Copiare in modo incrementale i dati da database SQL di Azure all'archiviazione BLOB usando il rilevamento delle modifiche nel portale di Azure
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
In una soluzione di integrazione dei dati il caricamento incrementale di dati dopo i caricamenti di dati iniziali è uno scenario ampiamente diffuso. I dati modificati in un periodo nell'archivio dati di origine possono essere facilmente sezionati (ad esempio, LastModifyTime, CreationTime). In alcuni casi, tuttavia, non esiste un modo esplicito per identificare i dati differenziali dall'ultima volta che sono stati elaborati i dati. È possibile usare la tecnologia di rilevamento delle modifiche supportata dagli archivi dati, ad esempio database SQL di Azure e SQL Server, per identificare i dati differenziali.
Questa esercitazione descrive come usare Azure Data Factory con il rilevamento delle modifiche per caricare in modo incrementale i dati differenziali da database SQL di Azure in Archiviazione BLOB di Azure. Per altre informazioni sul rilevamento delle modifiche, vedere Rilevamento modifiche in SQL Server.
In questa esercitazione vengono completati i passaggi seguenti:
- Preparare l'archivio dati di origine.
- Creare una data factory.
- Creare servizi collegati.
- Creare set di dati di origine, sink e di rilevamento delle modifiche.
- Creare, eseguire e monitorare la pipeline di copia completa.
- Aggiungere o aggiornare i dati nella tabella di origine.
- Creare, eseguire e monitorare la pipeline di copia incrementale.
Soluzione di alto livello
In questa esercitazione vengono create due pipeline che eseguono le operazioni seguenti.
Nota
Questa esercitazione usa il database SQL di Azure come archivio dati di origine. È anche possibile usare SQL Server.
Caricamento iniziale dei dati cronologici: si crea una pipeline con un'attività di copia che copia tutti i dati dall'archivio dati di origine (database SQL di Azure) all'archivio dati di destinazione (Archiviazione BLOB di Azure):
- Abilitare la tecnologia di rilevamento delle modifiche nel database di origine in database SQL di Azure.
- Ottenere il valore iniziale di
SYS_CHANGE_VERSIONnel database come linea di base per acquisire i dati modificati. - Caricare dati completi dal database di origine in Archiviazione BLOB di Azure.

Caricamento incrementale dei dati differenziali in base a una pianificazione: creare una pipeline con le attività seguenti ed eseguirla periodicamente:
Creare due attività di ricerca per ottenere i valori precedenti e nuovi
SYS_CHANGE_VERSIONda database SQL di Azure.Creare un'attività di copia per copiare i dati inseriti, aggiornati o eliminati (i dati differenziali) tra i due
SYS_CHANGE_VERSIONvalori da database SQL di Azure a Archiviazione BLOB di Azure.I dati differenziali vengono caricati unendo le chiavi primarie delle righe modificate (tra due
SYS_CHANGE_VERSIONvalori) dasys.change_tracking_tablescon i dati nella tabella di origine e quindi spostando i dati differenziali nella destinazione.Creare un'attività stored procedure per aggiornare il valore di
SYS_CHANGE_VERSIONper l'esecuzione successiva della pipeline.

Prerequisiti
- Sottoscrizione di Azure. Se non se ne dispone, creare un account gratuito prima di iniziare.
- Database SQL di Azure. Si usa un database in database SQL di Azure come archivio dati di origine. Se non è disponibile, vedere Creare un database in database SQL di Azure per la procedura per crearla.
- Account di archiviazione di Azure. L'archivio BLOB viene usato come archivio dati sink . Se non si ha un account di archiviazione di Azure, vedere Creare un account di archiviazione per la procedura per crearne uno. Creare un contenitore denominato adftutorial.
Nota
È consigliabile usare il modulo Azure Az PowerShell per interagire con Azure. Per iniziare, vedere Installare Azure PowerShell. Per informazioni su come eseguire la migrazione al modulo AZ PowerShell, vedere Eseguire la migrazione di Azure PowerShell da AzureRM ad Az.
Creare una tabella di origine dati nel database SQL di Azure
Aprire SQL Server Management Studio e connettersi a database SQL.
In Esplora server fare clic con il pulsante destro del mouse sul database e quindi scegliere Nuova query.
Eseguire il comando SQL seguente sul database per creare una tabella denominata
data_source_tablecome archivio dati di origine:create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Abilitare il rilevamento delle modifiche nel database e nella tabella di origine (
data_source_table) eseguendo la query SQL seguente.Nota
- Sostituire
<your database name>con il nome del database in database SQL di Azure condata_source_table. - Nell'esempio corrente i dati modificati vengono mantenuti per due giorni. Se i dati modificati vengono caricati ogni tre giorni o più, alcuni non verranno inclusi. È necessario modificare il valore di
CHANGE_RETENTIONin un numero maggiore o assicurarsi che il periodo di caricamento dei dati modificati sia entro due giorni. Per altre informazioni, vedere Abilitare il rilevamento delle modifiche per un database.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Sostituire
Creare una nuova tabella e archiviare denominata
ChangeTracking_versioncon un valore predefinito eseguendo la query seguente:create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Nota
Se i dati non vengono modificati dopo aver abilitato il rilevamento delle modifiche per database SQL, il valore della versione di rilevamento modifiche è
0.Eseguire la query seguente per creare una stored procedure nel database. La pipeline richiama questa stored procedure per aggiornare la versione di rilevamento delle modifiche nella tabella creata nel passaggio precedente.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Creare una data factory
Aprire il Web browser Microsoft Edge o Google Chrome. Attualmente, solo questi browser supportano l'interfaccia utente di Data Factory.
Nel portale di Azure scegliere Crea una risorsa dal menu a sinistra.
Selezionare Integration Data Factory(Integrazione>data factory).
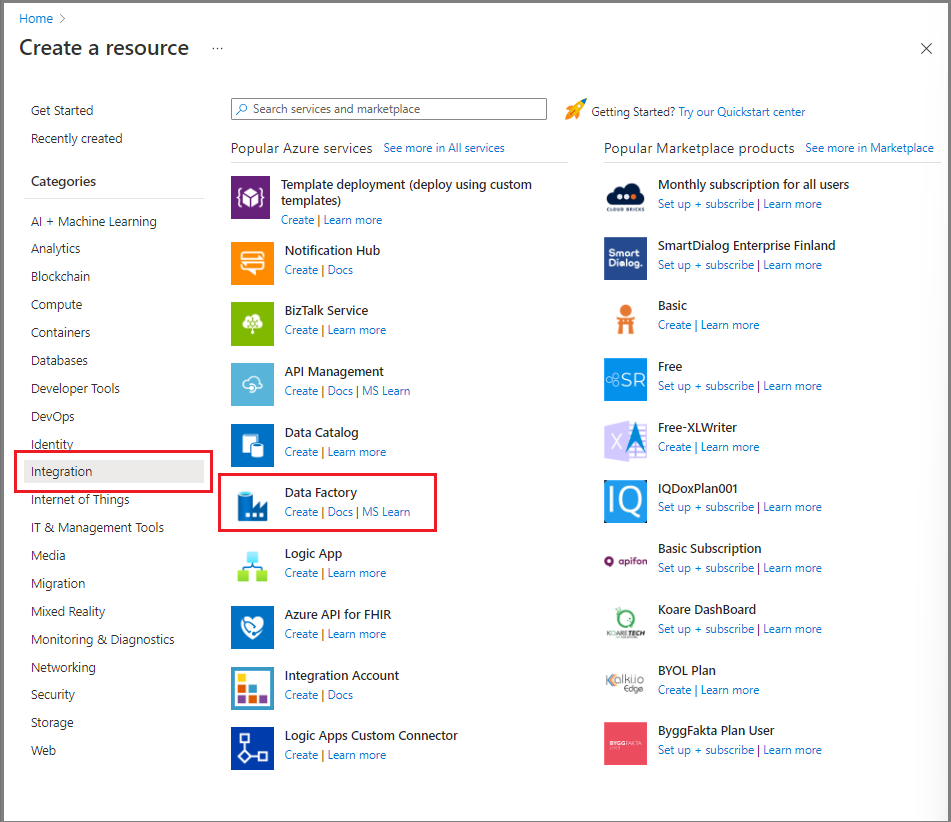
Nella pagina Nuova data factory immettere ADFTutorialDataFactory come nome.
Il nome della data factory deve essere globalmente univoco. Se viene visualizzato un errore che indica che il nome scelto non è disponibile, modificare il nome (ad esempio, in nomeADFTutorialDataFactory) e provare a creare nuovamente la data factory. Per altre informazioni, vedere Regole di denominazione di Azure Data Factory.
Selezionare la sottoscrizione di Azure in cui creare la data factory.
In Gruppo di risorse eseguire una di queste operazioni:
- Selezionare Usa esistente e quindi selezionare un gruppo di risorse esistente nell'elenco a discesa.
- Selezionare Crea nuovo e quindi immettere il nome di un gruppo di risorse.
Per informazioni sui gruppi di risorse, vedere l'articolo relativo all'uso di gruppi di risorse per la gestione delle risorse di Azure.
Per Versione selezionare V2.
In Area selezionare l'area per la data factory.
Nell'elenco a discesa vengono visualizzate solo le posizioni supportate. Gli archivi dati (ad esempio, Archiviazione di Azure e database SQL di Azure) e i calcoli (ad esempio, Azure HDInsight) usati da una data factory possono trovarsi in altre aree.
Selezionare Avanti: Configurazione Git. Configurare il repository seguendo le istruzioni riportate in Metodo di configurazione 4: Durante la creazione della factory o selezionare la casella di controllo Configura Git in un secondo momento .
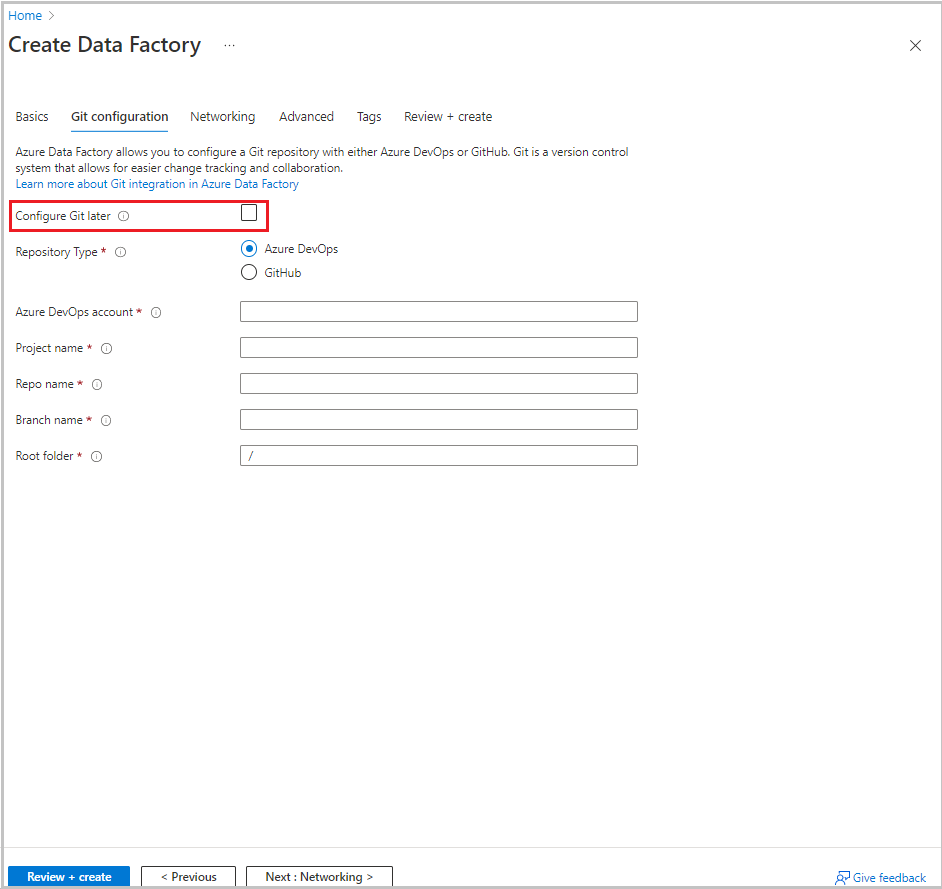
Selezionare Rivedi e crea.
Seleziona Crea.
Nel dashboard il riquadro Deploying Data Factory (Distribuzione di Data Factory ) mostra lo stato.

Al termine della creazione, viene visualizzata la pagina Data Factory . Selezionare il riquadro Launch Studio (Avvia studio ) per aprire l'interfaccia utente di Azure Data Factory in una scheda separata.
Creare servizi collegati
Si creano servizi collegati in una data factory per collegare gli archivi dati e i servizi di calcolo alla data factory. In questa sezione vengono creati servizi collegati all'account di archiviazione di Azure e al database in database SQL di Azure.
Creare un servizio collegato Archiviazione di Azure
Per collegare l'account di archiviazione alla data factory:
- Nell'interfaccia utente di Data Factory, nella scheda Gestisci, in Connessioni selezionare Servizi collegati. Selezionare quindi + Nuovo o il pulsante Crea servizio collegato.
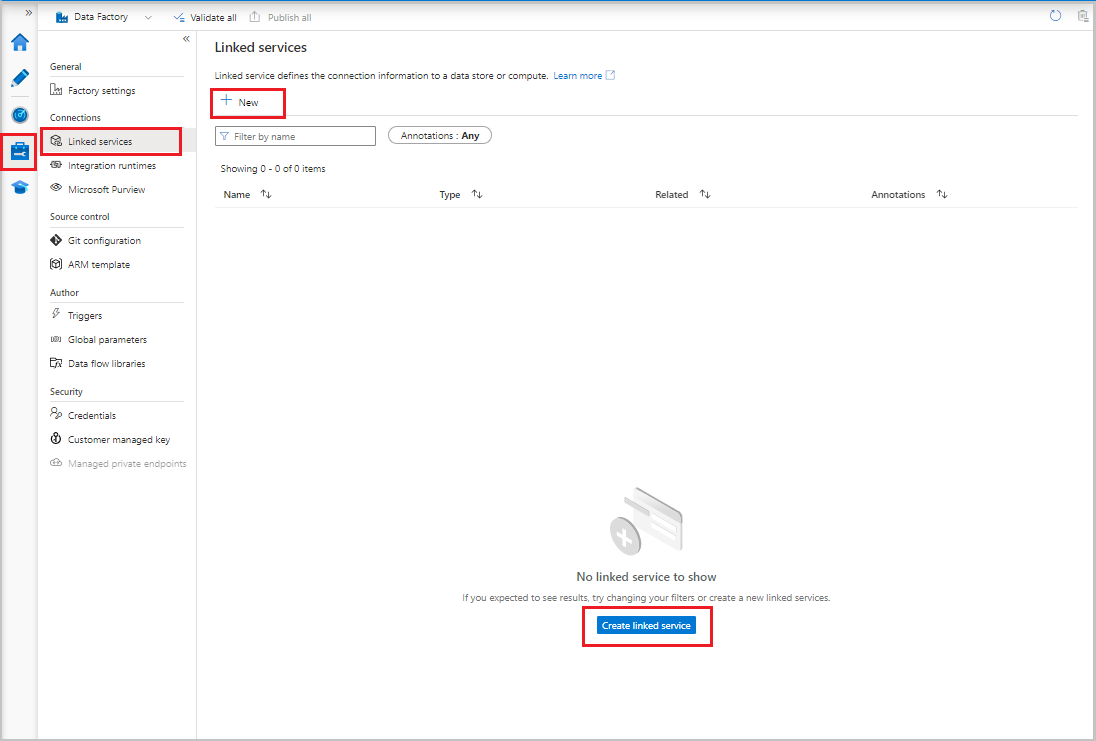
- Nella finestra Nuovo servizio collegato selezionare Archiviazione BLOB di Azure e quindi selezionare Continua.
- Immettere le informazioni seguenti:
- Per Nome immettere AzureStorageLinkedService.
- Per Connetti tramite runtime di integrazione selezionare il runtime di integrazione.
- In Tipo di autenticazione selezionare un metodo di autenticazione.
- Per Nome account di archiviazione selezionare l'account di archiviazione di Azure.
- Seleziona Crea.
Creare un servizio collegato Database SQL di Azure
Per collegare il database alla data factory:
Nell'interfaccia utente di Data Factory, nella scheda Gestisci, in Connessioni selezionare Servizi collegati. Selezionare quindi + Nuovo.
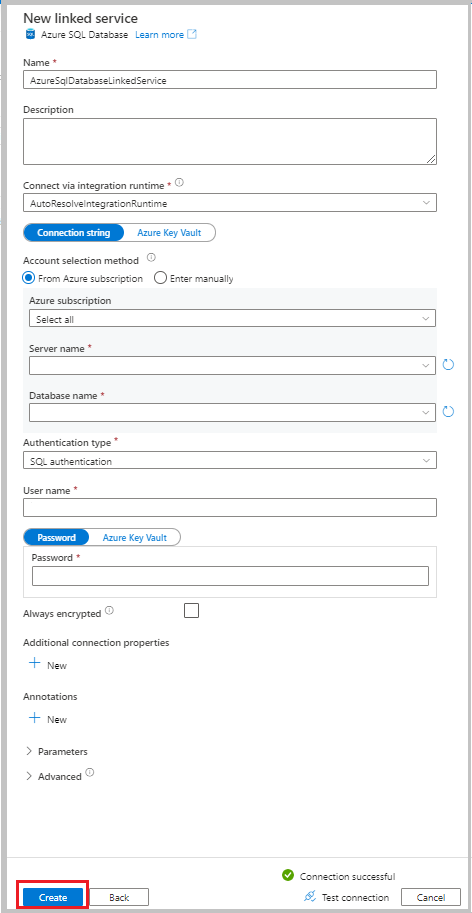
Nella finestra Nuovo servizio collegato selezionare database SQL di Azure e quindi selezionare Continua.
Immettere le informazioni seguenti:
- In Nome immettere AzureSqlDatabaseLinkedService.
- In Nome server selezionare il server.
- In Nome database selezionare il database.
- In Tipo di autenticazione selezionare un metodo di autenticazione. Questa esercitazione usa l'autenticazione SQL per la dimostrazione.
- In Nome utente immettere il nome dell'utente.
- Per Password immettere una password per l'utente. In alternativa, specificare le informazioni per Azure Key Vault - Servizio collegato AKV, Nome segreto e Versione privata.
Selezionare Test connessione per testare la connessione.
Selezionare Crea per creare il servizio collegato.
Creare i set di dati
In questa sezione vengono creati set di dati per rappresentare l'origine dati e la destinazione dati, insieme alla posizione in cui archiviare i SYS_CHANGE_VERSION valori.
Creare un set di dati per rappresentare i dati di origine
Nella scheda Autore dell'interfaccia utente di Data Factory selezionare il segno più (+). Selezionare quindi Set di dati o selezionare i puntini di sospensione per le azioni del set di dati.
Selezionare Database SQL di Azure e quindi selezionare Continua.
Nella finestra Imposta proprietà seguire questa procedura:
- In Nome immettere SourceDataset.
- Per Servizio collegato selezionare AzureSqlDatabaseLinkedService.
- In Nome tabella selezionare dbo.data_source_table.
- Per Importa schema selezionare l'opzione Da connessione/archivio .
- Seleziona OK.

Creare un set di dati per rappresentare i dati copiati nell'archivio dati sink
Nella procedura seguente viene creato un set di dati per rappresentare i dati copiati dall'archivio dati di origine. Il contenitore adftutorial è stato creato in Archiviazione BLOB di Azure come parte dei prerequisiti. Creare il contenitore se non esiste oppure impostare il nome di un contenitore esistente. In questa esercitazione il nome del file di output viene generato dinamicamente dall'espressione @CONCAT('Incremental-', pipeline().RunId, '.txt').
Nella scheda Autore dell'interfaccia utente di Data Factory selezionare +. Selezionare quindi Set di dati o selezionare i puntini di sospensione per le azioni del set di dati.
Selezionare Archiviazione BLOB di Azure e quindi continua.
Selezionare il formato del tipo di dati come DelimitedText e quindi selezionare Continua.
Nella finestra Imposta proprietà seguire questa procedura:
- In Nome immettere SinkDataset.
- Per Servizio collegato selezionare AzureBlobStorageLinkedService.
- In Percorso file immettere adftutorial/incchgtracking.
- Seleziona OK.
Dopo che il set di dati viene visualizzato nella visualizzazione albero, passare alla scheda Connessione e selezionare la casella di testo Nome file. Quando viene visualizzata l'opzione Aggiungi contenuto dinamico, selezionarla.
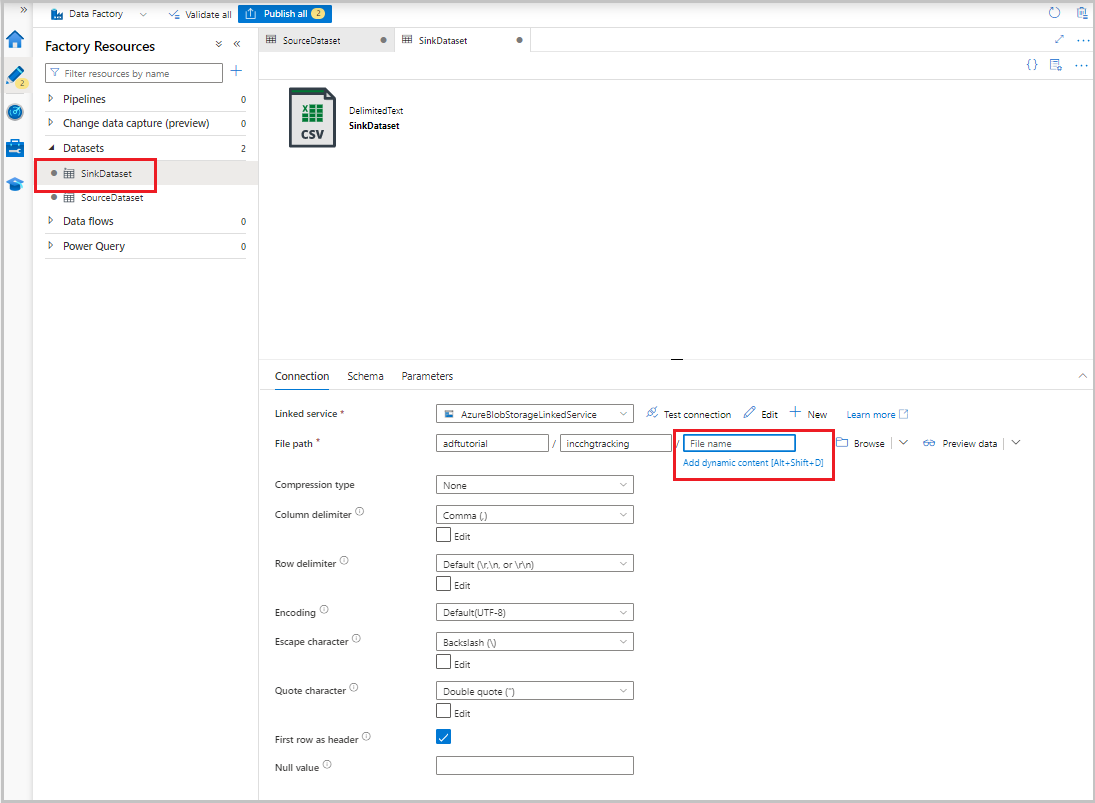
Verrà visualizzata la finestra Generatore di espressioni pipeline. Incollare
@concat('Incremental-',pipeline().RunId,'.csv')nella casella di testo.Seleziona OK.
Creare un set di dati per rappresentare i dati di rilevamento delle modifiche
Nella procedura seguente viene creato un set di dati per l'archiviazione della versione di rilevamento modifiche. La tabella è stata creata table_store_ChangeTracking_version come parte dei prerequisiti.
- Nella scheda Autore dell'interfaccia utente di Data Factory selezionare +e quindi Set di dati.
- Selezionare Database SQL di Azure e quindi selezionare Continua.
- Nella finestra Imposta proprietà seguire questa procedura:
- In Nome immettere ChangeTrackingDataset.
- Per Servizio collegato selezionare AzureSqlDatabaseLinkedService.
- In Nome tabella selezionare dbo.table_store_ChangeTracking_version.
- Per Importa schema selezionare l'opzione Da connessione/archivio .
- Seleziona OK.
Creare una pipeline per la copia completa
Nella procedura seguente viene creata una pipeline con un'attività di copia che copia tutti i dati dall'archivio dati di origine (database SQL di Azure) all'archivio dati di destinazione (Archiviazione BLOB di Azure):
Nell'interfaccia utente di Data Factory, nella scheda Autore selezionare +e quindi pipeline>.
Viene visualizzata una nuova scheda per la configurazione della pipeline. La pipeline viene visualizzata anche nella visualizzazione albero. Nella finestra Proprietà modificare il nome della pipeline in FullCopyPipeline.
Nella casella degli strumenti Attività espandere Sposta e trasforma. Eseguire uno dei passaggi seguenti:
- Trascinare l'attività di copia nell'area di progettazione della pipeline.
- Nella barra di ricerca in Attività cercare l'attività di copia dei dati e quindi impostare il nome su FullCopyActivity.
Passare alla scheda Origine . Per Set di dati di origine selezionare SourceDataset.
Passare alla scheda Sink . Per Set di dati sink selezionare SinkDataset.
Per convalidare la definizione della pipeline, selezionare Convalida sulla barra degli strumenti. Verificare che non sia presente alcun errore di convalida. Chiudere l'output di convalida della pipeline.
Per pubblicare entità (servizi collegati, set di dati e pipeline), selezionare Pubblica tutto. Attendere fino alla visualizzazione del messaggio Pubblicazione riuscita.
Per visualizzare le notifiche, selezionare il pulsante Mostra notifiche .
Eseguire la pipeline di copia completa
Nell'interfaccia utente di Data Factory, sulla barra degli strumenti per la pipeline selezionare Aggiungi trigger e quindi selezionare Attiva adesso.
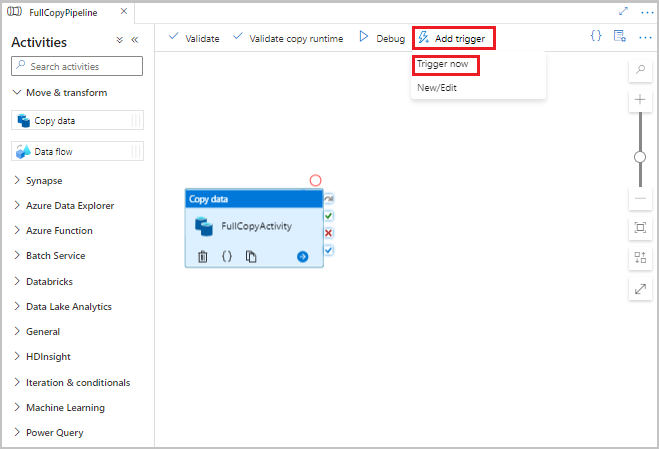
Nella finestra Esecuzione pipeline selezionare OK.

Monitorare la pipeline di copia completa
Nell'interfaccia utente di Data Factory selezionare la scheda Monitoraggio . L'esecuzione della pipeline e il relativo stato vengono visualizzati nell'elenco. Per aggiornare l'elenco, selezionare Aggiorna. Passare il puntatore del mouse sull'esecuzione della pipeline per ottenere l'opzione Riesegui o Consumo .
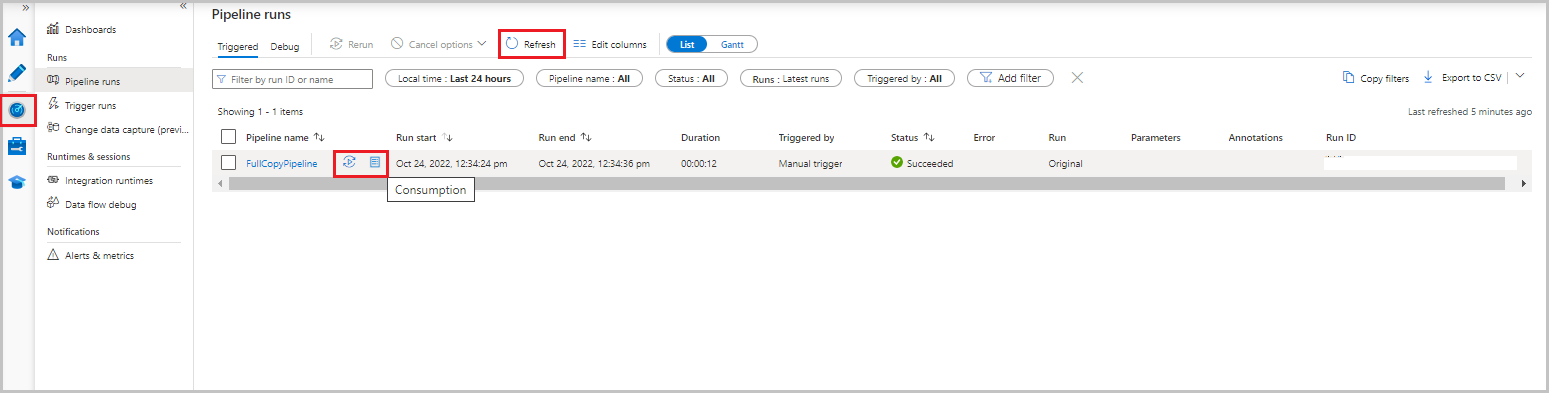
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il nome della pipeline dalla colonna Nome pipeline. Nella pipeline è presente una sola attività, quindi è presente una sola voce nell'elenco. Per tornare alla visualizzazione delle esecuzioni della pipeline, selezionare il collegamento Tutte le esecuzioni della pipeline nella parte superiore.
Esaminare i risultati
La cartella incchgtracking del contenitore adftutorial include un file denominato incremental-<GUID>.csv.
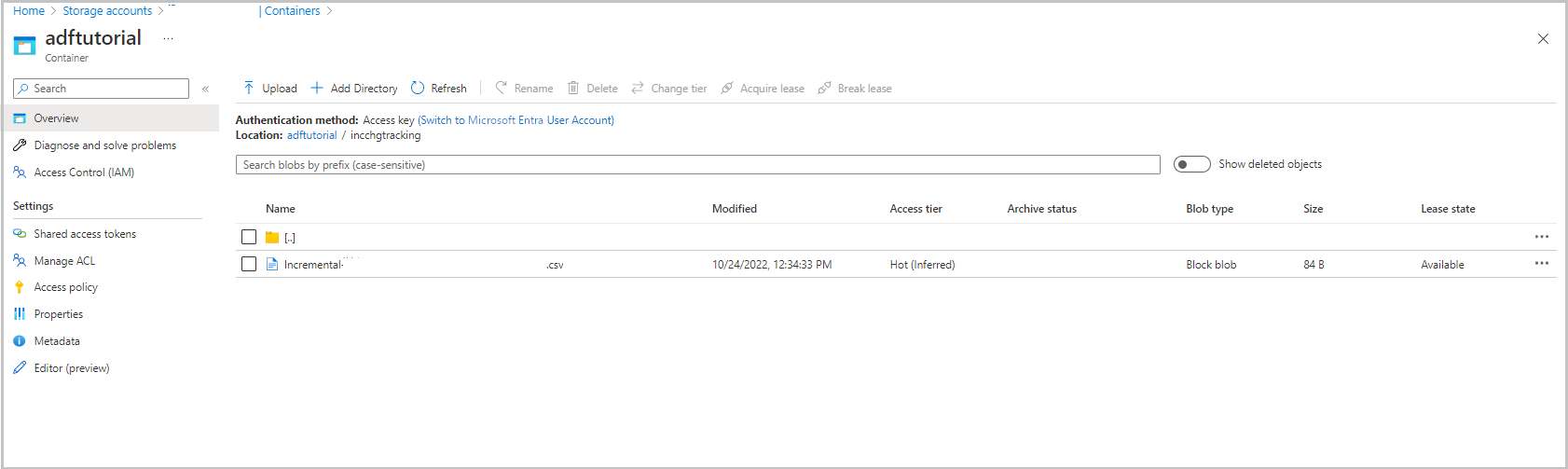
Il file conterrà i dati del database:
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Aggiungere altri dati alla tabella di origine
Eseguire la query seguente sul database per aggiungere una riga e aggiornare una riga:
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Creare una pipeline per la copia differenziale
Nella procedura seguente viene creata una pipeline con attività ed eseguita periodicamente. Quando si esegue la pipeline:
- Le attività di ricerca ottengono i valori vecchi e nuovi
SYS_CHANGE_VERSIONda database SQL di Azure e li passano all'attività di copia. - L'attività di copia copia i dati inseriti, aggiornati o eliminati tra i due
SYS_CHANGE_VERSIONvalori da database SQL di Azure a Archiviazione BLOB di Azure. - L'attività della stored procedure aggiorna il valore di
SYS_CHANGE_VERSIONper l'esecuzione successiva della pipeline.
Nell'interfaccia utente di Data Factory passare alla scheda Autore. Selezionare +e quindi pipeline.>
Viene visualizzata una nuova scheda per la configurazione della pipeline. La pipeline viene visualizzata anche nella visualizzazione albero. Nella finestra Proprietà modificare il nome della pipeline in IncrementalCopyPipeline.
Espandere Generale nella casella degli strumenti Attività . Trascinare l'attività di ricerca nell'area di progettazione della pipeline o cercare nella casella Attività di ricerca . Impostare il nome dell'attività su LookupLastChangeTrackingVersionActivity. Questa attività ottiene la versione di rilevamento delle modifiche usata nell'ultima operazione di copia archiviata nella
table_store_ChangeTracking_versiontabella.Passare alla scheda Impostazioni nella finestra Proprietà. Per Set di dati di origine selezionare ChangeTrackingDataset.
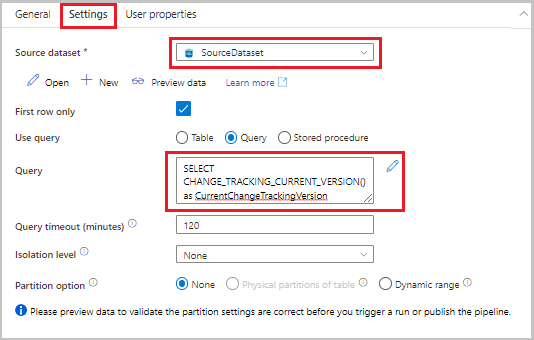
Trascinare l'attività di ricerca dalla casella degli strumenti Attività all'area di progettazione della pipeline. Impostare il nome dell'attività su LookupCurrentChangeTrackingVersionActivity. Questa attività recupera la versione corrente del rilevamento modifiche.
Passare alla scheda Impostazioni nella finestra Proprietà e quindi seguire questa procedura:
In Set di dati di origine selezionare SourceDataset.
In Usa query selezionare Query.
Per Query immettere la query SQL seguente:
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
Nella casella degli strumenti Attività espandere Sposta e trasforma. Trascinare l'attività di copia dei dati nell'area di progettazione della pipeline. Impostare il nome dell'attività su IncrementalCopyActivity. Questa attività copia i dati tra l'ultima versione del rilevamento modifiche e la versione corrente del rilevamento delle modifiche nell'archivio dati di destinazione.
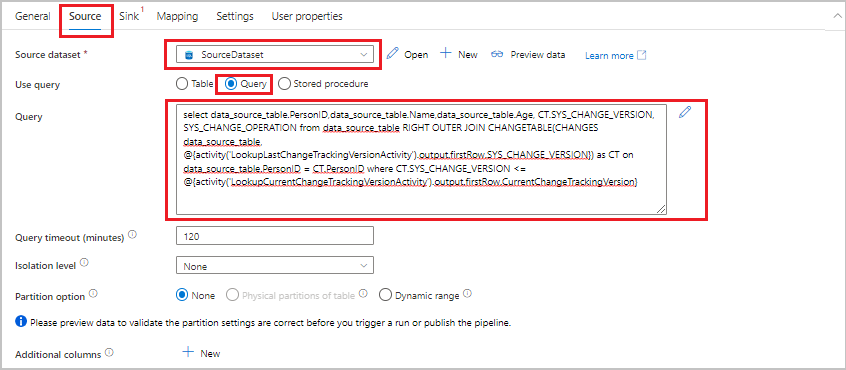
Passare alla scheda Origine nella finestra Proprietà e quindi seguire questa procedura:
In Set di dati di origine selezionare SourceDataset.
In Usa query selezionare Query.
Per Query immettere la query SQL seguente:
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
Passare alla scheda Sink . Per Set di dati sink selezionare SinkDataset.
Connettere entrambe le attività di ricerca all'attività di copia una alla sola. Trascinare il pulsante verde associato all'attività di ricerca all'attività di copia.
Trascinare l'attività della stored procedure dalla casella degli strumenti Attività all'area di progettazione della pipeline. Impostare il nome dell'attività su StoredProceduretoUpdateChangeTrackingActivity. Questa attività aggiorna la versione di rilevamento delle modifiche nella
table_store_ChangeTracking_versiontabella .Passare alla scheda Impostazioni e quindi seguire questa procedura:
- Per Servizio collegato selezionare AzureSqlDatabaseLinkedService.
- In Nome stored procedure selezionare Update_ChangeTracking_Version.
- Selezionare Importa.
- Nella sezione Parametri stored procedure specificare i valori seguenti per i parametri:
Nome Type Valore CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}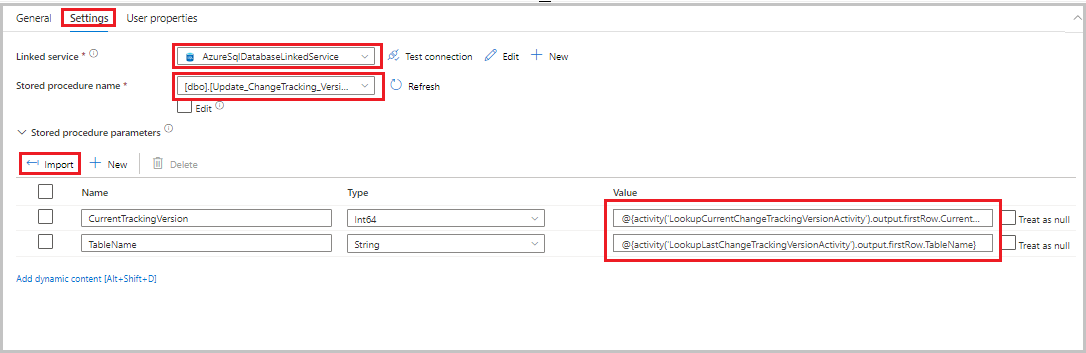
Connettere l'attività di copia all'attività stored procedure. Trascinare il pulsante verde associato all'attività di copia all'attività di stored procedure.
Selezionare Convalida sulla barra degli strumenti. Verificare che non siano presenti errori di convalida. Chiudere la finestra Report di convalida della pipeline.
Pubblicare entità (servizi collegati, set di dati e pipeline) nel servizio Data Factory selezionando il pulsante Pubblica tutto . Attendere che venga visualizzato il messaggio Pubblicazione completata .
Eseguire la pipeline di copia incrementale
Selezionare Aggiungi trigger sulla barra degli strumenti per la pipeline e quindi selezionare Attiva adesso.
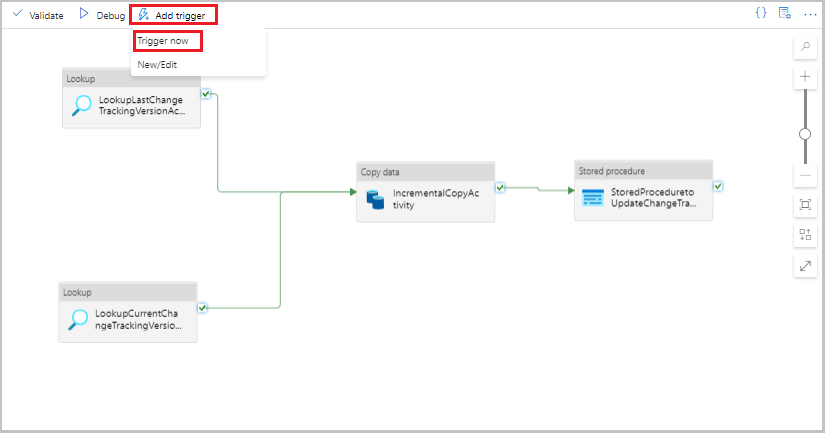
Nella finestra Pipeline Run (Esecuzione pipeline) selezionare OK.
Monitorare la pipeline di copia incrementale
Selezionare la scheda Monitoraggio . L'esecuzione della pipeline e il relativo stato vengono visualizzati nell'elenco. Per aggiornare l'elenco, selezionare Aggiorna.
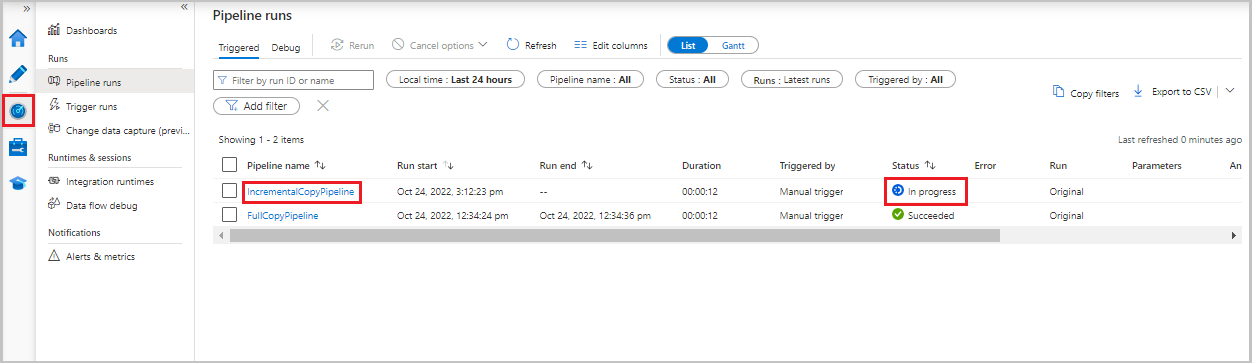
Per visualizzare le esecuzioni di attività associate all'esecuzione della pipeline, selezionare il collegamento IncrementalCopyPipeline nella colonna Nome pipeline. Le esecuzioni di attività vengono visualizzate in un elenco.
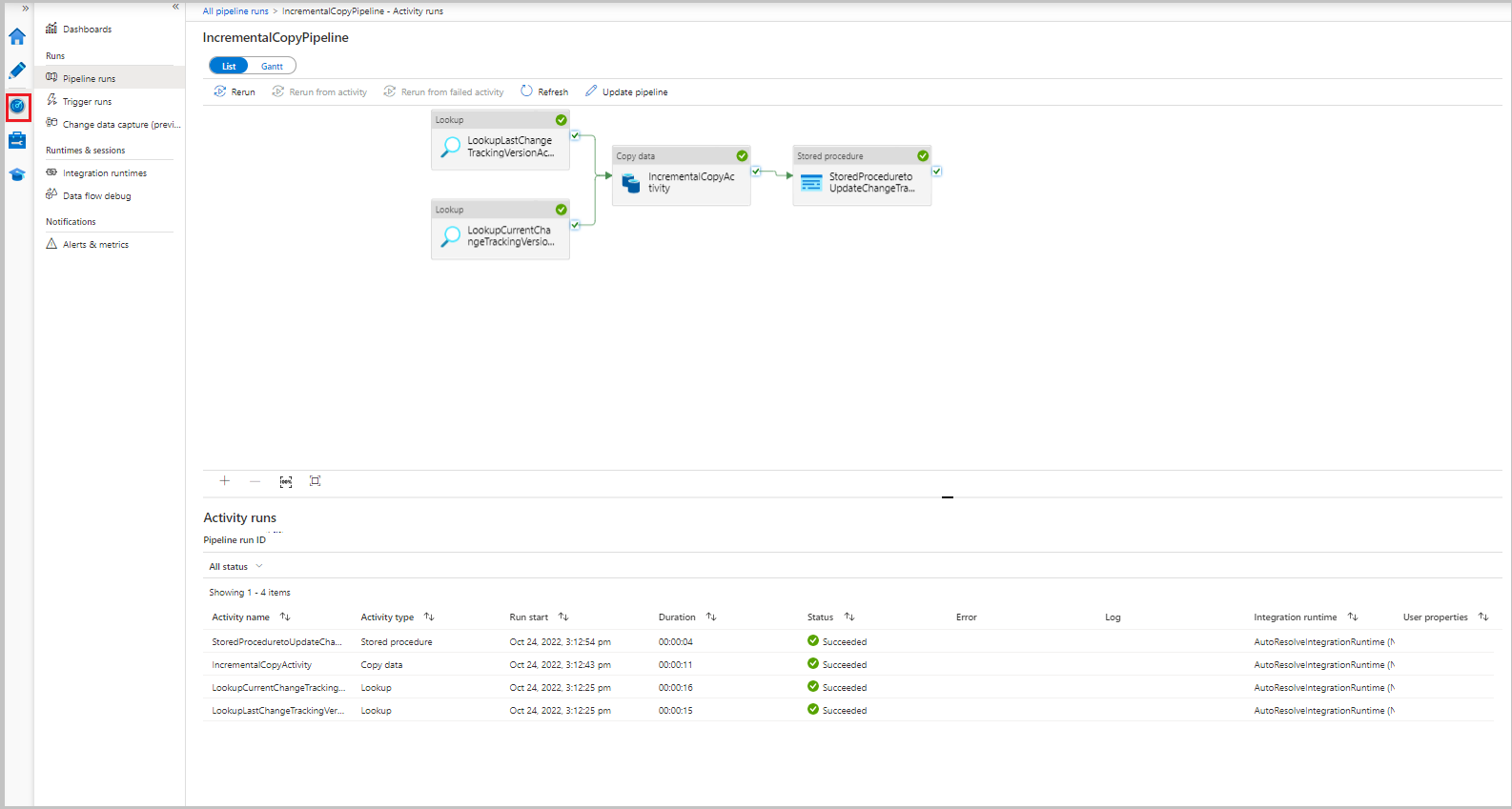
Esaminare i risultati
Il secondo file viene visualizzato nella cartella incchgtracking del contenitore adftutorial .
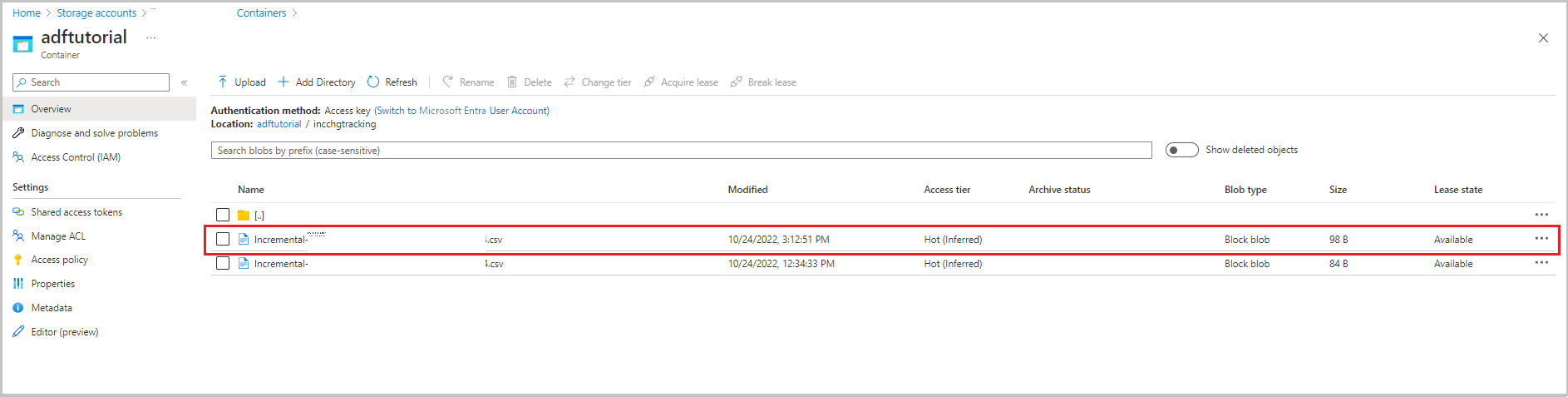
Il file conterrà solo i dati differenziali del database. Il record con U è la riga aggiornata nel database ed I è la riga aggiunta.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
Le prime tre colonne vengono modificate dai dati di data_source_table. Le ultime due colonne sono i metadati della tabella per il sistema di rilevamento delle modifiche. La quarta colonna è il SYS_CHANGE_VERSION valore per ogni riga modificata. La quinta colonna è l'operazione: U = update, I = insert. Per tutti i dettagli sulle informazioni di rilevamento delle modifiche, vedere CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Contenuto correlato
Passare all'esercitazione seguente per informazioni sulla copia solo di file nuovi e modificati, in LastModifiedDatebase a :