen2 (per le aree di lavoro create prima del 6 marzo 2023, Archiviazione BLOB di Azure). La disponibilità elevata non richiede una preparazione esplicita significativa del cliente di Azure Databricks.
Al contrario, un piano di ripristino di emergenza richiede decisioni e soluzioni che permettano a un'organizzazione specifica di gestire un'interruzione a livello di area più ampia per i sistemi critici. Questo articolo illustra la terminologia comune del ripristino di emergenza, le soluzioni comuni e alcune procedure consigliate per i piani di ripristino di emergenza con Azure Databricks.
Terminologia
Terminologia di area
Questo articolo usa le definizioni seguenti per le aree:
Area primaria: area geografica in cui gli utenti eseguono tipici carichi di lavoro quotidiani di analisi dei dati interattivi e automatizzati.
Area secondaria: area geografica in cui i team IT spostano temporaneamente i carichi di lavoro di analisi dei dati durante un'interruzione nell'area primaria.
Archiviazione con ridondanza geografica: Azure dispone di archiviazione con ridondanza geografica tra aree per l'archiviazione persistente usando un processo di replica asincrona di archiviazione.
Importante
Per i processi di ripristino di emergenza, Databricks consiglia di non basarsi sull'archiviazione con ridondanza geografica per la duplicazione di dati tra aree, come ADLS Gen2 (per le aree di lavoro create prima del 6 marzo 2023, Archiviazione BLOB di Azure) create da Azure Databricks per ogni area di lavoro nella sottoscrizione di Azure. In generale, usare Deep Clone per le tabelle Delta e convertire i dati in formato Delta per usare Deep Clone, se possibile per altri formati di dati.
Terminologia relativa allo stato della distribuzione
Questo articolo usa le definizioni seguenti dello stato della distribuzione:
Distribuzione attiva: gli utenti possono connettersi a una distribuzione attiva di un'area di lavoro di Azure Databricks ed eseguire carichi di lavoro. I processi vengono pianificati periodicamente usando il pianificatore di Azure Databricks o un altro meccanismo. I flussi di dati possono essere eseguiti anche in questa distribuzione. Alcuni documenti potrebbero fare riferimento a una distribuzione attiva come distribuzione ad accesso frequente.
Distribuzione passiva: i processi non vengono eseguiti in una distribuzione passiva. I team IT possono configurare procedure automatizzate per distribuire codice, configurazione e altri oggetti di Azure Databricks nella distribuzione passiva. Una distribuzione diventa attiva solo se è inattiva una distribuzione attiva corrente. Alcuni documenti potrebbero fare riferimento a una distribuzione passiva come distribuzione a freddo.
Importante
Un progetto può facoltativamente includere più distribuzioni passive in aree diverse per fornire opzioni aggiuntive per la risoluzione delle interruzioni a livello di area.
In generale, un team ha una sola distribuzione attiva alla volta, in una strategia di ripristino di emergenza denominata attiva-passiva. Esiste una strategia di soluzione di ripristino di emergenza meno comune denominata attivo-attivo, in cui sono presenti due distribuzioni attive simultanee.
Terminologia del settore del ripristino di emergenza
Esistono due importanti termini del settore che è necessario comprendere e definire per il team:
Obiettivo del punto di ripristino: un obiettivo del punto di ripristino (RPO) è il periodo di destinazione massimo in cui i dati (transazioni) potrebbero andare persi da un servizio IT a causa di un incidente grave. La distribuzione di Azure Databricks non archivia i dati principali dei clienti. Questo è archiviato in sistemi separati, ad esempio ADLS Gen2 (per le aree di lavoro create prima del 6 marzo 2023, Archiviazione BLOB di Azure) o in altre origini dati di cui si ha il controllo. Il piano di controllo di Azure Databricks archivia alcuni oggetti in parte o completi, ad esempio processi e notebook. Per Azure Databricks, l'RPO viene definito come periodo di destinazione massimo in cui gli oggetti, ad esempio le modifiche di processo e notebook, possono essere persi. Inoltre, l'utente è responsabile della definizione dell'RPO per i propri dati dei clienti in ADLS Gen2 (per le aree di lavoro create prima del 6 marzo 2023, Archiviazione BLOB di Azure) o altre origini dati di cui si ha il controllo.
Obiettivo del tempo di ripristino: l’obiettivo del tempo di ripristino (RTO) è la durata di tempo di destinazione e un livello di servizio entro il quale un processo aziendale deve essere ripristinato dopo un'emergenza.
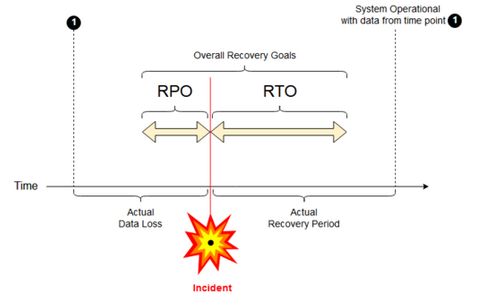
Ripristino di emergenza e danneggiamento dei dati
Una soluzione di ripristino di emergenza non riduce il danneggiamento dei dati. I dati danneggiati nell'area primaria vengono replicati dall'area primaria a un'area secondaria e sono danneggiati in entrambe le aree. Esistono altri modi per attenuare questo tipo di errore, ad esempio il viaggio in tempo delta.
Flusso di lavoro di ripristino tipico
Uno scenario di ripristino di emergenza di Azure Databricks in genere si verifica nel modo seguente:
Un errore si verifica in un servizio critico usato nell'area primaria. Può trattarsi di un servizio origine dati o di una rete che influisce sulla distribuzione di Azure Databricks.
Si esamina la situazione con il provider di servizi cloud.
Se si conclude che l'azienda non può attendere che il problema venga risolto nell'area primaria, potrebbe essere necessario eseguire il failover in un'area secondaria.
Verificare che lo stesso problema non influisca anche sull'area secondaria.
Eseguire il failover in un'area secondaria.
- Arrestare tutte le attività nell'area di lavoro. Gli utenti arrestano i carichi di lavoro. Se possibile, gli utenti o gli amministratori eseguono il backup delle modifiche recenti. I processi vengono arrestati se non sono falliti a causa dell'interruzione.
- Avviare la procedura di ripristino nell'area secondaria. La procedura di ripristino aggiorna il routing e la ridenominazione delle connessioni e del traffico di rete all'area secondaria.
- Dopo il test, dichiarare l'area secondaria operativa. I carichi di lavoro di produzione possono ora riprendere. Gli utenti possono accedere alla distribuzione ora attiva. È possibile ritentare i processi pianificati o posticipati.
Per i passaggi dettagliati in un contesto di Azure Databricks, vedere Failover di test.
A un certo punto, il problema nell'area primaria è mitigato e si conferma questo fatto.
Ripristinare (failback) nell'area primaria.
- Arrestare tutto il lavoro nell'area secondaria.
- Avviare la procedura di ripristino nell'area primaria. La procedura di ripristino gestisce il routing e la ridenominazione della connessione e del traffico di rete all'area primaria.
- Replicare i dati nell'area primaria in base alle esigenze. Per ridurre la complessità, ridurre al minimo la quantità di dati da replicare. Ad esempio, se alcuni processi sono di sola lettura quando vengono eseguiti nella distribuzione secondaria, potrebbe non essere necessario replicare i dati nella distribuzione primaria nell'area primaria. Tuttavia, potrebbe essere presente un processo di produzione che deve essere eseguito e potrebbe richiedere la replica dei dati nell'area primaria.
- Testare la distribuzione nell'area primaria.
- Dichiarare l'area primaria operativa e che si tratta della distribuzione attiva. Riprendere i carichi di lavoro di produzione.
Per maggiori informazioni sul ripristino nell'area primaria, vedere Testare il ripristino (failback).
Importante
Durante questi passaggi, potrebbe verificarsi una perdita di dati. L'organizzazione deve definire la quantità di perdita di dati accettabile e le operazioni che è possibile eseguire per attenuare tale perdita.
Passaggio 1: Comprendere le esigenze aziendali
Il primo passaggio consiste nel definire e comprendere le esigenze aziendali. Definire quali servizi dati sono critici e quali sono i valori RPO e RTO previsti.
Ricercare la tolleranza reale di ogni sistema e ricordare che il failover e il failback di ripristino di emergenza possono essere costosi e comportano altri rischi. Altri rischi possono includere il danneggiamento dei dati, i dati duplicati se si scrive nella posizione di archiviazione errata e gli utenti che accedono e apportano modifiche nelle posizioni sbagliate.
Eseguire il mapping di tutti i punti di integrazione di Azure Databricks che influiscono sul proprio lavoro:
- La soluzione di ripristino di emergenza deve supportare processi interattivi, processi automatizzati o entrambi?
- Quali servizi dati si usano? Alcuni potrebbero essere locali.
- In che modo i dati di input arrivano al cloud?
- Chi utilizza questi dati? Quali processi lo usano downstream?
- Sono presenti integrazioni di terze parti che devono essere consapevoli delle modifiche al ripristino di emergenza?
Determinare gli strumenti o le strategie di comunicazione che possono supportare il piano di ripristino di emergenza:
- Quali strumenti verranno usati per modificare rapidamente le configurazioni di rete?
- È possibile predefinire la configurazione e renderla modulare per supportare soluzioni di ripristino di emergenza in modo naturale e gestibile?
- Quali strumenti e canali di comunicazione informeranno i team interni e le terze parti (integrazioni, consumer downstream) del failover di ripristino di emergenza e delle modifiche di failback? E come confermate il loro riconoscimento?
- Quali strumenti o supporto speciale saranno necessari?
- Quali servizi potrebbero avere un arresto fino al completamento del ripristino?
Passaggio 2: scegliere un processo che soddisfi le esigenze aziendali
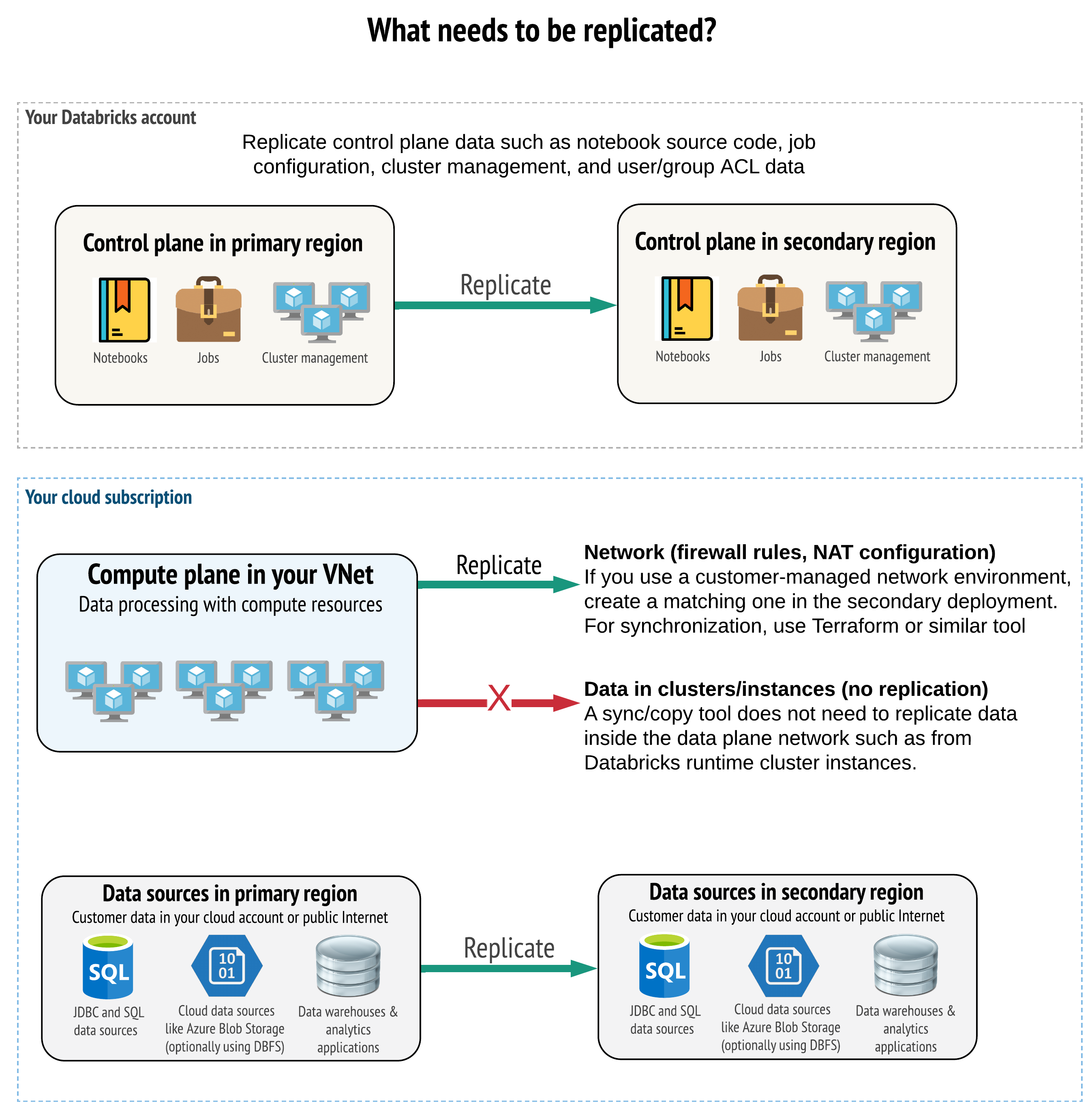
La soluzione deve replicare i dati corretti in entrambi i piani di controllo, piano di calcolo e origini dati. Le aree di lavoro ridondanti per il ripristino di emergenza devono essere mappate a piani di controllo diversi in aree diverse. È necessario mantenere i dati sincronizzati periodicamente usando una soluzione basata su script, uno strumento di sincronizzazione o un flusso di lavoro CI/CD. Non è necessario sincronizzare i dati dall'interno della rete del piano di calcolo stesso, ad esempio dai ruoli di lavoro di Databricks Runtime.
Se si usa la funzionalità di inserimento della rete virtuale (non disponibile con tutti i tipi di sottoscrizione e distribuzione), è possibile distribuire in modo coerente queste reti in entrambe le aree, usando strumenti basati su modelli come Terraform.
Inoltre, è necessario assicurarsi che le origini dati vengano replicate in base alle esigenze in tutte le aree.
Procedure consigliate generali
Le procedure consigliate generali per un corretto piano di ripristino di emergenza includono:
Comprendere quali processi sono fondamentali per l'azienda e devono essere eseguiti nel ripristino di emergenza.
Identificare chiaramente quali servizi sono coinvolti, quali dati vengono elaborati, qual è il flusso di dati e dove vengono archiviati
Isolare i servizi e i dati il più possibile. Ad esempio, creare un contenitore di archiviazione cloud speciale per i dati per il ripristino di emergenza o spostare gli oggetti di Azure Databricks necessari durante un'emergenza in un'area di lavoro separata.
È responsabilità dell'utente mantenere l'integrità tra le distribuzioni primarie e secondarie per altri oggetti non archiviati nel piano di controllo di Databricks.
Avviso
È consigliabile non archiviare i dati nella radice di ADLS Gen2 (per le aree di lavoro create prima del 6 marzo 2023, Archiviazione BLOB di Azure) usate per l'accesso radice DBFS per l'area di lavoro. L'archiviazione radice DBFS non è supportata per la produzione di dati dei clienti. Databricks consiglia anche di non archiviare librerie, file di configurazione o script init in questo percorso.
Per le origini dati, laddove possibile, è consigliabile usare strumenti nativi di Azure per la replica e la ridondanza per replicare i dati nelle aree di ripristino di emergenza.
Scegliere una strategia di soluzione di ripristino
Le soluzioni di ripristino di emergenza tipiche comportano due o più aree di lavoro. Esistono diverse strategie che è possibile scegliere. Considerare la durata potenziale dell'interruzione (qualche ora o un giorno intero), il lavoro necessario a garantire che l'area di lavoro sia completamente operativa e il tentativo di ripristino (failback) nell'area primaria.
Strategia della soluzione attiva-passiva
Una soluzione attiva-passiva è la soluzione più comune e più semplice e questo tipo di soluzione è l'obiettivo di questo articolo. Una soluzione attiva-passiva sincronizza le modifiche dei dati e degli oggetti dalla distribuzione attiva alla distribuzione passiva. Se si preferisce, è possibile avere più distribuzioni passive in aree diverse, tuttavia questo articolo si focalizza sull’approccio della distribuzione passiva singola. Durante un evento di ripristino di emergenza, la distribuzione passiva nell'area secondaria diventa la distribuzione attiva.
Esistono due varianti principali di questa strategia:
- Soluzione unificata (a livello aziendale): esattamente un set di distribuzioni attive e passive che supportano l'intera organizzazione.
- Soluzione per reparto o progetto: ogni dominio di reparto o progetto gestisce una soluzione di ripristino di emergenza separata. Alcune organizzazioni vogliono separare i dettagli del ripristino di emergenza tra i reparti e usare aree primarie e secondarie diverse per ogni team in base alle esigenze specifiche di ogni team.
Esistono altre varianti, ad esempio l'uso di una distribuzione passiva per i casi d'uso di sola lettura. Se si dispone di carichi di lavoro di sola lettura, ad esempio query utente, questi possono essere eseguiti in una soluzione passiva in qualsiasi momento se non modificano dati o oggetti di Azure Databricks, come notebook o processi.
Strategia della soluzione attiva-attiva
In una soluzione attiva-attiva vengono eseguiti tutti i processi di dati in entrambe le aree in parallelo. Il team operativo deve assicurarsi che un processo di dati, ad esempio un processo, sia contrassegnato come completato solo al termine corretto in entrambe le aree. Gli oggetti non possono essere modificati nell'ambiente di produzione e devono seguire una rigorosa promozione CI/CD dallo sviluppo/gestione temporanea all'ambiente di produzione.
Una soluzione attiva-attiva è la strategia più complessa e, poiché i processi vengono eseguiti in entrambe le aree, è previsto un costo finanziario aggiuntivo.
Proprio come per la strategia attiva-passiva, è possibile implementare questa soluzione come soluzione organizzativa unificata o per reparto.
Potrebbe non essere necessaria un'area di lavoro equivalente nel sistema secondario per tutte le aree di lavoro, a seconda del flusso di lavoro. Ad esempio, un'area di lavoro di sviluppo o di gestione temporanea potrebbe non avere bisogno di un duplicato. Con una pipeline di sviluppo ben progettata, è possibile ricostruire facilmente tali aree di lavoro, se necessario.
Scegliere gli strumenti
Esistono due approcci principali per gli strumenti per mantenere i dati il più simili possibile tra le aree di lavoro nelle aree primarie e secondarie:
- Client di sincronizzazione che copia da primario a secondario: un client di sincronizzazione esegue il push di dati e delle risorse di produzione dall'area primaria all'area secondaria. In genere, questa viene eseguita su base pianificata.
- Strumenti CI/CD per la distribuzione parallela: per il codice e le risorse di produzione, usare gli strumenti CI/CD che inseriscono le modifiche nei sistemi di produzione simultaneamente in entrambe le aree. Ad esempio, quando si esegue il push di codice e risorse dalla gestione temporanea/sviluppo alla produzione, un sistema CI/CD lo rende disponibile in entrambe le aree contemporaneamente. L'idea principale consiste nel considerare tutti gli artefatti in un'area di lavoro di Azure Databricks come infrastruttura-come-codice. La maggior parte degli artefatti può essere distribuita sia nelle aree di lavoro primarie che in quelle secondarie, mentre alcuni artefatti possono essere distribuiti solo dopo un evento di ripristino di emergenza. Per gli strumenti, vedere Script, esempi e prototipi di automazione.
Il diagramma seguente mette a confronto questi due approcci.
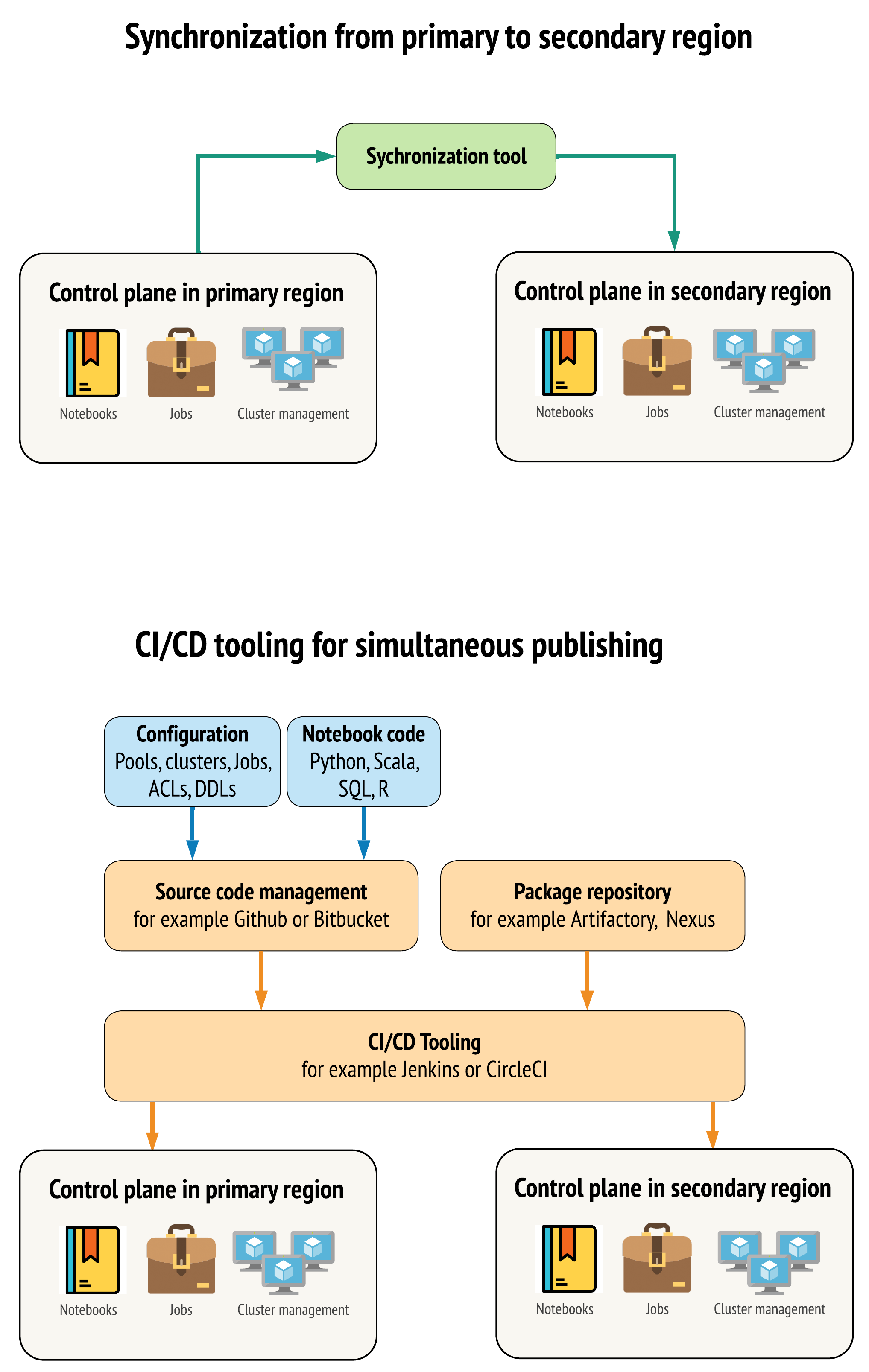
A seconda delle esigenze, è possibile combinare gli approcci. Ad esempio, usare CI/CD per il codice sorgente del notebook, ma usare la sincronizzazione per la configurazione, ad esempio pool e controlli di accesso.
Nella tabella seguente viene descritto come gestire tipi diversi di dati con ogni opzione di strumenti.
| Descrizione | Come gestire gli strumenti CI/CD | Come gestire con lo strumento di sincronizzazione |
|---|---|---|
| Codice sorgente: esportazioni dell'origine notebook e codice sorgente per le librerie in pacchetto | Eseguire la co-distribuzione sia nel database primario che secondario. | Sincronizzare il codice sorgente da primario a secondario. |
| Utenti e gruppi | Gestire i metadati come configurazione in Git. In alternativa, usare lo stesso provider di identità (IdP) per entrambe le aree di lavoro. Distribuire i dati di utenti e gruppi in distribuzioni primarie e secondarie. | Usare SCIM o un'altra automazione per entrambe le aree. La creazione manuale non è consigliata, ma se usata deve essere eseguita contemporaneamente. Se si usa un'installazione manuale, creare un processo automatizzato pianificato per confrontare l'elenco di utenti e gruppi tra le due distribuzioni. |
| Configurazioni dei pool | Può essere un modello in Git. Co-distribuzione in primario e secondario. Tuttavia, min_idle_instances in secondario deve essere zero fino all'evento di ripristino di emergenza. |
I pool creati con un min_idle_instances qualsiasi quando vengono sincronizzati con l'area di lavoro secondaria usando l'API o l'interfaccia della riga di comando. |
| Configurazioni del processo | Può essere un modello in Git. Per la distribuzione primaria, distribuire la definizione del processo così come è. Per la distribuzione secondaria, distribuire il processo e impostare le concorrenze su zero. In questo modo il processo in questa distribuzione viene disabilitato e viene impedita l'esecuzione aggiuntiva. Modificare il valore delle concorrenze dopo che la distribuzione secondaria diventa attiva. | Se i processi vengono eseguiti in cluster esistenti <interactive>, il client di sincronizzazione deve eseguire il mapping al corrispondente cluster_id nell'area di lavoro secondaria. |
| Elenchi di controllo di accesso (ACL) | Può essere un modello in Git. Co-distribuzione in distribuzioni primarie e secondarie per notebook, cartelle e cluster. Tuttavia, conservare i dati per i processi fino all'evento di ripristino di emergenza. | L'API Autorizzazioni può impostare controlli di accesso per cluster, processi, pool, notebook e cartelle. Un client di sincronizzazione deve eseguire il mapping agli ID oggetto corrispondenti per ogni oggetto nell'area di lavoro secondaria. Databricks consiglia di creare una mappa di ID oggetto dall'area di lavoro primaria a quella secondaria durante la sincronizzazione di tali oggetti prima di replicare i controlli di accesso. |
| Librerie | Includere nel codice sorgente e nei modelli di cluster/processo. | Sincronizzare librerie personalizzate da repository centralizzati, DBFS o archiviazione cloud (possono essere montate). |
| Script di avvio del cluster | Se si preferisce, includere nel codice sorgente. | Per una sincronizzazione più semplice, archiviare gli script init nell'area di lavoro primaria in una cartella comune o in un piccolo set di cartelle, se possibile. |
| Punti di montaggio | Includere nel codice sorgente se creato solo tramite processi basati su notebook o API di comando. | Usare i processi, che possono essere eseguiti come attività di Azure Data Factory (ADF). Si noti che gli endpoint di archiviazione potrebbero cambiare, dato che le aree di lavoro si trovano in aree diverse. Questo dipende molto anche dalla strategia di ripristino di emergenza dei dati. |
| Metadati delle tabelle | Includere con il codice sorgente se creato solo tramite processi basati su notebook o API di comando. Questo vale sia per il metastore interno di Azure Databricks che per il metastore esterno configurato. | Confrontare le definizioni di metadati tra i metastore usando l'API Catalogo Spark o Mostra Crea tabella tramite un notebook o script. Si noti che le tabelle per l'archiviazione sottostante possono essere basate sull'area e saranno diverse tra le istanze del metastore. |
| Segreti | Includere nel codice sorgente se creato solo tramite l'API command. Si noti che potrebbe essere necessario cambiare il contenuto dei segreti tra il database primario e quello secondario. | I segreti vengono creati in entrambe le aree di lavoro tramite l'API. Si noti che potrebbe essere necessario cambiare il contenuto dei segreti tra il database primario e quello secondario. |
| Configurazioni dei cluster | Può essere un modello in Git. Eseguire la co-distribuzione nelle distribuzioni primarie e secondarie, anche se quelle nella distribuzione secondaria devono essere terminate fino all'evento di ripristino di emergenza. | I cluster vengono creati dopo la sincronizzazione con l'area di lavoro secondaria usando l'API o la CLI. Questi possono essere terminati in modo esplicito se si desidera, a seconda delle impostazioni di terminazione automatica. |
| Autorizzazioni per notebook, processi e cartelle | Può essere un modello in Git. Co-distribuzione in distribuzioni primarie e secondarie. | Eseguire la replica usando l'API Autorizzazioni. |
Scegliere aree e più aree di lavoro secondarie
È necessario il controllo completo del trigger di ripristino di emergenza. È possibile decidere di attivarlo in qualsiasi momento o per qualsiasi motivo. È necessario assumersi la responsabilità della stabilizzazione del ripristino di emergenza prima di poter riavviare la modalità di failback dell'operazione (produzione normale). In genere, ciò significa che è necessario creare più aree di lavoro di Databricks di Azure per soddisfare le esigenze di produzione e ripristino di emergenza e scegliere l'area di failover secondaria.
In Azure controllare la replica dei dati, nonché la disponibilità dei tipi di prodotto e macchina virtuale.
Passaggio 3: Preparazione delle aree di lavoro e fare una copia una tantum
Se un'area di lavoro è già in produzione, in genere si esegue un'operazione di copia una tantum per sincronizzare la distribuzione passiva con la distribuzione attiva. Questa copia una tantum gestisce quanto segue:
- Replica dei dati: replica tramite una soluzione di replica cloud o un'operazione Delta Deep Clone.
- Generazione di token: usare la generazione di token per automatizzare la replica e i carichi di lavoro futuri.
- Replica dell'area di lavoro: usare la replica dell'area di lavoro usando i metodi descritti nel Passaggio 4: Preparare le origini dati.
- Convalida dell'area di lavoro: - testare per assicurarsi che l'area di lavoro e il processo possano essere eseguiti correttamente e fornire i risultati previsti.
Dopo l'operazione di copia una tantum iniziale, le azioni di copia e sincronizzazione successive sono più veloci e qualsiasi registrazione degli strumenti è anche un log delle modifiche apportate e di quando sono state apportate.
Passaggio 4: Preparare le origini dati
Azure Databricks può elaborare un'ampia gamma di origini dati usando l'elaborazione batch o i flussi di dati.
Elaborazione batch da origini dati
Quando i dati vengono elaborati in batch, in genere si trovano in un'origine dati che può essere replicata facilmente o distribuita in un'altra area.
Ad esempio, i dati potrebbero essere caricati regolarmente in una posizione di archiviazione cloud. In modalità di ripristino di emergenza per l'area secondaria, accertarsi che i file vengano caricati nell'archivio dell'area secondaria. I carichi di lavoro devono leggere l'archivio dell'area secondaria e scrivere nell'archivio dell'area secondaria.
Flussi dei dati
L'elaborazione di un flusso di dati è una sfida più complessa. I dati di streaming possono essere inseriti da varie origini ed essere elaborati e inviati a una soluzione di streaming:
- Coda di messaggi, ad esempio Kafka
- Database del flusso con Change Data Capture
- Elaborazione continua basata su file
- Elaborazione pianificata basata su file, nota anche come trigger una sola volta
In tutti questi casi, è necessario configurare le origini dati per gestire la modalità di ripristino di emergenza e per usare la distribuzione secondaria nell'area secondaria.
Un writer di flusso archivia un checkpoint con informazioni sui dati elaborati. Questo checkpoint può contenere una posizione dei dati (in genere archiviazione cloud) che deve essere modificata in una nuova posizione per garantire un riavvio corretto del flusso. Ad esempio, la source sottocartella nel checkpoint potrebbe archiviare la cartella cloud basata su file.
Questo checkpoint deve essere replicato in modo tempestivo. Prendere in considerazione la sincronizzazione dell'intervallo di checkpoint con qualsiasi nuova soluzione di replica cloud.
L'aggiornamento del checkpoint è una funzione del writer e pertanto si applica all'inserimento o all'elaborazione del flusso di dati e all'archiviazione in un'altra origine di streaming.
Per i carichi di lavoro di streaming, assicurarsi che i checkpoint siano configurati nell'archivio gestito dal cliente, in modo che possano essere replicati nell'area secondaria per riprendere il carico di lavoro dal punto dell'ultimo errore. Si può inoltre decidere di eseguire il processo di streaming secondario in parallelo al processo primario.
Passaggio 5: Implementare e testare la soluzione
Testare periodicamente la configurazione del ripristino di emergenza per assicurarsi che funzioni correttamente. Gestire una soluzione di ripristino di emergenza non ha alcuna utilità, se non è possibile usarla quando necessario. Alcune aziende passano da un'area all'altra in pochi mesi. Il passaggio regolare tra le diverse aree verifica i presupposti e i processi e garantisce che soddisfino le esigenze di ripristino. Ciò garantisce anche che l'organizzazione conosca i criteri e le procedure per le emergenze.
Importante
Testare regolarmente la soluzione di ripristino di emergenza in condizioni reali.
Se si scopre che manca un oggetto o un modello ed è comunque necessario basarsi sulle informazioni archiviate nell'area di lavoro primaria, modificare il piano per rimuovere questi ostacoli, replicare queste informazioni nel sistema secondario o renderle disponibili in altro modo.
Testare le modifiche organizzative necessarie ai processi e alla configurazione in generale. Il piano di ripristino di emergenza influisce sulla pipeline di distribuzione ed è importante che il team sappia cosa sincronizzare. Dopo aver configurato le aree di lavoro di ripristino di emergenza, assicurarsi che l'infrastruttura (manuale o codice), i processi, i notebook, le librerie e altri oggetti dell'area di lavoro siano disponibili nell'area secondaria.
Parlare con il team su come espandere i processi di lavoro standard e le pipeline di configurazione per distribuire le modifiche in tutte le aree di lavoro. Gestire le identità utente in tutte le aree di lavoro. Ricordarsi di configurare strumenti come l'automazione dei processi e il monitoraggio per le nuove aree di lavoro.
Pianificare e testare le modifiche apportate agli strumenti di configurazione:
- Inserimento: comprendere dove si trovano le origini dati e dove queste origini ottengono i dati. Se possibile, parametrizzare l'origine e assicurarsi di disporre di un modello di configurazione separato per lavorare con le distribuzioni secondarie e le aree secondarie. Preparare un piano per il failover e testare tutti i presupposti.
- Modifiche all'esecuzione: se si dispone di un pianificatore per attivare processi o altre azioni, potrebbe essere necessario configurare un pianificatore separato che funzioni con la distribuzione secondaria o le relative origini dati. Preparare un piano per il failover e testare tutti i presupposti.
- Connettività interattiva: valutare il modo in cui la configurazione, l'autenticazione e le connessioni di rete potrebbero essere interessate da interruzioni a livello di area per qualsiasi uso di API REST, strumenti dell'interfaccia della riga di comando o altri servizi, ad esempio JDBC/ODBC. Preparare un piano per il failover e testare tutti i presupposti.
- Modifiche all'automazione: per tutti gli strumenti di automazione, preparare un piano per il failover e testare tutti i presupposti.
- Output: per tutti gli strumenti che generano dati di output o log, preparare un piano per il failover e testare tutti i presupposti.
Failover di test
Il ripristino di emergenza può essere attivato da molti scenari diversi. Può essere attivato da un'interruzione imprevista. Alcune funzionalità di base potrebbero non essere disponibili, tra cui la rete cloud, l'archiviazione cloud o un altro servizio principale. Non si ha l’accesso per arrestare il sistema normalmente e si deve tentare il ripristino. Tuttavia, il processo può essere attivato da un arresto o da un'interruzione pianificata o anche da un cambio periodico delle distribuzioni attive tra due aree.
Quando si esegue il failover di test, connettersi al sistema ed eseguire l’arresto. Assicurarsi che tutti i processi siano completi e che i cluster siano terminati.
Un client di sincronizzazione (o strumenti CI/CD) può replicare gli oggetti e le risorse di Azure Databricks pertinenti nell'area di lavoro secondaria. Per attivare l'area di lavoro secondaria, il processo potrebbe includere tutte o alcune delle operazioni seguenti:
- Eseguire test per verificare che la piattaforma sia aggiornata.
- Disabilitare pool e cluster nell'area primaria in modo che, se il servizio non riuscito torna online, l'area primaria non avvia l'elaborazione di nuovi dati.
- Processo di ripristino:
- Controllare la data degli ultimi dati sincronizzati. Vedere terminologia del settore del ripristino di emergenza. I dettagli di questo passaggio variano in base a come vengono sincronizzati i dati e alle esigenze aziendali specifiche.
- Stabilizzare le origini dati e verificare che siano tutte disponibili. Includere tutte le origini dati esterne, ad esempio Azure Cloud SQL, nonché Delta Lake, Parquet o altri file.
- Trovare il punto di ripristino di streaming. Configurare il processo per il riavvio da questa posizione e avere un processo pronto per identificare ed eliminare potenziali duplicati (Delta Lake Lake semplifica questa operazione).
- Completare il processo del flusso di dati e informare gli utenti.
- Avviare pool pertinenti (o aumentare
min_idle_instancesal numero pertinente). - Avviare i cluster pertinenti (se non terminati).
- Modificare l'esecuzione simultanea per i processi ed eseguire i processi pertinenti. Può trattarsi di esecuzioni occasionali o di esecuzioni periodiche.
- Per qualsiasi strumento esterno che usa un URL o un nome di dominio per l'area di lavoro di Azure Databricks, aggiornare le configurazioni per tenere conto del nuovo piano di controllo. Ad esempio, aggiornare gli URL per le API REST e le connessioni JDBC/ODBC. L'URL dell'applicazione web di Azure Databricks rivolta ai clienti cambia quando cambia il piano di controllo, quindi manda una notifica agli utenti dell'organizzazione con il nuovo URL.
Ripristino di test (failback)
Il failback è più semplice da controllare e può essere eseguito in una finestra di manutenzione. Questo piano può includere tutti o alcuni dei seguenti elementi:
- Accertarsi che l'area primaria sia stata ripristinata.
- Disabilitare pool e cluster nell'area secondaria in modo che non venga avviata l'elaborazione di nuovi dati.
- Sincronizzare le risorse nuove o modificate nell'area di lavoro secondaria con la distribuzione primaria. A seconda della progettazione degli script di failover, è possibile eseguire gli stessi script per sincronizzare gli oggetti dall'area secondaria (ripristino di emergenza) all'area primaria (produzione).
- Sincronizzare gli eventuali nuovi aggiornamenti dei dati alla distribuzione primaria. È possibile usare i audit trail dei log e delle tabelle Delta per evitare la perdita di dati.
- Arrestare tutti i carichi di lavoro nell'area di ripristino di emergenza.
- Modificare l'URL di processi e utenti nell'area primaria.
- Eseguire test per verificare che la piattaforma sia aggiornata.
- Avviare pool pertinenti (o aumentare l'oggetto
min_idle_instancesa un numero pertinente). - Avviare i cluster pertinenti (se non terminati).
- Modificare l'esecuzione simultanea per i processi ed eseguire processi pertinenti. Può trattarsi di esecuzioni occasionali o di esecuzioni periodiche.
- Se necessario, configurare nuovamente l'area secondaria per ripristini di emergenza futuri.
Script, esempi e prototipi di automazione
Script di automazione da considerare per i progetti di ripristino di emergenza:
- Databricks consiglia di usare il Provider Databricks Terraform per sviluppare un processo di sincronizzazione personalizzato.
- Vedere Strumenti di migrazione dell'area di lavoro di Databricks per script di esempio e prototipo. Oltre agli oggetti Azure Databricks, replicare eventuali pipeline Azure Data Factory pertinenti in modo che facciano riferimento a un servizio collegato mappato all'area di lavoro secondaria.
- Il progetto Databricks Sync (DBSync) è uno strumento di sincronizzazione degli oggetti che esegue il backup, ripristina e sincronizza le aree di lavoro di Databricks.