Gestire i criteri di indicizzazione in Azure Cosmos DB
In Azure Cosmos DB, i dati vengono indicizzati seguendo i criteri di indicizzazione definiti per ogni contenitore. I criteri di indicizzazione predefiniti per i contenitori appena creati applicano indici di intervallo per qualsiasi stringa o numero. È possibile disabilitare questo criterio con i criteri di indicizzazione personalizzati.
Nota
Il metodo di aggiornamento dei criteri di indicizzazione descritto in questo articolo si applica solo ad Azure Cosmos DB per NoSQL. Informazioni sull'indicizzazione in Azure Cosmos DB per MongoDB e sull'indicizzazione secondaria in Azure Cosmos DB per Apache Cassandra.
Esempi di criteri di indicizzazione
Ecco alcuni esempi di criteri di indicizzazione nel loro formatoJSON. Vengono mostrati nel portale di Azure in formato JSON. Gli stessi parametri possono essere impostati tramite l'interfaccia della riga di comando di Azure o qualsiasi SDK.
Criteri di esclusione per escludere in modo selettivo alcuni percorsi delle proprietà
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/path/to/single/excluded/property/?"
},
{
"path": "/path/to/root/of/multiple/excluded/properties/*"
}
]
}
Criteri di inclusione per includere in modo selettivo alcuni percorsi delle proprietà
{
"indexingMode": "consistent",
"includedPaths": [
{
"path": "/path/to/included/property/?"
},
{
"path": "/path/to/root/of/multiple/included/properties/*"
}
],
"excludedPaths": [
{
"path": "/*"
}
]
}
Nota
In genere si consiglia di usare un criterio di indicizzazione di rifiuto esplicito. Azure Cosmos DB indicizza in modo proattivo qualsiasi nuova proprietà che potrebbe essere aggiunta al modello di dati.
Usare un indice spaziale solo in un percorso di proprietà specifico
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
}
],
"spatialIndexes": [
{
"path": "/path/to/geojson/property/?",
"types": [
"Point",
"Polygon",
"MultiPolygon",
"LineString"
]
}
]
}
Esempi di criteri di indicizzazione vettoriale
Oltre a includere o escludere i percorsi per le singole proprietà, è anche possibile specificare un indice vettoriale. In generale, gli indici vettoriali vanno specificati ogni volta che si usa la funzione di sistema VectorDistance per misurare la somiglianza tra un vettore di query e una proprietà vettoriale.
Nota
Prima di procedere, è necessario abilitare l'indicizzazione e la ricerca dei vettori NoSQL di Azure Cosmos DB.
Importante
I criteri di indicizzazione vettoriale devono trovarsi nel stesso percorso definito nei criteri vettoriali del contenitore. Altre informazioni sui criteri vettoriali dei contenitori.
{
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*"
}
],
"excludedPaths": [
{
"path": "/_etag/?"
},
{
"path": "/vector/*"
}
],
"vectorIndexes": [
{
"path": "/vector",
"type": "quantizedFlat"
}
]
}
Importante
Percorso vettoriale aggiunto alla sezione "excludedPaths" dei criteri di indicizzazione per garantire prestazioni ottimizzate per l'inserimento. Se non si aggiunge il percorso vettoriale a "excludedPaths", l’addebito e la latenza delle RU risulteranno più elevati.
Importante
Attualmente, i criteri vettoriali e gli indici vettoriali non sono modificabili dopo la creazione. Per apportare modifiche, creare una nuova raccolta.
È possibile definire i tipi seguenti di criteri di indice vettoriale:
| Tipo | Descrizione | Dimensioni massime |
|---|---|---|
flat |
Archivia i vettori nello stesso indice di altre proprietà indicizzate. | 505 |
quantizedFlat |
Quantizza (comprime) i vettori prima di archiviarli nell'indice. Ciò può migliorare la latenza e la velocità effettiva a scapito dell'accuratezza. | 4096 |
diskANN |
Crea un indice basato su DiskANN per una ricerca approssimativa veloce ed efficiente. | 4096 |
I tipi di indice flat e quantizedFlat usano l'indice di Azure Cosmos DB per archiviare e leggere ogni vettore durante l'esecuzione di una ricerca vettoriale. Le ricerche vettoriali con un indice flat sono ricerche di forza bruta e offrono una precisione del 100%. Tuttavia, esiste una limitazione delle dimensioni 505 per i vettori in un indice flat.
L'indice quantizedFlat archivia i vettori quantizzati o compressi nell'indice. Anche le ricerche vettoriali con indice quantizedFlat sono ricerche di forza bruta, ma la loro accuratezza potrebbe essere leggermente inferiore al 100% perché i vettori vengono quantizzati prima dell'aggiunta all'indice. Tuttavia, le ricerche vettoriali con quantized flat devono avere una latenza inferiore, una velocità effettiva più elevata e un costo UR inferiore rispetto alle ricerche vettoriali su un indice flat. Questa è un'opzione valida per gli scenari in cui si usano filtri di query per restringere la ricerca vettoriale a un set relativamente ridotto di vettori.
L'indice diskANN è un indice separato definito in modo specifico per i vettori che usano DiskANN, una suite di algoritmi di indicizzazione vettoriale con prestazioni elevate sviluppati da Microsoft Research. Gli indici DiskANN possono offrire alcune delle query con latenza più bassa, numero di query al secondo più elevato e costo UR più basso, con un'accuratezza elevata. Tuttavia, poiché DiskANN è un indice per la ricerca approssimativa del vicino più prossimo (ANN), l'accuratezza può essere inferiore a quantizedFlat o flat.
Gli diskANN indici e quantizedFlat possono accettare parametri di compilazione degli indici facoltativi che possono essere usati per ottimizzare il compromesso tra accuratezza e latenza che si applica a ogni indice di vettore Nearest Neighbors approssimato.
quantizationByteSize: imposta le dimensioni (in byte) per la quantizzazione del prodotto. Min=1, Default=dynamic (system decide), Max=512. L'impostazione di questa dimensione più grande può comportare ricerche di vettori di accuratezza più elevate a scapito di un costo più elevato delle UR e di una latenza più elevata. Questo vale sia per iquantizedFlatDiskANNtipi di indice che per i tipi di indice.indexingSearchListSize: imposta il numero di vettori da cercare durante la costruzione della compilazione dell'indice. Min=10, Default=100, Max=500. L'impostazione di questo valore maggiore può comportare ricerche di vettori di accuratezza più elevati a scapito di tempi di compilazione più lunghi dell'indice e latenze di inserimento di vettori più elevati. Questo vale solo perDiskANNgli indici.
Esempi di criteri di indicizzazione delle tuple
Questo criterio di indicizzazione di esempio definisce un indice di tupla in events.name ed events.category
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{"path":"/*"},
{"path":"/events/[]/{name,category}/?"}
],
"excludedPaths":[],
"compositeIndexes":[]
}
L'indice precedente viene usato per la query seguente.
SELECT *
FROM root r
WHERE
EXISTS (SELECT VALUE 1 FROM ev IN r.events
WHERE ev.name = ‘M&M’ AND ev.category = ‘Candy’)
Esempi di criteri di indicizzazione composti
Oltre a includere o escludere i percorsi per le singole proprietà, è anche possibile specificare un indice composto. Per eseguire una query con una ORDER BYclausola per più proprietà, è necessario un indice composito per quelle proprietà. Se la query comprende i filtri e la disposizione in più proprietà, potrebbe essere necessario più di un indice composito.
Gli indici compositi hanno anche un vantaggio per le prestazioni delle query che dispongono di più filtri o di un filtro e di una clausola ORDER BY.
Nota
I percorsi compositi hanno un /? implicito, dato che viene indicizzato solo il valore scalare in quel percorso. Il /* carattere jolly non è supportato nei percorsi compositi. Si consiglia di non specificare /? o /* in un percorso composito. I percorsi compositi fanno anche distinzione tra maiuscole e minuscole.
Indice composto definito per (nome asc, età desc):
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
L'indice composito riguardo il nome e l'età è necessario per le query seguenti:
Query 1:
SELECT *
FROM c
ORDER BY c.name ASC, c.age DESC
Query 2:
SELECT *
FROM c
ORDER BY c.name DESC, c.age ASC
Questo indice composito offre vantaggi alle query seguenti e ottimizza i filtri:
Query n. 3:
SELECT *
FROM c
WHERE c.name = "Tim"
ORDER BY c.name DESC, c.age ASC
Query n. 4:
SELECT *
FROM c
WHERE c.name = "Tim" AND c.age > 18
Indice composito definito secondo (nome ASC, età ASC) e (nome ASC, età DESC)
È possibile definire più indici compositi nello stesso criterio di indicizzazione.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"ascending"
}
],
[
{
"path":"/name",
"order":"ascending"
},
{
"path":"/age",
"order":"descending"
}
]
]
}
Indice composito definito secondo (nome ASC, età ASC)
Specificare l'ordine è facoltativo. Se non specificato, l'ordine è crescente.
{
"automatic":true,
"indexingMode":"Consistent",
"includedPaths":[
{
"path":"/*"
}
],
"excludedPaths":[],
"compositeIndexes":[
[
{
"path":"/name"
},
{
"path":"/age"
}
]
]
}
Escludere tutti i percorsi delle proprietà mantenendo però l'indicizzazione attiva
È possibile usare questo criterio in cui la funzionalità TTL (Time-to-Live) è attiva, ma non sono necessari altri indici per usare Azure Cosmos DB come archivio chiave-valore puro.
{
"indexingMode": "consistent",
"includedPaths": [],
"excludedPaths": [{
"path": "/*"
}]
}
Nessuna indicizzazione
Questo criterio disattiva l'indicizzazione. Se indexingMode è impostato su none, non è possibile impostare una TTL sul contenitore.
{
"indexingMode": "none"
}
Aggiornare i criteri di indicizzazione
In Azure Cosmos DB i criteri di indicizzazione possono essere aggiornati usando uno dei metodi seguenti:
- Dal portale di Azure
- Con l'interfaccia della riga di comando di Azure
- Utilizzo di PowerShell
- usando uno degli SDK
Un aggiornamento dei criteri di indicizzazione attiva una trasformazione dell'indice. Lo stato di avanzamento della trasformazione può essere monitorato anche dagli SDK.
Nota
Quando si aggiornano i criteri di indicizzazione, le scritture in Azure Cosmos DB non vengono interrotte. Altre informazioni sulle trasformazioni di indicizzazione.
Importante
La rimozione di un indice ha effetto immediato, mentre l'aggiunta di un nuovo indice richiede del tempo perché richiede una trasformazione di indicizzazione. Quando si sostituisce un indice con un altro (ad esempio, sostituendo un singolo indice di proprietà con un indice composito), assicurarsi di aggiungere prima il nuovo indice e quindi attendere che la trasformazione dell'indice sia completa prima di rimuovere l'indice precedente dai criteri di indicizzazione. In caso contrario, ciò influirà negativamente sulla possibilità di eseguire una query sull'indice precedente e potrebbe interrompere eventuali carichi di lavoro attivi che fanno riferimento all'indice precedente.
Usare il portale di Azure
I contenitori di Azure Cosmos DB archiviano i criteri di indicizzazione come documento JSON che il portale di Azure consente di modificare direttamente.
Accedere al portale di Azure.
Creare un nuovo account Azure Cosmos DB o selezionare un account esistente.
Aprire il riquadro Esplora dati e selezionare il contenitore da usare.
Selezionare Dimensioni e impostazioni.
Modificare il documento JSON dei criteri di indicizzazione, come mostrato in questi esempi.
Al termine, seleziona Salva.
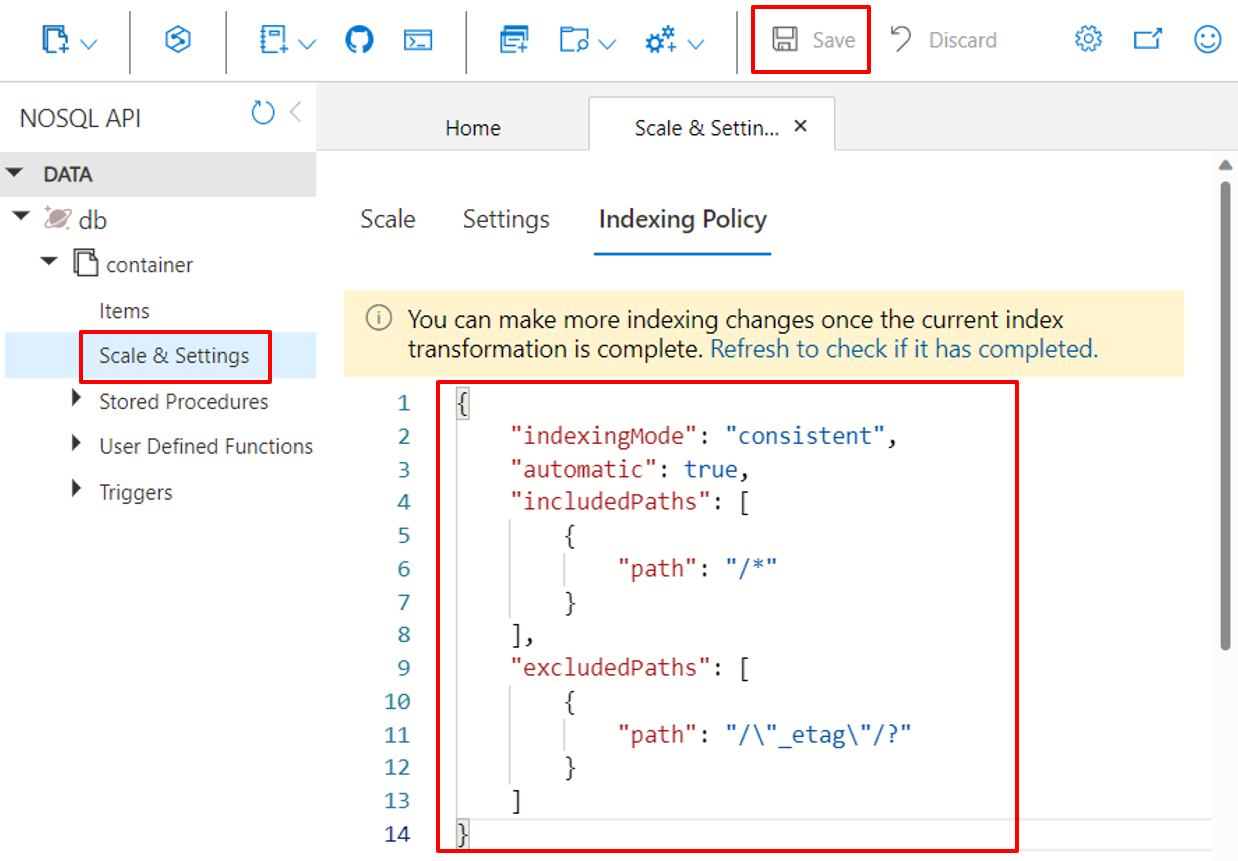
Usare l'interfaccia della riga di comando di Azure
Per creare un contenitore con criteri di indicizzazione personalizzati, vedere Creare un contenitore con criteri di indice personalizzati usando l'interfaccia della riga di comando.
Utilizzare PowerShell
Per creare un contenitore con criteri di indicizzazione personalizzati, vedere Creare un contenitore con criteri di indice personalizzati usando PowerShell.
Usare .NET SDK
L'oggetto ContainerProperties del .NET SDK v3 presenta una proprietà IndexingPolicy che consente di modificare il IndexingMode e aggiungere o rimuovere IncludedPaths e ExcludedPaths. Per altre informazioni, vedere Avvio rapido: Libreria client di Azure Cosmos DB per NoSQL per .NET.
// Retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync();
// Set the indexing mode to consistent
containerResponse.Resource.IndexingPolicy.IndexingMode = IndexingMode.Consistent;
// Add an included path
containerResponse.Resource.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
// Add an excluded path
containerResponse.Resource.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/name/*" });
// Add a spatial index
SpatialPath spatialPath = new SpatialPath
{
Path = "/locations/*"
};
spatialPath.SpatialTypes.Add(SpatialType.Point);
containerResponse.Resource.IndexingPolicy.SpatialIndexes.Add(spatialPath);
// Add a composite index
containerResponse.Resource.IndexingPolicy.CompositeIndexes.Add(new Collection<CompositePath> { new CompositePath() { Path = "/name", Order = CompositePathSortOrder.Ascending }, new CompositePath() { Path = "/age", Order = CompositePathSortOrder.Descending } });
// Update container with changes
await client.GetContainer("database", "container").ReplaceContainerAsync(containerResponse.Resource);
Per monitorare l'avanzamento della trasformazione dell'indice, passare un oggetto RequestOptions che consente di impostare la proprietà PopulateQuotaInfo su true. Recuperare il valore x-ms-documentdb-collection-index-transformation-progressdall'intestazione della risposta.
// retrieve the container's details
ContainerResponse containerResponse = await client.GetContainer("database", "container").ReadContainerAsync(new ContainerRequestOptions { PopulateQuotaInfo = true });
// retrieve the index transformation progress from the result
long indexTransformationProgress = long.Parse(containerResponse.Headers["x-ms-documentdb-collection-index-transformation-progress"]);
L'API Fluent SDK V3 consente di scrivere questa definizione in modo conciso ed efficiente quando si definiscono criteri di indicizzazione personalizzati durante la creazione di un nuovo contenitore:
await client.GetDatabase("database").DefineContainer(name: "container", partitionKeyPath: "/myPartitionKey")
.WithIndexingPolicy()
.WithIncludedPaths()
.Path("/*")
.Attach()
.WithExcludedPaths()
.Path("/name/*")
.Attach()
.WithSpatialIndex()
.Path("/locations/*", SpatialType.Point)
.Attach()
.WithCompositeIndex()
.Path("/name", CompositePathSortOrder.Ascending)
.Path("/age", CompositePathSortOrder.Descending)
.Attach()
.Attach()
.CreateIfNotExistsAsync();
Usare Java SDK
L'oggetto DocumentCollection Java SDK presenta i metodi getIndexingPolicy() e setIndexingPolicy(). L'oggetto IndexingPolicy che essi manipolano consente di modificare la modalità di indicizzazione e di aggiungere o rimuovere percorsi inclusi ed esclusi. Per altre informazioni, vedere Avvio rapido: Creare un'app Java per gestire i dati di Azure Cosmos DB per NoSQL.
// Retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), null);
containerResponse.subscribe(result -> {
DocumentCollection container = result.getResource();
IndexingPolicy indexingPolicy = container.getIndexingPolicy();
// Set the indexing mode to consistent
indexingPolicy.setIndexingMode(IndexingMode.Consistent);
// Add an included path
Collection<IncludedPath> includedPaths = new ArrayList<>();
IncludedPath includedPath = new IncludedPath();
includedPath.setPath("/*");
includedPaths.add(includedPath);
indexingPolicy.setIncludedPaths(includedPaths);
// Add an excluded path
Collection<ExcludedPath> excludedPaths = new ArrayList<>();
ExcludedPath excludedPath = new ExcludedPath();
excludedPath.setPath("/name/*");
excludedPaths.add(excludedPath);
indexingPolicy.setExcludedPaths(excludedPaths);
// Add a spatial index
Collection<SpatialSpec> spatialIndexes = new ArrayList<SpatialSpec>();
Collection<SpatialType> collectionOfSpatialTypes = new ArrayList<SpatialType>();
SpatialSpec spec = new SpatialSpec();
spec.setPath("/locations/*");
collectionOfSpatialTypes.add(SpatialType.Point);
spec.setSpatialTypes(collectionOfSpatialTypes);
spatialIndexes.add(spec);
indexingPolicy.setSpatialIndexes(spatialIndexes);
// Add a composite index
Collection<ArrayList<CompositePath>> compositeIndexes = new ArrayList<>();
ArrayList<CompositePath> compositePaths = new ArrayList<>();
CompositePath nameCompositePath = new CompositePath();
nameCompositePath.setPath("/name");
nameCompositePath.setOrder(CompositePathSortOrder.Ascending);
CompositePath ageCompositePath = new CompositePath();
ageCompositePath.setPath("/age");
ageCompositePath.setOrder(CompositePathSortOrder.Descending);
compositePaths.add(ageCompositePath);
compositePaths.add(nameCompositePath);
compositeIndexes.add(compositePaths);
indexingPolicy.setCompositeIndexes(compositeIndexes);
// Update the container with changes
client.replaceCollection(container, null);
});
Per tenere traccia dello stato di avanzamento della trasformazione dell'indice in un contenitore, passare un RequestOptions oggetto che richiede il popolamento delle informazioni sulla quota. Recuperare il valore x-ms-documentdb-collection-index-transformation-progressdall'intestazione della risposta.
// set the RequestOptions object
RequestOptions requestOptions = new RequestOptions();
requestOptions.setPopulateQuotaInfo(true);
// retrieve the container's details
Observable<ResourceResponse<DocumentCollection>> containerResponse = client.readCollection(String.format("/dbs/%s/colls/%s", "database", "container"), requestOptions);
containerResponse.subscribe(result -> {
// retrieve the index transformation progress from the response headers
String indexTransformationProgress = result.getResponseHeaders().get("x-ms-documentdb-collection-index-transformation-progress");
});
Usare Node.js SDK
L'interfaccia ContainerDefinition di Node.js SDK presenta una proprietà indexingPolicy che consente di modificare il indexingMode e aggiungere o rimuovere includedPaths e excludedPaths. Per altre informazioni, vedere Avvio rapido - Libreria client di Azure Cosmos DB per NoSQL per Node.js.
Recuperare i dettagli del contenitore:
const containerResponse = await client.database('database').container('container').read();
Impostare la modalità di indicizzazione su costante:
containerResponse.body.indexingPolicy.indexingMode = "consistent";
Aggiungere un percorso incluso, compreso un indice spaziale:
containerResponse.body.indexingPolicy.includedPaths.push({
includedPaths: [
{
path: "/age/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.String
},
{
kind: cosmos.DocumentBase.IndexKind.Range,
dataType: cosmos.DocumentBase.DataType.Number
}
]
},
{
path: "/locations/*",
indexes: [
{
kind: cosmos.DocumentBase.IndexKind.Spatial,
dataType: cosmos.DocumentBase.DataType.Point
}
]
}
]
});
Aggiungere il percorso escluso:
containerResponse.body.indexingPolicy.excludedPaths.push({ path: '/name/*' });
Aggiornare il contenitore con le modifiche:
const replaceResponse = await client.database('database').container('container').replace(containerResponse.body);
Per monitorare lo stato di avanzamento della trasformazione dell'indice in un contenitore, passare un oggetto RequestOptions che imposta la proprietà populateQuotaInfo su true. Recuperare il valore x-ms-documentdb-collection-index-transformation-progressdall'intestazione della risposta.
// retrieve the container's details
const containerResponse = await client.database('database').container('container').read({
populateQuotaInfo: true
});
// retrieve the index transformation progress from the response headers
const indexTransformationProgress = replaceResponse.headers['x-ms-documentdb-collection-index-transformation-progress'];
Aggiungere un indice composito:
console.log("create container with composite indexes");
const containerDefWithCompositeIndexes = {
id: "containerWithCompositeIndexingPolicy",
indexingPolicy: {
automatic: true,
indexingMode: IndexingMode.consistent,
includedPaths: [
{
path: "/*",
},
],
excludedPaths: [
{
path: '/"systemMetadata"/*',
},
],
compositeIndexes: [
[
{ path: "/field", order: "ascending" },
{ path: "/key", order: "ascending" },
],
],
},
};
const containerWithCompositeIndexes = (
await database.containers.create(containerDefWithCompositeIndexes)
).container;
Usare Python SDK
Quando si usa Python SDK V3, la configurazione del contenitore viene gestita come un dizionario. Da questo dizionario è possibile accedere ai criteri di indicizzazione e a tutti i relativi attributi. Per altre informazioni, vedere Avvio rapido: Libreria client di Azure Cosmos DB per NoSQL per Python.
Recuperare i dettagli del contenitore:
containerPath = 'dbs/database/colls/collection'
container = client.ReadContainer(containerPath)
Impostare la modalità di indicizzazione su costante:
container['indexingPolicy']['indexingMode'] = 'consistent'
Definire un criterio di indicizzazione con un percorso incluso e un indice spaziale:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"spatialIndexes":[
{"path":"/location/*","types":["Point"]}
],
"includedPaths":[{"path":"/age/*","indexes":[]}],
"excludedPaths":[{"path":"/*"}]
}
Definire un criterio di indicizzazione con un percorso escluso:
container["indexingPolicy"] = {
"indexingMode":"consistent",
"includedPaths":[{"path":"/*","indexes":[]}],
"excludedPaths":[{"path":"/name/*"}]
}
Aggiungere un indice composito:
container['indexingPolicy']['compositeIndexes'] = [
[
{
"path": "/name",
"order": "ascending"
},
{
"path": "/age",
"order": "descending"
}
]
]
Aggiornare il contenitore con le modifiche:
response = client.ReplaceContainer(containerPath, container)