Che cos'è il wrangling dei dati?
SI APPLICA A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Il wrangling dei dati comporta la trasformazione e la riformattazione dei dati dall'origine per renderli più adatti e utili per varie applicazioni downstream.
Le organizzazioni devono avere la possibilità di esplorare i dati aziendali critici per la preparazione e il wrangling dei dati per fornire un'analisi accurata dei dati complessi che continuano a crescere ogni giorno. La preparazione dei dati è necessaria in modo che le organizzazioni possano usare i dati in vari processi aziendali e ridurre il tempo a valore.
Data Factory consente di preparare i dati senza codice a livello di cloud in modo iterativo usando Power Query. Data Factory si integra con Power Query Online e rende disponibili le funzioni M di Power Query come attività della pipeline.
Data Factory converte la funzione M generata dall'editor mashup online di Power Query in codice Spark per l'esecuzione su scala cloud convertendo M in flussi di dati di Azure Data Factory. I dati di wrangling con Power Query e i flussi di dati sono particolarmente utili per i data engineer o per gli "integratori di dati cittadini".
Casi d'uso
Esplorazione e preparazione rapida dei dati interattivi
Più data engineer e integratori di dati cittadini possono esplorare e preparare in modo interattivo set di dati su larga scala. Con l'aumento del volume, della varietà e della velocità dei dati nei data lake, gli utenti hanno bisogno di un modo efficace per esplorare e preparare set di dati. Ad esempio, potrebbe essere necessario creare un set di dati con tutte le informazioni demografiche dei nuovi clienti dal 2017. Non si eseguirà il mapping a una destinazione nota. Si procederà a esplorare, sottoporre a wrangling e preparare dei set di dati per soddisfare un requisito prima di pubblicarlo nel lake. Il wrangling viene spesso usato per scenari di analisi meno formali. I set di dati pre-compressi possono essere usati per eseguire trasformazioni e operazioni di Machine Learning downstream.
Preparazione dei dati agile senza codice
Gli integratori di dati cittadini dedicano più del 60% del tempo alla ricerca e alla preparazione dei dati. Desiderano di farlo in modo gratuito per migliorare la produttività operativa. Consentire agli integratori di dati dei cittadini di arricchire, modellare e pubblicare dati usando strumenti noti come Power Query Online in modo scalabile migliora drasticamente la produttività. Il wrangling in Azure Data Factory consente al familiare editor mashup di Power Query Online di permettere agli integratori di dati cittadini di correggere rapidamente gli errori, standardizzare i dati e produrre dati di alta qualità per supportare le decisioni aziendali.
Convalida ed esplorazione dei dati
Analizzare visivamente i dati senza codice per rimuovere eventuali outlier e anomalie e uniformarli per un'analisi veloce.
Origini supportate
| Connector | Formato dati | Tipo di autenticazione |
|---|---|---|
| Archiviazione BLOB di Azure | CSV, Parquet, Excel | Chiave dell'account, entità servizio, MSI |
| Azure Data Lake Storage Gen1 | CSV, Parquet, Excel | Entità servizio, MSI |
| Azure Data Lake Storage Gen2 | CSV, Parquet, Excel | Chiave dell'account, entità servizio, MSI |
| Database SQL di Azure | - | Autenticazione SQL, MSI, entità servizio |
| Azure Synapse Analytics | - | Autenticazione SQL, MSI, entità servizio |
Editor mashup
Quando si crea un'attività di Power Query, tutti i set di dati di origine diventano query del set di dati e vengono inseriti nella cartella ADFResource. Per impostazione predefinita, UserQuery punterà alla prima query del set di dati. Tutte le trasformazioni devono essere eseguite in UserQuery perché le modifiche alle query del set di dati non sono supportate né verranno mantenute. La ridenominazione, l'aggiunta e l'eliminazione di query non sono attualmente supportate.
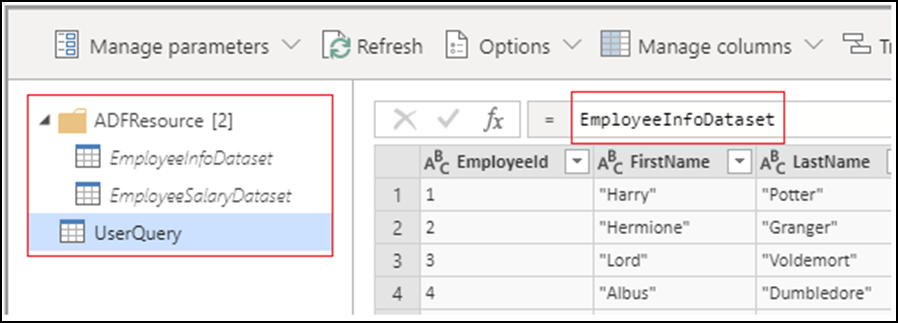
Attualmente non tutte le funzioni M di Power Query sono supportate per il data wrangling nonostante siano disponibili durante la creazione. Durante la compilazione delle attività di Power Query, verrà visualizzato il messaggio di errore seguente se una funzione non è supportata:
The Power Query Spark Runtime does not support the function
Per altre informazioni sulle trasformazioni supportate, vedere Funzioni di wrangling dei dati di Power Query.
Contenuto correlato
Informazioni su come creare un mash-up di Power Query per i dati.