Ottimizzare le applicazioni e i database per le prestazioni nel database SQL di Azure
Si applica a:![]() database SQL di Azure
database SQL di Azure![]() database SQL in Fabric
database SQL in Fabric
Dopo aver identificato un problema di prestazioni riscontrato con database SQL di Azure o il database SQL dell'infrastruttura, questo articolo è progettato per facilitare le attività seguenti:
- Ottimizzare l'applicazione e applicare alcune procedure consigliate che consentono di migliorare le prestazioni.
- Ottimizzare il database modificando gli indici e le query per usare i dati in modo più efficiente.
In questo articolo si presuppone che siano già stati usati i consigli di Advisor per il database e le raccomandazioni per l'ottimizzazione automatica, se applicabile. Si presuppone inoltre che tu abbia già letto le Informazioni generali sul monitoraggio e l’ottimizzazione, Monitoraggio delle prestazioni tramite Query Store e gli articoli correlati alla risoluzione dei problemi relativi alle prestazioni. In questo articolo si presuppone inoltre che il problema di prestazioni non sia correlato all’utilizzo delle risorse della CPU per la cui soluzione basta incrementare le dimensioni di calcolo o il livello di servizio per fornire altre risorse al database.
Nota
Per materiale sussidiario simile in Istanza gestita di SQL di Azure, vedi Ottimizzare applicazioni e database per le prestazioni in Istanza gestita di SQL di Azure.
Ottimizzare l'applicazione
Nel sistema SQL Server tradizionale in locale il processo di pianificazione della capacità iniziale è spesso separato dal processo di esecuzione di un'applicazione in produzione. Vengono acquistate prima di tutto le licenze per hardware e prodotti e l'ottimizzazione delle prestazioni viene eseguita in un secondo momento. Quando usi il Azure SQL, è consigliabile eseguire e ottimizzare al tempo stesso un'applicazione. Il modello di pagamento della capacità su richiesta consente di ottimizzare l'applicazione in modo da usare la quantità minima di risorse necessaria in un momento specifico, invece di effettuare l'overprovisioning dell'hardware in base a ipotesi di piani di crescita futura per un'applicazione, che spesso si rivelano errati.
Alcuni clienti potrebbero decidere di non ottimizzare un'applicazione e scegliere in alternativa di effettuare l'overprovisioning delle risorse hardware. Questo approccio potrebbe risultare valido se non si vuole modificare un'applicazione chiave in un periodo di attività elevata. L'ottimizzazione di un'applicazione può consentire tuttavia di ridurre i requisiti delle risorse e l'importo delle fatture mensili.
Procedure consigliate e antipattern nella progettazione applicazioni per il database SQL di Azure
Anche se i livelli di servizio del database SQL di Azure sono progettati per migliorare la stabilità e la prevedibilità delle prestazioni di un'applicazione, alcune procedure consigliate consentono di ottimizzare l'applicazione in modo da sfruttare al meglio le risorse corrispondenti alle dimensioni di calcolo. Anche se in molte applicazioni è possibile ottenere miglioramenti significativi delle prestazioni semplicemente passando a un livello di servizio o dimensioni di calcolo superiori, questo vantaggio non è assicurato per tutte le applicazioni senza un'ottimizzazione aggiuntiva. Per ottenere un aumento delle prestazioni, prendere in considerazione operazioni di ottimizzazione aggiuntive per le applicazioni con queste caratteristiche:
Applicazioni con prestazioni ridotte a causa di un comportamento "eccessivamente comunicativo"
Le applicazioni con un livello di comunicazioni elevato eseguono un numero eccessivo di operazioni di accesso ai dati, sensibili alla latenza di rete. Potrebbe essere necessario modificare questi tipi di applicazioni, in modo da ridurre il numero di operazioni di accesso ai dati nel database. È ad esempio possibile migliorare le prestazioni dell'applicazione usando tecniche come l'invio in batch di query ad hoc o lo spostamento delle query in stored procedure. Per altre informazioni, vedere Invio di query in batch.
Database con un carico di lavoro elevato che non possono essere supportati da una singola macchina virtuale intera
I database che superano le risorse delle dimensioni di calcolo Premium più elevate potrebbero trarre vantaggio dall'aumento del numero di istanze del carico di lavoro. Per altre informazioni, vedere Partizionamento orizzontale tra database e Partizionamento funzionale.
Applicazioni con query non ottimali
Le applicazioni con query non ottimizzate correttamente potrebbero non ottenere vantaggi da dimensioni di calcolo superiori. Tra queste sono incluse query prive della clausola WHERE, con indici mancanti o con statistiche obsolete. Queste applicazioni possono trarre vantaggio dalle tecniche standard di ottimizzazione delle prestazioni delle query. Per altre informazioni, vedere Indici mancanti e Hint/Ottimizzazione di query.
Applicazioni con progettazione di accesso ai dati non ottimale
Le applicazioni con problemi intrinseci di concorrenza per l'accesso ai dati, ad esempio il deadlock, potrebbero non trarre vantaggio da dimensioni di calcolo superiori. Provare a ridurre i round trip nel database memorizzando nella cache i dati sul lato client con il servizio di caching di Azure o un'altra tecnologia di memorizzazione nella cache. Vedere Memorizzazione nella cache a livello di applicazione.
Per prevenire la ricorrenza dei deadlock nel database SQL di Azure, vedere Analizzare e prevenire i deadlock nel database SQL di Azure e nel database SQL di Fabric.
Ottimizzare il database
Questa sezione illustra alcune tecniche che puoi usare per ottimizzare il database in modo da ottenere le prestazioni migliori per l'applicazione ed eseguirla alle dimensioni di calcolo più basse possibile. Alcune di queste tecniche corrispondono alle tradizionali procedure consigliate di ottimizzazione di SQL Server, ma altre sono specifiche del database SQL di Azure. In alcuni casi è possibile esaminare le risorse utilizzate per un database, in modo da individuare aree che richiedono ottimizzazione aggiuntiva e da estendere le tecniche tradizionali di SQL Server per l'uso nel database SQL di Azure.
Identificare e aggiungere gli indici mancanti
Un problema comune nelle prestazioni del database OLTP è correlato alla progettazione fisica del database. Spesso gli schemi di database vengono progettati e forniti senza verificare la scala (nel caricamento o nel volume di dati). Le prestazioni di un piano di query possono essere accettabili su scala ridotta, ma potrebbero purtroppo peggiorare notevolmente in caso di volumi elevati di dati a livello di produzione. L'origine più comune di questo problema è legata alla mancanza di indici adatti per soddisfare i filtri o altre restrizioni in una query. La mancanza di indici si manifesta spesso con una scansione di tabella quando potrebbe essere sufficiente una ricerca dell'indice.
In questo esempio il piano di query selezionato usa un'analisi quando invece sarebbe sufficiente una ricerca:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
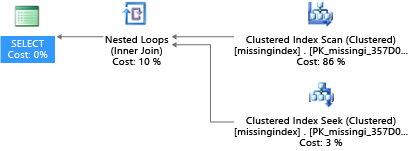
Il database SQL di Azure può consentire di trovare e risolvere condizioni comuni di indici mancanti. Le viste a gestione dinamica integrate nel database SQL di Azure esaminano le compilazioni di query in cui un indice ridurrebbe in modo significativo il costo stimato per l'esecuzione di una query. Durante l'esecuzione di query, il motore di database tiene traccia della frequenza con cui viene eseguito ogni piano di query e del divario stimato tra il piano di query eseguito e quello previsto in presenza dell'indice. È possibile usare queste viste a gestione dinamica per ipotizzare rapidamente quali modifiche alla progettazione fisica del database potrebbero migliorare il costo complessivo del carico di lavoro per un database e il rispettivo carico di lavoro reale.
È possibile usare questa query per valutare gli indici potenzialmente mancanti:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
In questo esempio la query ha restituito questo suggerimento:
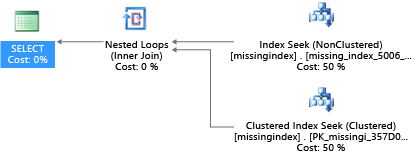
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Dopo la creazione, la stessa istruzione SELECT seleziona un piano diverso, che usa una ricerca invece di un'analisi, e quindi esegue il piano in modo più efficiente:
L'aspetto chiave è che la capacità di I/O di un sistema apposito condiviso è più limitata di un computer server dedicato. Esiste un vantaggio nella riduzione dell'I/O non necessario, che consente di sfruttare al massimo il sistema nelle risorse delle dimensioni di calcolo dei livelli di servizio. Le opzioni appropriate di progettazione fisica del database possono migliorare notevolmente la latenza delle singole query, la velocità effettiva di richieste simultanee gestibili per unità di scala e ridurre i costi necessari per soddisfare la query.
Per altre informazioni sull’ottimizzazione degli indici usando richieste di indici mancanti, vedi Ottimizzare gli indici non cluster con suggerimenti di indici mancanti.
Hint/Ottimizzazione di query
Query Optimizer nel database SQL di Azure è simile a Query Optimizer tradizionale di SQL Server. La maggior parte delle procedure consigliate per ottimizzare le query e per comprendere i motivi delle limitazioni del modello per Query Optimizer si applica anche al database SQL di Azure. Se si ottimizzano query nel database SQL di Azure, si potrebbe ottenere il vantaggio aggiuntivo della riduzione delle richieste di risorsa aggregate. L'applicazione potrebbe essere eseguita a un costo inferiore rispetto a un'applicazione equivalente non ottimizzata, perché potrebbe usare dimensioni di calcolo inferiori.
Un esempio comune in SQL Server e applicabile anche al database SQL di Azure è costituito dal modo in cui Query Optimizer "analizza" i parametri. Durante la compilazione, Query Optimizer valuta il valore corrente di un parametro per determinare se può generare un piano di query più idoneo. Anche se questa strategia può comportare spesso la creazione di un piano di query significativamente più veloce rispetto a un piano compilato senza valori di parametri noti, non funziona attualmente in modo perfetto nel database SQL di Azure. (Una nuova caratteristica di prestazioni intelligenti delle query introdotta con SQL Server 2022 denominata Ottimizzazione del piano di importanza dei parametri tratta lo scenario in cui un singolo piano memorizzato nella cache per una query con parametri non è ottimale per tutti i possibili valori dei parametri in ingresso. Attualmente, l'ottimizzazione del piano di importanza dei parametri non è disponibile in database SQL di Azure.)
Il motore di motore di database include gli hint per la query (direttive) per consentire di specificare l’intento più deliberatamente e sostituire il comportamento predefinito per l'analisi dei parametri. Puoi scegliere di usare hint quando il comportamento predefinito è imperfetto per un carico di lavoro specifico.
L'esempio successivo illustra il modo in cui Query Processor può generare un piano non ottimale per i requisiti di prestazioni e risorse. L'esempio mostra anche che l'uso di un hint per la query può ridurre il tempo di esecuzione delle query e i requisiti delle risorse per il database:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Il codice di configurazione crea dati asimmetrici (o distribuiti in modo irregolare) nella tabella t1. Il piano di query ottimale varia in base al parametro selezionato. Il comportamento di memorizzazione nella cache del piano non esegue sempre la ricompilazione della query in base al valore di parametro più comune, purtroppo. È quindi possibile che un piano non ottimale venga memorizzato nella cache e usato per molti valori, anche se un piano diverso potrebbe costituire mediamente una scelta migliore. Il piano di query crea quindi due stored procedure identiche, ad eccezione del fatto che una include un hint di query speciale.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
È consigliabile attendere almeno 10 minuti prima di iniziare la parte 2 dell'esempio, in modo che i risultati siano distinti nei dati di telemetria risultanti.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Ogni parte di questo esempio prova a eseguire 1.000 volte un'istruzione INSERT con parametri, per generare un carico sufficiente utilizzabile in un set di dati di test. Durante l'esecuzione di stored procedure, Query Processor esamina il valore del parametro passato alla procedura durante la prima compilazione ("analisi" dei parametri). Query Processor memorizza nella cache il piano risultante e lo usa per le chiamate successive, anche se il valore del parametro è diverso. È possibile che non venga usato il piano ottimale in tutti i casi. È a volte necessario consentire a Query Optimizer la selezione di un piano che sia migliore per la metà dei casi anziché per il caso specifico quando la query viene compilata per la prima volta. In questo esempio, il piano iniziale genera un piano di "analisi" che legge tutte le righe per cercare tutti i valori corrispondenti al parametro:

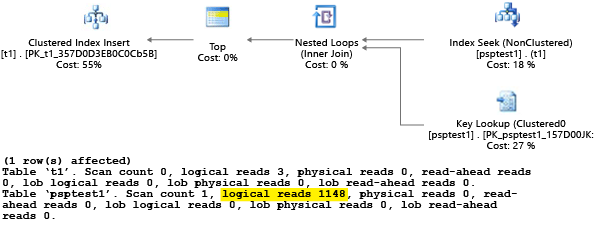
Poiché la procedura è stata eseguita con il valore 1, il piano risultante è ottimale per il valore 1, ma non per tutti gli altri valori nella tabella. È probabile che il risultato non sia quello che si sceglierebbe se si potesse selezionare casualmente ogni piano, perché presenta prestazioni inferiori e usa una quantità maggiore di risorse.
Se si esegue il test con SET STATISTICS IO impostato su ON, le operazioni di analisi logica in questo esempio vengono eseguite in background. Come si può notare, 1.148 operazioni di lettura vengono eseguite dal piano e ciò è poco efficiente, se il caso medio consiste nel restituire solo una riga:

La seconda parte dell'esempio usa un hint per la query per indicare a Query Optimizer di usare un valore specifico durante il processo di compilazione. In questo caso impone a Query Processor di ignorare il valore passato come parametro e di presupporre invece UNKNOWN. Ciò fa riferimento a un valore con frequenza media nella tabella, ignorando eventuali asimmetrie. Il piano risultante è un piano basato su ricerca, più veloce e con un minore impiego medio di risorse rispetto al piano della parte 1 dell'esempio:
Puoi visualizzare l'effetto nella visualizzazione di sistema sys.resource_stats, specifica per database SQL di Azure. Si verifica un ritardo dal momento in cui si esegue il test e quando i dati popolano la tabella. Per questo esempio, la parte 1 è stata eseguita durante l'intervallo di tempo 22:25:00 e la parte 2 nell'intervallo di tempo 22:35:00. Nell'intervallo di tempo precedente sono state usate più risorse rispetto a quello successivo, in seguito ai miglioramenti di efficienza di piano.
SELECT TOP 1000 *
FROM sys.resource_stats
WHERE database_name = 'resource1'
ORDER BY start_time DESC

Nota
Anche se il volume in questo esempio è intenzionalmente ridotto, l'effetto dei parametri non ottimali può essere significativo, in particolare nei database di dimensioni più grandi. La differenza, nei casi estremi, può essere di alcuni secondi per i casi veloci e di alcune ore per i casi lenti.
Esaminando sys.resource_stats puoi determinare se la risorsa usata per un test usa una quantità di risorse superiore o inferiore rispetto a un altro test. Quando confronti i dati, separa gli intervalli di test in modo che non rientrino nella stessa finestra di 5 minuti nella visualizzazione sys.resource_stats. L'obiettivo dell'esercizio consiste nel ridurre la quantità totale di risorse usate e non di ridurre le risorse di picco. In genere, anche con l'ottimizzazione di una parte di codice per la latenza viene ridotto il consumo di risorse. Assicurarsi che le modifiche apportate a un'applicazione siano necessarie e che non influiscano negativamente sull'esperienza dei clienti che potrebbero usare hint di query nell'applicazione.
Se un carico di lavoro include un set di query ripetute, è spesso consigliabile acquisire e confermare la validità delle scelte del piano perché determinerà l'unità di dimensioni minima delle risorse per ospitare il database. Dopo la convalida, esaminare di nuovo occasionalmente i piani per accertarsi che siano ancora ottimali. Per altre informazioni, vedere Hint per la query (Transact-SQL).
Ottimizzare la connettività e il pool di connessioni
Per ridurre il sovraccarico della creazione di connessioni frequenti all'applicazione nel database SQL di Azure, il pool di connessioni è disponibile nei provider di dati. Il pool di connessioni è abilitato in ADO.NET per impostazione predefinita, ad esempio. Il pool di connessioni consente a un'applicazione di riutilizzare le connessioni e ridurre al minimo il sovraccarico di stabilire nuove connessioni.
Il pool di connessioni può migliorare la velocità effettiva, ridurre la latenza e migliorare le prestazioni complessive dei carichi di lavoro del database. Quando si usano meccanismi di autenticazione predefiniti, i driver gestiscono internamente i token e il rinnovo dei token. Tenere presente queste procedure consigliate:
Configurare le impostazioni del pool di connessioni, ad esempio connessioni massime, timeout di connessione o durata della connessione, in base ai requisiti di concorrenza e latenza del carico di lavoro. Per altre informazioni, vedere la documentazione del provider di dati.
Le applicazioni cloud devono implementare logica di ritentativo per gestire in modo adeguato i fallimenti di connettività temporanei. Scopri di più su come progettare la logica di ritentare per gli errori temporanei .
I meccanismi di autenticazione basati su token, ad esempio l'autenticazione di Microsoft Entra ID, devono generare nuovi token alla scadenza. Le connessioni fisiche nei pool con token scaduti devono essere chiuse e devono essere create nuove connessioni fisiche. Per ottimizzare il tempo necessario per creare connessioni fisiche che usano l'autenticazione basata su token:
-
Implementare il rinnovo proattivo e asincrono dei token: La prima connessione
Open()per ottenere un nuovo token potrebbe richiedere un breve ritardo per ottenere un nuovo token ID Entra. Per molte applicazioni, questo ritardo è trascurabile e non è necessaria alcuna riconfigurazione. Se si sceglie di fare in modo che la propria applicazione gestisca i token, ottenere nuovi token di accesso prima della scadenza e assicurarsi che vengano memorizzati nella cache. Ciò può ridurre al minimo il ritardo dell'acquisizione dei token durante la creazione della connessione fisica. L'esecuzione del rinnovo del token sposta in modo proattivo il breve ritardo in un processo non utente. - Regolare la durata dei token:Configurare i criteri di scadenza dei token in Microsoft Entra ID per avere almeno la durata prevista delle connessioni logiche nell'applicazione. Anche se non è necessario, la regolazione della scadenza del token consente di bilanciare la sicurezza con il sovraccarico delle prestazioni della ricreazione delle connessioni fisiche.
-
Implementare il rinnovo proattivo e asincrono dei token: La prima connessione
Monitorare il database SQL di Azure le prestazioni di connessione e l'utilizzo delle risorse per identificare i colli di bottiglia, ad esempio connessioni inattive eccessive o limiti di pool insufficienti e modificare le configurazioni di conseguenza. Usare i log di Microsoft Entra ID per tenere traccia degli errori di scadenza dei token e assicurarsi che le scadenze dei token siano configurate in modo appropriato. È consigliato utilizzare Database Watcher o Azure Monitor, dove applicabile.
Procedure consigliate per architetture di database di dimensioni molto estese in database SQL di Azure
Prima del rilascio del livello di servizio Hyperscale per i database singoli nel database SQL di Azure, i clienti potevano incontrare limiti di capacità per i singoli database. Anche se i pool elastici Hyperscale offrono limiti di archiviazione significativamente superiori, i pool elastici e i database in pool in altri livelli di servizio potrebbero comunque essere vincolati da tali limiti di capacità di archiviazione nei livelli di servizio non Hyperscale.
Le due sezioni seguenti illustrano due opzioni per risolvere i problemi relativi ai database di dimensioni molto estese in database SQL di Azure quando non puoi usare il livello di servizio Hyperscale.
Nota
I pool elastici non sono disponibili per Istanza gestita di SQL di Azure, istanze di SQL Server in locale, SQL Server in VM di Azure o Azure Synapse Analytics.
Partizionamento orizzontale tra database
Poiché il database SQL di Azure viene eseguito in hardware apposito, i limiti della capacità per un database singolo sono inferiori a quelli per un'installazione locale tradizionale di SQL Server. Alcuni clienti usano tecniche di partizionamento orizzontale per estendere le operazioni in più database quando non rientrano nei limiti relativi a un database singolo nel database SQL di Azure. La maggior parte dei clienti che usa le tecniche di partizionamento orizzontale nel database SQL di Azure suddivide i dati di una singola dimensione in più database. Per questo approccio è necessario comprendere che le applicazioni OLTP eseguono spesso transazioni applicabili a una riga o a un piccolo gruppo di righe nello schema.
Nota
Il database SQL di Azure offre ora un catalogo per semplificare il partizionamento orizzontale. Per altre informazioni, vedere Panoramica della libreria client dei database elastici.
Se, ad esempio, un database include il nome del cliente, l'ordine e i dettagli dell'ordine (come illustrato nel database AdventureWorks), puoi dividere questi dati in più database raggruppando un cliente con l'ordine correlato e con le informazioni dettagliate sull'ordine. È possibile assicurare che i dati del cliente rimangano in un singolo database. L'applicazione suddividerebbe i diversi clienti tra database, estendendo di fatto il carico tra più database. Con il partizionamento orizzontale, i clienti possono evitare di raggiungere il limite massimo delle dimensioni del database, ma anche il database SQL di Azure può elaborare carichi di lavoro notevolmente maggiori rispetto ai limiti corrispondenti alle diverse dimensioni di calcolo, a condizione che ogni singolo database rientri nel relativo limite del livello di servizio.
Anche se il partizionamento orizzontale del database non riduce la capacità aggregata delle risorse per una soluzione, è notevolmente efficace nel supportare soluzioni di dimensioni molto elevate distribuite in più database. Ogni database può essere eseguito a dimensioni di calcolo diverse per supportare database "efficaci" di dimensioni molto grandi con requisiti molto elevati a livello di risorse.
Partizionamento funzionale
Gli utenti combinano spesso molte funzioni all'interno di un singolo database. Se un'applicazione include ad esempio la logica per gestire l'inventario di un negozio, è possibile che quel database includa la logica associata all'inventario, il rilevamento degli ordini di acquisto, le stored procedure e le viste indicizzate o materializzate mediante le quali sono stati gestiti i report di fine mese. Questa tecnica semplifica l'amministrazione del database per operazioni quali il backup, ma richiede anche il ridimensionamento dell'hardware per gestire il carico massimo in tutte le funzioni di un'applicazione.
Se si usa un'architettura con aumento del numero di istanze nel database SQL di Azure, è consigliabile suddividere le diverse funzioni di un'applicazione in diversi database. Se usi questa tecnica, ogni applicazione viene ridimensionata in modo indipendente. Quando un'applicazione viene usata con maggiore frequenza e il carico nel relativo database aumenta, l'amministratore può scegliere dimensioni di calcolo indipendenti per ogni funzione in un'applicazione. Nei limiti, questa architettura fa sì che le dimensioni di un'applicazione diventino più grandi di quelle gestibili da una singola macchina apposita, perché il carico viene distribuito in più macchine.
Invio di query in batch
Per le applicazioni che accedono ai dati con un uso frequente ed elevato di query ad hoc, gran parte del tempo di risposta viene speso nelle comunicazioni di rete tra il livello applicazione e il livello di database. Anche quando l'applicazione e il database risiedono nello stesso data center, la latenza di rete tra questi due elementi potrebbe essere aumentata per un numero grande di operazioni di accesso ai dati. Per ridurre i round trip di rete per le operazioni di accesso ai dati, prendere in considerazione l'uso dell'opzione per l'invio in batch delle query ad hoc o per la compilazione delle query come stored procedure. L'invio in batch delle query ad hoc consente di inviare più query come un unico grande batch in una singola operazione al database. La compilazione di query ad hoc in stored procedure può produrre lo stesso risultato dell'invio in batch. L'uso di una stored procedure offre inoltre il vantaggio di aumentare le opportunità di memorizzare nella cache i piani di query nel database per usare nuovamente la stored procedure.
Alcune applicazioni comportano un utilizzo elevato di scrittura. È a volte possibile ridurre il carico totale di I/O in un database considerando la modalità di invio in batch delle scritture. Questa operazione è spesso semplice come l'uso di transazioni esplicite anziché di transazioni commit automatico in stored procedure e batch ad hoc. Per una valutazione delle differenti tecniche che puoi usare, vedi Tecniche di esecuzione in batch per applicazioni di database in Azure. Provare a usare il proprio carico di lavoro per individuare il modello ottimale per l'invio in batch. Assicurarsi di comprendere che un modello potrebbe offrire garanzie di coerenza transazionale leggermente diverse. Per trovare il carico di lavoro ottimale che consenta un uso delle risorse minimo è necessario individuare la corretta combinazione di compromessi tra prestazioni e coerenza.
Memorizzazione nella cache a livello di applicazione
Alcune applicazioni di database contengono carichi di lavoro con intensa attività di lettura. I livelli di memorizzazione nella cache possono consentire di ridurre il carico nel database e di ridurre le dimensioni di calcolo necessarie per supportare un database usando il database SQL di Azure. La cache di Azure per Redis, in caso di carico di lavoro con intensa attività di lettura, può consentire di leggere i dati una volta (o forse una volta per macchina di livello applicazione, a seconda della relativa configurazione) e di archiviare i dati al di fuori del database. In questo modo è possibile ridurre il carico del database (CPU e I/O letti), ma vi sarà un impatto sulla coerenza transazionale poiché i dati letti dalla cache potrebbero non essere sincronizzati con i dati nel database. Anche se in molte applicazioni è accettabile un livello di incoerenza, ciò non rappresenta una soluzione valida per tutti i carichi di lavoro. È necessario conoscere bene tutti i requisiti delle applicazioni prima di implementare una strategia di caching a livello di applicazione.
Ottenere suggerimenti per la configurazione e la progettazione
Se usi database SQL di Azure, puoi eseguire uno script T-SQL open source per migliorare la configurazione e la progettazione del database in database SQL di Azure. Lo script analizza il database su richiesta e fornisce suggerimenti per migliorare le prestazioni e il funzionamento del database. Alcuni suggerimenti indicano modifiche operative e di configurazione in base alle procedure consigliate, mentre altri suggerimenti consigliano modifiche di progettazione adatte per il carico di lavoro, ad esempio l'abilitazione delle caratteristiche avanzate del motore di database.
Per altre informazioni sullo script e sulle attività iniziali, visita la pagina wiki Suggerimenti per Azure SQL.
Per rimanere aggiornati sulle funzionalità e sugli aggiornamenti più recenti per database SQL di Azure, vedere Novità di database SQL di Azure
Contenuto correlato
- Monitorare i database SQL di Azure
- Analisi delle prestazioni delle query per Azure SQL Database
- Monitoraggio delle prestazioni tramite viste a gestione dinamica
- osservatore del database
- diagnosticare e risolvere i problemi di utilizzo elevato della CPU nel database SQL di Azure
- Ottimizzare gli indici non cluster con suggerimenti di indici mancanti
- Video: Procedure consigliate per il caricamento dei dati in database SQL di Azure