Esercitazione: Analizzare i dati nei log di Monitoraggio di Azure usando un notebook
I notebook sono ambienti integrati che consentono di creare e condividere documenti con codice live, equazioni, visualizzazioni e testo. L'integrazione di un notebook con un'area di lavoro di Log Analytics consente di creare un processo in più passaggi che esegue il codice in ogni passaggio in base ai risultati del passaggio precedente. È possibile usare questi processi semplificati per creare pipeline di Machine Learning, strumenti di analisi avanzati, guide alla risoluzione dei problemi (TSG) per esigenze di supporto e altro ancora.
L'integrazione di un notebook con un'area di lavoro di Log Analytics consente anche di:
- Eseguire query KQL e codice personalizzato in qualsiasi linguaggio.
- Introdurre nuove funzionalità di analisi e visualizzazione, ad esempio nuovi modelli di Machine Learning, sequenze temporali personalizzate e alberi di elaborazione.
- Integrare set di dati all'esterno di Log di Monitoraggio di Azure, ad esempio set di dati locali.
- Sfruttare i vantaggi di un aumento dei limiti del servizio usando i limiti dell'API query rispetto al portale di Azure.
In questa esercitazione apprenderai a:
- Integrare un notebook con l'area di lavoro di Log Analytics usando la libreria client di Query di Monitoraggio di Azure e la libreria client di Identità di Azure
- Esplorare e visualizzare i dati dall'area di lavoro di Log Analytics in un notebook
- Inserire dati dal notebook in una tabella personalizzata nell'area di lavoro di Log Analytics (facoltativo)
Per un esempio di come eseguire compilare una pipeline di Machine Learning per analizzare i dati in Log di Monitoraggio di Azure usando un notebook, vedere questo notebook di esempio: Rilevare le anomalie in Log di Monitoraggio di Azure usando tecniche di Machine Learning.
Suggerimento
Per ovviare alle limitazioni correlate all'API, suddividere le query di dimensioni maggiori in più query più piccole.
Prerequisiti
Per eseguire questa esercitazione, è necessario avere:
Un'area di lavoro di Azure Machine Learning con istanza di ambiente di calcolo CPU con:
- Un notebook.
- Un kernel impostato su Python 3.8 o versione successiva.
I ruoli e le autorizzazioni seguenti:
In Log di Monitoraggio di Azure: il ruolo Collaboratore di Log Analytics per leggere i dati da e inviare dati all'area di lavoro Log Analytics. Per altre informazioni, vedere Gestire l'accesso a un'area di lavoro Log Analytics.
In Azure Machine Learning:
- Ruolo Proprietario o Collaboratore a livello di gruppo di risorse per creare una nuova area di lavoro di Azure Machine Learning, se necessario.
- Un ruolo Collaboratore nell'area di lavoro di Azure Machine Learning in cui si esegue il notebook.
Per altre informazioni, vedere Gestire l'accesso a un'area di lavoro di Azure Machine Learning.
Strumenti e notebook
In questa esercitazione si usano questi strumenti:
| Strumento | Descrizione |
|---|---|
| Libreria client di Query di Monitoraggio di Azure | Consente di eseguire query di sola lettura sui dati in Log di Monitoraggio di Azure. |
| Libreria client di Identità di Azure | Consente ai client Azure SDK di eseguire l'autenticazione con Microsoft Entra ID. |
| Libreria client di Inserimento di Monitoraggio di Azure | Consente di inviare log personalizzati a Monitoraggio di Azure usando l'API di inserimento dei log. Necessario per inserire dati analizzati in una tabella personalizzata nell'area di lavoro di Log Analytics (facoltativo) |
| Regola di raccolta dati, endpoint di raccolta dati e un' applicazione registrata | Necessario per inserire dati analizzati in una tabella personalizzata nell'area di lavoro di Log Analytics (facoltativo) |
Altre librerie di query che è possibile usare includono:
- La libreria Kqlmagic consente di eseguire query KQL direttamente all'interno di un notebook nello stesso modo in cui si eseguono query KQL dallo strumento Log Analytics.
- La libreria MSTICPY fornisce query basate su modelli che richiamano le funzionalità predefinite della serie temporale KQL e di Machine Learning e fornisce strumenti di visualizzazione avanzati e analisi dei dati nell'area di lavoro di Log Analytics.
Altre esperienze dei notebook Microsoft per l'analisi avanzata includono:
1. Integrare l'area di lavoro di Log Analytics con il notebook
Configurare il notebook per eseguire query nell'area di lavoro di Log Analytics:
Installare le librerie client di inserimento di Monitoraggio di Azure, Identità di Azure e Monitoraggio di Azure insieme alla libreria di analisi dei dati Pandas, libreria di visualizzazione Plotly:
import sys !{sys.executable} -m pip install --upgrade azure-monitor-query azure-identity azure-monitor-ingestion !{sys.executable} -m pip install --upgrade pandas plotlyImpostare la variabile
LOGS_WORKSPACE_IDseguente sull'ID dell'area di lavoro di Log Analytics. La variabile è attualmente impostata per l'uso dell'area di lavoro Demo di Monitoraggio di Azure, che è possibile usare per eseguire una dimostrazione del notebook.LOGS_WORKSPACE_ID = "DEMO_WORKSPACE"Configurare
LogsQueryClientper autenticare ed eseguire query su Log di Monitoraggio di Azure.Questo codice configura
LogsQueryClientper l'autenticazione tramiteDefaultAzureCredential:from azure.core.credentials import AzureKeyCredential from azure.core.pipeline.policies import AzureKeyCredentialPolicy from azure.identity import DefaultAzureCredential from azure.monitor.query import LogsQueryClient if LOGS_WORKSPACE_ID == "DEMO_WORKSPACE": credential = AzureKeyCredential("DEMO_KEY") authentication_policy = AzureKeyCredentialPolicy(name="X-Api-Key", credential=credential) else: credential = DefaultAzureCredential() authentication_policy = None logs_query_client = LogsQueryClient(credential, authentication_policy=authentication_policy)LogsQueryClientin genere supporta solo l'autenticazione con le credenziali del token Microsoft Entra. È tuttavia possibile passare criteri di autenticazione personalizzati per abilitare l'uso delle chiavi API. In questo modo il client può eseguire query sull'area di lavoro demo. La disponibilità e l'accesso a questa area di lavoro demo sono soggetti a modifiche, quindi è consigliabile usare la propria area di lavoro di Log Analytics.Definire una funzione helper, denominata
query_logs_workspace, per eseguire una determinata query nell'area di lavoro di Log Analytics e restituire i risultati come DataFrame Pandas.import pandas as pd import plotly.express as px from azure.monitor.query import LogsQueryStatus from azure.core.exceptions import HttpResponseError def query_logs_workspace(query): try: response = logs_query_client.query_workspace(LOGS_WORKSPACE_ID, query, timespan=None) if response.status == LogsQueryStatus.PARTIAL: error = response.partial_error data = response.partial_data print(error.message) elif response.status == LogsQueryStatus.SUCCESS: data = response.tables for table in data: my_data = pd.DataFrame(data=table.rows, columns=table.columns) except HttpResponseError as err: print("something fatal happened") print (err) return my_data
2. Esplorare e visualizzare i dati dall'area di lavoro di Log Analytics nel notebook
Verranno ora esaminati alcuni dati nell'area di lavoro eseguendo una query dal notebook:
Questa query controlla la quantità di dati (in megabyte) inseriti in ognuna delle tabelle (tipi di dati) nell'area di lavoro di Log Analytics ogni ora nell'ultima settimana:
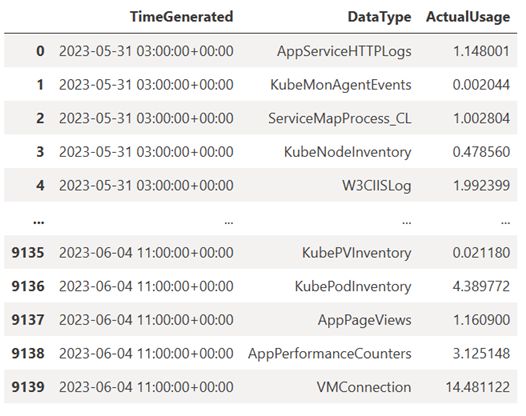
TABLE = "Usage" QUERY = f""" let starttime = 7d; // Start date for the time series, counting back from the current date let endtime = 0d; // today {TABLE} | project TimeGenerated, DataType, Quantity | where TimeGenerated between (ago(starttime)..ago(endtime)) | summarize ActualUsage=sum(Quantity) by TimeGenerated=bin(TimeGenerated, 1h), DataType """ df = query_logs_workspace(QUERY) display(df)Il Dataframe risultante mostra l'inserimento orario in ognuna delle tabelle nell'area di lavoro di Log Analytics:
È ora possibile visualizzare i dati come grafico che mostra l'utilizzo orario per vari tipi di dati nel tempo, in base al Dataframe Pandas:
df = df.sort_values(by="TimeGenerated") graph = px.line(df, x='TimeGenerated', y="ActualUsage", color='DataType', title="Usage in the last week - All data types") graph.show()Il grafico risultante è simile al seguente:
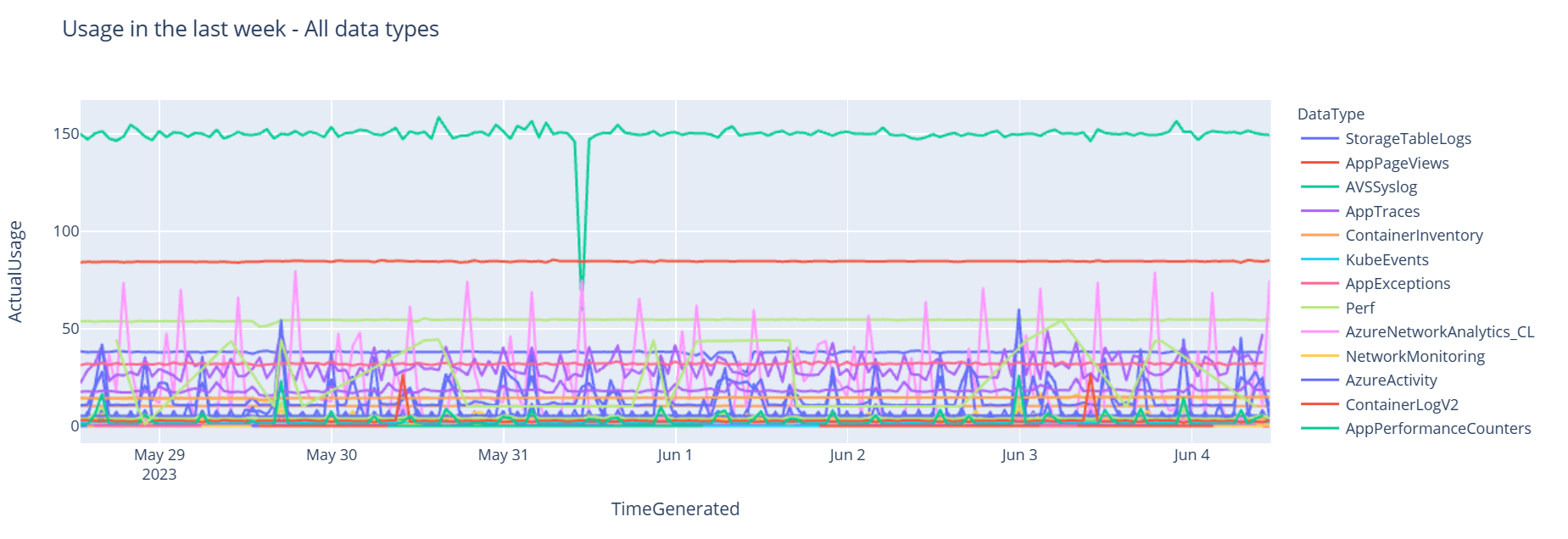
I dati di log dell'area di lavoro di Log Analytics sono stati sottoposti a query e visualizzati correttamente nel notebook.

3. Analizzare i dati
Come esempio semplice, si prendano le prime cinque righe:
analyzed_df = df.head(5)
Per un esempio di come implementare tecniche di Machine Learning per analizzare i dati in Log di Monitoraggio di Azure, vedere questo notebook di esempio: Rilevare le anomalie in Log di Monitoraggio di Azure usando tecniche di Machine Learning.
4. Inserire dati analizzati in una tabella personalizzata nell'area di lavoro di Log Analytics (facoltativo)
Inviare i risultati dell'analisi a una tabella personalizzata nell'area di lavoro di Log Analytics per attivare gli avvisi o renderli disponibili per un'ulteriore analisi.
Per inviare dati all'area di lavoro di Log Analytics, è necessaria una tabella personalizzata, un endpoint di raccolta dati, una regola di raccolta dati e un'applicazione Microsoft Entra registrata con l'autorizzazione per usare la regola di raccolta dati, come illustrato in Esercitazione: Inviare dati a Log di Monitoraggio di Azure con l'API di inserimento dei log (portale di Azure).
Quando si crea la tabella personalizzata:
Caricare questo file di esempio per definire lo schema della tabella:
[ { "TimeGenerated": "2023-03-19T19:56:43.7447391Z", "ActualUsage": 40.1, "DataType": "AzureDiagnostics" } ]
Definire le costanti necessarie per l'API di inserimento log:
os.environ['AZURE_TENANT_ID'] = "<Tenant ID>"; #ID of the tenant where the data collection endpoint resides os.environ['AZURE_CLIENT_ID'] = "<Application ID>"; #Application ID to which you granted permissions to your data collection rule os.environ['AZURE_CLIENT_SECRET'] = "<Client secret>"; #Secret created for the application os.environ['LOGS_DCR_STREAM_NAME'] = "<Custom stream name>" ##Name of the custom stream from the data collection rule os.environ['LOGS_DCR_RULE_ID'] = "<Data collection rule immutableId>" # immutableId of your data collection rule os.environ['DATA_COLLECTION_ENDPOINT'] = "<Logs ingestion URL of your endpoint>" # URL that looks like this: https://xxxx.ingest.monitor.azure.comInserire i dati nella tabella personalizzata nell'area di lavoro di Log Analytics:
from azure.core.exceptions import HttpResponseError from azure.identity import ClientSecretCredential from azure.monitor.ingestion import LogsIngestionClient import json credential = ClientSecretCredential( tenant_id=AZURE_TENANT_ID, client_id=AZURE_CLIENT_ID, client_secret=AZURE_CLIENT_SECRET ) client = LogsIngestionClient(endpoint=DATA_COLLECTION_ENDPOINT, credential=credential, logging_enable=True) body = json.loads(analyzed_df.to_json(orient='records', date_format='iso')) try: response = client.upload(rule_id=LOGS_DCR_RULE_ID, stream_name=LOGS_DCR_STREAM_NAME, logs=body) print("Upload request accepted") except HttpResponseError as e: print(f"Upload failed: {e}")Nota
Quando si crea una tabella nell'area di lavoro di Log Analytics, la visualizzazione dei dati inseriti nella tabella può richiedere fino a 15 minuti.
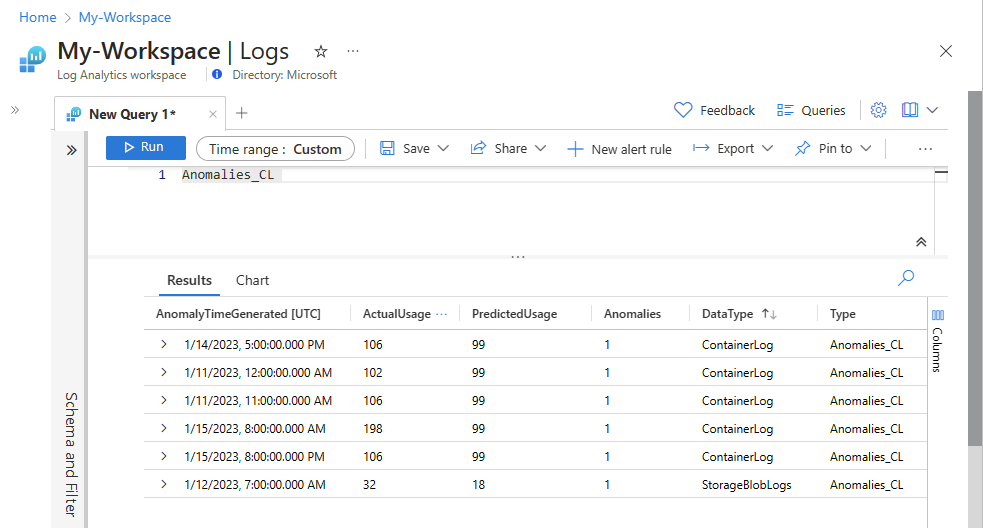
Verificare che i dati siano ora visualizzati nella tabella personalizzata.

Passaggi successivi
Altre informazioni su come: