Elaborare i dati eseguendo script U-SQL in Azure Data Lake Analytics con Azure Data Factory e Synapse Analytics
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Una pipeline in un'area di lavoro di Azure Data Factory o Synapse Analytics elabora i dati nei servizi di archiviazione collegati usando servizi di calcolo collegati. Contiene una sequenza di attività in cui ogni attività esegue una specifica operazione di elaborazione. Questo articolo descrive l'attività U-SQL di Data Lake Analytics che esegue uno script U-SQL in un servizio di calcolo collegato di Azure Data Lake Analytics.
Creare un account di Azure Data Lake Analytics prima di creare una pipeline con un'attività U-SQL di Data Lake Analytics. Per altre informazioni su Azure Data Lake Analytics, vedere Introduzione ad Azure Data Lake con l'SDK .NET.
Aggiungere un'attività U-SQL per Azure Data Lake Analytics a una pipeline con l'interfaccia utente
Per usare un'attività U-SQL per Azure Data Lake Analytics in una pipeline, seguire questa procedura:
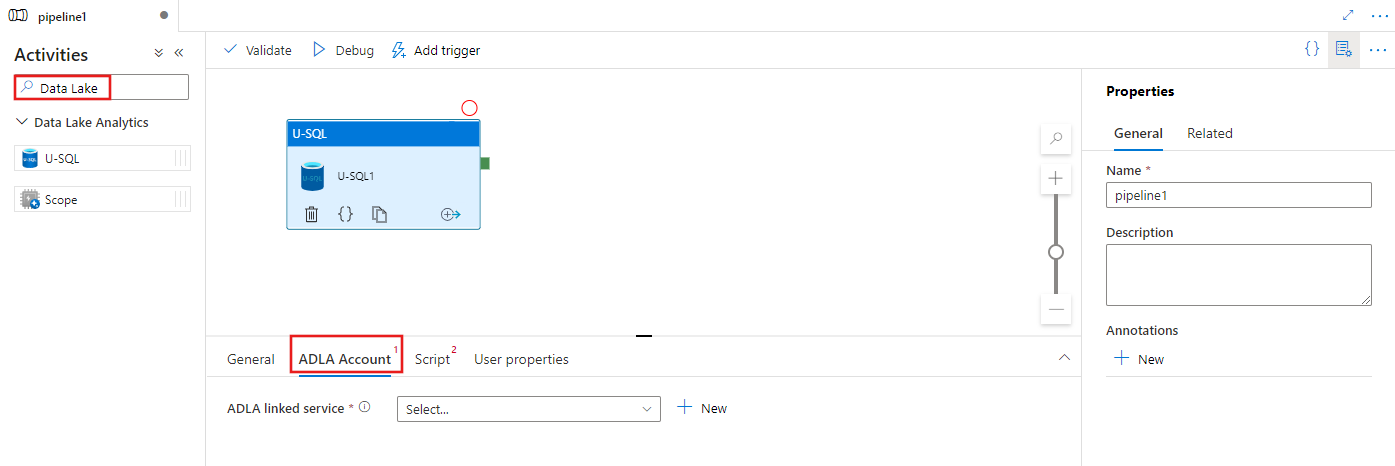
Cercare Data Lake nel riquadro Attività pipeline e trascinare un'attività U-SQL nell'area di disegno della pipeline.
Selezionare la nuova attività U-SQL nell'area di disegno, se non è già selezionata.
Selezionare la scheda Account ADLA per selezionare o creare un nuovo servizio collegato di Azure Data Lake Analytics che verrà usato per eseguire l'attività U-SQL.
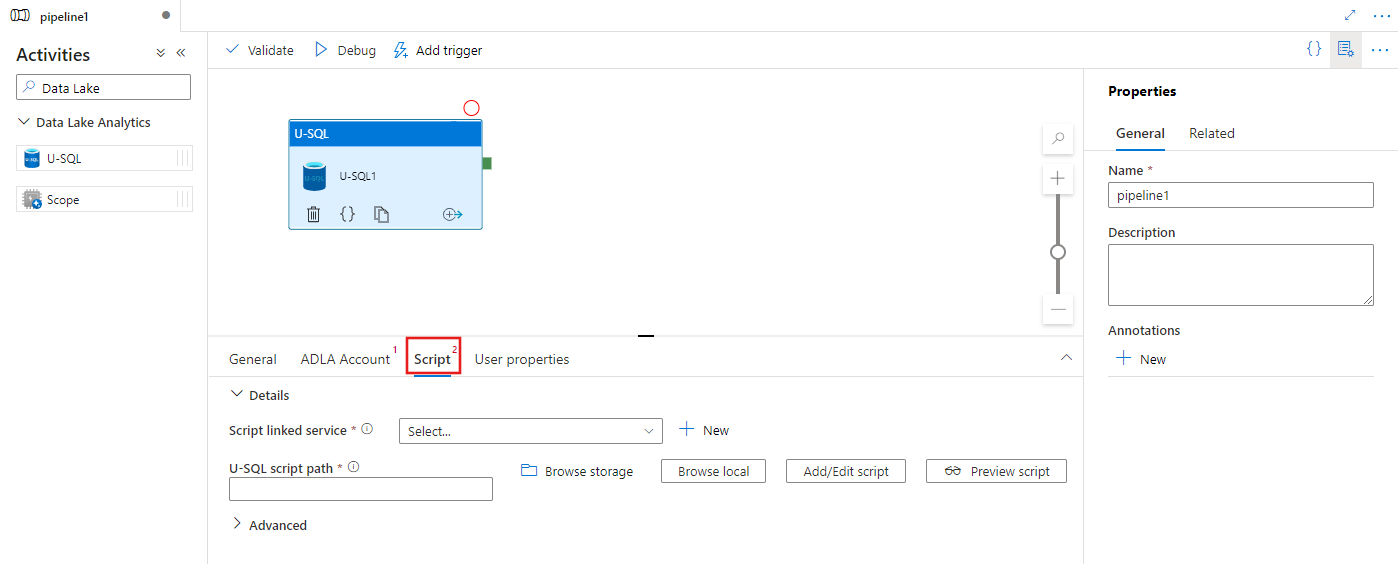
Selezionare la scheda Script per selezionare o creare un nuovo servizio collegato di archiviazione e un percorso all'interno del percorso di archiviazione, che ospiterà lo script.
Servizio collegato di Azure Data Lake Analytics
Si crea un servizio collegato di Azure Data Lake Analytics per collegare un servizio di calcolo di Azure Data Lake Analytics a un'area di lavoro di Azure Data Factory o Synapse Analytics. L'attività U-SQL di Data Lake Analytics nella pipeline fa riferimento a questo servizio collegato.
La tabella seguente fornisce le descrizioni delle proprietà generiche usate nella definizione JSON.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su AzureDataLakeAnalytics. | Sì |
| accountName | Nome dell'account di Azure Data Lake Analytics. | Sì |
| dataLakeAnalyticsUri | URI di Azure Data Lake Analytics. | No |
| subscriptionId | ID sottoscrizione di Azure | No |
| resourceGroupName | Nome del gruppo di risorse di Azure | No |
Autenticazione dell'entità servizio
Per connettersi al servizio Azure Data Lake Analytics, il servizio collegato di Azure Data Lake Analytics richiede l'autenticazione di un'entità servizio. Per usare l'autenticazione dell'entità servizio, registrare un'entità applicazione in Microsoft Entra ID e concedergli l'accesso sia a Data Lake Analytics che a Data Lake Store usato. Per la procedura dettaglia, vedere Autenticazione da servizio a servizio. Prendere nota dei valori seguenti che si usano per definire il servizio collegato:
- ID applicazione
- Chiave applicazione
- ID tenant
Concedere l'autorizzazione dell'entità servizio ad Azure Data Lake Analytics usando l'Aggiunta guidata utente.
Usare l'autenticazione basata su entità servizio specificando le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| servicePrincipalId | Specificare l'ID client dell'applicazione. | Sì |
| servicePrincipalKey | Specificare la chiave dell'applicazione. | Sì |
| tenant | Specificare le informazioni sul tenant (nome di dominio o ID tenant) in cui si trova l'applicazione. È possibile recuperarlo passando il cursore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
Esempio: autenticazione basata su entità servizio
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Per altre informazioni sul servizio collegato, vedere Servizi collegati di calcolo.
Attività U-SQL di Data Lake Analytics
Il frammento JSON seguente definisce una pipeline con un'attività U-SQL di Data Lake Analytics. La definizione dell'attività contiene un riferimento al servizio collegato di Azure Data Lake Analytics creato in precedenza. Per eseguire uno script U-SQL di Data Lake Analytics, il servizio invia lo script specificato a Data Lake Analytics e gli input e gli output necessari vengono definiti nello script per Data Lake Analytics per recuperare e restituire l'output.
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
Nella tabella seguente vengono descritti i nomi e le descrizioni delle proprietà specifiche per questa attività.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'attività nella pipeline | Sì |
| description | Testo che descrive l'attività. | No |
| type | Per l'attività U-SQL di Data Lake Analytics, il tipo corrisponde a DataLakeAnalyticsU-SQL. | Sì |
| linkedServiceName | Servizio collegato ad Azure Data Lake Analytics. Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| scriptPath | Percorso della cartella contenente lo script U-SQL. Il nome del file distingue tra maiuscole e minuscole. | Sì |
| scriptLinkedService | Servizio collegato che collega Azure Data Lake Store o Archiviazione di Azure che contiene lo script | Sì |
| degreeOfParallelism | Il numero massimo di nodi usati contemporaneamente per eseguire il processo. | No |
| priority | Determina quali processi rispetto a tutti gli altri disponibili nella coda devono essere selezionati per essere eseguiti per primi. Più è basso il numero, maggiore sarà la priorità. | No |
| parameters | Parametri da passare allo script U-SQL. | No |
| runtimeVersion | Versione di runtime del motore di U-SQL da usare. | No |
| compilationMode | Modalità di compilazione di U-SQL. Deve corrispondere a uno dei valori seguenti: Semantic: consente di eseguire solo controlli semantici e i controlli di integrità necessari. Full: consente di eseguire una compilazione completa, inclusi il controllo della sintassi, l'ottimizzazione, la generazione di codice e così via. SingleBox: consente di eseguire una compilazione completa usando SingleBox come impostazione di TargetType. Se per questa proprietà non si specifica alcun valore, il server determina la modalità di compilazione ottimale. |
No |
Per la definizione dello script, vedere SearchLogProcessing.txt.
Script U-SQL di esempio
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
Nell'esempio di script precedente, l'input e l'output dello script vengono definiti nei parametri @in e @out . I valori per i parametri @in e @out nello script U-SQL vengono passati dinamicamente dal servizio usando la sezione 'parameters'.
È possibile specificare anche altre proprietà come degreeOfParallelism e priorità nella definizione della pipeline per i processi in esecuzione sul servizio Azure Data Lake Analytics.
Parametri dinamici
Nell'esempio di definizione di pipeline i parametri in e out vengono assegnati con valori hardcoded.
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
È anche possibile usare parametri dinamici. Ad esempio:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
In questo caso, i file di input vengono prelevati dalla cartella /datalake/input e i file di output vengono generati nella cartella /datalake/output. I nomi dei file sono dinamici in base all'ora di inizio della finestra passata quando viene attivata la pipeline.
Contenuto correlato
Vedere gli articoli seguenti, che illustrano altre modalità di trasformazione dei dati: