Caricare dati in modo incrementale da più tabelle di SQL Server in un database di Database SQL di Azure con il portale di Azure
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
In questa esercitazione si crea un'istanza di Azure Data Factory con una pipeline che carica dati differenziali da più tabelle in un database di SQL Server in un database in database SQL di Azure.
In questa esercitazione vengono completati i passaggi seguenti:
- Preparare gli archivi dati di origine e di destinazione.
- Creare una data factory.
- Creare un runtime di integrazione self-hosted.
- Installare il runtime di integrazione.
- Creare servizi collegati.
- Creare i set di dati di origine, sink e limite.
- Creare, eseguire e monitorare una pipeline.
- Esaminare i risultati.
- Aggiungere o aggiornare dati nelle tabelle di origine.
- Rieseguire e monitorare la pipeline.
- Esaminare i risultati finali.
Panoramica
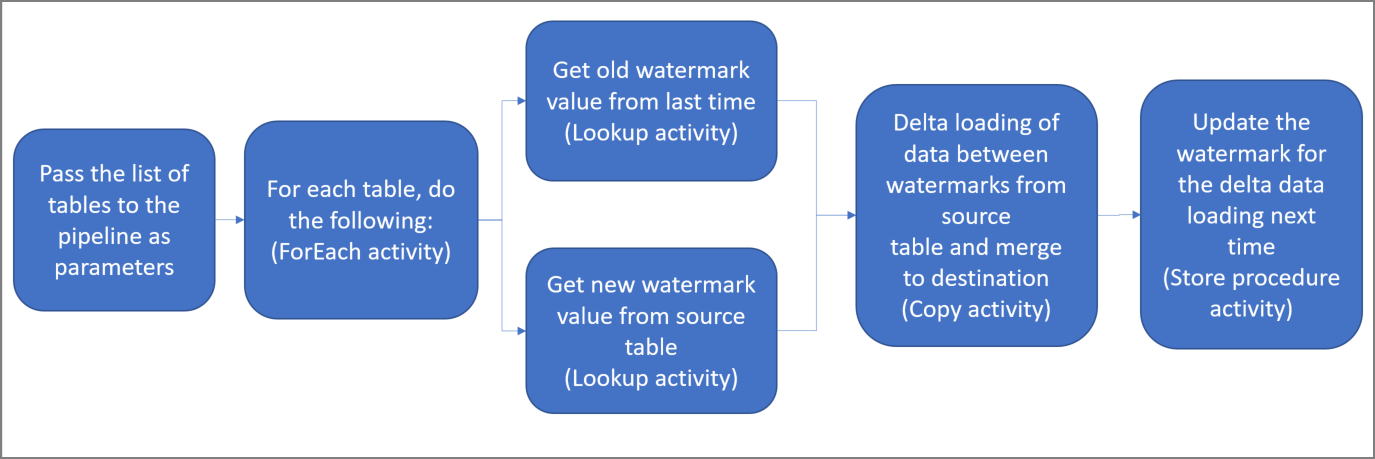
Di seguito sono descritti i passaggi fondamentali per la creazione di questa soluzione:
Selezionare la colonna del limite.
Selezionare una colonna per ogni tabella nell'archivio dati di origine, che può essere usata per identificare i record nuovi o aggiornati per ogni esecuzione. I dati della colonna selezionata (ad esempio last_modify_time o ID) continuano in genere ad aumentare quando le righe vengono create o aggiornate. Il valore massimo di questa colonna viene usato come limite.
Preparare un archivio dati per l'archiviazione del valore limite.
In questa esercitazione si archivia il valore limite in un database SQL.
Creare una pipeline con le attività seguenti:
a. Creare un'attività ForEach che esegue l'iterazione di un elenco di nomi di tabella di origine passato come parametro alla pipeline. Per ogni tabella di origine, l'attività richiama le attività seguenti per eseguire il caricamento differenziale per la tabella.
b. Creare due attività di ricerca. Usare la prima attività di ricerca per recuperare l'ultimo valore limite. Usare la seconda attività di ricerca per recuperare il nuovo valore limite. Questi valori limite vengono passati all'attività di copia.
c. Creare un'attività di copia che copi le righe dell'archivio dati di origine con il valore della colonna del limite maggiore del valore limite precedente e minore del nuovo valore limite. L'attività copierà quindi i dati delta dall'archivio dati di origine a un archivio BLOB di Azure come nuovo file.
d. Creare un'attività stored procedure che aggiorni il valore limite per la pipeline che verrà eseguita la volta successiva.
Il diagramma generale della soluzione è il seguente:
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
- SQL Server. In questa esercitazione si usa un database di SQL Server come archivio dati di origine.
- Database SQL di Azure. Usare un database del database SQL di Azure come archivio dati sink. Se non si ha un database in Database SQL di Azure, vedere la procedura per crearne uno descritta in Creare un database in Database SQL di Azure.
Creare le tabelle di origine nel database di SQL Server
Aprire SQL Server Management Studio e connettersi al database di SQL Server.
In Esplora server fare clic con il pulsante destro del mouse sul database e scegliere Nuova query.
Eseguire il comando SQL seguente sul database per creare le tabelle denominate
customer_tableeproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Creare le tabelle di destinazione nel database
Aprire SQL Server Management Studio e connettersi al database in Database SQL di Azure.
In Esplora server fare clic con il pulsante destro del mouse sul database e scegliere Nuova query.
Eseguire il comando SQL seguente sul database per creare le tabelle denominate
customer_tableeproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Creare un'altra tabella nel database per archiviare il valore del limite massimo
Eseguire il comando SQL seguente nel database SQL per creare una tabella denominata
watermarktablein cui archiviare il valore limite:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Inserire i valori del limite iniziale per entrambe le tabelle di origine nella tabella dei limiti.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Creare una stored procedure nel database
Eseguire il comando seguente per creare una stored procedure nel database. Questa stored procedure aggiorna il valore del limite dopo ogni esecuzione di pipeline.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Creare tipi di dati e stored procedure aggiuntive nel database
Eseguire la query seguente per creare due stored procedure e due tipi di dati nel database. Questi elementi vengono usati per unire i dati delle tabelle di origine nelle tabelle di destinazione.
Per semplificare la procedura, si usano direttamente queste stored procedure passando i dati differenziali tramite una variabile di tabella e quindi unendoli nell'archivio di destinazione. Si noti che non è prevista l'archiviazione di un numero di righe delta elevato (più di 100) nella variabile di tabella.
Se è necessario unire un numero elevato di righe delta nell'archivio di destinazione, è consigliabile usare un'attività di copia per copiare prima tutti i dati differenziali in una tabella temporanea nell'archivio di destinazione e quindi compilare la propria stored procedure senza usare la variabile di tabella per eseguire il merge dalla tabella temporanea alla tabella finale.
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Creare una data factory
Avviare il Web browser Microsoft Edge o Google Chrome. L'interfaccia utente di Data Factory è attualmente supportata solo nei Web browser Microsoft Edge e Google Chrome.
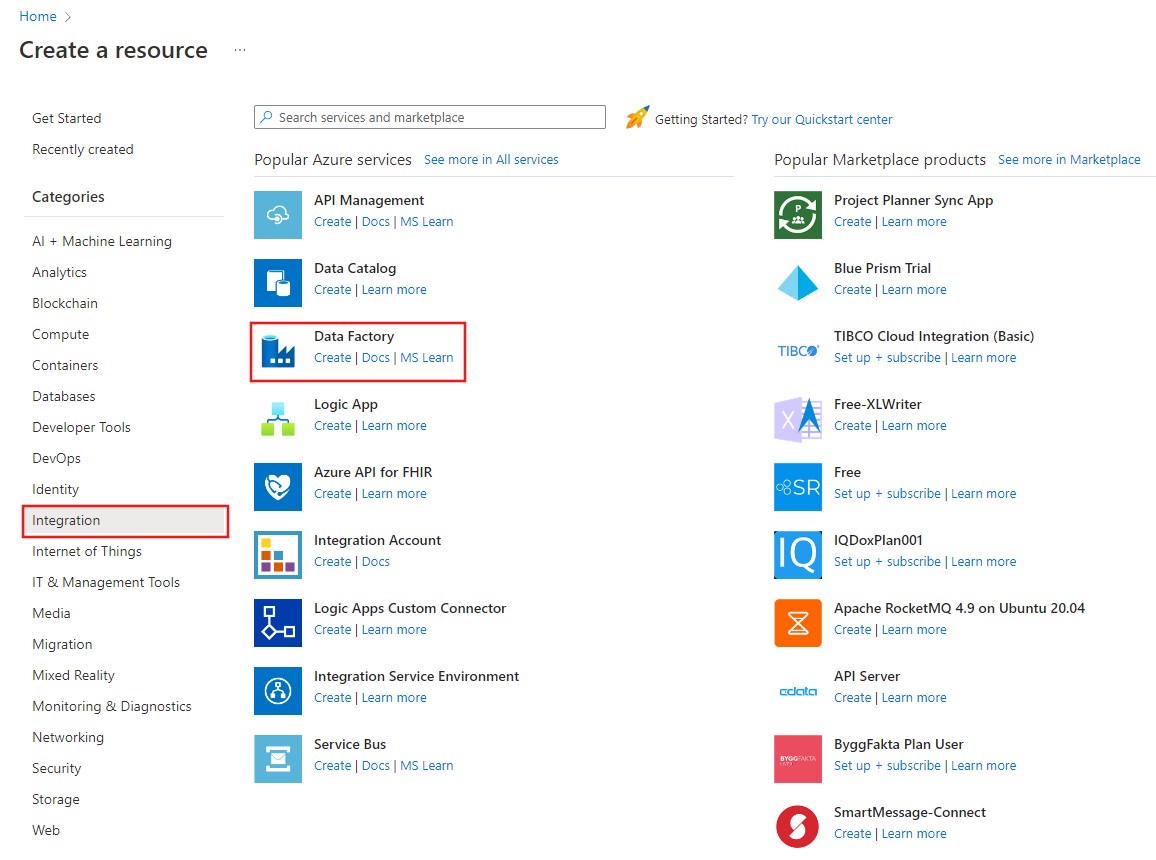
Nel menu sinistro selezionare Crea una risorsa>Integrazione>Data factory:
Nella pagina Nuova data factory immettere ADFMultiIncCopyTutorialDF per Nome.
Il nome dell'istanza di Azure Data Factory deve essere univoco globale. Se viene visualizzato un punto esclamativo rosso con l'errore seguente, modificare il nome della data factory, ad esempio nomeutenteADFIncCopyTutorialDF, e riprovare. Per informazioni sulle regole di denominazione per gli elementi di Data Factory, vedere l'articolo Data Factory - Regole di denominazione.
Data factory name "ADFIncCopyTutorialDF" is not availableSelezionare la sottoscrizione di Azure in cui creare la data factory.
Per il gruppo di risorse, eseguire una di queste operazioni:
- Selezionare Usa esistentee scegliere un gruppo di risorse esistente dall'elenco a discesa.
- Selezionare Crea nuovoe immettere un nome per il gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo relativo all'uso di gruppi di risorse per la gestione delle risorse di Azure.
Selezionare V2 per version.
Selezionare la località per la data factory. Nell'elenco a discesa vengono mostrate solo le località supportate. Gli archivi dati (Archiviazione di Azure, database SQL di Azure e così via) e le risorse di calcolo (HDInsight e così via) usati dalla data factory possono trovarsi in altre aree.
Cliccare su Crea.
Al termine della creazione verrà visualizzata la pagina Data factory, come illustrato nell'immagine.

Selezionare Apri nel riquadro Apri Azure Data Factory Studio per avviare l'interfaccia utente di Azure Data Factory in una scheda separata.
Creare un runtime di integrazione self-hosted
Mentre si spostano i dati da un archivio dati di una rete privata (locale) a un archivio dati di Azure, installare un runtime di integrazione self-hosted nell'ambiente locale. Il runtime di integrazione self-hosted sposta i dati tra la rete privata e Azure.
Nella home page dell'interfaccia utente di Azure Data Factory selezionare la scheda Gestisci nel riquadro più a sinistra.
Selezionare Runtime di integrazione nel riquadro sinistro, quindi selezionare + Nuovo.
Nella finestra Integration Runtime Setup (Configurazione runtime di integrazione) selezionare Perform data movement and dispatch activities to external computes (Eseguire attività di invio e spostamento dati in servizi di calcolo esterni) e fare clic su Continua.
Selezionare Self-hosted e fare clic su Continua.
Immettere MySelfHostedIR in Nome e fare clic su Crea.
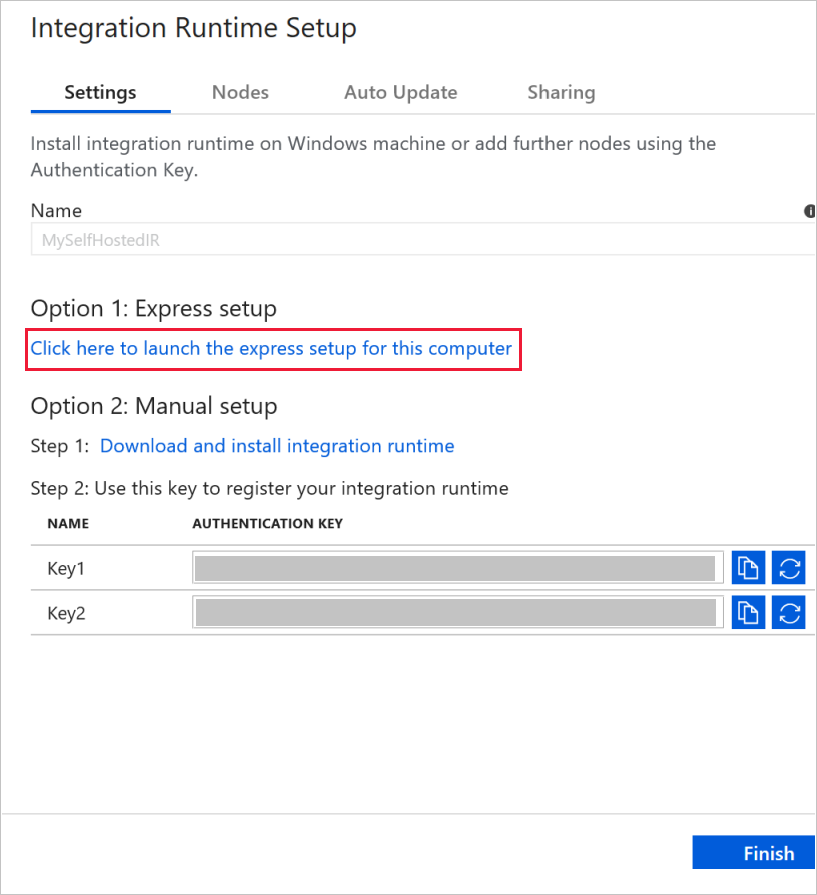
Fare clic su Click here to launch the express setup for this computer (Fare clic qui per avviare l'installazione rapida per il computer) nella sezione Option 1: Express setup (Opzione 1: Installazione rapida).
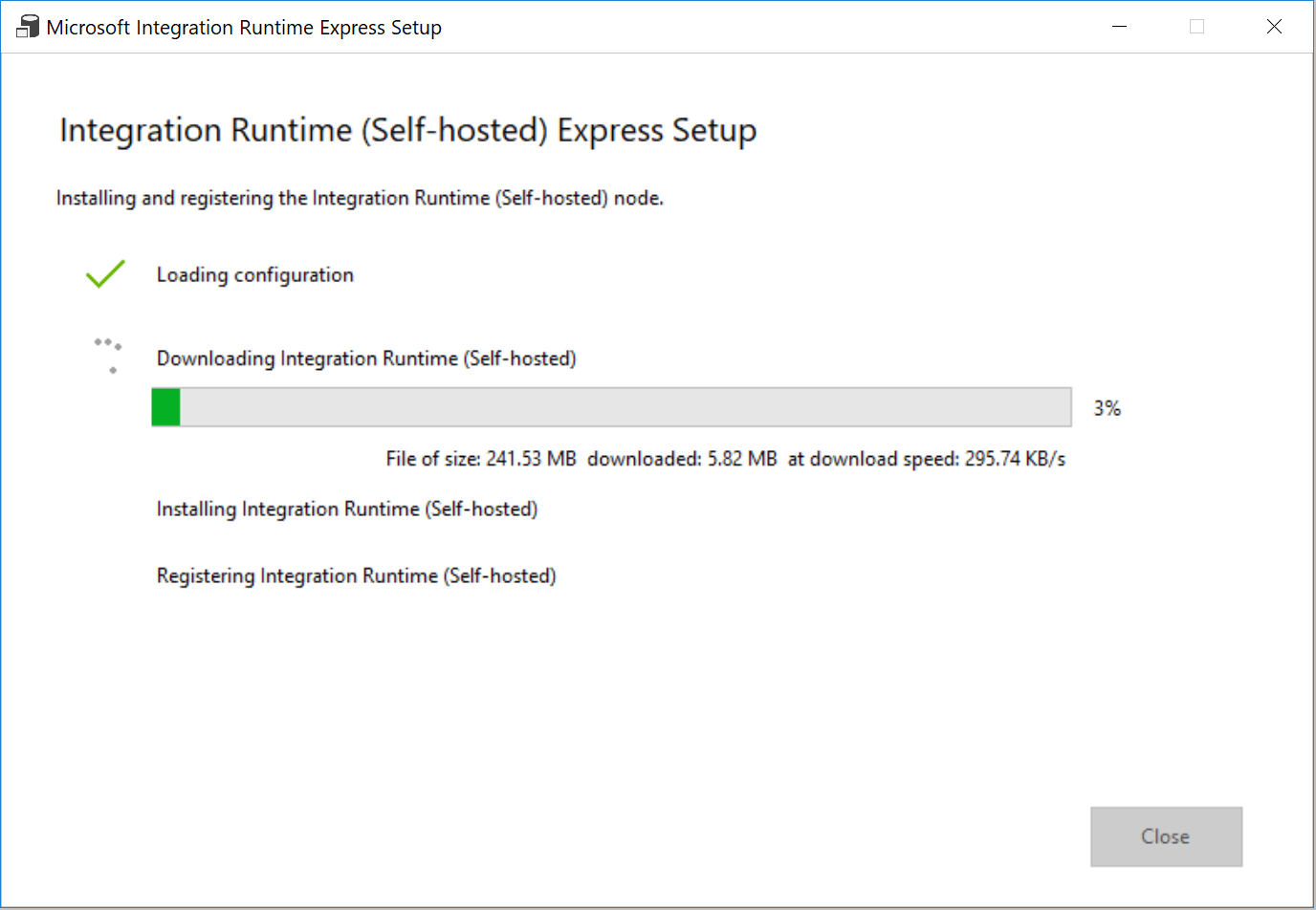
Nella finestra Installazione rapida di Integration Runtime (self-hosted) fare clic su Chiudi.
Nel Web browser fare clic su Fine nella finestra Integration Runtime Setup (Installazione runtime di integrazione).
Verificare che MySelfHostedIR sia visualizzato nell'elenco di runtime di integrazione.
Creare servizi collegati
Si creano servizi collegati in una data factory per collegare gli archivi dati e i servizi di calcolo alla data factory. In questa sezione vengono creati i servizi collegati al database di SQL Server e al database nel database SQL di Azure.
Creare il servizio collegato di SQL Server
In questo passaggio si collega il database di SQL Server alla data factory.
Nella finestra Connessioni passare dalla scheda Integration Runtimes (Runtime di integrazione) alla scheda Servizi collegati e fare clic su + Nuovo.
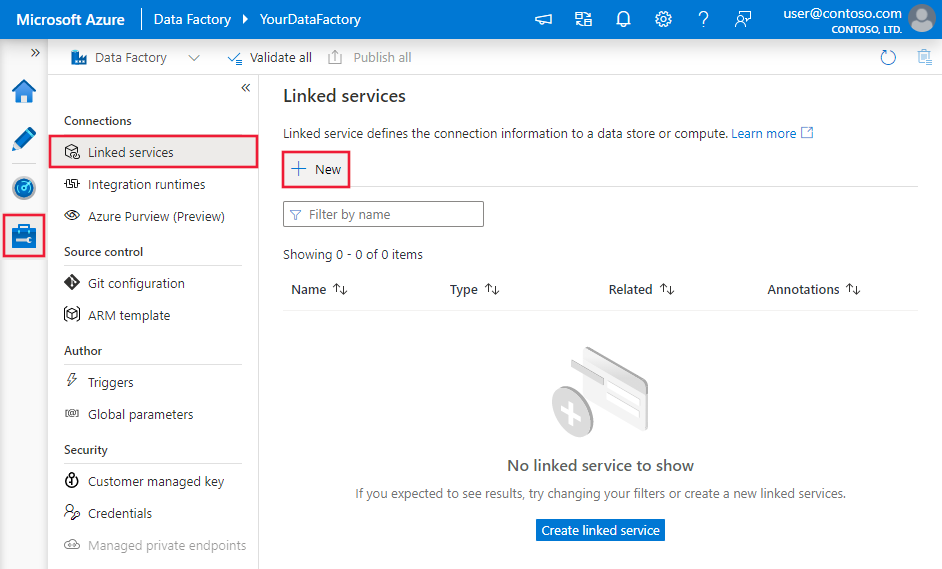
Nella finestra New Linked Service (Nuovo servizio collegato) selezionare SQL Server e fare clic su Continua.
Nella finestra New Linked Service (Nuovo servizio collegato) seguire questa procedura:
- Immettere SqlServerLinkedService per Nome.
- Selezionare MySelfHostedIR per Connect via integration runtime (Connetti tramite runtime di integrazione). Questo è un passaggio importante. Il runtime di integrazione predefinita non può connettersi a un archivio dati locale. Usare il runtime di integrazione self-hosted creato in precedenza.
- Per Nome server immettere il nome del computer che ospita il database di SQL Server.
- Per Nome database immettere il nome del database nell'istanza di SQL Server che ospita l'origine dati. Come parte dei prerequisiti è stata creata una tabella e sono stati inseriti i dati in questo database.
- Per Tipo di autenticazione selezionare il tipo dell'autenticazione che si vuole usare per connettersi al database.
- Per Nome utente immettere il nome dell'utente che ha accesso al database di SQL Server. Se è necessario usare una barra (
\) nell'account utente o nel nome del server, usare il carattere di escape (\). Un esempio èmydomain\\myuser. - Per Password immettere la password dell'utente.
- Per testare se Data Factory può connettersi al database di SQL Server, fare clic su Connessione di test. Correggere eventuali errori fino a quando la connessione ha esito positivo.
- Per salvare il servizio collegato, fare clic su Fine.
Creare il servizio collegato Database SQL di Azure
Nell'ultimo passaggio viene creato un servizio collegato per collegare il database di SQL Server di origine alla data factory. In questo passaggio viene collegato il database di destinazione/sink alla data factory.
Nella finestra Connessioni passare dalla scheda Integration Runtimes (Runtime di integrazione) alla scheda Servizi collegati e fare clic su + Nuovo.
Nella finestra New Linked Service (Nuovo servizio collegato) selezionare Database SQL di Azure e fare clic su Continua.
Nella finestra New Linked Service (Nuovo servizio collegato) seguire questa procedura:
- Immettere AzureSqlDatabaseLinkedService per Nome.
- Per Nome server selezionare il nome del server dall'elenco a discesa.
- Per Nome database selezionare il database in cui sono state create le tabelle customer_table e project_table come parte dei prerequisiti.
- Per Nome utente immettere il nome dell'utente che ha accesso al database.
- Per Password immettere la password dell'utente.
- Per testare se Data Factory può connettersi al database di SQL Server, fare clic su Connessione di test. Correggere eventuali errori fino a quando la connessione ha esito positivo.
- Per salvare il servizio collegato, fare clic su Fine.
Verificare che nell'elenco siano visualizzati due servizi collegati.
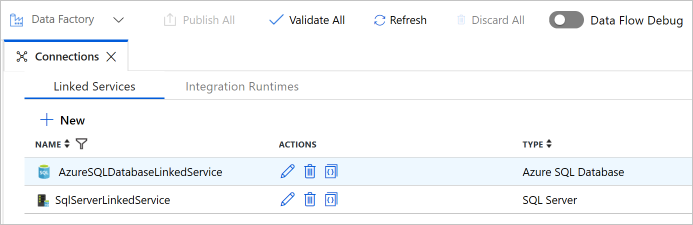
Creare i set di dati
In questo passaggio vengono creati i set di dati per rappresentare l'origine dati, la destinazione dati e la posizione di archiviazione del valore limite.
Creare set di dati di origine
Nel riquadro a sinistra fare clic su + (segno più) e quindi su Set di dati.
Nella finestra Nuovo set di dati selezionare SQL Server e fare clic su Continua.
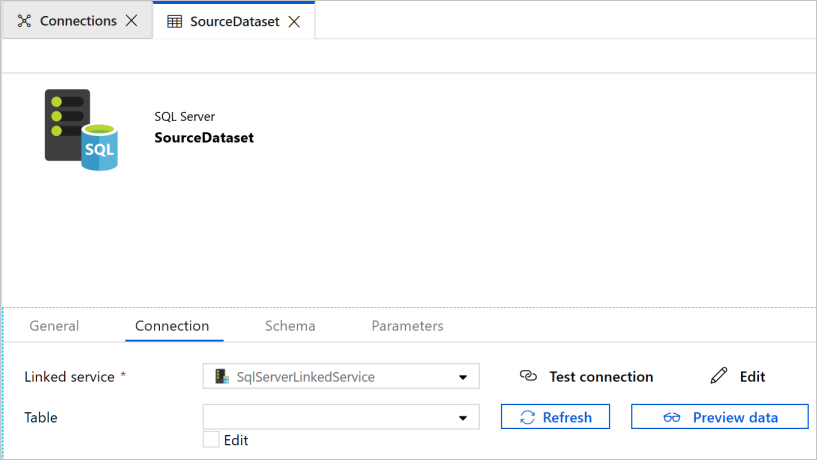
Nel Web browser viene aperta una nuova scheda per la configurazione del set di dati. Un set di dati è presente anche nella visualizzazione struttura ad albero. Nella scheda Generale della finestra Proprietà in basso immettere SourceDataset per Nome.
Passare alla scheda Connessione nella finestra Proprietà e selezionare SqlServerLinkedService per Servizio collegato. Qui non si seleziona una tabella. L'attività di copia nella pipeline usa una query SQL per caricare i dati invece di caricare l'intera tabella.
Creare un set di dati sink
Nel riquadro a sinistra fare clic su + (segno più) e quindi su Set di dati.
Nella finestra Nuovo set di dati selezionare Database SQL di Azure e fare clic su Continua.
Nel Web browser viene aperta una nuova scheda per la configurazione del set di dati. Un set di dati è presente anche nella visualizzazione struttura ad albero. Nella scheda Generale della finestra Proprietà in basso immettere SinkDataset per Nome.
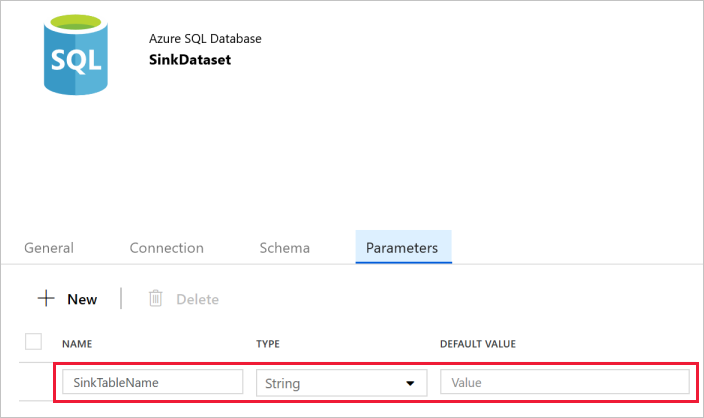
Passare alla scheda Parametri nella finestra Proprietà e seguire questa procedura:
Fare clic su Nuovo nella sezione Create/update parameters (Crea/Aggiorna parametri).
Immettere SinkTableName per il nome e Stringa per il tipo. Questo set di dati accetta SinkTableName come parametro. Il parametro SinkTableName viene impostato dalla pipeline in modo dinamico in fase di esecuzione. L'attività ForEach nella pipeline esegue l'iterazione di un elenco di nomi di tabella e passa il nome di tabella a questo set di dati in ogni interazione.
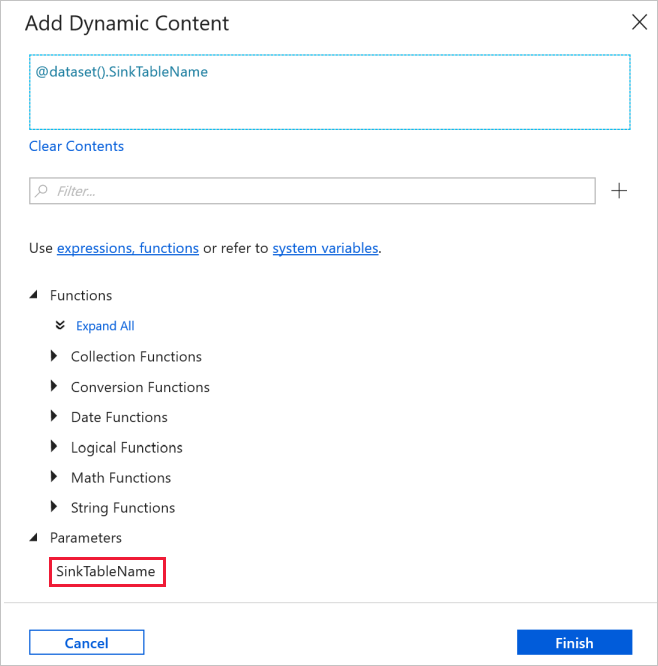
Passare alla scheda Connessione nella finestra Proprietà e selezionare AzureSqlDatabaseLinkedService per Servizio collegato. Per la proprietà Tabella fare clic su Aggiungi contenuto dinamico.
Nella finestra Aggiungi contenuto dinamico selezionare SinkTableName nella sezione Parametri.
Dopo aver fatto clic su Fine, viene visualizzato "@dataset(). SinkTableName" come nome della tabella.
Creare un set di dati per un limite
In questo passaggio si crea un set di dati per l'archiviazione di un valore limite massimo.
Nel riquadro a sinistra fare clic su + (segno più) e quindi su Set di dati.
Nella finestra Nuovo set di dati selezionare Database SQL di Azure e fare clic su Continua.
Nella scheda Generale della finestra Proprietà in basso immettere WatermarkDataset per Nome.
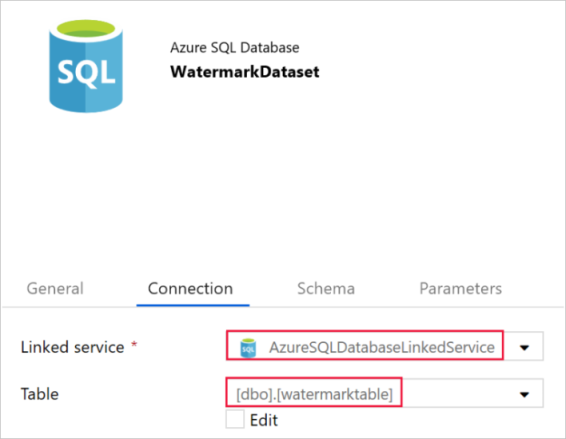
Passare alla scheda Connessione e seguire questa procedura:
Selezionare AzureSqlDatabaseLinkedService per Servizio collegato.
Selezionare [dbo].[watermarktable] per Tabella.
Creare una pipeline
Questa pipeline accetta un elenco di nomi di tabella come parametro. L'attività ForEach esegue l'iterazione dell'elenco dei nomi di tabella ed esegue le operazioni seguenti:
Usa l'attività di ricerca per recuperare il valore del limite precedente (valore iniziale o usato nell'ultima iterazione).
Usa l'attività di ricerca per recuperare il nuovo valore del limite (valore massimo della colonna dei limiti nella tabella di origine).
Usa l'attività di copia per copiare dati tra i due valori del limite dal database di origine al database di destinazione.
Usa l'attività StoredProcedure per aggiornare il valore del limite precedente da usare nel primo passaggio dell'iterazione successiva.
Creare la pipeline
Nel riquadro a sinistra fare clic su + (segno più) e quindi su Pipeline.
Nel pannello Generale in Proprietà specificare IncrementalCopyPipeline per Nome. Comprimere quindi il pannello facendo clic sull'icona Proprietà nell'angolo in alto a destra.
Nella scheda Parametri seguire questa procedura:
- Fare clic su + Nuovo.
- Immettere tableList per il nome del parametro.
- Selezionare Array come parametro type.
Nella casella degli strumenti Attività espandere Iteration & Conditionals (Iterazione e istruzioni condizionali) e trascinare l'attività ForEach nell'area di progettazione della pipeline. Nella scheda Generale della finestra Proprietà immettere IterateSQLTables.
Passare alla scheda Impostazioni e immettere
@pipeline().parameters.tableListper Elementi. L'attività ForEach esegue l'iterazione di un elenco di tabelle ed esegue l'operazione di copia incrementale.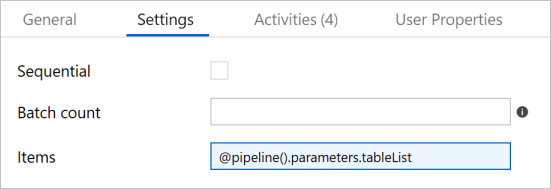
Selezionare l'attività ForEach nella pipeline se non è già selezionata. Fare clic sul pulsante Modifica (icona a forma di matita).
Nella casella degli strumenti Attività espandere Generale, trascinare l'attività Cerca nell'area di progettazione della pipeline e immettere LookupOldWaterMarkActivity in Nome.
Passare alla scheda Impostazioni della finestra Proprietà e seguire questa procedura:
Selezionare WatermarkDataset per Source Dataset (Set di dati di origine).
Selezionare Query per Use Query (Usa query).
Immettere la query SQL seguente per Query.
select * from watermarktable where TableName = '@{item().TABLE_NAME}'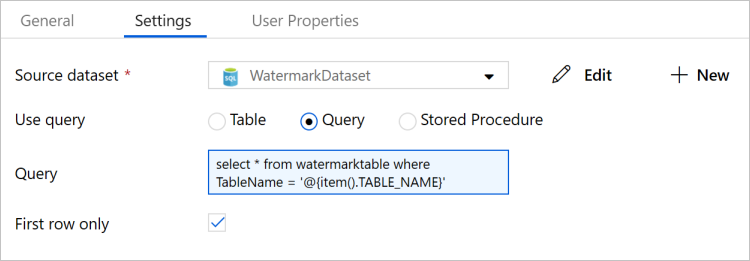
Trascinare l'attività Ricerca dalla casella degli strumenti Attività e immettere LookupNewWaterMarkActivity per Nome.
Passare alla scheda Impostazioni .
Selezionare SourceDataset per Source Dataset (Set di dati di origine).
Selezionare Query per Use Query (Usa query).
Immettere la query SQL seguente per Query.
select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}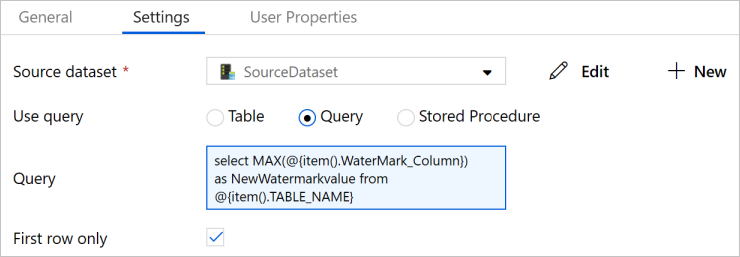
Trascinare l'attività Copia dalla casella degli strumenti Attività e immettere IncrementalCopyActivity per Nome.
Una alla volta, connettere le attività Ricerca all'attività Copia. Per connetterle, iniziare il trascinamento dalla casella verde dell'attività Ricerca e rilasciarla sull'attività Copia. Rilasciare il pulsante del mouse quando il bordo dell'attività di copia diventa di colore blu.
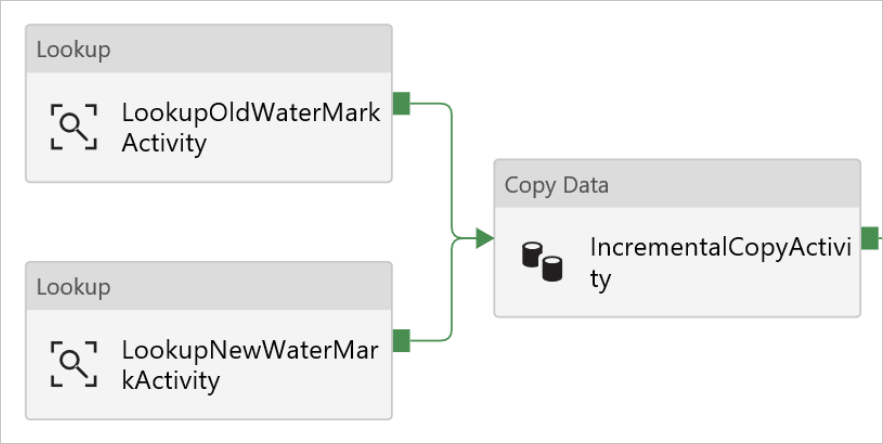
Selezionare l'attività Copia nella pipeline. Passare alla scheda Origine nella finestra Proprietà.
Selezionare SourceDataset per Source Dataset (Set di dati di origine).
Selezionare Query per Use Query (Usa query).
Immettere la query SQL seguente per Query.
select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'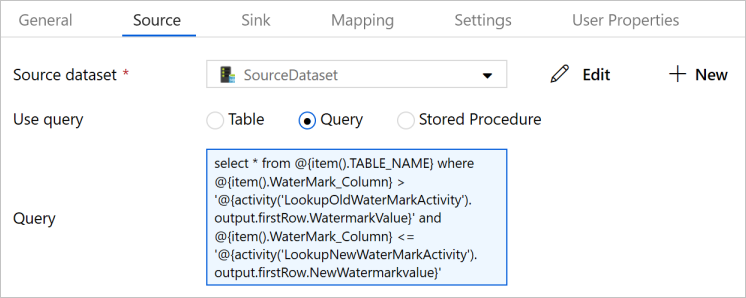
Passare alla scheda Sink e selezionare SinkDataset in Sink Dataset (Set di dati sink).
Effettua i passaggi seguenti:
In Proprietà set di dati immettere
@{item().TABLE_NAME}per il parametro SinkTableName.Per la proprietà Stored Procedure Name (Nome stored procedure) immettere
@{item().StoredProcedureNameForMergeOperation}.Per la proprietà Table Type (Tipo di tabella) immettere
@{item().TableType}.Per la proprietà Table type parameter name (Nome del parametro di tipo di tabella) immettere
@{item().TABLE_NAME}.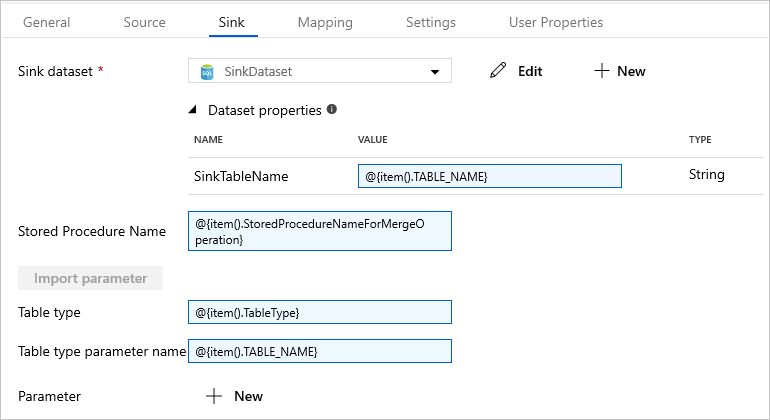
Trascinare l'attività Stored procedure dalla casella degli strumenti Attività all'area di progettazione della pipeline. Connettere l'attività Copia all'attività Stored procedure.
Selezionare l'attività Stored procedure nella pipeline e immettere StoredProceduretoWriteWatermarkActivity per Nome nella scheda Generale della finestra Proprietà.
Passare alla scheda Account SQL e selezionare AzureSqlDatabaseLinkedService per Servizio collegato.

Passare alla scheda Stored procedure e seguire questa procedura:
In Nome stored procedure selezionare
[dbo].[usp_write_watermark].Selezionare Import parameter (Importa parametro).
Specificare i valori seguenti per i parametri:
Nome Type Valore LastModifiedtime Data/Ora @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}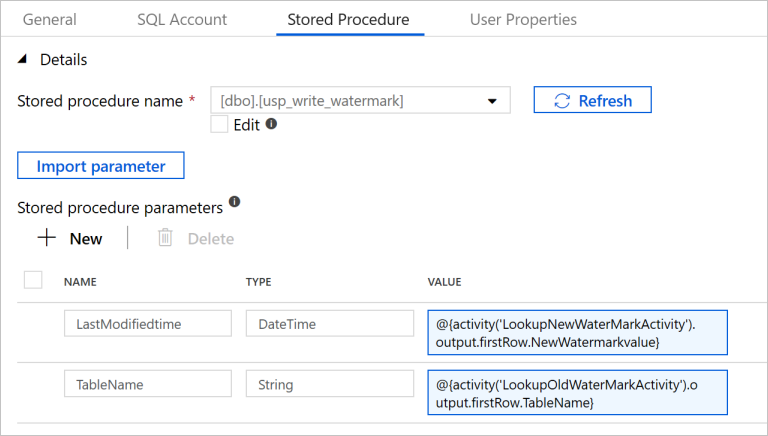
Per pubblicare le entità create nel servizio Data Factory, selezionare Pubblica tutti.
Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita. Per visualizzare le notifiche, fare clic sul collegamento Show Notifications (Mostra notifiche). Per chiudere la finestra delle notifiche, fare clic su X.
Eseguire la pipeline
Sulla barra degli strumenti per la pipeline fare clic su Aggiungi trigger e quindi su Trigger Now (Attiva adesso).
Nella finestra Pipeline Run (Esecuzione di pipeline) immettere il valore seguente per il parametro tableList e fare clic su Fine.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]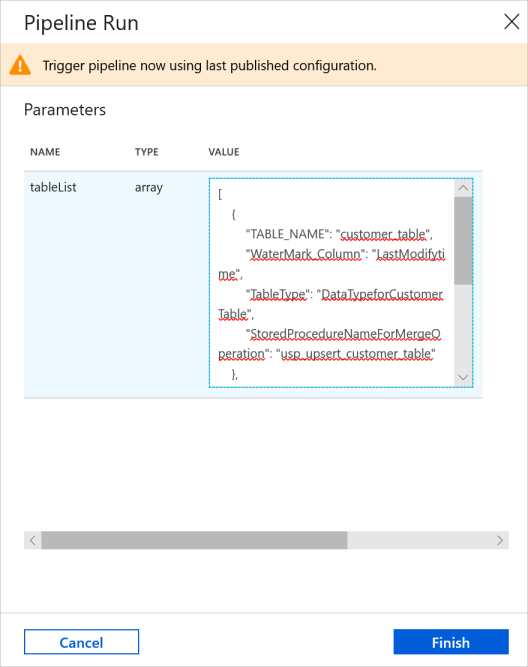
Monitorare la pipeline
Passare alla scheda Monitoraggio a sinistra. Viene visualizzata l'esecuzione della pipeline attivata dal trigger manuale. È possibile usare i collegamenti nella colonna NOME PIPELINE per visualizzare i dettagli delle attività ed eseguire di nuovo la pipeline.
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il collegamento sotto la colonna NOME PIPELINE. Per i dettagli sulle esecuzioni di attività, selezionare il collegamento Dettagli (icona degli occhiali) sotto la colonna NOME ATTIVITÀ.
Per tornare alla visualizzazione Esecuzioni della pipeline, selezionare Tutte le esecuzioni di pipeline in alto. Per aggiornare la visualizzazione, selezionare Aggiorna.
Esaminare i risultati
In SQL Server Management Studio eseguire queste query sul database SQL di destinazione per verificare che i dati siano stati copiati dalle tabelle di origine alle tabelle di destinazione:
Query
select * from customer_table
Output
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Query
select * from project_table
Output
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Query
select * from watermarktable
Output
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Notare che i valori del limite per entrambe le tabelle sono stati aggiornati.
Aggiungere altri dati alle tabelle di origine
Eseguire questa query sul database di SQL Server di origine per aggiornare una riga esistente in customer_table. Inserire una nuova riga in project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Eseguire di nuovo la pipeline
Nella finestra del Web browser passare alla scheda Modifica a sinistra.
Sulla barra degli strumenti per la pipeline fare clic su Aggiungi trigger e quindi su Trigger Now (Attiva adesso).
Nella finestra Pipeline Run (Esecuzione di pipeline) immettere il valore seguente per il parametro tableList e fare clic su Fine.
[ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ]
Monitorare di nuovo la pipeline
Passare alla scheda Monitoraggio a sinistra. Viene visualizzata l'esecuzione della pipeline attivata dal trigger manuale. È possibile usare i collegamenti nella colonna NOME PIPELINE per visualizzare i dettagli delle attività ed eseguire di nuovo la pipeline.
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il collegamento sotto la colonna NOME PIPELINE. Per i dettagli sulle esecuzioni di attività, selezionare il collegamento Dettagli (icona degli occhiali) sotto la colonna NOME ATTIVITÀ.
Per tornare alla visualizzazione Esecuzioni della pipeline, selezionare Tutte le esecuzioni di pipeline in alto. Per aggiornare la visualizzazione, selezionare Aggiorna.
Esaminare i risultati finali
In SQL Server Management Studio eseguire le query seguenti sul database SQL di destinazione per verificare che i dati nuovi/aggiornati siano stati copiati dalle tabelle di origine alle tabelle di destinazione.
Query
select * from customer_table
Output
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Notare i nuovi valori di Name e LastModifytime per PersonID per il numero 3.
Query
select * from project_table
Output
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Si noti che è stata aggiunta la voce NewProject a project_table.
Query
select * from watermarktable
Output
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Notare che i valori del limite per entrambe le tabelle sono stati aggiornati.
Contenuto correlato
In questa esercitazione sono stati eseguiti i passaggi seguenti:
- Preparare gli archivi dati di origine e di destinazione.
- Creare una data factory.
- Creare un runtime di integrazione self-hosted.
- Installare il runtime di integrazione.
- Creare servizi collegati.
- Creare i set di dati di origine, sink e limite.
- Creare, eseguire e monitorare una pipeline.
- Esaminare i risultati.
- Aggiungere o aggiornare dati nelle tabelle di origine.
- Rieseguire e monitorare la pipeline.
- Esaminare i risultati finali.
Passare all'esercitazione successiva per informazioni sulla trasformazione dei dati usando un cluster Spark in Azure: