Riferimenti alla tabella di sistema dei lavori
Nota
Lo schema lakeflow era precedentemente noto come workflow. Il contenuto di entrambi gli schemi è identico. Per rendere visibile lo schema lakeflow, è necessario abilitarlo separatamente.
Questo articolo è un riferimento per l'uso delle tabelle di sistema lakeflow per monitorare i processi nell'account. Queste tabelle includono record di tutte le aree di lavoro nell'account distribuito nella stessa area cloud. Per visualizzare i record di un'altra area, è necessario visualizzare le tabelle da un'area di lavoro distribuita in tale area.
Requisiti
- Lo schema
system.lakeflowdeve essere abilitato da un amministratore dell'account. Vedere Abilitare gli schemi di tabella di sistema. - Per accedere a queste tabelle di sistema, gli utenti devono:
- Essere sia un amministratore del metastore che un amministratore dell'account oppure
- Disporre delle autorizzazioni
USEeSELECTper gli schemi di sistema. Fare riferimento a Concedere l'accesso alle tabelle di sistema.
Tabelle dei lavori disponibili
Tutte le tabelle di sistema correlate ai lavori si trovano nello schema system.lakeflow. Attualmente, lo schema ospita quattro tabelle:
| Tavolo | Descrizione | Supporta lo streaming | Periodo di conservazione gratuito | Includono dati globali o regionali |
|---|---|---|---|---|
| incarichi (anteprima pubblica) | Tiene traccia di tutti i lavori creati nell'account | Sì | 365 giorni | Regionale |
| job_tasks (anteprima pubblica) | Tiene traccia di tutte le attività lavorative che vengono eseguite nell'account | Sì | 365 giorni | Regionale |
| job_run_timeline (anteprima pubblica) | Tiene traccia delle esecuzioni delle attività e dei metadati correlati | Sì | 365 giorni | Regionale |
| job_task_run_timeline (anteprima pubblica) | Tiene traccia delle esecuzioni delle attività di processo e dei metadati correlati | Sì | 365 giorni | Regionale |
Informazioni di riferimento dettagliate sullo schema
Nelle sezioni seguenti vengono forniti riferimenti allo schema per ciascuna delle tabelle di sistema relative ai lavori.
Schema della tabella lavori
La tabella jobs è una tabella delle dimensioni a modifica lenta (SCD2). Quando una riga viene modificata, viene generata una nuova riga, sostituendo logicamente quella precedente.
percorso tabella: system.lakeflow.jobs
| Nome colonna | Tipo di dati | Descrizione | Note |
|---|---|---|---|
account_id |
stringa | L'ID dell'account a cui appartiene il lavoro | |
workspace_id |
stringa | ID dell'area di lavoro a cui appartiene questo incarico | |
job_id |
stringa | ID del lavoro | Solo univoco all'interno di una singola area di lavoro |
name |
stringa | Nome dell'attività fornito dall'utente | |
description |
stringa | Descrizione fornita dall'utente del lavoro | Questo campo è vuoto se avete configurato chiavi gestite dal cliente. Non popolato per le righe emesse prima della fine di agosto 2024 |
creator_id |
stringa | ID del principale che ha creato il processo di lavoro | |
tags |
stringa | Tag personalizzati forniti dall'utente associati a questo processo | |
change_time |
timestamp | Ora dell'ultima modifica del lavoro | Fuso orario registrato come +00:00 (UTC) |
delete_time |
timestamp | L'ora in cui il lavoro è stato eliminato dall'utente | Fuso orario registrato come +00:00 (UTC) |
run_as |
stringa | ID dell'utente o del principale del servizio le cui autorizzazioni vengono usate per l'esecuzione del processo |
Query di esempio
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
Schema della tabella delle attività di lavoro
La tabella delle attività lavorative è una tabella di dimensioni a modifica lenta (SCD2). Quando una riga viene modificata, viene generata una nuova riga, sostituendo logicamente quella precedente.
percorso tabella: system.lakeflow.job_tasks
| Nome colonna | Tipo di dati | Descrizione | Note |
|---|---|---|---|
account_id |
stringa | ID dell'account a cui appartiene l'attività | |
workspace_id |
stringa | ID dell'area di lavoro a cui appartiene questo lavoro | |
job_id |
stringa | ID del lavoro | Solo univoco all'interno di una singola area di lavoro |
task_key |
stringa | Chiave di riferimento per un'attività in una mansione | Solo unico all'interno di un singolo lavoro |
depends_on_keys |
array | Chiavi di attività di tutte le dipendenze upstream di questa attività | |
change_time |
timestamp | Ora dell'ultima modifica dell'attività | Fuso orario registrato come +00:00 (UTC) |
delete_time |
timestamp | Ora in cui un'attività è stata eliminata dall'utente | Fuso orario registrato come +00:00 (UTC) |
Query di esempio
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
schema della tabella della cronologia dell'esecuzione del processo
La tabella della sequenza temporale dell'esecuzione del processo non è modificabile e viene completata al momento della produzione.
percorso tabella: system.lakeflow.job_run_timeline
| Nome colonna | Tipo di dati | Descrizione | Note |
|---|---|---|---|
account_id |
stringa | L'ID dell'account a cui questa attività appartiene | |
workspace_id |
stringa | ID dell'area di lavoro a cui appartiene questo processo | |
job_id |
stringa | ID del lavoro | Questa chiave è univoca solo all'interno di una singola area di lavoro |
run_id |
stringa | ID di esecuzione del lavoro | |
period_start_time |
timestamp | Ora di inizio per la corsa o per il periodo di tempo | Le informazioni sul fuso orario vengono registrate alla fine del valore con +00:00 che rappresenta l'ora UTC |
period_end_time |
timestamp | Ora di fine per l'esecuzione o l'intervallo di tempo | Le informazioni sul fuso orario vengono registrate alla fine del valore con +00:00 che rappresenta l'ora UTC |
trigger_type |
stringa | Tipo di trigger che può generare un'esecuzione | Per i valori possibili, vedere Valori dei tipi di trigger |
run_type |
stringa | Tipo di esecuzione del lavoro | Per i valori possibili, vedere Valori dei tipi di esecuzione |
run_name |
stringa | Nome di esecuzione fornito dall'utente associato all'esecuzione del processo | |
compute_ids |
array | Array contenente gli ID di calcolo dei job per l'esecuzione del job padre | Usare per identificare il cluster di processi utilizzato dai tipi di esecuzioni WORKFLOW_RUN. Per altre informazioni di calcolo, vedere la tabella job_task_run_timeline.Non popolato per le righe emesse prima della fine di agosto 2024 |
result_state |
stringa | Risultato dell'esecuzione del lavoro | Per i valori possibili, vedere Valori dello stato risultato |
termination_code |
stringa | Codice di terminazione dell'esecuzione del compito | Per i valori possibili, vedere valori di codice di terminazione. Non popolato per le righe emesse prima della fine di agosto 2024 |
job_parameters |
mappa | Parametri a livello di attività usati nell'esecuzione del lavoro | Le impostazioni deprecate notebook_params non sono incluse in questo campo. Non popolato per le righe emesse prima di fine agosto 2024 |
Query di esempio
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
schema della tabella della sequenza temporale dell'esecuzione del compito lavorativo
La tabella della sequenza temporale dell'esecuzione dell'attività di processo non è modificabile e viene completata al momento della produzione.
percorso tabella: system.lakeflow.job_task_run_timeline
| Nome colonna | Tipo di dati | Descrizione | Note |
|---|---|---|---|
account_id |
stringa | ID dell'account a cui appartiene l'attività | |
workspace_id |
stringa | ID dell'area di lavoro a cui appartiene questa attività | |
job_id |
stringa | ID del lavoro | Solo univoco all'interno di una singola area di lavoro |
run_id |
stringa | ID dell'esecuzione dell'attività | |
job_run_id |
stringa | Identificativo dell'esecuzione del processo | Non popolato per le righe emesse prima della fine di agosto 2024 |
parent_run_id |
stringa | ID dell'esecuzione padre | Non popolato per le righe emesse prima di fine agosto 2024 |
period_start_time |
timestamp | Ora di inizio per l'attività o per il periodo di tempo | Le informazioni sul fuso orario vengono registrate alla fine del valore con +00:00 che rappresenta l'ora UTC |
period_end_time |
timestamp | Ora di fine per l'attività o per il periodo di tempo | Le informazioni sul fuso orario vengono registrate alla fine del valore con +00:00 che rappresenta l'ora UTC |
task_key |
stringa | Chiave di riferimento per un'attività in una mansione | Questa chiave è univoca solo all'interno di un singolo compito |
compute_ids |
array | La matrice compute_ids contiene ID di cluster di processi, cluster interattivi e magazzini SQL usati dall'attività del processo | |
result_state |
stringa | Risultato dell'esecuzione dell'attività lavorativa | Per i valori possibili, vedere Valori dello stato risultato |
termination_code |
stringa | Codice di terminazione dell'esecuzione dell'attività | Per i valori possibili, vedere valori di codice di terminazione. Non popolato per le righe emesse prima di tardo agosto 2024 |
modelli di join comuni
Nelle sezioni seguenti sono fornite query di esempio che mettono in evidenza i modelli di join usati comunemente per le tabelle di sistema dei lavori.
Unire le tabelle dei lavori e della sequenza temporale di esecuzione dei lavori
Arricchire l'esecuzione di un processo con un nome di processo
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Aggiungere la sequenza temporale di esecuzione del processo e le tabelle di utilizzo
Arricchire ogni log di fatturazione con i metadati di esecuzione del processo
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Calcolare il costo per ogni esecuzione dell'operazione
Questa query si unisce alla tabella di sistema billing.usage per calcolare un costo per ogni esecuzione del lavoro.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Ottieni i log di utilizzo per un job SUBMIT_RUN
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Aggiungere la sequenza temporale di esecuzione dell'attività di processo e le tabelle dei cluster
Arricchire le esecuzioni dei processi di lavoro con i metadati dei cluster
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Trovare processi in esecuzione in un ambiente di calcolo all-purpose
Questa query si unisce alla tabella di sistema compute.clusters per restituire i job recenti che sono in esecuzione sul calcolo generico per tutti gli usi anziché sul calcolo dedicato ai job.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Dashboard di monitoraggio dei lavori
Il seguente dashboard utilizza le tabelle di sistema per aiutarti a iniziare a monitorare i tuoi lavori e la salute operativa. Include casi d'uso comuni, ad esempio il rilevamento delle prestazioni dei processi, il monitoraggio degli errori e l'utilizzo delle risorse.
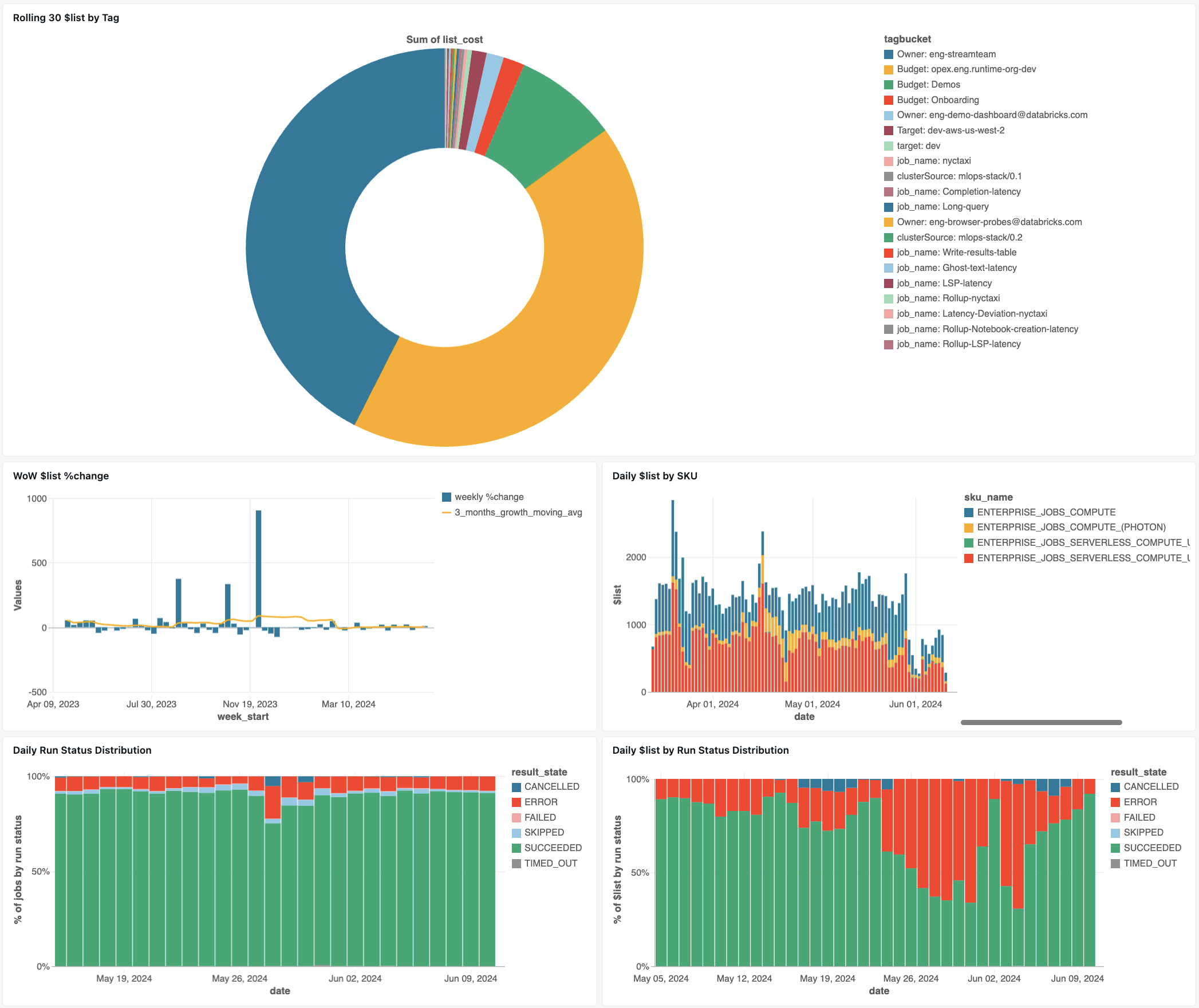
Per informazioni sul download del dashboard, consulta Monitoraggio dei costi e delle prestazioni dei processi con le tabelle di sistema
Risoluzione dei problemi
Processo non è registrato nella tabella lakeflow.jobs
Se un lavoro non è visibile nelle tabelle di sistema:
- Il lavoro non è stato modificato negli ultimi 365 giorni.
- Modificare uno dei campi del lavoro presenti nello schema per generare un nuovo record.
- Il lavoro è stato creato in una regione diversa
- Creazione di posti di lavoro recenti (ritardo nella tabella)
Impossibile trovare un lavoro visualizzato nella tabella job_run_timeline
Non tutte le esecuzioni dell'attività sono visibili ovunque. Mentre le voci JOB_RUN appaiono in tutte le tabelle relative al lavoro, le esecuzioni del flusso di lavoro del notebook (WORKFLOW_RUN) vengono registrate solo in job_run_timeline, mentre le esecuzioni inviate una tantum (SUBMIT_RUN) vengono registrate esclusivamente in entrambe le tabelle della sequenza temporale. Queste esecuzioni non vengono inserite in altre tabelle del sistema di lavoro, come jobs o job_tasks.
Consulta la tabella Categorie di esecuzione di seguito per una suddivisione dettagliata su dove ciascuna categoria di esecuzione è visibile e accessibile.
L'esecuzione del processo non è visibile nella tabella billing.usage
In system.billing.usage, il usage_metadata.job_id viene popolato solo per i processi eseguiti in job compute o nel calcolo serverless.
Inoltre, i lavori WORKFLOW_RUN non hanno la propria attribuzione usage_metadata.job_id o usage_metadata.job_run_id in system.billing.usage.
Invece, il loro utilizzo di calcolo viene attribuito al notebook principale che li ha avviati.
Ciò significa che quando un notebook avvia un flusso di lavoro, tutti i costi di calcolo sono attribuiti all'utilizzo del notebook padre, non come un processo del flusso di lavoro separato.
Per ulteriori informazioni, consultare il riferimento ai metadati di utilizzo .
Calcolare il costo di un task in esecuzione in un ambiente di calcolo multiuso
Il calcolo preciso dei costi per i processi in esecuzione nel calcolo per scopi non è possibile con 100% accuratezza. Quando un processo viene eseguito in un calcolo interattivo (tutto scopo), più carichi di lavoro come notebook, query SQL o altri processi spesso vengono eseguiti contemporaneamente sulla stessa risorsa di calcolo. Poiché le risorse del cluster sono condivise, non esiste un mapping diretto 1:1 tra i costi di calcolo e le esecuzioni di singoli processi.
Per tenere traccia dei costi dei processi accurati, Databricks consiglia l'esecuzione di processi in un ambiente di calcolo dedicato o serverless, in cui l'usage_metadata.job_id e usage_metadata.job_run_id consentono un'attribuzione precisa dei costi.
Se è necessario utilizzare il calcolo generico, è possibile:
- Monitorare l'utilizzo complessivo del cluster e i costi in
system.billing.usagesulla base diusage_metadata.cluster_id. - Tenere traccia delle metriche di esecuzione del lavoro separatamente.
- Si consideri che qualsiasi stima dei costi sarà approssimativa a causa delle risorse condivise.
Per ulteriori informazioni sull'attribuzione dei costi, vedere il riferimento ai metadati di utilizzo .
Valori di riferimento
La sezione seguente include riferimenti per le colonne selezionate nelle tabelle relative ai lavori.
valori dei tipi di trigger
I valori possibili per la colonna trigger_type sono:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Valori di tipo di esecuzione
I valori possibili per la colonna run_type sono:
| Digitare | Descrizione | Posizione dell'interfaccia utente | Punto di accesso API | Tabelle di sistema |
|---|---|---|---|---|
JOB_RUN |
Esecuzione di lavori standard | Interfaccia utente Attività & esecuzioni di attività | /jobs e /jobs/runs endpointS | lavori, compiti di lavoro, cronologia esecuzione lavori, cronologia esecuzione compiti di lavoro |
SUBMIT_RUN |
Esecuzione una tantum tramite POST /jobs/runs/submit | Solo l'interfaccia utente per le esecuzioni di processi | /jobs/runs termina solo | cronologia_esecuzione_lavoro, cronologia_esecuzione_attività_lavoro |
WORKFLOW_RUN |
Esecuzione avviata dal flusso di lavoro del notebook | Non visibile | Non accessibile | cronologia esecuzione lavoro |
Valori dello stato di risultato
I valori possibili per la colonna result_state sono:
| Stato | Descrizione |
|---|---|
SUCCEEDED |
L'esecuzione è stata completata con successo |
FAILED |
L'esecuzione è stata completata con un errore |
SKIPPED |
Non è mai stata eseguita perché non è stata soddisfatta una condizione |
CANCELLED |
L'esecuzione è stata annullata alla richiesta dell'utente |
TIMED_OUT |
L'esecuzione è stata arrestata dopo aver raggiunto il timeout |
ERROR |
Operazione completata con un errore |
BLOCKED |
L'esecuzione è stata bloccata in una dipendenza upstream |
Valori del codice di terminazione
I valori possibili per la colonna termination_code sono:
| Codice di terminazione | Descrizione |
|---|---|
SUCCESS |
L'esecuzione è stata completata correttamente |
CANCELLED |
L'esecuzione è stata annullata dalla piattaforma Databricks; ad esempio, se è stata superata la durata massima consentita. |
SKIPPED |
L'esecuzione non è mai stata avviata, ad esempio se l'esecuzione del compito upstream non è riuscita, la condizione del tipo di dipendenza non è stata soddisfatta o non erano disponibili compiti concreti da eseguire. |
DRIVER_ERROR |
L'esecuzione ha rilevato un errore durante la comunicazione con il driver Spark |
CLUSTER_ERROR |
L'esecuzione non è riuscita a causa di un errore del cluster |
REPOSITORY_CHECKOUT_FAILED |
Impossibile completare la transazione a causa di un errore durante la comunicazione con il servizio di terze parti |
INVALID_CLUSTER_REQUEST |
L'esecuzione non è riuscita perché ha emesso una richiesta non valida per avviare il cluster |
WORKSPACE_RUN_LIMIT_EXCEEDED |
L'area di lavoro ha raggiunto la quota per il numero massimo di esecuzioni attive simultanee. Valutare la possibilità di pianificare le esecuzioni in un intervallo di tempo più ampio |
FEATURE_DISABLED |
L'esecuzione non è riuscita perché ha tentato di accedere a una funzionalità non disponibile per l'area di lavoro |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
Il numero di richieste di creazione, avvio e ridimensionamento del cluster ha superato il limite di frequenza assegnato. Prendere in considerazione di distribuire l'esecuzione dell'operazione su un arco di tempo più ampio |
STORAGE_ACCESS_ERROR |
L'esecuzione non è riuscita a causa di un errore durante l'accesso all'archiviazione BLOB del cliente |
RUN_EXECUTION_ERROR |
L'esecuzione è stata completata con fallimenti delle attività |
UNAUTHORIZED_ERROR |
L'esecuzione non è riuscita a causa di un problema di autorizzazione durante l'accesso a una risorsa |
LIBRARY_INSTALLATION_ERROR |
L'esecuzione non è riuscita durante l'installazione della libreria richiesta dall'utente. Le cause possono includere, ma non sono limitate a: la libreria fornita non è valida, non sono disponibili autorizzazioni sufficienti per installare la libreria e così via |
MAX_CONCURRENT_RUNS_EXCEEDED |
L'esecuzione pianificata supera il limite massimo di esecuzioni simultanee impostate per il processo |
MAX_SPARK_CONTEXTS_EXCEEDED |
L'esecuzione è pianificata in un cluster che ha già raggiunto il numero massimo di contesti configurati per la creazione |
RESOURCE_NOT_FOUND |
Una risorsa necessaria per l'esecuzione di un processo non esiste |
INVALID_RUN_CONFIGURATION |
L'esecuzione non è riuscita a causa di una configurazione non valida |
CLOUD_FAILURE |
L'esecuzione non è riuscita a causa di un problema del provider di servizi cloud |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
L'esecuzione è stata saltata a causa del raggiungimento del limite di dimensione della coda a livello di lavoro. |