Panoramica dell'indicizzazione in Azure Cosmos DB
SI APPLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabella
Tabella
Azure Cosmos DB è un database senza schema che consente di eseguire l'iterazione sull'applicazione senza dover gestire schemi o indici. Per impostazione predefinita, Azure Cosmos DB indicizza automaticamente ogni proprietà per tutti gli elementi nel contenitore senza dover definire schemi né configurare indici secondari.
Lo scopo di questo articolo è spiegare come Azure Cosmos DB indicizza i dati e come usa gli indici per migliorare le prestazioni delle query. Si consiglia di esaminare questa sezione prima di vedere come personalizzare i criteri di indicizzazione.
Da elementi ad alberi
Ogni volta che un elemento viene archiviato in un contenitore, il relativo contenuto viene proiettato come documento JSON e quindi convertito in una rappresentazione ad albero. Questa conversione implica che ogni proprietà di quell’elemento viene rappresentata come un “node” in un albero. Un nodo pseudoradice viene creato come elemento padre per tutte le proprietà di primo livello dell'elemento. I nodi foglia contengono i valori scalari effettivi di un elemento.
Ad esempio, considerare questo elemento:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Questo albero rappresenta l'esempio dell’elemento JSON:
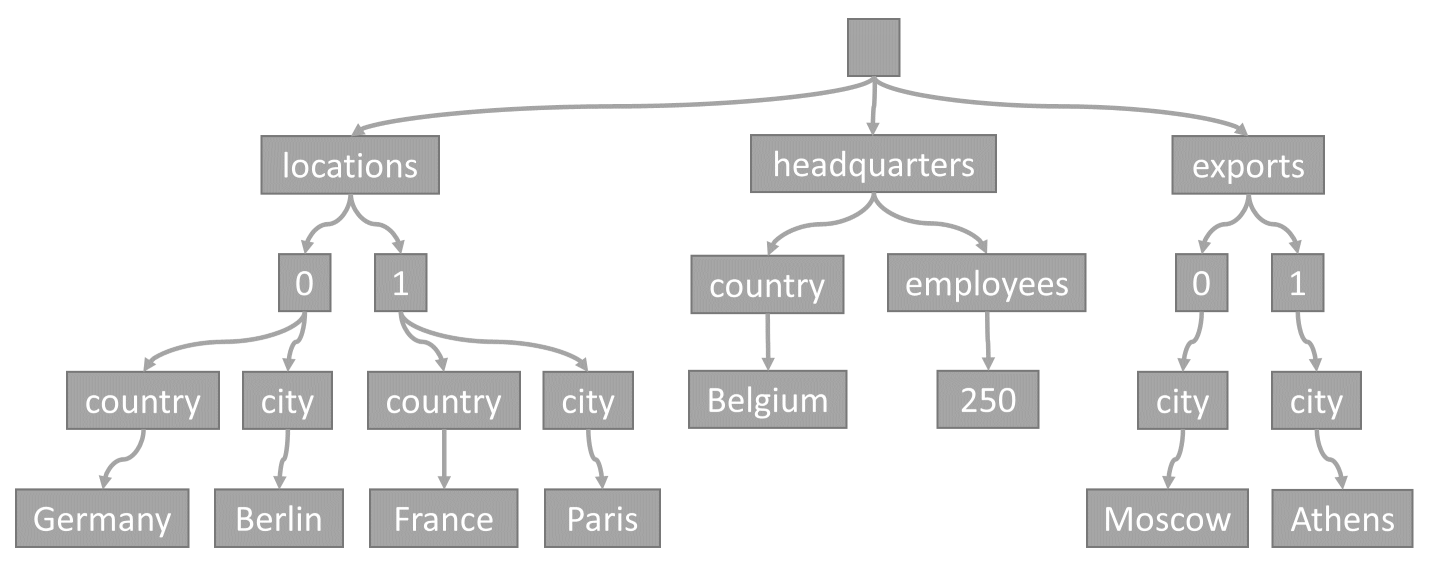
Si noti il modo in cui le matrici vengono codificate nell'albero: ogni voce in una matrice ottiene un nodo intermedio etichettato con l'indice di tale voce all'interno della matrice (0, 1 e così via).
Da alberi a percorsi delle proprietà
Il motivo per cui Azure Cosmos DB trasforma gli elementi in alberi è per consentire al sistema di riferirsi alle proprietà usando i propri percorsi all'interno di questi alberi. Per ottenere il percorso di una proprietà, è possibile eseguire l'attraversamento dell'albero dal nodo radice a tale proprietà e concatenare le etichette di ogni nodo attraversato.
Questi sono i percorsi per ogni proprietà dell'elemento di esempio descritto in precedenza:
/locations/0/country: "Germania"/locations/0/city: "Berlino"/locations/1/country: "Francia"/locations/1/city: "Parigi"/headquarters/country: "Belgio"/headquarters/employees: 250/exports/0/city: "Mosca"/exports/1/city: "Atene"
Azure Cosmos DB indicizza in modo efficace il percorso di ogni proprietà e il valore corrispondente quando viene scritto un elemento.
Tipi di indici
Azure Cosmos DB supporta al momento tre tipi di indice. È possibile configurare questi tipi di indice quando si definiscono i criteri di indicizzazione.
Indice di intervallo
Gli indici di Range si basano su una struttura ad albero ordinata. L’indice di Range si usa per:
Query di uguaglianza:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Corrispondenza di uguaglianza su un elemento di matrice
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Query su intervallo:
SELECT * FROM container c WHERE c.property > 'value'Nota
(per
>,<,>=,<=!=)Verifica della presenza di una proprietà:
SELECT * FROM c WHERE IS_DEFINED(c.property)Funzioni di sistema di stringa:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")Query
ORDER BY:SELECT * FROM container c ORDER BY c.propertyQuery
JOIN:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
Gli indici di intervallo possono essere usati in valori scalari (stringa o numero). I criteri di indicizzazione predefiniti per i contenitori appena creati applicano indici di intervallo per qualsiasi stringa o numero. Per informazioni su come configurare gli indici di Range, fare riferimento agli esempi dei criteri di indicizzazione di Range
Nota
Una clausola ORDER BY che ordina in base a una singola proprietà necessita sempre di un indice di intervallo e avrà esito negativo se il percorso a cui fa riferimento non ne ha uno. In modo analogo, una query ORDER BY che ordina in base a più proprietà necessita sempre di un indice composto.
Indice spaziale
Gli indici spaziali consentono query efficienti su oggetti geospaziali , ad esempio punti, linee, poligoni e multipoligoni. Queste query usano le parole chiave ST_DISTANCE, ST_WITHIN, ST_INTERSECTS. Di seguito ci sono alcuni esempi che usano gli indici di tipo spaziale:
Query geospaziale distance:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Query geospaziale within:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Query geospaziale intersect:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
Gli indici spaziali possono essere usati su oggetti GeoJSON con formato corretto. Attualmente sono supportati gli oggetti Point, LineString, Polygon e MultiPolygon. Per informazioni su come configurare gli indici spaziali, fare riferimento agli esempi di criteri di indicizzazione Spaziale
Indici compositi
Gli indici composti aumentano l'efficienza quando esegui operazioni su più campi. L’indice di tipo composto si usa per:
Query
ORDER BYsu più proprietà:SELECT * FROM container c ORDER BY c.property1, c.property2Query con un filtro e
ORDER BY. Queste query possono usare un indice composto se la proprietà di filtro viene aggiunta alla clausolaORDER BY.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Query con un filtro su due o più proprietà in cui almeno una proprietà è un filtro di uguaglianza
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Finché un predicato del filtro usa uno dei tipi di indice, il motore delle query lo valuta prima di analizzare il resto. Se si dispone ad esempio di una query SQL come SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
La query precedente filtra innanzitutto le voci in cui firstName = "Andrew" usando l'indice. Passa quindi tutte le occorrenze firstName = "Andrew" attraverso una pipeline successiva per valutare il predicato di filtro CONTAINS.
È possibile velocizzare le query ed evitare analisi complete dei contenitori quando si usano funzioni che eseguono un'analisi completa come CONTAINS. È possibile aggiungere altri predicati di filtro che usano l'indice per velocizzare queste query. L'ordine delle clausole di filtro non è importante. Il motore delle query individua i predicati più selettivi ed esegue la query di conseguenza.
Per configurare gli indici composti, fare riferimento agli Esempi di criteri di indicizzazione Composti
Indici vettoriali
Gli indici vettoriali aumentano l'efficienza durante l'esecuzione di ricerche vettoriali usando la funzione di sistema VectorDistance. Le ricerche vettoriali avranno una latenza significativamente inferiore, una velocità effettiva più elevata e un consumo minore di UR quando si sfrutta un indice vettoriale.
Per informazioni su come configurare gli indici vettoriali, vedere esempi di criteri di indicizzazione vettoriali
ORDER BYquery di ricerca vettoriali:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Proiezione del punteggio di somiglianza nelle query di ricerca vettoriale:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Filtri di intervallo per il punteggio di somiglianza.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Importante
Attualmente, i criteri vettoriali e gli indici vettoriali non sono modificabili dopo la creazione. Per apportare modifiche, creare una nuova raccolta.
Utilizzo dell'indice
Ci sono cinque modi in cui il motore di query può valutare i filtri di query, che vanno dal più efficiente e meno efficiente:
- Ricerca nell'indice
- Analisi precisa dell'indice
- Analisi estesa dell'indice
- Analisi completa dell'indice
- Analisi completa
Per indicizzare i percorsi delle proprietà, il motore di query usa automaticamente l'indice nel modo più efficiente possibile. Oltre all'indicizzazione di nuovi percorsi di proprietà, non è necessario configurare nulla per ottimizzare il modo in cui le query usano l'indice. L'addebito UR di una query è una combinazione sia dell'addebito delle UR dall'utilizzo dell'indice che dell'addebito delle UR dal caricamento degli elementi.
Ecco una tabella che riassume i diversi modi in cui si usano gli indici in Azure Cosmos DB:
| Tipo di ricerca dell'indice | Descrizione | Esempi comuni | Addebito UR per l'utilizzo dell'indice | Addebiti UR per il caricamento di elementi dall'archivio dei dati transazionali |
|---|---|---|---|---|
| Ricerca nell'indice | Legge solamente i valori indicizzati richiesti e carica solamente gli elementi corrispondenti dall'archivio dati transazionale | Filtri di uguaglianza, IN | Filtro di costante per uguaglianza | Aumenta in base al numero di elementi nei risultati della query |
| Analisi precisa dell'indice | Ricerca binaria di valori indicizzati e carica solo gli elementi corrispondenti dall'archivio dati transazionale | Confronti tra range (>, <, <=, o >=), StartsWith | Confrontabile con la ricerca di indici, aumenta leggermente in base alla cardinalità delle proprietà indicizzate | Aumenta in base al numero di elementi nei risultati della query |
| Analisi estesa dell'indice | Ricerca ottimizzata (ma meno efficiente di una ricerca binaria) di valori indicizzati e carica solo gli elementi corrispondenti dall'archivio dati transazionale | StartsWith (senza distinzione tra maiuscole e minuscole), StringEquals (senza distinzione tra maiuscole e minuscole) | Aumenta leggermente in base alla cardinalità delle proprietà indicizzate | Aumenta in base al numero di elementi nei risultati della query |
| Analisi completa dell'indice | Legge un set distinto di valori indicizzati e caricare solo gli elementi corrispondenti dall'archivio dati transazionale | Contains, EndsWith, RegexMatch, LIKE | Aumenta in modo lineare in base alla cardinalità delle proprietà indicizzate | Aumenta in base al numero di elementi nei risultati della query |
| Analisi completa | Carica tutti gli elementi dall'archivio dati transazionale | Superiore, Inferiore | N/D | Aumenta in base al numero di elementi nel contenitore |
Quando si scrivono le query, usare i predicati di filtro che utilizzano l'indice nel modo più efficiente possibile. Ad esempio, se StartsWith o Contains dovessero andare bene per quello che è necessario fare, scegliere StartsWith dato che esegue un'analisi dell'indice precisa anziché un'analisi completa dell'indice.
Dettagli sull'utilizzo dell'indice
In questa sezione ci sono ulteriori informazioni sul modo in cui le query usano gli indici. Queste informazioni non sono necessarie per usare Azure Cosmos DB, ma sono riportate in dettaglio per gli utenti più curiosi. Si fa riferimento all'elemento di esempio condiviso in precedenza in questo documento:
Elementi esempio:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB usa un indice invertito. L'indice funziona eseguendo il mapping di ogni percorso JSON del set di elementi che contengono quel valore. Il mapping dell'ID dell’elemento viene rappresentato in svariate pagine dell’indice per il container. Di seguito vediamo un diagramma di un esempio di un indice invertito per un container che comprende i due elementi esempio:
| Percorso | Valore | Elenco degli ID dell’elemento |
|---|---|---|
| /locations/0/country | Germania | 1 |
| /locations/0/country | Irlanda | 2 |
| /locations/0/city | Berlino | 1 |
| /locations/0/city | Dublino | 2 |
| /locations/1/country | Francia | 1 |
| /locations/1/city | Parigi | 1 |
| /headquarters/country | Belgio | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
L'indice invertito ha due caratteristiche importanti:
- Per un determinato percorso, i valori vengono ordinati in ordine crescente. Quindi il motore di query può facilmente operare
ORDER BYdall'indice. - Per un determinato percorso, il motore di query può analizzare il set distinto di possibili valori per identificare le pagine dell’indice dove sono presenti dei risultati.
Il motore di query può usare l'indice invertito in quattro modi diversi:
Ricerca nell'indice
Si consideri la query seguente:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
Il predicato di query (filtrando gli elementi in cui qualsiasi posizione ha "Francia" come paese/regione) corrisponde al percorso evidenziato in questo diagramma:
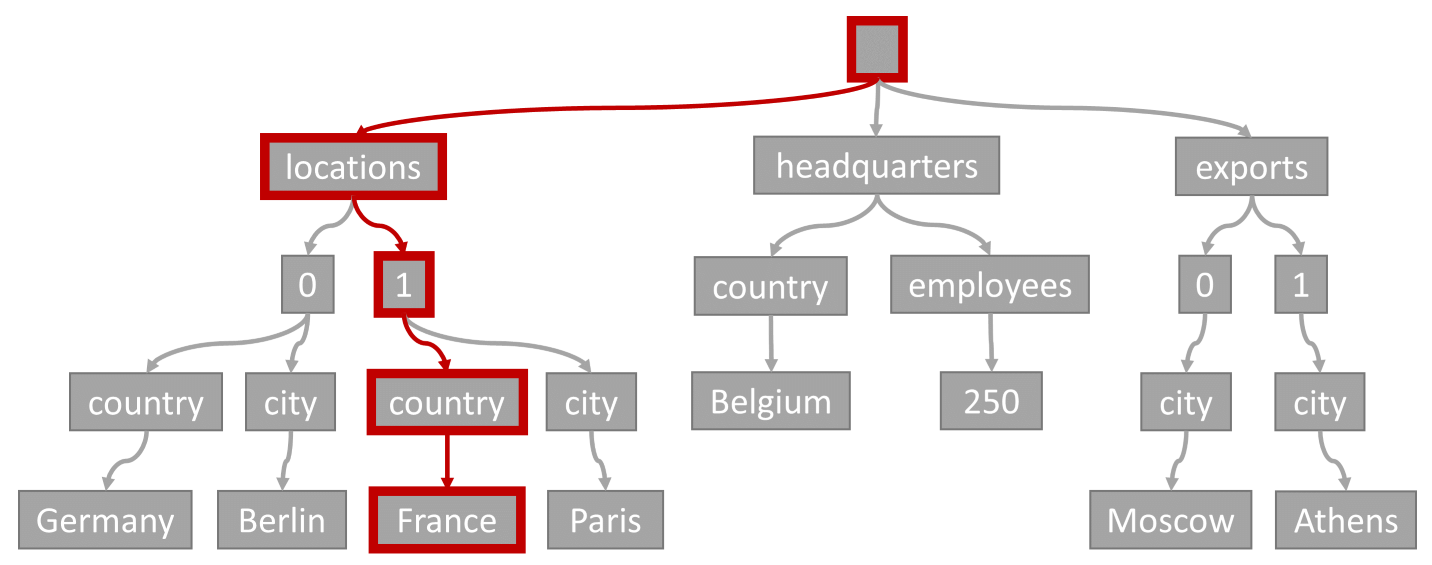
Visto che questa query ha un filtro di uguaglianza, dopo aver attraversato questa struttura ad albero, possiamo identificare rapidamente le pagine dell’indice che contengono i risultati della query. In questo caso, il motore di query leggerà le pagine dell’indice che contengono l'elemento 1. Una ricerca dell’indice è il modo più efficiente per usare l'indice. Con una ricerca dell’indice, leggiamo solo le pagine dell’indice necessarie e carichiamo solo gli elementi nei risultati della query. Di conseguenza, il tempo di ricerca dell'indice e l'addebito delle UR dalla ricerca dell'indice sono incredibilmente bassi, indipendentemente dal volume di dati totale.
Analisi precisa dell'indice
Si consideri la query seguente:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
Il predicato di query (filtrando gli elementi in cui sono presenti più di 200 dipendenti) può essere valutato con un'analisi precisa dell'indice del percorso headquarters/employees. Facendo un'analisi dell’indice precisa, il motore di query inizia eseguendo una ricerca binaria del set distinto dei possibili valori per trovare la posizione del valore 200 per il percorso headquarters/employees. Visto che i valori per ogni percorso sono in ordine crescente, è facile per il motore di query eseguire una ricerca binaria. Dopo che il motore di query trova il valore 200, inizia a leggere tutte le pagine dell’indice rimanenti (in maniera crescente).
Dato che il motore di query può eseguire una ricerca binaria per evitare l'analisi di pagine dell’indice non necessarie, le analisi precise degli indici tendono ad avere una latenza simile e gli addebiti UR per le operazioni di ricerca degli indici.
Analisi estesa dell'indice
Si consideri la query seguente:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
Il predicato di query (filtrando gli elementi che sono in un luogo che inizia con "United" senza distinzione tra maiuscole e minuscole), può essere valutato con un'analisi estesa dell’indice del percorso headquarters/country. Le operazioni che eseguono un'analisi estesa dell’indice hanno ottimizzazioni che aiutano a evitare di dover analizzare ogni pagina dell’indice, ma sono leggermente più care rispetto ad una ricerca binaria di un'analisi dell'indice precisa.
Ad esempio, quando si valuta la distinzione tra maiuscole e minuscole StartsWith, il motore di query controlla l'indice cercando diverse combinazioni possibili di valori con maiuscole e minuscole. Questa ottimizzazione consente al motore di query di evitare di leggere la maggior parte delle pagine dell’indice. Diverse funzioni di sistema hanno svariate ottimizzazioni che possono usare per evitare di leggere ogni pagina dell’indice, per poi categorizzarle in maniera generale come analisi ampia dell'indice.
Analisi completa dell'indice
Si consideri la query seguente:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Il predicato di query (filtrando gli elementi che sono in una posizione che contiene "United") può essere valutato con un'analisi dell'indice del percorso headquarters/country. A differenza di un'analisi di indice precisa, un'analisi completa dell'indice analizza sempre il set distinto dei valori possibili per identificare le pagine dell’indice in cui sono presenti dei risultati. In questo caso, Contains viene eseguito sull'indice. Il tempo di ricerca dell'indice e l'addebito UR per le analisi degli indici aumenta man mano che aumenta la cardinalità del percorso. In altre parole, sono i valori distinti possibili che il motore di query deve analizzare, maggiore è la latenza e l'addebito UR coinvolti nell'esecuzione di un'analisi completa dell'indice.
Prendiamo, per esempio, due proprietà: town e country. La cardinalità della città è 5.000 e la cardinalità di country è 200. Di seguito ci sono due esempi di query, ognuna con una funzione di sistema Contains che esegue un'analisi completa dell'indice sulla proprietà town. La prima query usa più UR rispetto alla seconda query perché la cardinalità della città è superiore a country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Analisi completa
In alcuni casi, il motore di query potrebbe non riuscire a valutare un filtro di query usando l'indice. In questo caso, il motore di query deve caricare tutti gli elementi dall'archivio transazionale per valutare il filtro di query. Le analisi complete non usano l'indice e hanno un addebito di UR che aumenta in modo lineare rispetto alle dimensioni totali dei dati. Fortunatamente, le operazioni che richiedono analisi complete sono rare.
Query di ricerca vettoriali senza un indice vettoriale definito
Se non si definiscono criteri di indice vettoriale e si usa la funzione di sistema VectorDistance in una clausola ORDER BY, verrà generata un'analisi completa e verrà applicato un addebito UR superiore a quello definito da un criterio di indice vettoriale. Somiglianza, se si usa VectorDistance con il valore booleano di forza bruta impostato su true e non è definito un indice flat per il percorso vettoriale, verrà eseguita un'analisi completa.
Query con espressioni di filtro complesse
Negli esempi precedenti abbiamo visto solo query con espressioni di filtro semplici (ad esempio query con un solo filtro di uguaglianza o di range). In realtà, la maggior parte delle query ha espressioni di filtro molto più complesse.
Si consideri la query seguente:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
Per eseguire questa query, il motore di query deve fare una ricerca dell’indice su headquarters/employees e l'analisi completa dell'indice su headquarters/country. Il motore di query ha un’euristica interna usata per valutare l'espressione di filtro delle query nel modo più efficiente possibile. In questo caso, il motore di query eviterebbe di leggere le pagine dell’indice non necessarie eseguendo prima la ricerca dell'indice. Se, ad esempio, solo 50 elementi corrispondono al filtro di uguaglianza, il motore di query dovrà valutare solo Contains nelle pagine dell’indice che contengono questi 50 elementi. Non sarebbe necessaria un'analisi completa dell'indice dell'intero contenitore.
Utilizzo degli indici per le funzioni di aggregazione scalari
Le query con funzioni di aggregazione devono basarsi esclusivamente sull'indice per usarle.
In alcuni casi, l'indice può restituire dei falsi positivi. Ad esempio, quando valutiamo Contains sull'indice, il numero di corrispondenze nell'indice può superare il numero di risultati della query. Il motore di query carica tutte le corrispondenze dell’indice, valuta il filtro sugli elementi caricati e restituisce solo i risultati corretti.
Per la maggior parte delle query, il caricamento dei falsi positivi dell’indice non ha alcun effetto rilevante sull'utilizzo dell'indice.
Ad esempio, si consideri la query seguente:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
La funzione di sistema Contains può restituire falsi positivi. Quindi il motore di query deve verificare se ogni elemento caricato corrisponde all'espressione di filtro. In questo esempio, il motore di query potrebbe dover caricare solo alcuni elementi aggiuntivi. Perciò l'effetto sull'utilizzo dell'indice e l'addebito UR è minimo.
Tuttavia, le query con funzioni di aggregazione devono basarsi esclusivamente sull'indice per usarle. Si consideri ad esempio la query seguente con un'aggregazione Count:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Come nel primo esempio, la funzione di sistema Contains può restituire dei falsi positivi. Tuttavia, a differenza della query SELECT *, la query Count non può valutare l'espressione di filtro sugli elementi caricati per verificare tutte le corrispondenze di indice. La query Count deve basarsi esclusivamente sull'indice, quindi se un'espressione di filtro può restituire dei falsi positivi, il motore di query esegue a un'analisi completa.
Le query con le funzioni di aggregazione seguenti devono basarsi esclusivamente sull'indice, quindi la valutazione di alcune funzioni di sistema richiede un'analisi completa.
Passaggi successivi
Altre informazioni sull'indicizzazione sono disponibili negli articoli seguenti: