Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo illustra le procedure consigliate di sicurezza per la pianificazione o la gestione di una distribuzione sicura di Azure Machine Learning. Le procedure consigliate provengono da Microsoft e dall'esperienza dei clienti con Azure Machine Learning. Ogni linea guida illustra la pratica e la relativa logica. L'articolo fornisce anche collegamenti a procedure e documentazione di riferimento.
Architettura di sicurezza di rete consigliata (rete gestita)
L'architettura di sicurezza di rete di Machine Learning consigliata è una rete virtuale gestita. Una rete virtuale gestita di Azure Machine Learning protegge l'area di lavoro, le risorse di Azure associate e tutte le risorse di calcolo gestite. Semplifica la configurazione e la gestione della sicurezza di rete preconfigurando gli output necessari e creando automaticamente risorse gestite all'interno della rete. È possibile usare endpoint privati per consentire ai servizi di Azure di accedere alla rete e, facoltativamente, definire regole in uscita per consentire alla rete di accedere a Internet.
La rete virtuale gestita dispone di due modalità per cui è possibile configurarla:
Consenti connessioni Internet in uscita : questa modalità consente la comunicazione in uscita con le risorse che si trovano su Internet, ad esempio i repository di pacchetti PyPi o Anaconda pubblici.

Consenti solo in uscita approvato: questa modalità consente solo la comunicazione in uscita minima necessaria per il funzionamento dell'area di lavoro. Questa modalità è consigliata per le aree di lavoro che devono essere isolate da Internet. Oppure dove l'accesso in uscita è consentito solo a risorse specifiche tramite endpoint di servizio, tag di servizio o nomi di dominio completi.

Per altre informazioni, vedere Isolamento della rete virtuale gestita.
Architettura di sicurezza di rete consigliata (Azure Rete virtuale)
Se non è possibile usare una rete virtuale gestita a causa dei requisiti aziendali, è possibile usare una rete virtuale di Azure con le subnet seguenti:
- La subnet di training contiene le risorse di calcolo usate per il training, ad esempio istanze di ambiente di calcolo o cluster di elaborazione per l'apprendimento automatico.
- La subnet di punteggio contiene le risorse di calcolo usate per l'assegnazione del punteggio, ad esempio il servizio Azure Kubernetes.
- La subnet del firewall contiene il firewall che consente il traffico da e verso la rete Internet pubblica, ad esempio Firewall di Azure.
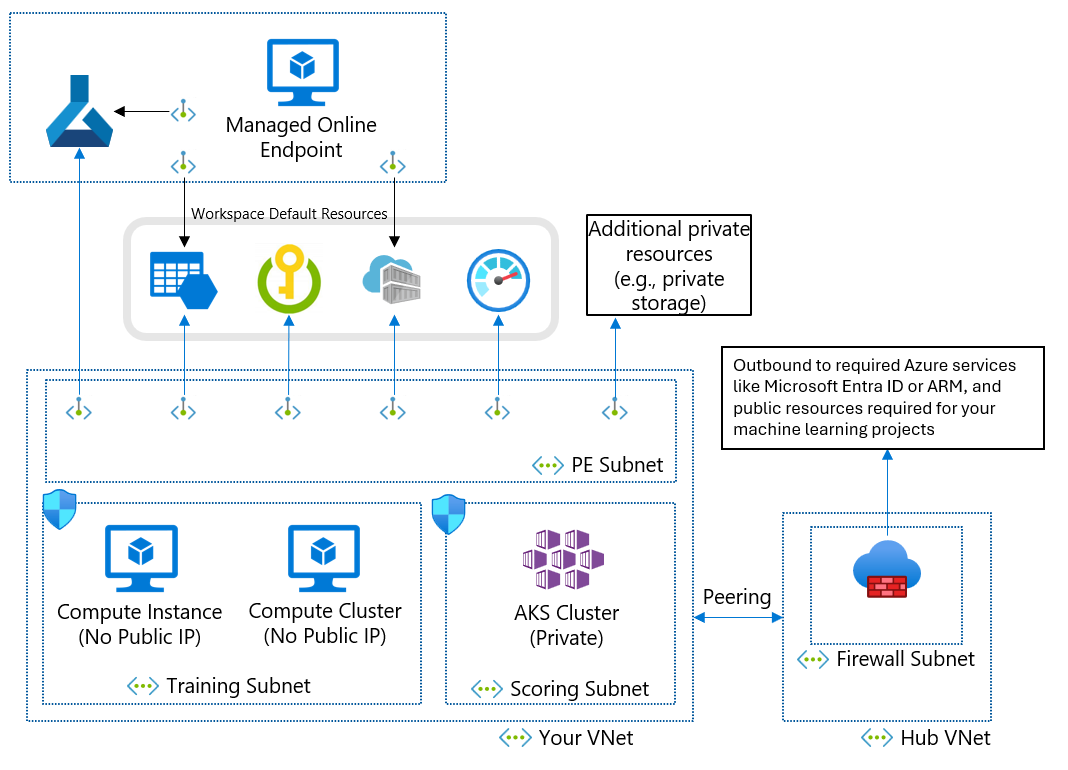
La rete virtuale contiene anche un endpoint privato per l'area di lavoro di Machine Learning e i servizi dipendenti seguenti:
- Account di archiviazione di Azure
- Azure Key Vault
- Registro Azure Container
La comunicazione in uscita dalla rete virtuale deve poter raggiungere i servizi Microsoft seguenti:
- Apprendimento automatico
- Microsoft Entra ID
- Registro Azure Container e registri specifici gestiti da Microsoft
- Frontdoor di Azure
- Azure Resource Manager
- Archiviazione di Azure
I client remoti si connettono alla rete virtuale usando Azure ExpressRoute o una connessione VPN (Virtual Private Network).
Progettazione di reti virtuali ed endpoint privati
Quando si progetta un Rete virtuale di Azure, le subnet e gli endpoint privati, considerare i requisiti seguenti:
In generale, creare subnet separate per il training e l'assegnazione dei punteggi e usare la subnet di training per tutti gli endpoint privati.
Per l'indirizzamento IP, le istanze di ambiente di calcolo necessitano di un indirizzo IP privato ciascuna. I cluster di elaborazione necessitano di un indirizzo IP privato per nodo. I cluster del servizio Azure Kubernetes necessitano di molti indirizzi IP privati, come descritto in Pianificare l'indirizzamento IP per il cluster del servizio Azure Kubernetes . Una subnet separata almeno per il servizio Azure Kubernetes consente di evitare l'esaurimento degli indirizzi IP.
Le risorse di calcolo nelle subnet di training e assegnazione dei punteggi devono accedere all'account di archiviazione, all'insieme di credenziali delle chiavi e al registro contenitori. Creare endpoint privati per l'account di archiviazione, l'insieme di credenziali delle chiavi e il registro contenitori.
L'archiviazione predefinita dell'area di lavoro di apprendimento automatico richiede due endpoint privati, uno per Archiviazione BLOB di Azure e l'altro per Archiviazione file di Azure.
Se si usa studio di Azure Machine Learning, gli endpoint privati dell'area di lavoro e dell'archiviazione devono trovarsi nella stessa rete virtuale.
Se sono presenti più aree di lavoro, usare una rete virtuale per ogni area di lavoro per creare un limite di rete esplicito tra le aree di lavoro.
Usare indirizzi IP privati
Gli indirizzi IP privati riducono al minimo l'esposizione delle risorse di Azure a Internet. L'apprendimento automatico usa molte risorse di Azure e l'endpoint privato dell'area di lavoro di apprendimento automatico non è sufficiente per l'indirizzo IP privato end-to-end. La tabella seguente illustra le principali risorse usate da Machine Learning e come abilitare l'indirizzo IP privato per le risorse. Le istanze di ambiente di calcolo e i cluster di elaborazione sono le uniche risorse che non hanno la funzionalità IP privato.
| Risorse | Soluzione IP privato | Documentazione |
|---|---|---|
| Area di lavoro | Endpoint privato | Configurare un endpoint privato per un'area di lavoro di Azure Machine Learning |
| Registro | Endpoint privato | Isolamento di rete con i registri di Azure Machine Learning |
| Risorse associate | ||
| Storage | Endpoint privato | Proteggere gli account di archiviazione di Azure con gli endpoint di servizio |
| Key Vault | Endpoint privato | Proteggere Azure Key Vault |
| Registro Container | Endpoint privato | Abilitare Registro Azure Container |
| Risorse di formazione | ||
| Istanza di calcolo | IP privato (nessun indirizzo IP pubblico) | Proteggere gli ambienti di training |
| Cluster di elaborazione | IP privato (nessun indirizzo IP pubblico) | Proteggere gli ambienti di training |
| Hosting delle risorse | ||
| Endpoint online gestito | Endpoint privato | Isolamento della rete con endpoint online gestiti |
| Endpoint online (Kubernetes) | Endpoint privato | Proteggere servizio Azure Kubernetes endpoint online |
| Endpoint batch | IP privato (ereditato dal cluster di calcolo) | Isolamento di rete negli endpoint batch |
Controllare il traffico in ingresso e in uscita della rete virtuale
Usare un firewall o un gruppo di sicurezza di rete (NSG) di Azure per controllare il traffico in ingresso e in uscita della rete virtuale. Per altre informazioni sui requisiti in ingresso e in uscita, vedere Configurare il traffico di rete in ingresso e in uscita. Per altre informazioni sui flussi di traffico tra componenti, vedere Flusso del traffico di rete in un'area di lavoro protetta.
Garantire l'accesso all'area di lavoro
Per assicurarsi che l'endpoint privato possa accedere all'area di lavoro di apprendimento automatico, seguire questa procedura:
Assicurarsi di avere accesso alla rete virtuale usando una connessione VPN, ExpressRoute o una macchina virtuale jump box con accesso ad Azure Bastion. L'utente pubblico non può accedere all'area di lavoro di apprendimento automatico con l'endpoint privato perché è possibile accedervi solo dalla rete virtuale. Per altre informazioni, vedere Proteggere l'area di lavoro con reti virtuali.
Assicurarsi di poter risolvere i nomi di dominio completi (FQDN) dell'area di lavoro con l'indirizzo IP privato. Se si usa un server DNS (Domain Name System) o un'infrastruttura DNS centralizzata, è necessario configurare un server d'inoltro DNS. Per altre informazioni, vedere Come usare l'area di lavoro con un server DNS personalizzato.
Gestione dell'accesso all'area di lavoro
Quando si definiscono i controlli di gestione delle identità e degli accessi per l'apprendimento automatico, è possibile separare i controlli che definiscono l'accesso alle risorse di Azure dai controlli che gestiscono l'accesso agli asset di dati. A seconda del caso d'uso, valutare se usare la gestione delle identità e degli accessi self-service, incentrata sui dati o incentrata sul progetto.
Modello self-service
In un modello self-service, i data scientist possono creare e gestire le aree di lavoro. Questo modello è più adatto per situazioni di verifica che richiedono flessibilità per provare configurazioni diverse. Lo svantaggio è che i data scientist hanno bisogno delle competenze necessarie per effettuare il provisioning delle risorse di Azure. Questo approccio è meno adatto quando sono necessari controlli rigorosi, uso delle risorse, tracce di controllo e accesso ai dati.
Definire i criteri di Azure per impostare misure di sicurezza per il provisioning e l'utilizzo delle risorse, ad esempio le dimensioni del cluster consentite e i tipi di macchine virtuali.
Creare un gruppo di risorse per contenere le aree di lavoro e concedere ai data scientist un ruolo Collaboratore nel gruppo di risorse.
I data scientist possono ora creare aree di lavoro e associare le risorse nel gruppo di risorse in modalità self-service.
Per accedere all'archiviazione dei dati, creare identità gestite assegnate dall'utente e concedere alle identità ruoli di accesso in lettura nella risorsa di archiviazione.
Quando i data scientist creano risorse di calcolo, possono assegnare le identità gestite alle istanze di ambiente di calcolo per ottenere l'accesso ai dati.
Per le procedure consigliate, vedere Autenticazione per l'analisi su scala cloud.
Modello incentrato sui dati
In un modello incentrato sui dati, l'area di lavoro appartiene a un singolo data scientist che potrebbe lavorare su più progetti. Il vantaggio di questo approccio è che il data scientist può riusare il codice o le pipeline di training tra i progetti. Finché l'area di lavoro è limitata a un singolo utente, l'accesso ai dati può essere ricondotto a tale utente durante il controllo dei log di archiviazione.
Lo svantaggio è che l'accesso ai dati non è compartimentato o limitato per ogni progetto e qualsiasi utente aggiunto all'area di lavoro può accedere agli stessi asset.
Creare l'area di lavoro.
Creare risorse di calcolo con le identità gestite assegnate dal sistema abilitate.
Quando un data scientist deve accedere ai dati per un determinato progetto, concedere all'identità gestita di calcolo l'accesso in lettura ai dati.
Concedere all'identità gestita di calcolo l'accesso ad altre risorse necessarie, ad esempio un registro contenitori con immagini Docker personalizzate per il training.
Concedere anche il ruolo di accesso in lettura dell'identità gestita dell'area di lavoro ai dati per abilitare l'anteprima dei dati.
Concedere al data scientist l'accesso all'area di lavoro.
Il data scientist può ora creare archivi dati per accedere ai dati necessari per i progetti e inviare esecuzioni di training che usano i dati.
Facoltativamente, creare un gruppo di sicurezza Microsoft Entra e concedergli l'accesso in lettura ai dati, quindi aggiungere identità gestite al gruppo di sicurezza. Questo approccio riduce il numero di assegnazioni di ruolo dirette per le risorse, per evitare di raggiungere il limite della sottoscrizione per le assegnazioni di ruolo.
Modello incentrato sul progetto
Un modello incentrato sul progetto crea un'area di lavoro di apprendimento automatico per un progetto specifico e molti data scientist collaborano all'interno della stessa area di lavoro. L'accesso ai dati è limitato al progetto specifico, rendendo l'approccio particolarmente adatto per l'uso di dati sensibili. È anche semplice aggiungere o rimuovere data scientist dal progetto.
Lo svantaggio di questo approccio è che può essere difficile la condivisione degli asset tra i progetti. È anche difficile tracciare l'accesso ai dati a utenti specifici durante i controlli.
Creare l'area di lavoro
Identificare le istanze di archiviazione dati necessarie per il progetto, creare un'identità gestita assegnata dall'utente e concedere all'identità l'accesso in lettura alla risorsa di archiviazione.
Facoltativamente, concedere all'identità gestita dell'area di lavoro l'accesso all'archiviazione dati per consentire l'anteprima dei dati. È possibile omettere questo accesso per i dati sensibili non adatti per l'anteprima.
Creare archivi dati senza credenziali per le risorse di archiviazione.
Creare risorse di calcolo all'interno dell'area di lavoro e assegnare l'identità gestita alle risorse di calcolo.
Concedere all'identità gestita di calcolo l'accesso ad altre risorse necessarie, ad esempio un registro contenitori con immagini Docker personalizzate per il training.
Concedere ai data scientist che lavorano al progetto un ruolo nell'area di lavoro.
Usando il controllo degli accessi in base al ruolo di Azure, è possibile impedire ai data scientist di creare nuovi archivi dati o nuove risorse di calcolo con identità gestite diverse. Questa procedura impedisce l'accesso a dati non specifici del progetto.
Facoltativamente, per semplificare la gestione delle appartenenze ai progetti, è possibile creare un gruppo di sicurezza Microsoft Entra per i membri del progetto e concedere al gruppo l'accesso all'area di lavoro.
Azure Data Lake Storage con passthrough delle credenziali
È possibile usare l'identità utente di Microsoft Entra per l'accesso interattivo all'archiviazione da Machine Learning Studio. Data Lake Storage con lo spazio dei nomi gerarchico abilitato consente una migliore organizzazione degli asset di dati per l'archiviazione e la collaborazione. Con lo spazio dei nomi gerarchico di Data Lake Storage, è possibile compartimentalizzare l'accesso ai dati concedendo a utenti diversi l'accesso basato sull'elenco di controllo di accesso (ACL) a diverse cartelle e file. Ad esempio, è possibile concedere l'accesso ai dati riservati solo a un subset di utenti.
Controllo degli accessi in base al ruolo e ruoli personalizzati
Il controllo degli accessi in base al ruolo di Azure consente di gestire chi può accedere alle risorse di Machine Learning e configurare chi può eseguire operazioni. Ad esempio, è possibile concedere solo a utenti specifici il ruolo di amministratore dell'area di lavoro per gestire le risorse di calcolo.
L'ambito dell'accesso può variare a seconda degli ambienti. In un ambiente di produzione può essere necessario limitare la capacità degli utenti di aggiornare gli endpoint di inferenza. È invece possibile concedere tale autorizzazione a un'entità servizio autorizzata.
L'apprendimento automatico ha diversi ruoli predefiniti: proprietario, collaboratore, lettore e data scientist. È anche possibile creare ruoli personalizzati, ad esempio per creare autorizzazioni che riflettano la struttura organizzativa. Per altre informazioni, vedere Gestire gli accessi all'area di lavoro di Azure Machine Learning.
Nel tempo, la composizione del team potrebbe cambiare. Se si crea un gruppo Microsoft Entra per ogni ruolo e area di lavoro del team, è possibile assegnare un ruolo controllo degli accessi in base al ruolo di Azure al gruppo Microsoft Entra e gestire separatamente l'accesso alle risorse e i gruppi di utenti.
Le entità utente e le entità servizio possono far parte dello stesso gruppo Microsoft Entra. Ad esempio, quando si crea un'identità gestita assegnata dall'utente usata da Azure Data Factory per attivare una pipeline di Machine Learning, è possibile includere l'identità gestita in un gruppo Microsoft Entrator pipelines ml.
Gestione centrale delle immagini Docker
Azure Machine Learning fornisce immagini Docker curate che è possibile usare per il training e la distribuzione. Tuttavia, i requisiti di conformità dell'organizzazione potrebbero imporre l'uso di immagini da un repository privato gestito dall'azienda. L'apprendimento automatico consente di usare un repository centrale in due modi:
Usare le immagini di un repository centrale come immagini di base. La gestione dell'ambiente di apprendimento automatico installa i pacchetti e crea un ambiente Python in cui viene eseguito il codice di training o di inferenza. Con questo approccio, è possibile aggiornare facilmente le dipendenze dei pacchetti senza modificare l'immagine di base.
Usare le immagini così come sono, senza usare la gestione dell'ambiente di apprendimento automatico. Questo approccio offre un livello di controllo superiore, ma richiede anche di costruire attentamente l'ambiente Python come parte dell'immagine. È necessario soddisfare tutte le dipendenze necessarie per eseguire il codice ed eventuali nuove dipendenze richiedono la ricompilazione dell'immagine.
Per altre informazioni, vedere Gestire gli ambienti.
Crittografia dei dati
I dati inattivi di apprendimento automatico hanno due origini dati:
L'archiviazione include tutti i dati, inclusi i dati del training e del modello con training, ad eccezione dei metadati. L'utente è responsabile della crittografia della risorsa di archiviazione.
Azure Cosmos DB contiene i metadati, incluse le informazioni sulla cronologia di esecuzione, ad esempio il nome dell'esperimento e la data e l'ora di invio dell'esperimento. Nella maggior parte delle aree di lavoro, Azure Cosmos DB si trova nella sottoscrizione Microsoft ed è crittografato con una chiave gestita da Microsoft.
Se si vogliono crittografare i metadati usando la propria chiave, è possibile usare un'area di lavoro chiave gestita dal cliente. Lo svantaggio è che è necessario avere Azure Cosmos DB nella sottoscrizione e pagarne i costi. Per altre informazioni, vedere Crittografia dei dati con Azure Machine Learning.
Per informazioni su come Azure Machine Learning esegue la crittografia dei dati in transito, vedere Crittografia in transito.
Monitoraggio
Quando si distribuiscono risorse di apprendimento automatico, configurare i comandi di registrazione e controllo per l'osservabilità. Le motivazioni per l'osservazione dei dati possono variare in base a chi li esamina. Alcuni scenari includono:
I professionisti dell'apprendimento automatico o i team operativi vogliono monitorare l'integrità della pipeline di apprendimento automatico. Questi osservatori devono comprendere i problemi relativi all'esecuzione pianificata o ai problemi relativi alla qualità dei dati o alle prestazioni di training previste. È possibile creare dashboard di Azure che monitorano i dati di Azure Machine Learning o creano flussi di lavoro basati su eventi.
I responsabili della capacità, i professionisti dell'apprendimento automatico o i team operativi potrebbero voler creare un dashboard per osservare l'utilizzo dell'ambiente di calcolo e delle quote. Per gestire una distribuzione con più aree di lavoro di Azure Machine Learning, è consigliabile creare un dashboard centrale per comprendere l'utilizzo delle quote. Le quote vengono gestite a livello di sottoscrizione, quindi la visualizzazione a livello di ambiente è importante per l'ottimizzazione.
I team IT e operativi possono configurare la registrazione diagnostica per controllare l'accesso alle risorse e gli eventi di modifica nell'area di lavoro.
È consigliabile creare dashboard che monitorino l'integrità complessiva dell'infrastruttura per l'apprendimento automatico e risorse dipendenti come una risorsa di archiviazione. Ad esempio, la combinazione di metriche Archiviazione di Azure con i dati di esecuzione della pipeline consente di ottimizzare l'infrastruttura per ottenere prestazioni migliori o individuare le cause radice dei problemi.
Azure raccoglie e archivia automaticamente le metriche della piattaforma e i log attività. È possibile instradare i dati ad altre posizioni usando un'impostazione di diagnostica. Configurare la registrazione diagnostica in un'area di lavoro Log Analytics centralizzata per l'osservabilità in diverse istanze dell'area di lavoro. Usare Criteri di Azure per configurare automaticamente la registrazione per le nuove aree di lavoro di apprendimento automatico in questa area di lavoro Log Analytics centrale.
Criteri di Azure
È possibile applicare e controllare l'utilizzo delle funzionalità di sicurezza nelle aree di lavoro tramite Criteri di Azure. Raccomandazioni incluse:
- Applicare la crittografia con chiave gestita personalizzata.
- Applicare Collegamento privato di Azure ed endpoint privati.
- Applicare zone DNS private.
- Disabilitare l'autenticazione non Azure AD, ad esempio Secure Shell (SSH).
Per altre informazioni, vedere Definizioni di criteri predefiniti per Azure Machine Learning.
È anche possibile usare definizioni di criteri personalizzati per gestire la sicurezza dell'area di lavoro in modo flessibile.
Cluster di elaborazione e istanze di ambiente di calcolo
Le considerazioni e le raccomandazioni seguenti si applicano ai cluster di elaborazione e alle istanze di ambiente di calcolo dell'apprendimento automatico.
Crittografia del disco
Il disco del sistema operativo per un'istanza di calcolo o un nodo del cluster di calcolo viene archiviato in Archiviazione di Azure e crittografato con chiavi gestite da Microsoft. Ogni nodo ha anche un disco temporaneo locale. Il disco temporaneo viene crittografato anche con chiavi gestite da Microsoft se l'area di lavoro è stata creata con il hbi_workspace = True parametro . Per altre informazioni, vedere Crittografia dei dati con Azure Machine Learning.
Identità gestita
I cluster di elaborazione supportano l'uso di identità gestite per l'autenticazione nelle risorse di Azure. L'uso di un'identità gestita per il cluster consente l'autenticazione nelle risorse senza esporre le credenziali nel codice. Per altre informazioni, vedere Creare un cluster di elaborazione di Azure Machine Learning.
Script di configurazione
È possibile usare uno script di installazione per automatizzare la personalizzazione e la configurazione delle istanze di calcolo al momento della creazione. Gli amministratori possono scrivere uno script di personalizzazione da usare per la creazione di tutte le istanze di ambiente di calcolo in un'area di lavoro. È possibile usare Criteri di Azure per applicare l'uso dello script di installazione per creare ogni istanza di calcolo. Per altre informazioni, vedere Creare e gestire un'istanza di ambiente di calcolo di Azure Machine Learning.
Creare per conto di un altro utente
Se non si vuole che i data scientist eseseguono il provisioning delle risorse di calcolo, è possibile creare istanze di calcolo per loro conto e assegnarle ai data scientist. Per altre informazioni, vedere Creare e gestire un'istanza di ambiente di calcolo di Azure Machine Learning.
Area di lavoro abilitata per gli endpoint privati
Usare le istanze di ambiente di calcolo con un'area di lavoro abilitata per gli endpoint privati. L'istanza di ambiente di calcolo rifiuta tutti gli accessi pubblici dall'esterno della rete virtuale. Questa configurazione impedisce anche il filtraggio di pacchetti.
Supporto di Criteri di gruppo
Quando si usa una rete virtuale di Azure, è possibile usare Criteri di Azure per assicurarsi che ogni cluster di calcolo o istanza venga creato in una rete virtuale e specificare la rete virtuale e la subnet predefinite. I criteri non sono necessari quando si usa una rete virtuale gestita, perché le risorse di calcolo vengono create automaticamente nella rete virtuale gestita.
È anche possibile usare un criterio per disabilitare l'autenticazione non Azure AD, ad esempio SSH.
Passaggi successivi
Per altre informazioni sulle configurazioni di sicurezza dell'apprendimento automatico, vedere:
Iniziare a usare una distribuzione basata su modelli di apprendimento automatico:
- Modelli di avvio rapido di Azure (
microsoft.com) - Analisi su scala aziendale e zona di destinazione dei dati di intelligenza artificiale
Vedere altri articoli sulle considerazioni relative all'architettura per la distribuzione dell'apprendimento automatico:
Informazioni su come la struttura del team, l'ambiente o i vincoli a livello di area influiscono sulla configurazione dell'area di lavoro.
Informazioni su come gestire i costi di calcolo e il budget tra team e utenti.
Informazioni su Machine Learning DevOps (MLOps), che usa una combinazione di persone, processi e tecnologie per offrire soluzioni di apprendimento automatico solide, affidabili e automatizzate.