MLOps (Machine Learning Operations)
Le operazioni di Machine Learning (dette anche MLOps) sono l'applicazione dei principi DevOps alle applicazioni infuse tramite intelligenza artificiale. Per implementare operazioni di Machine Learning in un'organizzazione, competenze, processi e tecnologie specifiche devono essere implementate. L'obiettivo è offrire soluzioni di Machine Learning affidabili, scalabili, affidabili e automatizzate.
Questo articolo illustra come pianificare le risorse per supportare le operazioni di Machine Learning a livello di organizzazione. Esaminare le procedure consigliate e le raccomandazioni basate sull'uso di Azure Machine Learning per adottare operazioni di Machine Learning nell'organizzazione.
Informazioni sulle operazioni di Machine Learning
Gli algoritmi e i framework di Machine Learning moderni semplificano sempre più lo sviluppo di modelli in grado di eseguire stime accurate. Le operazioni di Machine Learning sono un modo strutturato per incorporare l'apprendimento automatico nello sviluppo di applicazioni nell'azienda.
In uno scenario di esempio è stato creato un modello di Machine Learning che supera tutte le aspettative di accuratezza e impressiona gli sponsor aziendali. È ora possibile distribuire il modello nell'ambiente di produzione, ma potrebbe non essere così semplice come previsto. È probabile che l'organizzazione debba disporre di persone, processi e tecnologie prima di poter usare il modello di Machine Learning nell'ambiente di produzione.
Nel corso del tempo, l'utente o un collega potrebbe sviluppare un nuovo modello che funziona meglio del modello originale. La sostituzione di un modello di Machine Learning usato nell'ambiente di produzione introduce alcune problematiche importanti per l'organizzazione:
- Si vuole implementare il nuovo modello senza interrompere le operazioni aziendali che si basano sul modello distribuito.
- Ai fini normativi, potrebbe essere necessario spiegare le stime del modello o ricreare il modello se stime insolite o distorte derivano dai dati nel nuovo modello.
- I dati usati nel training e nel modello di Machine Learning possono cambiare nel tempo. Con le modifiche apportate ai dati, potrebbe essere necessario ripetere periodicamente il training del modello per mantenere l'accuratezza della stima. A una persona o a un ruolo deve essere assegnata la responsabilità di inserire i dati, monitorare le prestazioni del modello, ripetere il training del modello e correggere il modello in caso di errore.
Si supponga di avere un'applicazione che gestisce le stime di un modello tramite l'API REST. Anche un caso d'uso semplice come questo potrebbe causare problemi nell'ambiente di produzione. L'implementazione di una strategia operativa di Machine Learning consente di risolvere i problemi di distribuzione e supportare le operazioni aziendali che si basano su applicazioni basate sull'intelligenza artificiale.
Alcune attività operative di Machine Learning sono adatte al framework DevOps generale. Gli esempi includono la configurazione di unit test e test di integrazione e il rilevamento delle modifiche usando il controllo della versione. Altre attività sono più specifiche per le operazioni di Machine Learning e possono includere:
- Abilitare la sperimentazione continua e il confronto con un modello di base.
- Monitorare i dati in ingresso per rilevare la deriva dei dati.
- Attivare il training del modello e configurare un rollback per il ripristino di emergenza.
- Creare pipeline di dati riutilizzabili per il training e l'assegnazione dei punteggi.
L'obiettivo delle operazioni di Machine Learning è quello di colmare il divario tra lo sviluppo e la produzione e offrire valore ai clienti più velocemente. Per raggiungere questo obiettivo, è necessario ripensare i processi di sviluppo e produzione tradizionali.
Non tutti i requisiti operativi di Machine Learning dell'organizzazione sono gli stessi. L'architettura delle operazioni di Machine Learning di un'azienda multinazionale di grandi dimensioni probabilmente non sarà la stessa infrastruttura stabilita da una piccola startup. Le organizzazioni iniziano in genere piccole e si accumulano man mano che aumentano la maturità, il catalogo dei modelli e l'esperienza.
Il modello di maturità delle operazioni di Machine Learning consente di vedere dove si trova l'organizzazione sulla scala di maturità delle operazioni di Machine Learning e di pianificare la crescita futura.
Operazioni di Machine Learning e DevOps
Le operazioni di Machine Learning sono diverse da DevOps in diverse aree chiave. Le operazioni di Machine Learning presentano queste caratteristiche:
- L'esplorazione precede lo sviluppo e le operazioni.
- Il ciclo di vita di data science richiede un modo adattivo di lavorare.
- Limiti sullo stato di avanzamento della qualità dei dati e del limite di disponibilità.
- Un impegno operativo maggiore è necessario rispetto a DevOps.
- I team di lavoro richiedono specialisti ed esperti di dominio.
Per un riepilogo, vedere i sette principi delle operazioni di Machine Learning.
L'esplorazione precede lo sviluppo e le operazioni
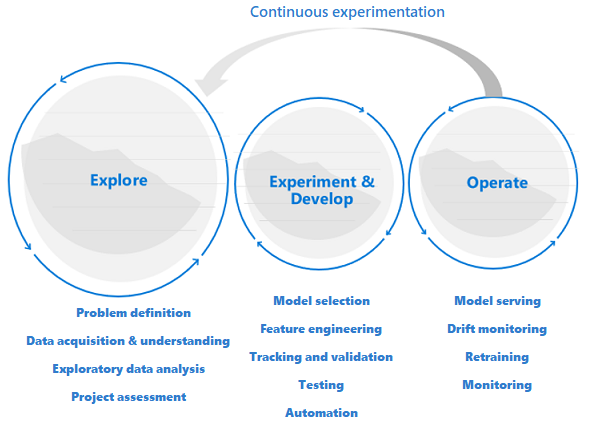
I progetti di data science sono diversi dai progetti di sviluppo di applicazioni o di ingegneria dei dati. Un progetto di data science potrebbe renderlo di produzione, ma spesso sono necessari più passaggi rispetto a una distribuzione tradizionale. Dopo un'analisi iniziale, potrebbe risultare chiaro che il risultato aziendale non può essere ottenuto con i set di dati disponibili. Una fase di esplorazione più dettagliata è in genere il primo passaggio di un progetto di data science.
L'obiettivo della fase di esplorazione è definire e perfezionare il problema. Durante questa fase, i data scientist eseguono l'analisi esplorativa dei dati. Usano statistiche e visualizzazioni per confermare o falsificare le ipotesi del problema. Gli stakeholder devono comprendere che il progetto potrebbe non estendersi oltre questa fase. Allo stesso tempo, è importante rendere questa fase il più facile possibile per un rapido turnaround. A meno che il problema da risolvere includa un elemento di sicurezza, evitare di limitare la fase esplorativa con processi e procedure. I data scientist devono essere autorizzati a lavorare con gli strumenti e i dati che preferiscono. Per questo lavoro esplorativo sono necessari dati reali.
Il progetto può passare alle fasi di sperimentazione e sviluppo quando gli stakeholder sono sicuri che il progetto di data science sia fattibile e possa fornire valore aziendale reale. In questa fase, le pratiche di sviluppo diventano sempre più importanti. È consigliabile acquisire le metriche per tutti gli esperimenti che vengono effettuati in questa fase. È anche importante incorporare il controllo del codice sorgente in modo da poter confrontare i modelli e alternare le diverse versioni del codice.
Le attività di sviluppo includono il refactoring, il test e l'automazione del codice di esplorazione nelle pipeline di sperimentazione ripetibili. L'organizzazione deve creare applicazioni e pipeline per gestire i modelli. Il refactoring del codice in componenti modulari e librerie consente di aumentare la riutilizzabilità, i test e l'ottimizzazione delle prestazioni.
Infine, le pipeline di inferenza batch o dell'applicazione che servono i modelli vengono distribuite in ambienti di staging o di produzione. Oltre a monitorare l'affidabilità e le prestazioni dell'infrastruttura, ad esempio per un'applicazione standard, in una distribuzione di modelli di Machine Learning, è necessario monitorare continuamente la qualità dei dati, il profilo dati e il modello per la riduzione o la deriva. I modelli di Machine Learning richiedono anche la ripetizione del training nel tempo per rimanere pertinenti in un ambiente in continua evoluzione.
Il ciclo di vita del data science richiede una modalità di lavorazione adattiva
Poiché la natura e la qualità dei dati inizialmente non sono incerte, è possibile che non si riesca a raggiungere gli obiettivi aziendali se si applica un processo DevOps tipico a un progetto di data science. L'esplorazione e la sperimentazione sono attività ricorrenti e esigenze in tutto il processo di Machine Learning. Teams in Microsoft usa un ciclo di vita del progetto e un processo di lavoro che rifletta la natura delle attività specifiche per l'analisi scientifica dei dati. Il processo di data science per i team e il processo del ciclo di vita di data science sono esempi di implementazioni di riferimento.
Limiti sullo stato di avanzamento della qualità dei dati e del limite di disponibilità
Per consentire a un team di Machine Learning di sviluppare in modo efficace applicazioni infuse di Machine Learning, l'accesso ai dati di produzione è preferibile per tutti gli ambienti di lavoro pertinenti. Se l'accesso ai dati di produzione non è possibile a causa di requisiti di conformità o vincoli tecnici, è consigliabile implementare il controllo degli accessi in base al ruolo di Azure con Azure Machine Learning, l'accesso JIT o le pipeline di spostamento dei dati per creare repliche di dati di produzione e migliorare la produttività degli utenti.
Machine Learning richiede un impegno operativo maggiore
A differenza del software tradizionale, le prestazioni di una soluzione di Machine Learning sono costantemente a rischio perché la soluzione dipende dalla qualità dei dati. Per mantenere una soluzione qualitativa nell'ambiente di produzione, è fondamentale monitorare e rivalutare costantemente sia i dati che la qualità del modello. È possibile che un modello di produzione richieda nuovi training, ridistribuzioni e ottimizzazioni al momento opportuno. Queste attività sono basate sulla sicurezza quotidiana, sul monitoraggio dell'infrastruttura e sui requisiti di conformità e richiedono competenze specializzate.
I team di Machine Learning richiedono specialisti ed esperti di dominio
Anche se i progetti di data science condividono ruoli con progetti IT regolari, il successo di un'attività di Machine Learning dipende molto dalla presenza di esperti essenziali della tecnologia di Machine Learning e esperti del dominio. Uno specialista tecnologico ha il giusto background per eseguire la sperimentazione di Machine Learning end-to-end. Un esperto di dominio può supportare lo specialista analizzando e sintetizzando i dati o qualificando i dati per l'uso.
I ruoli tecnici comuni univoci per i progetti di data science sono esperti di dominio, data engineer, data scientist, ingegneri di intelligenza artificiale, validator di modelli e ingegneri di Machine Learning. Per altre informazioni sui ruoli e sulle attività in un tipico team di data science, vedere Processo di data science per i team.
Sette principi delle operazioni di Machine Learning
Quando si prevede di adottare operazioni di Machine Learning nell'organizzazione, è consigliabile applicare i principi di base seguenti come base:
Usare il controllo della versione per output di codice, dati e sperimentazione. A differenza dello sviluppo di software tradizionale, i dati hanno un'influenza diretta sulla qualità dei modelli di Machine Learning. È consigliabile eseguire la versione della codebase di sperimentazione, ma anche la versione dei set di dati per assicurarsi di poter riprodurre esperimenti o risultati di inferenza. Gli output della sperimentazione di controllo delle versioni, ad esempio i modelli, possono risparmiare sforzo e il costo di calcolo della ricreazione delle versioni.
Usare più ambienti. Per separare lo sviluppo e il test dal lavoro di produzione, replicare l'infrastruttura in almeno due ambienti. Il controllo di accesso per gli utenti potrebbe essere diverso per ogni ambiente.
Gestire l'infrastruttura e le configurazioni come codice. Quando si creano e aggiornano i componenti dell'infrastruttura negli ambienti di lavoro, usare l'infrastruttura come codice, quindi le incoerenze non si sviluppano negli ambienti. Gestire le specifiche del processo dell'esperimento di Machine Learning come codice in modo da poter eseguire e riutilizzare facilmente una versione dell'esperimento in più ambienti.
Tenere traccia e gestire esperimenti di Machine Learning. Tenere traccia degli indicatori di prestazioni chiave e di altri artefatti per gli esperimenti di Machine Learning. Quando si mantiene una cronologia delle prestazioni del lavoro, è possibile eseguire un'analisi quantitativa del successo della sperimentazione e migliorare la collaborazione e l'agilità del team.
Testare il codice, convalidare l'integrità dei dati e garantire la qualità del modello. Testare la codebase di sperimentazione per le funzioni corrette di preparazione dei dati e estrazione delle funzionalità, l'integrità dei dati e le prestazioni del modello.
Integrazione e recapito continui di Machine Learning. Usare l'integrazione continua (CI) per automatizzare i test per il team. Includere il training del modello come parte delle pipeline di training continue. Includere test A/B come parte della versione per assicurarsi che venga usato solo un modello qualitativo nell'ambiente di produzione.
Monitorare servizi, modelli e dati. Quando si gestiscono i modelli in un ambiente operativo di Machine Learning, è fondamentale monitorare i servizi per il tempo di attività, la conformità e la qualità del modello dell'infrastruttura. Configurare il monitoraggio per identificare i dati e la deriva del modello e per comprendere se è necessaria la ripetizione del training. Valutare la possibilità di configurare i trigger per la ripetizione automatica del training.
Procedure consigliate di Azure Machine Learning
Azure Machine Learning offre servizi di gestione degli asset, orchestrazione e automazione per gestire il ciclo di vita dei flussi di lavoro di training e distribuzione del modello di Machine Learning. Esaminare le procedure consigliate e le raccomandazioni per applicare le operazioni di Machine Learning nelle aree delle risorse di persone, processi e tecnologie, tutte supportate da Azure Machine Learning.
Persone
Collaborare con i team del progetto per usare al meglio conoscenze specializzate e di dominio nell'organizzazione. Configurare le aree di lavoro di Azure Machine Learning per ogni progetto in modo che siano conformi ai requisiti di separazione dei casi d'uso.
Definire un set di responsabilità e attività come ruolo in modo che qualsiasi membro del team in un team di progetto di operazioni di Machine Learning possa essere assegnato e soddisfare più ruoli. Usare ruoli personalizzati in Azure per definire un set di operazioni granulari di Controllo degli accessi in base al ruolo di Azure per Azure Machine Learning che ogni ruolo può eseguire.
Standardizzare in base al ciclo di vita di un progetto e alla metodologia Agile. Il processo di data science per i team consente un'implementazione del ciclo di vita di riferimento.
I team bilanciati possono eseguire tutte le fasi di operazioni di Machine Learning, tra cui esplorazione, sviluppo e operazioni.
Processo
Standardizzare in un modello di codice per il riutilizzo del codice e accelerare il tempo di avvio in un nuovo progetto o quando un nuovo membro del team partecipa al progetto. Usare pipeline di Azure Machine Learning, script di invio di processi e pipeline CI/CD come base per i nuovi modelli.
Uso del controllo della versione. I processi inviati da una cartella supportata da Git rilevano automaticamente i metadati del repository con il processo in Azure Machine Learning per la riproducibilità.
Usare il controllo delle versioni per gli input e gli output dell'esperimento per la riproducibilità. Usare set di dati di Azure Machine Learning, gestione dei modelli e funzionalità di gestione dell'ambiente per facilitare il controllo delle versioni.
Creare una cronologia di esecuzione delle esecuzioni dell'esperimento per confronti, pianificazione e collaborazione. Usare un framework di rilevamento dell'esperimento come MLflow per raccogliere le metriche.
Misurare e controllare continuamente la qualità del lavoro del team tramite CI sulla base di codice di sperimentazione completa.
Terminare il training all'inizio del processo quando un modello non converge. Usare un framework di rilevamento dell'esperimento e la cronologia di esecuzione in Azure Machine Learning per monitorare le esecuzioni dei processi.
Definire una strategia di gestione di esperimenti e modelli. Prendere in considerazione l'uso di un nome come campione per fare riferimento al modello di base corrente. Un modello challenger è un modello candidato che potrebbe superare le prestazioni del modello campione nell'ambiente di produzione. Applicare tag in Azure Machine Learning per contrassegnare esperimenti e modelli. In uno scenario come la previsione delle vendite, potrebbero essere necessari mesi per determinare se le stime del modello sono accurate.
Elevare l'integrazione continua per il training continuo includendo il training del modello nella compilazione. Ad esempio, iniziare il training del modello nel set di dati completo con ogni richiesta pull.
Ridurre il tempo necessario per ottenere feedback sulla qualità della pipeline di Machine Learning eseguendo una compilazione automatizzata su un esempio di dati. Usare i parametri della pipeline di Azure Machine Learning per parametrizzare i set di dati inseriti.
Usare la distribuzione continua (CD) per i modelli di Machine Learning per automatizzare la distribuzione e il test dei servizi di assegnazione dei punteggi in tempo reale negli ambienti Azure.
In alcuni settori regolamentati potrebbe essere necessario completare i passaggi di convalida del modello prima di poter usare un modello di Machine Learning in un ambiente di produzione. L'automazione dei passaggi di convalida potrebbe accelerare il tempo di consegna. Quando i passaggi di revisione o convalida manuali sono ancora un collo di bottiglia, valutare se è possibile certificare la pipeline di convalida automatica del modello. Usare i tag delle risorse in Azure Machine Learning per indicare la conformità degli asset e i candidati per la revisione o come trigger per la distribuzione.
Non ripetere il training nell'ambiente di produzione e quindi sostituire direttamente il modello di produzione senza eseguire test di integrazione. Anche se le prestazioni del modello e i requisiti funzionali potrebbero risultare validi, tra gli altri potenziali problemi, un modello sottoposto a training potrebbe avere un footprint di ambiente maggiore e interrompere l'ambiente server.
Quando l'accesso ai dati di produzione è disponibile solo nell'ambiente di produzione, usare il controllo degli accessi in base al ruolo di Azure e i ruoli personalizzati per concedere a un numero selezionato di professionisti di Machine Learning l'accesso in lettura. Alcuni ruoli potrebbero dover leggere i dati per l'esplorazione dei dati correlata. In alternativa, rendere disponibile una copia dei dati in ambienti non di produzione.
Accettare le convenzioni di denominazione e i tag per gli esperimenti di Azure Machine Learning per differenziare la ripetizione del training delle pipeline di apprendimento automatico di base dal lavoro sperimentale.
Tecnologia
Se attualmente si inviano processi tramite l'interfaccia utente o l'interfaccia della riga di comando di studio di Azure Machine Learning, anziché inviare processi tramite l'SDK, usare l'interfaccia della riga di comando o le attività di Machine Learning di Azure DevOps per configurare i passaggi della pipeline di automazione. Questo processo potrebbe ridurre il footprint del codice riutilizzando gli stessi invii di processi direttamente dalle pipeline di automazione.
Usare la programmazione basata su eventi. Ad esempio, attivare una pipeline di test del modello offline usando Funzioni di Azure dopo la registrazione di un nuovo modello. In alternativa, inviare una notifica a un alias di posta elettronica designato quando non è possibile eseguire una pipeline critica. Azure Machine Learning crea eventi in Griglia di eventi di Azure. È possibile sottoscrivere più ruoli per ricevere una notifica di un evento.
Quando si usa Azure DevOps per l'automazione, usare le attività di Azure DevOps per Machine Learning per usare i modelli di Machine Learning come trigger della pipeline.
Quando si sviluppano pacchetti Python per l'applicazione di Machine Learning, è possibile ospitarli in un repository di Azure DevOps come artefatti e pubblicarli come feed. Usando questo approccio, è possibile integrare il flusso di lavoro DevOps per la creazione di pacchetti con l'area di lavoro di Azure Machine Learning.
Provare a usare un ambiente di gestione temporanea per testare l'integrazione del sistema della pipeline di Machine Learning con componenti dell'applicazione upstream o downstream.
Creare unit test e test di integrazione per gli endpoint di inferenza per il debug avanzato e accelerare il tempo di distribuzione.
Per attivare la ripetizione del training, usare i monitoraggi dei set di dati e i flussi di lavoro basati su eventi. Sottoscrivere eventi di deriva dei dati e automatizzare il trigger delle pipeline di Machine Learning per la ripetizione del training.
Factory di intelligenza artificiale per le operazioni di Machine Learning dell'organizzazione
Un team di data science potrebbe decidere che può gestire più casi d'uso di Machine Learning internamente. L'adozione di operazioni di Machine Learning consente a un'organizzazione di configurare team di progetto per una migliore qualità, affidabilità e manutenibilità delle soluzioni. Grazie a team bilanciati, processi supportati e automazione tecnologica, un team che adotta operazioni di Machine Learning può ridimensionare e concentrarsi sullo sviluppo di nuovi casi d'uso.
Man mano che il numero di casi d'uso aumenta in un'organizzazione, il carico di gestione del supporto dei casi d'uso aumenta in modo lineare o ancora più. La sfida per l'organizzazione diventa come accelerare il time-to-market, supportare una valutazione più rapida della fattibilità dei casi d'uso, implementare la ripetibilità e usare al meglio risorse e set di competenze disponibili su una gamma di progetti. Per molte organizzazioni, lo sviluppo di una factory di intelligenza artificiale è la soluzione.
Una factory di intelligenza artificiale è un sistema di processi aziendali ripetibili e artefatti standardizzati che facilitano lo sviluppo e la distribuzione di un ampio set di casi d'uso di Machine Learning. Una factory di intelligenza artificiale ottimizza la configurazione del team, le procedure consigliate, la strategia operativa di Machine Learning, i modelli architetturali e i modelli riutilizzabili personalizzati in base ai requisiti aziendali.
Una factory di intelligenza artificiale di successo si basa su processi ripetibili e asset riutilizzabili per aiutare l'organizzazione a scalare in modo efficiente da decine di casi d'uso a migliaia di casi d'uso.
La figura seguente riepiloga gli elementi chiave di una factory IA:

Standardizzare con i modelli di architettura ripetibili
La ripetibilità è una caratteristica chiave di una factory di intelligenza artificiale. I team di data science possono accelerare lo sviluppo dei progetti e migliorare la coerenza tra di essi sviluppando alcuni modelli di architettura ripetibili che coprono la maggior parte dei casi d'uso di apprendimento automatico per l'organizzazione. Quando questi modelli sono disponibili, la maggior parte dei progetti può usare i modelli per ottenere i vantaggi seguenti:
- Fase di progettazione accelerata
- Approvazioni accelerate da parte dei team IT e responsabili della sicurezza quando questi riutilizzano gli strumenti nei progetti
- Sviluppo accelerato a causa di un'infrastruttura riutilizzabile come modelli di codice e modelli di progetto
I modelli di architettura possono includere, ma non solo, gli argomenti seguenti:
- Servizi preferiti per ogni fase del progetto
- Connettività e governance dei dati
- Una strategia operativa di Machine Learning personalizzata in base ai requisiti del settore, dell'azienda o della classificazione dei dati
- Campione di gestione dell'esperimento e modelli challenger
Facilitare la collaborazione e la condivisione tra team
I repository e le utilità del codice condiviso possono accelerare lo sviluppo di soluzioni di Machine Learning. I repository di codice possono essere sviluppati in modo modulare durante lo sviluppo del progetto in modo che siano abbastanza generici da usare in altri progetti. Possono essere disponibili in un repository centrale a cui tutti team di data science possono accedere.
Condividere e riutilizzare la proprietà intellettuale
Per ottimizzare il riutilizzo del codice, esaminare la proprietà intellettuale seguente all'inizio di un progetto:
- Codice interno progettato per riutilizzare nell'organizzazione. Gli esempi includono pacchetti e moduli.
- Set di dati creati in altri progetti di Machine Learning o disponibili nell'ecosistema di Azure.
- Progetti di data science esistenti con un'architettura e problemi aziendali simili.
- GitHub o repository open source che possono accelerare il progetto.
Qualsiasi retrospettiva del progetto deve includere un elemento di azione per determinare se gli elementi del progetto possono essere condivisi e generalizzati per un riutilizzo più ampio. L'elenco di asset che l'organizzazione può condividere e riutilizzare espande nel tempo.
Per facilitare la condivisione e l'individuazione, molte organizzazioni hanno introdotto repository condivisi per organizzare frammenti di codice e artefatti di Machine Learning. Gli artefatti in Azure Machine Learning, inclusi set di dati, modelli, ambienti e pipeline, possono essere definiti come codice, in modo da poterli condividere in modo efficiente tra progetti e aree di lavoro.
Modelli di progetto
Per accelerare il processo di migrazione delle soluzioni esistenti e ottimizzare il riutilizzo del codice, molte organizzazioni standardizzano in un modello di progetto per avviare nuovi progetti. Esempi di modelli di progetto consigliati per l'uso con Azure Machine Learning sono esempi di Azure Machine Learning, processo del ciclo di vita di data science e processo di data science per i team.
Gestione centrale dei dati
Il processo di accesso ai dati per l'esplorazione o l'utilizzo della produzione può richiedere molto tempo. Molte organizzazioni centralizzano la gestione dei dati per riunire produttori di dati e consumer di dati per facilitare l'accesso ai dati per la sperimentazione di Machine Learning.
Utilità condivise
L'organizzazione può usare dashboard centralizzati a livello aziendale per consolidare le informazioni di registrazione e monitoraggio. I dashboard possono includere la registrazione degli errori, la disponibilità del servizio e i dati di telemetria e il monitoraggio delle prestazioni del modello.
Usare le metriche di Monitoraggio di Azure per creare un dashboard per Azure Machine Learning e i servizi associati, ad esempio Archiviazione di Azure. Un dashboard consente di tenere traccia dello stato di sperimentazione, dell'integrità dell'infrastruttura di calcolo e dell'utilizzo della quota gpu.
Team specializzato di ingegneria di Machine Learning
Molte organizzazioni hanno implementato il ruolo di tecnico di Machine Learning. Un tecnico di Machine Learning è specializzato nella creazione e nell'esecuzione di pipeline di Machine Learning affidabili, monitoraggio della deriva e ripetizione del training dei flussi di lavoro e dashboard di monitoraggio. Il tecnico ha la responsabilità generale di industrializzare la soluzione di Machine Learning, dallo sviluppo alla produzione. Il tecnico lavora a stretto contatto con ingegneria dei dati, architetti, sicurezza e operazioni per garantire che siano presenti tutti i controlli necessari.
Anche se l'analisi scientifica dei dati richiede competenze approfondite sul dominio, la progettazione di Machine Learning è più tecnica. La differenza rende il tecnico di Machine Learning più flessibile, in modo da poter lavorare su vari progetti e con vari reparti aziendali. Le procedure di data science di grandi dimensioni possono trarre vantaggio da un team specializzato di ingegneria di Machine Learning che guida la ripetibilità e il riutilizzo dei flussi di lavoro di automazione in diversi casi d'uso e aree aziendali.
Abilitazione e documentazione
È importante fornire indicazioni chiare sul processo di fabbrica di intelligenza artificiale per team e utenti nuovi ed esistenti. Le linee guida consentono di garantire coerenza e ridurre il lavoro richiesto dal team di progettazione di Machine Learning durante l'industrializzazione di un progetto. Valutare la possibilità di progettare il contenuto in modo specifico per i vari ruoli dell'organizzazione.
Tutti hanno un modo unico di imparare, quindi una combinazione dei tipi di indicazioni seguenti può aiutare ad accelerare l'adozione del framework di fabbrica di intelligenza artificiale:
- Hub centrale con collegamenti a tutti gli artefatti. Ad esempio, questo hub potrebbe essere un canale in Microsoft Teams o in un sito di Microsoft SharePoint.
- Training e piano di abilitazione progettato per ogni ruolo.
- Presentazione di riepilogo generale dell'approccio e di un video complementare.
- Documento dettagliato o playbook.
- Video di procedura.
- Valutazioni di idoneità.
Operazioni di Machine Learning nella serie di video di Azure
Una serie di video sulle operazioni di Machine Learning in Azure illustra come stabilire operazioni di Machine Learning per la soluzione di Machine Learning, dallo sviluppo iniziale all'ambiente di produzione.
Etica
L'etica svolge un ruolo fondamentale nella progettazione di una soluzione di IA. Se i principi etici non vengono implementati, i modelli sottoposti a training potrebbero presentare la stessa distorsione presente nei dati su cui è stato eseguito il training. Il risultato potrebbe essere che il progetto non è più disponibile. Ancora più importante, la reputazione dell'organizzazione potrebbe essere a rischio.
Per garantire che i principi etici chiave per cui l'organizzazione sia in grado di essere implementati in tutti i progetti, l'organizzazione deve fornire un elenco di questi principi e modi per convalidarli da un punto di vista tecnico durante la fase di test. Usare le funzionalità di Machine Learning in Azure Machine Learning per comprendere qual è l'apprendimento automatico responsabile e come compilarlo nelle operazioni di Machine Learning.
Passaggi successivi
Altre informazioni su come organizzare e configurare ambienti di Azure Machine Learning o guardare una serie di video pratici sulle operazioni di Machine Learning in Azure.
Altre informazioni su come gestire budget, quote e costi a livello di organizzazione usando Azure Machine Learning: