Creare e gestire asset di dati
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Questo articolo illustra come creare e gestire asset di dati in Azure Machine Learning.
Gli asset di dati possono essere utili quando sono necessari:
- Controllo delle versioni: gli asset di dati supportano il controllo delle versioni dei dati.
- Riproducibilità: una volta creata, una versione dell'asset di dati è non modificabile. Non può essere modificata né eliminata. Di conseguenza, i processi di training o le pipeline che usano l'asset di dati sono riproducibili.
- Verificabilità: poiché la versione dell'asset di dati non è modificabile, è possibile tenere traccia delle versioni, controllando chi ha aggiornato una versione e quando.
- Derivazione: per qualsiasi asset di dati specifico, è possibile visualizzare quali processi o pipeline utilizzano i dati.
- Facilità d'uso: un asset di dati di Azure Machine Learning è simile ai segnalibri del Web browser (preferiti). Invece di ricordare percorsi di archiviazione lunghi (URI) che fanno riferimento ai dati usati più di frequente in Archiviazione di Azure, è possibile creare una versione di asset di dati e quindi accedervi con un nome descrittivo, ad esempio
azureml:<my_data_asset_name>:<version>.
Suggerimento
Per accedere ai dati in una sessione interattiva (ad esempio, un notebook) o in un processo, non è necessario creare prima un asset di dati. È possibile usare gli URI dell'archivio dati per accedere ai dati. Gli URI dell'archivio dati offrono un modo semplice per accedere ai dati per chi inizia a usare Azure Machine Learning.
Prerequisiti
Per creare e usare asset di dati, è necessario:
Una sottoscrizione di Azure. Se non se ne dispone, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning. Creare le risorse dell'area di lavoro.
L'interfaccia della riga di comando/SDK di Azure Machine Learning installata.
Creare asset di dati
Quando si crea l'asset di dati, è necessario impostare il relativo tipo. Azure Machine Learning supporta tre tipi di asset di dati:
| Type | API | Scenari canonici |
|---|---|---|
| file Riferimento a un singolo file |
uri_file |
Lettura di un singolo file in Archiviazione di Azure ( il file può avere qualsiasi formato). |
| Cartella Riferimento a una cartella |
uri_folder |
Lettura di una cartella di file parquet/CSV in Pandas/Spark. Lettura di dati non strutturati (immagini, testo, audio e così via) situati in una cartella. |
| Tabella Riferimento a una tabella dati |
mltable |
Si dispone di uno schema complesso soggetto a modifiche frequenti oppure è necessario un subset di dati tabulari di grandi dimensioni. AutoML con tabelle. Legge i dati non strutturati (immagini, testo, audio e così via) distribuiti tra più posizioni di archiviazione. |
Nota
Usare le nuove righe incorporate nei file CSV solo se si registrano i dati come MLTable. I caratteri di nuova riga incorporati nei file CSV possono causare valori di campo non allineati durante la lettura dei dati. MLTable dispone del support_multi_line parametro disponibile nella trasformazione read_delimited, per interpretare le interruzioni di riga tra virgolette come un record.
Quando si utilizza l'asset di dati in un processo di Azure Machine Learning, è possibile montare o scaricare l'asset in uno o più nodi di calcolo. Per altre informazioni, vedere Modalità.
Inoltre, è necessario specificare un parametro path che punta alla posizione dell'asset di dati. I percorsi supportati includono:
| Ufficio | Esempi |
|---|---|
| Un percorso nel computer locale | ./home/username/data/my_data |
| Un percorso in un archivio dati | azureml://datastores/<data_store_name>/paths/<path> |
| Un percorso in uno o più server HTTP pubblici | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Un percorso in Archiviazione di Azure | (BLOB) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS Gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS Gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Nota
Quando si crea un asset di dati da un percorso locale, verrà caricato automaticamente nell'archivio dati predefinito di Azure Machine Learning nel cloud.
Creare un asset di dati: tipo di file
Un asset di dati di un tipo di file (uri_file) punta a un singolo file nell'archiviazione (ad esempio, un file CSV). È possibile creare un asset di dati di tipo file con:
Creare un file YAML e copiare/incollare il frammento di codice seguente. Assicurarsi di aggiornare i segnaposto <> con
- nome dell'asset di dati
- versione
- description
- percorso a un singolo file in una posizione supportata
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Eseguire quindi il comando seguente nell'interfaccia della riga di comando. Assicurarsi di aggiornare il segnaposto <filename> al nome file YAML.
az ml data create -f <filename>.yml
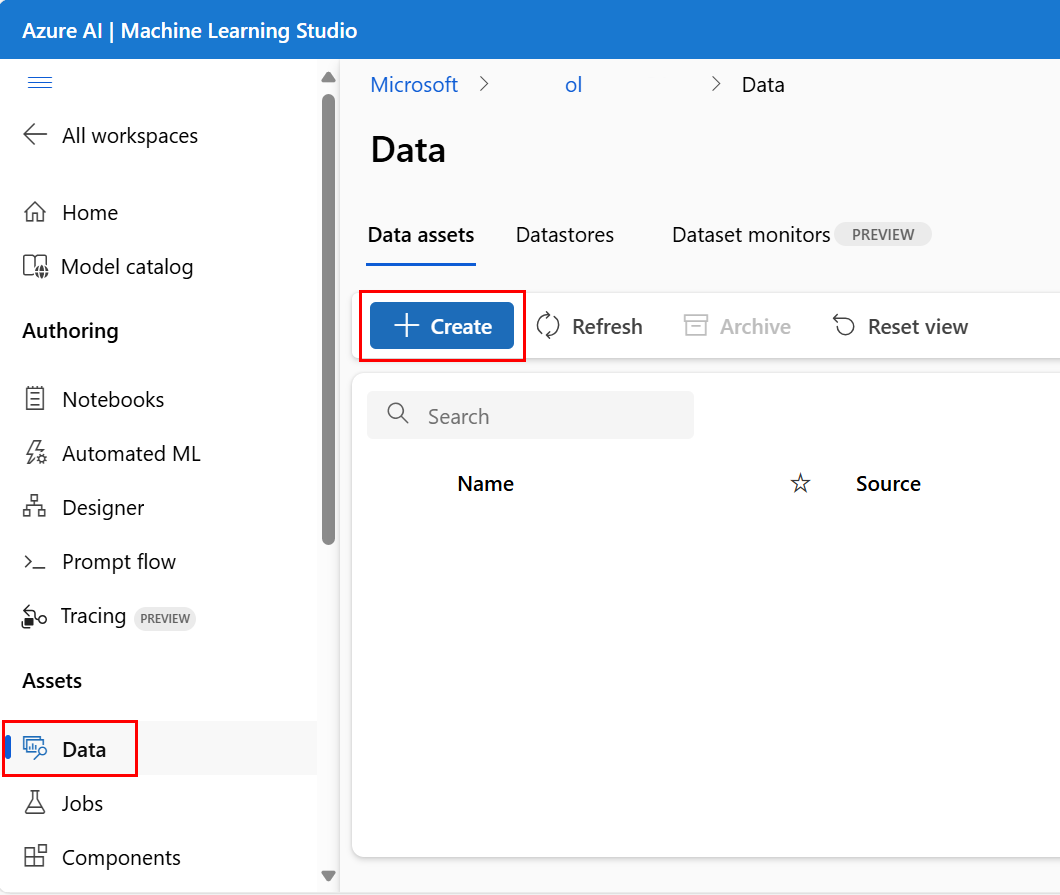

Creare un asset di dati: tipo di cartella
Un tipo di asset di dati Cartella (uri_folder) punta a una cartella in una risorsa di archiviazione, ad esempio una cartella contenente diverse sottocartelle di immagini. È possibile creare un asset di dati di tipo cartella con:
Copiare e incollare il codice seguente in un nuovo file YAML. Assicurarsi di aggiornare i segnaposto <> con
- Nome dell'asset di dati
- Versione
- Descrizione
- Percorso a una cartella in una posizione supportata
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Eseguire quindi il comando seguente nell'interfaccia della riga di comando. Assicurarsi di aggiornare il segnaposto <filename> al nome file YAML.
az ml data create -f <filename>.yml

Creare un asset di dati: tipo di tabella
Le tabelle di Azure Machine Learning (MLTable) hanno funzionalità avanzate, descritte in modo più dettagliato in Uso delle tabelle in Azure Machine Learning. Invece di ripetere la documentazione qui, leggere questo esempio che descrive come creare un asset di dati di tipo Tabella, con i dati Titanic che si trovano in un account di archiviazione BLOB di Azure disponibile pubblicamente.
Creare prima di tutto una nuova directory denominata data e creare un file denominato MLTable:
mkdir data
touch MLTable
Quindi copiare e incollare il codice YAML seguente nel file MLTable creato nel passaggio precedente:
Attenzione
Non rinominare il file MLTable in MLTable.yaml o MLTable.yml. Azure Machine Learning si aspetta un file MLTable.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Eseguire il comando seguente nell'interfaccia della riga di comando. Assicurarsi di aggiornare i segnaposto <> con il nome e i valori della versione dell'asset di dati.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Importante
Il valore di path deve essere una cartella che contiene un file MLTable valido.
Creazione di asset di dati dagli output di un processo
È possibile creare un asset di dati da un processo di Azure Machine Learning. A tale scopo, impostare il parametro name nell'output. In questo esempio si invia un processo che copia i dati da un archivio BLOB pubblico all'archivio dati predefinito di Azure Machine Learning e crea un asset di dati denominato job_output_titanic_asset.
Creare un file YAML di specifica del processo (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Inviare quindi il processo usando l'interfaccia della riga di comando:
az ml job create --file <file-name>.yml
Gestire gli asset di dati
Eliminare un asset di dati
Importante
Da progettazione, l'eliminazione degli asset di dati non è supportata.
Se Azure Machine Learning consentisse l'eliminazione degli asset di dati, si verificherebbero gli effetti negativi e avversi seguenti:
- I processi di produzione che utilizzano gli asset di dati eliminati in un secondo momento non riuscirebbero.
- Diventerebbe più difficile riprodurre un esperimento di Machine Learning.
- La derivazione dei processi si interromperebbe, perché diventerebbe impossibile visualizzare la versione degli asset di dati eliminati.
- Non sarebbe possibiletenere traccia e controllare correttamente i processi, poiché le versioni potrebbero non essere presenti.
Pertanto, la non modificabilità degli asset di dati offre un livello di protezione quando si lavora in un team che crea carichi di lavoro di produzione.
Per un asset di dati creato erroneamente, ad esempio con un nome, un tipo o un percorso non corretto, Azure Machine Learning offre soluzioni per gestire la situazione senza le conseguenze negative dell'eliminazione:
| Si vuole eliminare un asset di dati perché: | Soluzione |
|---|---|
| Il nome non è corretto | Archiviare l'asset di dati |
| Il team non usa più l'asset di dati | Archiviare l'asset di dati |
| Rende complesso l'elenco di asset di dati | Archiviare l'asset di dati |
| Il percorso non è corretto | Creare una nuova versione dell'asset di dati con lo stesso nome e con il percorso corretto. Per altre informazioni, vedere Creare asset di dati. |
| È di un tipo non corretto | Al momento, Azure Machine Learning non consente la creazione di una nuova versione con un tipo diverso rispetto a quello della versione iniziale. (1) Archiviare l'asset di dati (2) Creare un nuovo asset di dati con un nome diverso e con il tipo corretto. |
Archiviare un asset di dati
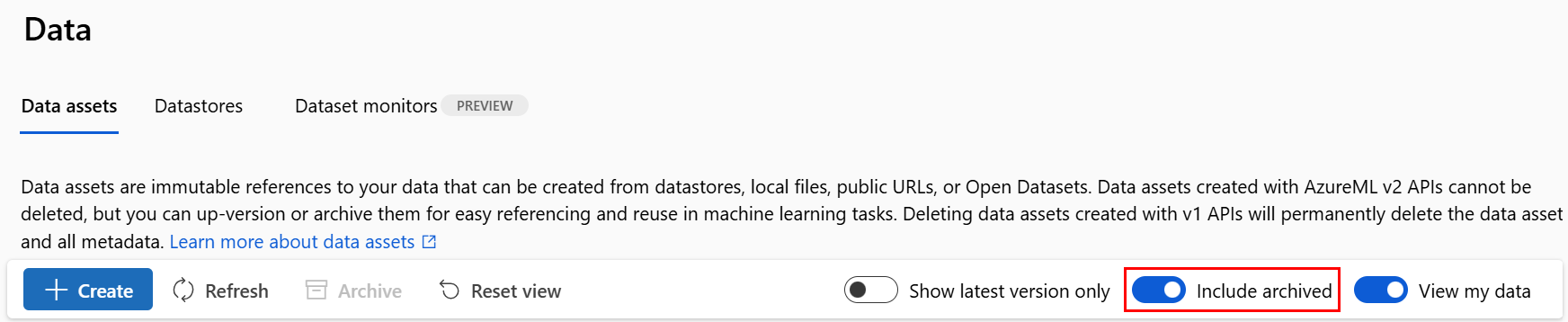
Se un asset di dati viene archiviato, per impostazione predefinita viene nascosto alle query di elenco (ad esempio, nell'interfaccia della riga di comando az ml data list) e all'elenco di asset di dati nell'interfaccia utente dello studio. È comunque possibile continuare a fare riferimento e usare un asset di dati archiviato nei flussi di lavoro. È possibile archiviare:
- Tutte le versioni dell'asset di dati con un determinato nome oppure
or
- Una versione specifica dell'asset di dati
Archiviare tutte le versioni di un asset di dati
Per archiviare tutte le versioni dell'asset di dati con un nome specificato, usare:
Eseguire il comando seguente. Assicurarsi di aggiornare i segnaposto <> con le informazioni.
az ml data archive --name <NAME OF DATA ASSET>

Archiviare una versione specifica dell'asset di dati
Per archiviare una versione specifica dell'asset di dati, usare:
Eseguire il comando seguente. Assicurarsi di aggiornare i segnaposto <> con la versione e il nome dell'asset di dati.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Ripristinare un asset di dati archiviato
È possibile ripristinare un asset di dati archiviato. Se vengono archiviate tutte le versioni dell'asset di dati, non è possibile ripristinare singole versioni. È necessario ripristinarle tutte.
Ripristinare tutte le versioni di un asset di dati
Per ripristinare tutte le versioni dell'asset di dati con un nome specificato, usare:
Eseguire il comando seguente. Assicurarsi di aggiornare i segnaposto <> con il nome dell'asset di dati.
az ml data restore --name <NAME OF DATA ASSET>
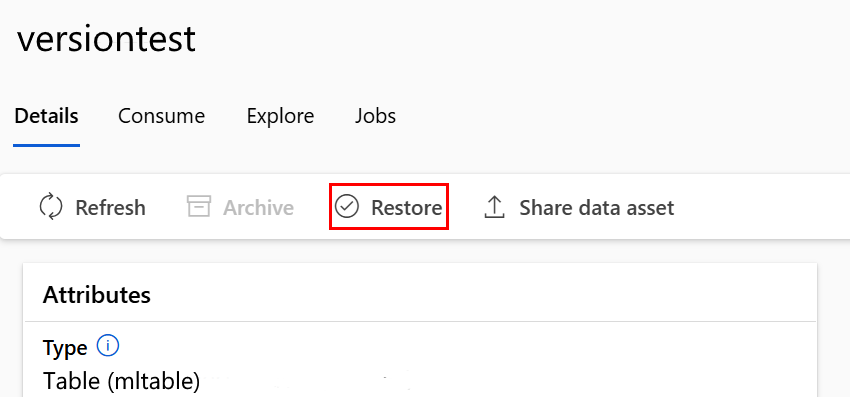
Ripristinare una versione specifica dell'asset di dati
Importante
Se sono state archiviate tutte le versioni dell'asset di dati, non è possibile ripristinare singole versioni. È necessario ripristinarle tutte.
Per ripristinare una versione specifica dell'asset di dati, usare:
Eseguire il comando seguente. Assicurarsi di aggiornare i segnaposto <> con la versione e il nome dell'asset di dati.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Derivazione dei dati
Per derivazione dei dati si intende comunemente il ciclo di vita che si estende dall'origine dei dati ai vari spostamenti nel corso del tempo nell'archiviazione. Diversi tipi di scenari retroattivi lo usano, ad esempio
- Risoluzione dei problemi
- Tracciare le cause radice nelle pipeline di Machine Learning
- Debug
Viene usata anche in scenari di analisi della qualità dei dati, conformità e simulazione. La derivazione viene rappresentata visivamente per mostrare i dati che passano dall'origine alla destinazione e illustra anche le relative trasformazioni. Considerando la complessità della maggior parte degli ambienti di dati aziendali, queste visualizzazioni possono diventare difficili da interpretare senza consolidamento o mascheramento di punti dati periferici.
In una pipeline di Azure Machine Learning, gli asset di dati mostrano l'origine dei dati e il modo in cui sono stati elaborati, ad esempio:

È possibile visualizzare i processi che usano l'asset di dati nell'interfaccia utente dello studio. Selezionare prima di tutto Dati nel menu a sinistra e quindi selezionare il nome dell'asset di dati. Si notino i processi che usano l'asset di dati:
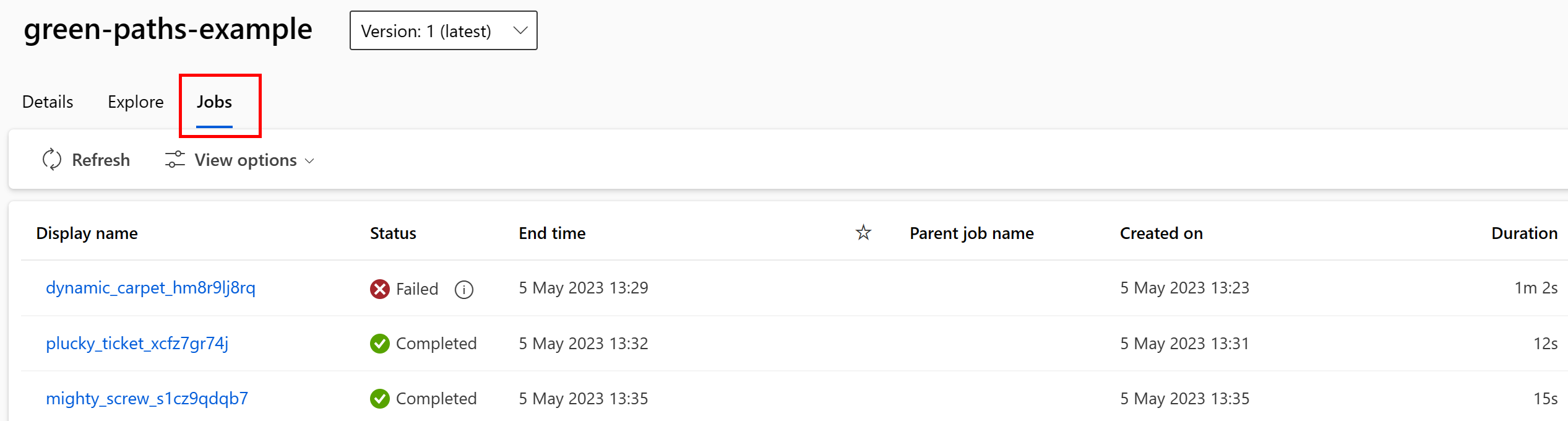
La visualizzazione dei processi in Asset di dati semplifica l'individuazione di errori e l'esecuzione di analisi della causa radice nelle pipeline di ML e nel debug.
Assegnazione di tag agli asset di dati
Gli asset di dati supportano l'assegnazione di tag, ovvero metadati aggiuntivi applicati come coppia chiave-valore. L'assegnazione di tag ai dati offre numerosi vantaggi:
- Descrizione della qualità dei dati. Ad esempio, se l'organizzazione usa un'architettura lakehouse medallion è possibile assegnare agli asset i tag
medallion:bronze(non elaborato),medallion:silver(convalidato) emedallion:gold(arricchito). - Funzionalità efficienti di ricerca e filtro dei dati per favorirne l'individuazione.
- Identificazione di dati personali sensibili, per gestire e regolamentare correttamente l'accesso ai dati. Ad esempio:
sensitivity:PII/sensitivity:nonPII. - Determinazione del fatto che i dati siano approvati da un controllo di intelligenza artificiale responsabile (RAI). Ad esempio:
RAI_audit:approved/RAI_audit:todo.
È possibile aggiungere tag agli asset di dati come parte del flusso di creazione oppure aggiungerli a dati esistenti. Questa sezione illustra entrambi gli elementi:
Aggiungere tag come parte del flusso di creazione degli asset di dati
Creare un file YAML e copiare e incollare il codice seguente in tale file YAML. Assicurarsi di aggiornare i segnaposto <> con
- nome dell'asset di dati
- versione
- description
- tag (coppie chiave-valore)
- percorso a un singolo file in una posizione supportata
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Eseguire il comando seguente nell'interfaccia della riga di comando. Assicurarsi di aggiornare il segnaposto <filename> al nome file YAML.
az ml data create -f <filename>.yml
Aggiungere tag a un asset di dati esistente
Quindi, eseguire il comando seguente nell'interfaccia della riga di comando di Azure. Assicurarsi di aggiornare i segnaposto <> con
- Nome dell'asset di dati
- Versione
- Coppia chiave-valore per il tag
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Procedure consigliate relative al controllo delle versioni
In genere, i processi ETL organizzano la struttura di cartelle in Archiviazione di Azure in base al tempo, ad esempio:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
La combinazione di cartelle strutturate in base a tempo/versione e di tabelle di Azure Machine Learning (MLTable) consente di creare set di dati con versione. Un esempio ipotetico illustra come ottenere dati con versione con le tabelle di Azure Machine Learning. Si supponga di avere un processo che carica immagini della fotocamera in archiviazione BLOB di Azure ogni settimana, in questa struttura:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Nota
Anche se viene illustrato come eseguire versione dei dati di immagine (jpeg), lo stesso approccio funziona per qualsiasi tipo di file( ad esempio Parquet, CSV).
Con le tabelle di Azure Machine Learning (mltable), creare una Tabella di percorsi che includono i dati fino alla fine della prima settimana nel 2023. Quindi, creare un asset di dati:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Alla fine della settimana seguente, il processo ETL ha aggiornato i dati per includerne altri:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
La prima versione (20230108) continua a montare/scaricare solo i file da year=2022/week=52 e year=2023/week=1 perché i percorsi vengono dichiarati nel file MLTable. Ciò garantisce riproducibilità per gli esperimenti. Per creare una nuova versione dell'asset di dati che include year=2023/week2, usare:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Sono ora disponibili due versioni dei dati, in cui il nome della versione corrisponde alla data in cui le immagini sono state caricate nell'archiviazione:
- 20230108: le immagini fino a 08/01/2023.
- 20230115: le immagini fino a 15/01/2023.
In entrambi i casi, MLTable crea una tabella di percorsi che include solo le immagini fino a tali date.
In un processo di Azure Machine Learning è possibile montare o scaricare questi percorsi in MLTable con versione nella destinazione di calcolo usando le modalità eval_download o eval_mount:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Nota
Le modalità eval_mount e eval_download sono univoche per MLTable. In questo caso, la funzionalità di runtime dei dati di AzureML valuta il file MLTable e monta i percorsi nella destinazione di calcolo.