Monitorare le prestazioni usando le viste a gestione dinamica
Si applica a:![]() database SQL di Azure
database SQL di Azure ![]() database SQL in Fabric
database SQL in Fabric
È possibile usare i DMV per monitorare le prestazioni di carico di lavoro e diagnosticare i problemi delle prestazioni che potrebbero essere causati da query bloccate o con esecuzione prolungata, colli di bottiglia delle risorse, piani di query insufficienti e così via.
Questo articolo fornisce informazioni su come rilevare problemi comuni relativi alle prestazioni interrogando le DMV tramite T-SQL. È possibile usare qualsiasi strumento di query, ad esempio:
Autorizzazioni
In database SQL di Azure, a seconda delle dimensioni di calcolo e dell'opzione di distribuzione e i dati nel DMV, l'esecuzione di query su una DMV potrebbe richiedere l’autorizzazione VIEW DATABASE STATE o VIEW SERVER PERFORMANCE STATE, o VIEW SERVER SECURITY STATE. Le ultime due autorizzazioni sono incluse nell'autorizzazione VIEW SERVER STATE. Le autorizzazioni di visualizzazione dello stato del server vengono concesse tramite l'appartenenza ai ruoli del server corrispondenti. Per determinare quali autorizzazioni sono necessarie per eseguire query su una DMV specifica, vedere DMV e trovare l'articolo che descrive la DMV.
Per concedere l'autorizzazione VIEW DATABASE STATE a un utente del database, eseguire la query seguente, sostituendo database_user con il nome dell'entità utente nel database:
GRANT VIEW DATABASE STATE TO [database_user];
Per concedere l'adesione al ruolo del server ##MS_ServerStateReader## a un account di accesso denominato login_name su un server logico, collegarsi al database master ed eseguire la query seguente come esempio:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
Affinché l'autorizzazione concessa abbia effetto, potrebbero essere necessari alcuni minuti. Per altre informazioni, vedere Limiti dei ruoli a livello del server.
Monitorare l'uso delle risorse
È possibile monitorare l'utilizzo della risorsa a livello di database usando le viste seguenti: Queste viste sono applicabili ai database autonomi e ai database in un pool elastico.
È possibile monitorare l'uso della risorsa a livello del pool elastico usando le viste seguenti:
È possibile monitorare l'uso della risorsa a livello di query usando Informazioni dettagliate sulle prestazioni delle query del database SQL nel portale di Azure o in Query Store.
sys.dm_db_resource_stats
È possibile usare la vista sys.dm_db_resource_stats in ogni database. La sys.dm_db_resource_stats vista mostra i dati recenti relativi all'uso delle risorse rispetto ai limiti delle dimensioni di calcolo. Le percentuali di CPU, I/O dei dati, scritture di log, thread di lavoro e utilizzo della memoria verso il limite vengono registrate per ogni intervallo di 15 secondi e vengono mantenute per circa un'ora.
Poiché questa vista fornisce una visione granulare sui dati sull'uso delle risorse, si consiglia di usare prima sys.dm_db_resource_stats per eventuali analisi o risoluzioni di problemi dello stato corrente. Ad esempio, questa query descrive l'uso medio e massimo delle risorse per il database corrente nell'ultima ora:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
Per altre query, vedere gli esempi in sys.dm_db_resource_stats.
sys.resource_stats
La vista sys.resource_stats nel database master fornisce informazioni aggiuntive utili per il monitoraggio dell'uso delle prestazioni del database ai relativi livello di servizio e dimensioni di calcolo. I dati vengono raccolti ogni 5 minuti e conservati per circa 14 giorni. Questa vista è utile per analisi cronologiche a lungo termine dell'uso delle risorse del database.
Il grafico seguente illustra l'uso di risorse della CPU per un database Premium con dimensioni di calcolo P2 per ogni ora nell'arco di una settimana. Questo grafico inizia di lunedì e mostra cinque giorni lavorativi e un fine settimana in cui l'uso di risorse nell'applicazione è molto inferiore.
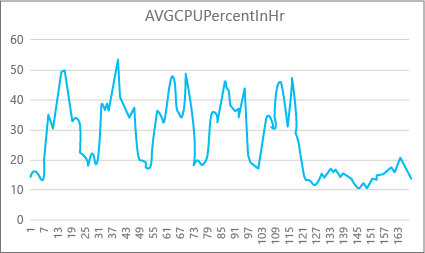
In base ai dati, per le dimensioni di calcolo P2 il carico massimo della CPU di questo database attualmente supera di poco il 50% dell'uso della CPU (a mezzogiorno di martedì). Se la CPU è il fattore più importante nel profilo delle risorse dell'applicazione, si può scegliere P2 come dimensioni di calcolo idonee a garantire che il carico di lavoro sia sempre adeguato. Se si prevede che un'applicazione presenti un incremento nel tempo, è consigliabile avere un buffer di risorse aggiuntivo, in modo che l'applicazione non raggiunga mai il limite del livello di prestazioni. Se si aumentano le dimensioni di calcolo, è possibile evitare gli errori visibili ai clienti che si possono verificare se un database non ha risorse sufficienti per elaborare in modo efficiente le richieste, in particolare in ambienti sensibili alla latenza.
Per altri tipi di applicazioni, è possibile interpretare in modo diverso lo stesso grafico. Se ad esempio un'applicazione prova a elaborare i dati del libro paga ogni giorno e usa lo stesso grafico, questo tipo di modello di processo batch potrebbe essere eseguito correttamente con dimensioni di calcolo P1. Il valore di DTU delle dimensioni di calcolo P1 è pari a 100, mentre quello delle dimensioni di calcolo P2 è pari a 200. Il livello di prestazioni fornito dalle dimensioni di calcolo P2 è doppio rispetto a quello fornito dalle dimensioni di calcolo P1. Il 50% dell'uso della CPU nel livello P2 equivale quindi al 100% dell'uso della CPU in P1. Se l'applicazione non presenta timeout, è possibile che non sia rilevante se il completamento di un processo richiede 2 ore o 2,5 ore, se viene completato in giornata. Per un'applicazione che rientra in questa categoria è probabilmente sufficiente usare le dimensioni di calcolo P1. Si può sfruttare la presenza di periodi di tempo durante il giorno in cui l'uso delle risorse è inferiore, in modo da spalmare un picco massimo in altri momenti nel corso della giornata. Le dimensioni di calcolo P1 possono essere ottimali per questo tipo di applicazione e possono consentire di limitare i costi, purché i processi vengano completati in orario ogni giorno.
Il motore di database espone le informazioni sulle risorse usate per ogni database attivo nella vista sys.resource_stats del database master in ogni server logico. I dati nella visualizzazione vengono aggregati per intervalli di 5 minuti. È possibile che la visualizzazione dei dati nella tabella richieda diversi minuti, quindi sys.resource_stats risultano più utili per le analisi cronologiche, invece che per le analisi in near-real-time. Esegui una query sys.resource_stats per visualizzare la cronologia recente di un database e verificare se le dimensioni di calcolo scelte hanno offerto le prestazioni desiderate quando necessario.
Nota
È necessario connettersi al database master per eseguire query sys.resource_stats negli esempi seguenti.
Questo esempio mostra i dati in sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
L'esempio successivo mostra i diversi modi in cui è possibile usare la vista del catalogo sys.resource_stats per ottenere informazioni sul modo in cui il database usa le risorse:
Per esaminare l'uso delle risorse nella settimana precedente per il database utente
userdb1, è possibile eseguire questa query sostituendo il nome del database:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Per verificare l'idoneità del carico di lavoro per le dimensioni di calcolo, è necessario eseguire il drill-down in ogni aspetto delle metriche delle risorse, ovvero CPU, dati I/O, scrittura del log, numero di ruoli di lavoro e numero di sessioni. Ecco una query modificata usando
sys.resource_statsper segnalare i valori medi e massimi di queste metriche delle risorse per ogni dimensione di calcolo per cui è stato effettuato il provisioning del database:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Con queste informazioni sui valori medi e massimi di ogni metrica delle risorse è possibile valutare l'idoneità delle dimensioni di calcolo scelte in rapporto al carico di lavoro. I valori medi di
sys.resource_statsoffrono in genere una buona previsione da usare nelle dimensioni di destinazione.Per i database del modello di acquisto DTU:
È ad esempio possibile che si usi il livello di servizio Standard con le dimensioni di calcolo S2. Le percentuali medie di uso per la CPU e per operazioni di scrittura e lettura I/O sono inferiori al 40%, il numero medio di thread di lavoro è inferiore a 50 e il numero medio di sessioni è inferiore a 200. Il carico di lavoro potrebbe essere idoneo per le dimensioni di calcolo S1. È facile verificare se il database rientra nei limiti dei thread di lavoro e delle sessioni. Per verificare se un database può rientrare in dimensioni di calcolo inferiori, è sufficiente dividere il numero di DTU delle dimensioni di calcolo inferiori per il numero di DTU delle dimensioni di calcolo correnti e moltiplicare il risultato per 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Il risultato rappresenta la differenza di prestazioni relativa, in percentuale, tra le due dimensioni di calcolo. Se l'uso delle risorse non supera questa percentuale, il carico di lavoro potrebbe essere idoneo per le dimensioni di calcolo inferiori. È tuttavia necessario esaminare anche tutti gli intervalli dei valori di uso delle risorse e determinare, a livello di percentuale, la frequenza con cui il carico di lavoro del database può rientrare nelle dimensioni di calcolo inferiori. La query seguente genera questa percentuale per ogni dimensione di risorsa, in base alla soglia del 40% calcolata in questo esempio:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;In base livello di servizio del database, è possibile stabilire se il carico di lavoro può rientrare nelle dimensioni di calcolo inferiori. Se l'obiettivo del carico di lavoro del database è 99,9% e la query precedente restituisce valori superiori al 99,9% per tutte e tre le dimensioni della risorsa, è probabile che il carico di lavoro possa rientrare nelle dimensioni di calcolo inferiori.
La percentuale calcolata in precedenza consente inoltre di stabilire se è opportuno usare le dimensioni di calcolo superiori a quelle attualmente in uso per soddisfare l'obiettivo. Ad esempio, l'utilizzo della CPU per un database di esempio nell'ultima settimana:
Percentuale CPU media Percentuale CPU massima 24.5 100.00 L'uso medio della CPU corrisponde a circa un quarto del limite delle dimensioni di calcolo, che potrebbe rientrare nelle dimensioni di calcolo del database.
Per il modello di acquisto DTU e i database del modello di acquisto vCore:
Il valore massimo corrisponde al limite delle dimensioni di calcolo del database. È necessario passare alle dimensioni di calcolo superiori a quelle attualmente in uso? Considerare il numero di volte in cui il carico di lavoro raggiunge il 100% e quindi confrontare tale numero con l'obiettivo del carico di lavoro del database.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Queste percentuali sono il numero di campioni che rientrano nel carico di lavoro all'interno delle dimensioni di calcolo correnti. Se questa query restituisce un valore inferiore al 99,9% per una delle tre dimensioni della risorsa, il carico di lavoro medio campionato ha superato i limiti. Considera il passaggio alla successiva dimensione di calcolo superiore o usa tecniche di ottimizzazione delle applicazioni per ridurre il carico nel database.
sys.dm_elastic_pool_resource_stats
Si applica a:![]() solo database SQL di Azure
solo database SQL di Azure
Analogamente a sys.dm_db_resource_stats, sys.dm_elastic_pool_resource_stats fornisce dati di utilizzo delle risorse recenti e granulari per un pool elastico database SQL di Azure. È possibile eseguire query sulla vista in qualsiasi database di un pool elastico per fornire i dati di utilizzo della risorsa per un intero pool anziché per qualsiasi database specifico. I valori percentuali segnalati da questa DMV sono verso i limiti del pool elastico, che potrebbe essere superiore ai limiti per un database nel pool.
Questo esempio mostra i dati di utilizzo delle risorse riepilogati per il pool elastico corrente negli ultimi 15 minuti:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Se si rileva che qualsiasi utilizzo delle risorse si avvicina al 100% per un periodo di tempo significativo, potrebbe essere necessario esaminare l'utilizzo delle risorse per singoli database nello stesso pool elastico per determinare quanto contribuisce ogni database all'utilizzo delle risorse a livello di pool.
sys.elastic_pool_resource_stats
Si applica a:![]() solo database SQL di Azure
solo database SQL di Azure
Analogamente a sys.resource_stats, sys.elastic_pool_resource_stats nel master database fornisce dati cronologici sull'utilizzo delle risorse per tutti i pool elastici nel server logico. È possibile usare sys.elastic_pool_resource_stats per il monitoraggio cronologico negli ultimi 14 giorni, inclusa l'analisi delle tendenze di utilizzo.
Questo esempio mostra i dati di utilizzo delle risorse riepilogati negli ultimi sette giorni per tutti i pool elastici nel server logico corrente. Eseguire la query nel master database.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Richieste simultanee
Per visualizzare il numero attuale di richieste simultanee, eseguire questa query sul database utente:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Questo è solo uno snapshot in un singolo punto nel tempo. Per una migliore comprensione del carico di lavoro e dei requisiti relativi alle richieste simultanee, sarà necessario raccogliere molti campioni nel tempo.
Tasso medio richiesto
In questo esempio viene illustrato come trovare la frequenza media delle richieste per un database o per i database in un pool elastico in un periodo di tempo. In questo esempio, il periodo di tempo è impostato su 30 secondi. È possibile modificarlo modificando l'istruzione WAITFOR DELAY. Eseguire questa query nel database utente. Se il database si trova in un pool elastico e se si dispone di autorizzazioni sufficienti, i risultati includono altri database nel pool elastico.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Sessione corrente
Per visualizzare il numero di sessioni attive correnti, esegui questa query sul database:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Questa query restituisce un conteggio temporizzato. Raccogliendo più campioni nel tempo, otterrai una comprensione ottimale dell'uso della sessione.
Cronologia recente di richieste, sessioni e ruoli di lavoro
In questo esempio viene restituito l'utilizzo cronologico recente di richieste, sessioni e thread di lavoro per un database o per i database in un pool elastico. Ogni riga rappresenta uno snapshot dell'utilizzo delle risorse in un momento specifico per un database. La requests_per_second colonna è la frequenza media delle richieste durante l'intervallo di tempo che termina con snapshot_time. Se il database si trova in un pool elastico e se si dispone di autorizzazioni sufficienti, i risultati includono altri database nel pool elastico.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Calcolare le dimensioni di database e oggetti
La seguente query restituisce la dimensione dei dati del database (in megabyte):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
La query seguente restituisce le dimensioni dei singoli oggetti (in megabyte) nel database:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Identificare i problemi di prestazioni della CPU
Questa sezione consente di identificare le singole query che sono i principali utenti della CPU.
Se l'utilizzo della CPU è superiore all'80% per lunghi periodi di tempo, considera i passaggi di risoluzione dei problemi seguenti sia se il problema della CPU si è presentato ora per la prima volta o se è già accaduto in passato. È anche possibile seguire i passaggi descritti in questa sezione per identificare in modo proattivo le prime query che utilizzano la CPU e ottimizzarle. In alcuni casi, la riduzione dell'utilizzo della CPU potrebbe consentire di ridurre i database e i pool elastici e risparmiare sui costi.
I passaggi per la risoluzione dei problemi sono gli stessi per i database e i database autonomi in un pool elastico. Eseguire tutte le query nel database utente.
Il problema della CPU si sta verificando in questo momento
Se il problema si sta verificando in questo momento, esistono due possibili scenari:
Numerose singole query hanno un utilizzo cumulativo elevato della CPU
Usare la query seguente per identificare gli hash di query più frequenti:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Query con esecuzione prolungata che usano la CPU sono ancora in esecuzione
Usare la query seguente per identificare le query:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
Il problema della CPU si è verificato in precedenza
Se il problema si è verificato in precedenza e si vuole eseguire l'analisi della causa radice, usare Query Store. Gli utenti con accesso al database possono usare T-SQL per eseguire query sui dati di Query Store. Per impostazione predefinita, Query Store acquisisce statistiche di query aggregate per intervalli di un'ora.
Usare la query seguente per esaminare l'attività di query con un utilizzo elevato della CPU. Questa query restituisce le 15 query con un maggior utilizzo della CPU. Ricordarsi di modificare
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()per esaminare un periodo di tempo diverso dalle ultime due ore:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Dopo avere identificato le query problematiche, è possibile ottimizzare le query per ridurre l'utilizzo della CPU. In alternativa, è possibile scegliere di aumentare le dimensioni di calcolo del database o del pool elastico per risolvere il problema.
Per altre informazioni sulla gestione dei problemi di prestazioni della CPU in database SQL di Azure, vedi Diagnosticare e risolvere i problemi relativi all'utilizzo elevato della CPU in Database SQL di Azure.
Identificare i problemi di prestazioni di IO
Quando si identificano problemi di prestazioni di input/output (I/O) di archiviazione, i principali tipi di attesa sono:
PAGEIOLATCH_*Per i problemi di I/O dei file di dati (inclusi
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Se il nome del tipo di attesa include IO, il tipo di attesa punta a un problema di I/O. Se il nome di attesa latch della pagina non include IO, il tipo di attesa punta a un tipo di problema che non è correlato alle prestazioni di archiviazione (ad esempio alla contesa ditempdb).WRITE_LOGPer i problemi di I/O del log delle transazioni.
Se il problema di I/O si sta verificando in questo momento
Usare sys.dm_exec_requests o sys.dm_os_waiting_tasks per visualizzare wait_type e wait_time.
Identifica l'utilizzo di I/O dei dati e dei log
Usa la query seguente per identificare l'utilizzo di I/O dei dati e dei log.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Per altri esempi che usano sys.dm_db_resource_stats, vedi la sezione Monitorare l'uso delle risorse più avanti in questo articolo.
Se è stato raggiunto il limite di I/O, sono disponibili due opzioni:
- Aggiornare le dimensioni di calcolo o il livello di servizio
- Identificare e ottimizzare le query che utilizzano la maggior parte dell'I/O
Visualizzare l'I/O correlato ai buffer usando Query Store
Per identificare le query principali mediante I/O, è possibile usare la query seguente in Query Store per l'I/O correlato ai buffer per visualizzare le ultime due ore di attività tracciate:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
È anche possibile usare la vista sys.query_store_runtime_stats, concentrandosi sulle query con valori di grandi dimensioni nelle colonne avg_physical_io_reads e avg_num_physical_io_reads.
Visualizza l'I/O totale dei log per le attese WRITELOG
Se il tipo di attesa è WRITELOG, usa la query seguente per visualizzare l'I/O totale dei log per istruzione:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identifica i problemi di prestazioni tempdb
I tipi di attesa comuni associati a problemi di tempdb sono PAGELATCH_* (non PAGEIOLATCH_*). Tuttavia, le attese PAGELATCH_* non indicano sempre una contesa di tempdb. Questo tipo di attesa può anche indicare una contesa della pagina di dati utente-oggetto causata da richieste simultanee che puntano alla stessa pagina di dati. Per confermare la contesa di tempdb, usa sys.dm_exec_requests per confermare che il valore wait_resourceinizia con 2:x:y dove 2 l'ID del database tempdb, x è l'ID file e y è l'ID pagina.
Un metodo comune per la contesa di tempdb consiste nel ridurre o nel riscrivere il codice dell'applicazione che si basa su tempdb. Le aree di utilizzo di tempdb comuni includono:
- Tabelle temporanee
- Variabili di tabella
- Parametri con valori di tabella
- Query con piani di query che usano ordinamenti, hash join e spool
Per ulteriori informazioni, vedi tempdb in Azure SQL.
Tutti i database in un pool elastico condividono lo stesso database tempdb. Un utilizzo elevato tempdb dello spazio di un database può influire su altri database nello stesso pool elastico.
Query con maggior utilizzo di variabili di tabella e tabelle temporanee
Usare la query seguente per identificare le query con maggior utilizzo di variabili di tabella e tabelle temporanee:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identificare le transazioni a esecuzione prolungata
Usare la query seguente per identificare le transazioni a esecuzione prolungata. Le transazioni a esecuzione prolungata impediscono la pulizia dell'archivio versioni permanente (PVS). Per altre informazioni, vedere Risolvere i problemi relativi al ripristino accelerato del database.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identificare i problemi di prestazioni di attesa della concessione di memoria
Se il tipo di attesa principale è RESOURCE_SEMAPHORE, potrebbe essere presente un problema di concessione di memoria in attesa in cui le query non possono iniziare l'esecuzione fino a quando non ottengono una concessione di memoria sufficientemente grande.
Determina se un'attesa RESOURCE_SEMAPHORE è una delle attese più frequenti
Usa la query seguente per determinare se un'attesa RESOURCE_SEMAPHORE è una delle attese più frequenti. Sarebbe indicativo anche un rango di tempo di attesa crescente di RESOURCE_SEMAPHORE nella cronologia recente. Per ulteriori informazioni sulla risoluzione dei problemi di attesa delle concessioni di memoria, vedi Risolvere i problemi di prestazioni lente o di memoria insufficiente causati da concessioni di memoria in SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Identifica le istruzioni con utilizzo della memoria elevato
Se noti errori di memoria insufficiente in database SQL di Azure, controlla sys.dm_os_out_of_memory_events. Per ulteriori informazioni, vedi Risolvere i problemi relativi a errori di memoria insufficiente con il database SQL di Azure.
Prima di tutto, modificare lo script seguente per aggiornare i valori rilevanti di start_time e end_time. Poi, usa la query seguente per identificare le istruzioni con utilizzo della memoria elevato:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identificare le 10 concessioni di memoria attive più frequenti
Usare la query seguente per identificare le 10 concessioni di memoria attive più frequenti:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Monitorare le connessioni
È possibile usare la vista sys.dm_exec_connections per recuperare informazioni sulle connessioni stabilite con un database specifico e i dettagli di ogni connessione. Se un database si trova in un pool elastico e se si dispone di autorizzazioni sufficienti, la visualizzazione restituisce l’insieme di connessioni per tutti i database nel pool elastico. Inoltre, la vista sys.dm_exec_sessions è utile durante il recupero di informazioni su tutte le connessioni utente attive e le attività interne.
Visualizza le sessioni correnti
La query seguente recupera informazioni per la connessione e la sessione correnti. Per visualizzare tutte le connessioni e le sessioni, rimuovere la clausola WHERE.
Vengono visualizzate tutte le sessioni in esecuzione nel database solo se si dispone dell'autorizzazione VIEW DATABASE STATE per il database durante l'esecuzione delle visualizzazioni sys.dm_exec_requests e sys.dm_exec_sessions. In caso contrario, sarà possibile visualizzare solo la sessione corrente.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Monitorare le prestazioni delle query
L’esecuzione della query rallentata o prolungata può consumare delle risorse di sistema importanti. In questa sezione viene illustrato come utilizzare le DMV per rilevare alcuni problemi di prestazione delle query comuni usando la DMV sys.dm_exec_query_stats. La vista contiene una riga per ogni istruzione di query nel piano memorizzato nella cache e la durata delle righe è legata al piano stesso. Quando un piano viene rimosso dalla cache, le righe corrispondenti vengono eliminate da questa vista. Se una query non dispone di un piano memorizzato nella cache, ad esempio perché OPTION (RECOMPILE) viene usato, non è presente nei risultati di questa visualizzazione.
Trovare le query principali in base al tempo di CPU
Nell'esempio seguente vengono restituite informazioni sulle prime 15 query classificate in base al tempo medio della CPU per esecuzione. Nell'esempio le query vengono aggregate in base al relativo valore hash, in modo da raggruppare le query logicamente equivalenti in base all'utilizzo di risorse cumulativo.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Monitorare i piani di query per il tempo di CPU cumulativo
Un piano di query inefficiente può anche aumentare il consumo della CPU. L'esempio seguente determina quale query usa la CPU più cumulativa nella cronologia recente.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Monitorare le query bloccate
Le query lente o con esecuzione prolungata possono contribuire al consumo eccessivo delle risorse ed essere la conseguenza di query bloccate. Le cause del blocco possono essere una progettazione povera dell'applicazione, dei piani di query non validi, la mancanza di indici utili e così via.
È possibile utilizzare la vista sys.dm_tran_locks per ottenere informazioni sulle attività di blocco correnti nel database. Per esempi di codice, vedere sys.dm_tran_locks. Per ulteriori informazioni, vedi Comprendere e risolvere i problemi di blocco di Azure SQL.
Monitorare i deadlock
In alcuni casi, due o più query possono bloccarsi a vicenda causando un deadlock.
È possibile creare una traccia degli eventi estesi per acquisire eventi deadlock, quindi trovare query correlate e i relativi piani di esecuzione in Query Store. Per ulteriori informazioni, vedi Analizzare e impedire deadlock in database SQL di Azure, incluso un lab per causare un deadlock in AdventureWorksLT. Ulteriori informazioni su altri tipi in risorse che possono causare un deadlock.
Contenuto correlato
- Introduzione a database SQL di Azure e Istanza gestita di SQL di Azure
- Diagnosticare e risolvere i problemi relativi all'utilizzo elevato della CPU in Database SQL di Azure
- Ottimizzare le applicazioni e i database per le prestazioni nel database SQL di Azure
- Comprendere e risolvere i problemi di blocco di Database SQL di Azure
- Analizzare e impedire deadlock in database SQL di Azure
- Monitorare i carichi di lavoro di Azure SQL con il database watcher (anteprima)