Creare una pipeline predittiva usando Machine Learning Studio (versione classica) con Azure Data Factory o Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Importante
Il supporto di Azure Machine Learning Studio (versione classica) terminerà il 31 agosto 2024. Si consiglia di passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non è possibile creare nuove risorse (area di lavoro e piano di servizio Web) dello di Machine Learning Studio (versione classica). Fino al 31 agosto 2024 è possibile continuare a usare gli esperimenti e i servizi Web esistenti di Machine Learning Studio (versione classica). Per altre informazioni, vedi:
- Migrare a Azure Machine Learning da Machine Learning Studio (versione classica)
- Cos'è Azure Machine Learning?
La documentazione relativa a Machine Learning Studio (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Nota
Poiché le risorse di Machine Learning Studio (versione classica) non possono più essere create dopo il 1° dicembre 2021, gli utenti sono invitati a usare Azure Machine Learning con l'attività Execute Pipeline di Machine Learning anziché usare l'attività Batch Execution per eseguire batch di Machine Learning Studio (versione classica).
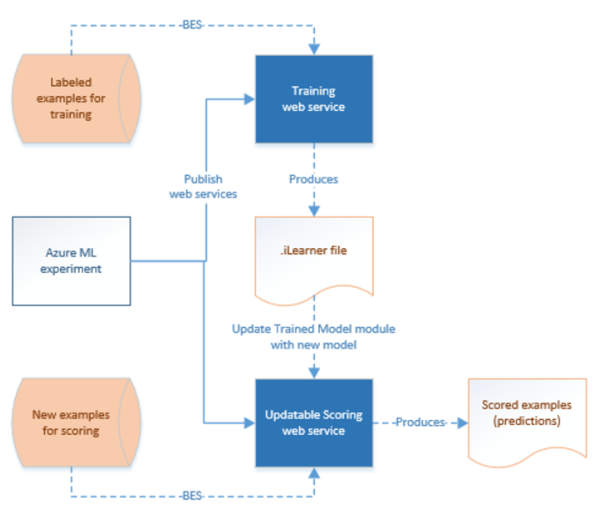
Studio di Azure Machine Learning (versione classica) consente di compilare, testare e distribuire soluzioni di analisi predittiva. Da un punto di vista generale, questo avviene in tre passaggi:
- Creare un esperimento di training. Questo passaggio deve essere eseguito con studio di ML (versione classica). Studio di ML (versione classica) è un ambiente di sviluppo visivo di collaborazione usato per eseguire il training e il test di un modello di analisi predittiva usando dati di training.
- Convertirlo in un esperimento predittivo. Dopo aver eseguito il training del modello con i dati esistenti, preparare e semplificare l'esperimento di assegnazione dei punteggi quando si è pronti a usarlo per valutare nuovi dati.
- Distribuirlo come servizio Web. È possibile pubblicare l'esperimento di assegnazione dei punteggi come servizio Web di Azure. È possibile inviare dati al modello tramite l'endpoint di questo servizio Web e ricevere le stime dei risultati dal modello.
Usando studio di ML (versione classica) con Azure Data Factory o Synapse Analytics
Azure Data Factory e Synapse Analytics consentono di creare facilmente pipeline che usano un servizio Web di studio di ML (versione classica) pubblicato per l'analisi predittiva. Usando l'attività Batch Execution in una pipeline, è possibile richiamare un servizio Web di studio di ML (versione classica) per eseguire stime sui dati in batch.
Nel corso del tempo è necessario ripetere il training dei modelli predittivi negli esperimenti di assegnazione dei punteggi di studio di ML usando nuovi set di dati di input. È possibile ripetere il training di un modello da una pipeline seguendo questa procedura:
- Pubblicare l'esperimento di training, non l'esperimento predittivo, come servizio Web. Eseguire questo passaggio in studio di ML (versione classica) come è stato fatto per esporre l'esperimento predittivo come servizio Web nello scenario precedente.
- Usare attività Batch Execution di studio di ML (versione classico) per richiamare il servizio Web per l'esperimento di training. In sostanza, è possibile usare attività Batch Execution di studio di ML per richiamare sia il servizio Web di training che il servizio Web di assegnazione dei punteggi.
Al termine della ripetizione del training, aggiornare il servizio Web di assegnazione dei punteggi, ovvero l'esperimento predittivo esposto come servizio Web, con il modello appena sottoposto a training usando l'Attività della risorsa di aggiornamento di studio di ML (versione classica). Per informazioni dettagliate, vedere l'articolo Updating models using Update Resource Activity (Aggiornamento dei modelli con Attività della risorsa di aggiornamento).
Servizio collegato di studio di ML (versione classica)
Si crea un servizio collegato di studio di ML (versione classica) per collegare un servizio Web di studio ML (versione classica). Il servizio collegato viene usato da attività Batch Execution di studio di ML (versione classica) e da Attività della risorsa di aggiornamento.
{
"type" : "linkedServices",
"name": "AzureMLLinkedService",
"properties": {
"type": "AzureML",
"typeProperties": {
"mlEndpoint": "URL to Azure ML Predictive Web Service",
"apiKey": {
"type": "SecureString",
"value": "api key"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Vedere l'articolo Servizi collegati di calcolo per le descrizioni sulle proprietà nella definizione JSON.
Studio di ML (versione classica) supporta sia i servizi Web classici che i nuovi servizi Web per l'esperimento predittivo. È possibile scegliere quello giusto da usare dall'area di lavoro di Data Factory o Synapse. Per ottenere le informazioni necessarie per creare il servizio collegato di studio di ML (versione classica), passare a https://ml.azure.com/, dove sono elencati tutti i servizi Web nuovi e i servizi Web classici. Fare clic sul servizio Web cui si desidera accedere e fare clic sulla pagina Consume (Uso). Copiare la chiave primaria per la proprietà apiKey e le richieste batch per la proprietà mlEndpoint.
Attività di esecuzione batch di ML Studio (versione classica)
Il frammento JSON seguente definisce un'attività Batch Execution di ML Studio (classica). La definizione dell'attività ha un riferimento al servizio collegato di studio di ML (versione classica) creato in precedenza.
{
"name": "AzureMLExecutionActivityTemplate",
"description": "description",
"type": "AzureMLBatchExecution",
"linkedServiceName": {
"referenceName": "AzureMLLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"webServiceInputs": {
"<web service input name 1>": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService1",
"type": "LinkedServiceReference"
},
"FilePath":"path1"
},
"<web service input name 2>": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService1",
"type": "LinkedServiceReference"
},
"FilePath":"path2"
}
},
"webServiceOutputs": {
"<web service output name 1>": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService2",
"type": "LinkedServiceReference"
},
"FilePath":"path3"
},
"<web service output name 2>": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService2",
"type": "LinkedServiceReference"
},
"FilePath":"path4"
}
},
"globalParameters": {
"<Parameter 1 Name>": "<parameter value>",
"<parameter 2 name>": "<parameter 2 value>"
}
}
}
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'attività nella pipeline | Sì |
| description | Testo che descrive l'attività. | No |
| type | Per l'attività U-SQL di Data Lake Analytics, il tipo di attività è AzureMLBatchExecution. | Sì |
| linkedServiceName | Servizi collegati al servizio collegato di studio di ML (versione classica). Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| webServiceInputs | Coppie chiave, valore, mapping dei nomi degli input del servizio Web di studio di ML (versione classica). La chiave deve corrispondere ai parametri di input definiti nel servizio Web di studio di ML (versione classica) pubblicato. Il valore è una coppia di proprietà FilePath e dei servizi collegati di archiviazione di Azure che specifica i percorsi BLOB di input. | No |
| webServiceOutputs | Coppie chiave, valore, mapping dei nomi degli output dei servizi Web di studio di ML (versione classica). La chiave deve corrispondere ai parametri di output definiti nel servizio Web di studio di ML (versione classica) pubblicato. Il valore è una coppia di proprietà FilePath e dei servizi collegati di archiviazione di Azure che specifica i percorsi BLOB di output. | No |
| globalParameters | Coppie chiave, valore da passare all'endpoint del servizio di Batch Execution di studio di ML (versione classica). Le chiavi devono corrispondere ai nomi dei parametri dei servizi Web definiti nel servizio Web pubblicato di studio di ML (versione classica). I valori vengono passati nella proprietà GlobalParameters della richiesta di Batch Execution di studio di ML (versione classica) | No |
Scenario 1: Esperimenti di uso degli input/output del servizio Web che fanno riferimento ai dati presenti nell'archiviazione BLOB di Azure
Il questo scenario il servizio Web di studio di ML esegue stime usando dati provenienti da un file dell'archiviazione BLOB di Azure e archivia i risultati nell'archiviazione BLOB. Il frammento di codice JSON seguente definisce una pipeline con un'attività AzureMLBatchExecution. Viene fatto riferimento ai dati di input e output nell'archiviazione BLOB di Azure tramite una coppia di LinkedName e FilePath. Nell'esempio i servizi collegati di input e output sono diversi; è possibile usare servizi collegati diversi per ognuno degli input/output per il servizio per poter selezionare i file corretti e inviarli al servizio Web di studio di ML (versione classica)
Importante
Nell'esperimento di studio di ML (versione classica), le porte e i parametri globali di input e output del servizio Web hanno nomi predefiniti ("input1", "input2") che è possibile personalizzare. I nomi scelti per le impostazioni webServiceInputs, webServiceOutputs e globalParameters devono corrispondere esattamente ai nomi negli esperimenti. Per verificare il mapping previsto, è possibile visualizzare il payload della richiesta di esempio nella pagina della Guida relativa all'esecuzione in batch per l'endpoint di studio di ML (versione classica).
{
"name": "AzureMLExecutionActivityTemplate",
"description": "description",
"type": "AzureMLBatchExecution",
"linkedServiceName": {
"referenceName": "AzureMLLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"webServiceInputs": {
"input1": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService1",
"type": "LinkedServiceReference"
},
"FilePath":"amltest/input/in1.csv"
},
"input2": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService1",
"type": "LinkedServiceReference"
},
"FilePath":"amltest/input/in2.csv"
}
},
"webServiceOutputs": {
"outputName1": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService2",
"type": "LinkedServiceReference"
},
"FilePath":"amltest2/output/out1.csv"
},
"outputName2": {
"LinkedServiceName":{
"referenceName": "AzureStorageLinkedService2",
"type": "LinkedServiceReference"
},
"FilePath":"amltest2/output/out2.csv"
}
}
}
}
Scenario 2: Esperimenti di uso dei moduli Reader e Writer per fare riferimento ai dati in diversi archivi
Un altro scenario comune durante la creazione di esperimenti di studio di ML (versione classica) è quello relativo all'uso dei moduli Import Data e Output Data. Il modulo Import Data consente di caricare i dati in un esperimento, mentre il modulo Output Data consente di salvare i dati derivanti dagli esperimenti. Per informazioni dettagliate sui moduli Import Data e Output Data, vedere gli argomenti Import Data e Output Data in MSDN Library.
Quando si usano i moduli Import Data e Output Data, è consigliabile usare un parametro del servizio Web per ogni proprietà di tali moduli. Questi parametri Web consentono di configurare i valori durante il runtime. Ad esempio, è possibile creare un esperimento con un modulo Import Data che usa un database SQL di Azure: XXX.database.windows.net. Dopo aver distribuito il servizio Web, si intende consentire ai consumer del servizio Web di specificare un altro server SQL logico denominato YYY.database.windows.net. È possibile usare un parametro del servizio Web per consentire la configurazione di questo valore.
Nota
L'input e l'output del servizio Web sono diversi dai parametri del servizio Web. Nel primo scenario è stato illustrato come è possibile specificare un input e un output per un servizio Web di studio di ML (versione classica). In questo scenario si passano i parametri per un servizio Web corrispondenti alle proprietà dei moduli Import Data e Output Data.
Viene preso in esame uno scenario relativo all'uso dei parametri del servizio Web. È stato distribuito un servizio Web di studio di ML (versione classica) che usa un modulo lettore per leggere i dati da una delle origini dati supportate da studio di ML (versione classica), ad esempio il database SQL di Azure. Dopo l'esecuzione batch, i risultati vengono scritti usando un modulo Writer (database SQL di Azure). Negli esperimenti non sono definiti input e output del servizio Web. In questo caso, è consigliabile configurare i parametri del servizio Web rilevanti per i moduli Reader e Writer. Ciò consente la configurazione dei moduli Reader e Writer quando si usa l'attività AzureMLBatchExecution. Specificare i parametri del servizio Web nella sezione globalParameters del codice JSON dell'attività come indicato di seguito.
"typeProperties": {
"globalParameters": {
"Database server name": "<myserver>.database.windows.net",
"Database name": "<database>",
"Server user account name": "<user name>",
"Server user account password": "<password>"
}
}
Nota
I parametri del servizio Web applicano la distinzione tra maiuscole e minuscole. È quindi necessario assicurarsi che i nomi specificati nel file JSON dell'attività corrispondano ai nomi esposti dal servizio Web.
Al termine della ripetizione del training, aggiornare il servizio Web di assegnazione dei punteggi, ovvero l'esperimento predittivo esposto come servizio Web, con il modello appena sottoposto a training usando l'Attività della risorsa di aggiornamento di studio di ML (versione classica). Per informazioni dettagliate, vedere l'articolo Updating models using Update Resource Activity (Aggiornamento dei modelli con Attività della risorsa di aggiornamento).
Contenuto correlato
Vedere gli articoli seguenti, che illustrano altre modalità di trasformazione dei dati: