Esercitazione: Rilevare e analizzare le anomalie usando le funzionalità di Machine Learning KQL in Monitoraggio di Azure
Il Linguaggio di query Kusto (KQL) include operatori di Machine Learning, funzioni e plug-in per l'analisi delle serie temporali, il rilevamento anomalie, la previsione e l'analisi della causa radice. Usare queste funzionalità KQL per eseguire analisi avanzate dei dati in Monitoraggio di Azure senza il sovraccarico dell'esportazione dei dati in strumenti di Machine Learning esterni.
In questa esercitazione apprenderai a:
- Creare una serie temporale
- Identificare le anomalie in una serie temporale
- Modificare le impostazioni di rilevamento anomalie per perfezionare i risultati
- Analizzare la causa radice delle anomalie
Nota
Questa esercitazione fornisce collegamenti a un ambiente demo di Log Analytics in cui è possibile eseguire gli esempi di query KQL. I dati nell'ambiente demo sono dinamici, quindi i risultati della query non corrispondono ai risultati della query mostrati in questo articolo. Tuttavia, è possibile implementare le stesse query e entità KQL nel proprio ambiente e tutti gli strumenti di Monitoraggio di Azure che usano KQL.
Prerequisiti
- Un account Azure con una sottoscrizione attiva. Creare un account gratuitamente.
- Un'area di lavoro con dati di log.
Autorizzazioni obbligatorie
Occorrono autorizzazioni Microsoft.OperationalInsights/workspaces/query/*/read per le aree di lavoro Log Analytics su cui si esegue la query, ad esempio le autorizzazioni fornite dal ruolo predefinito Lettore di Log Analytics.
Creare una serie temporale
Usare l'operatore make-series KQL per creare una serie temporale.
Si creerà una serie temporale basata sui log nella tabella Utilizzo, che contiene informazioni sulla quantità di dati inseriti ogni ora in un'area di lavoro, inclusi i dati fatturabili e non fatturabili.
Questa query usa make-series per creare un grafico della quantità totale di dati fatturabili inseriti da ogni tabella nell'area di lavoro ogni giorno, negli ultimi 21 giorni:
Fare clic per eseguire la query
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
Nel grafico risultante è possibile visualizzare chiaramente alcune anomalie, ad esempio nei tipi di dati AzureDiagnostics e SecurityEvent:
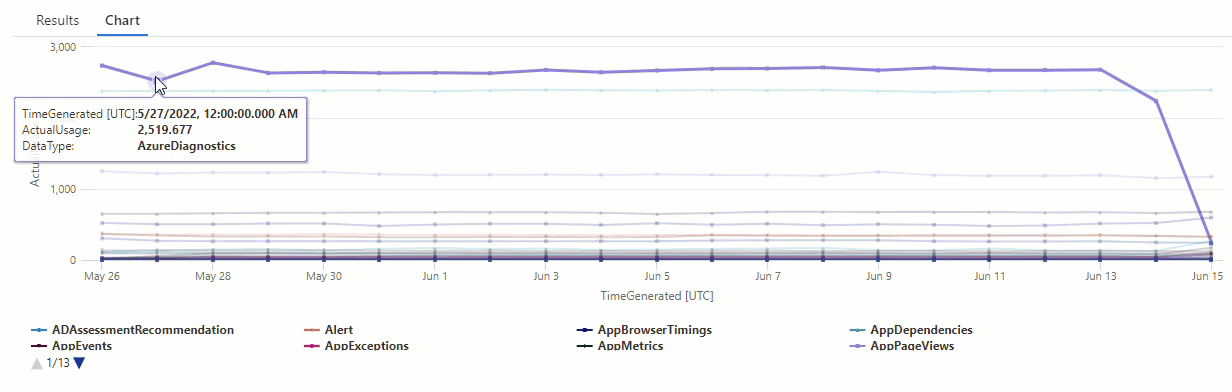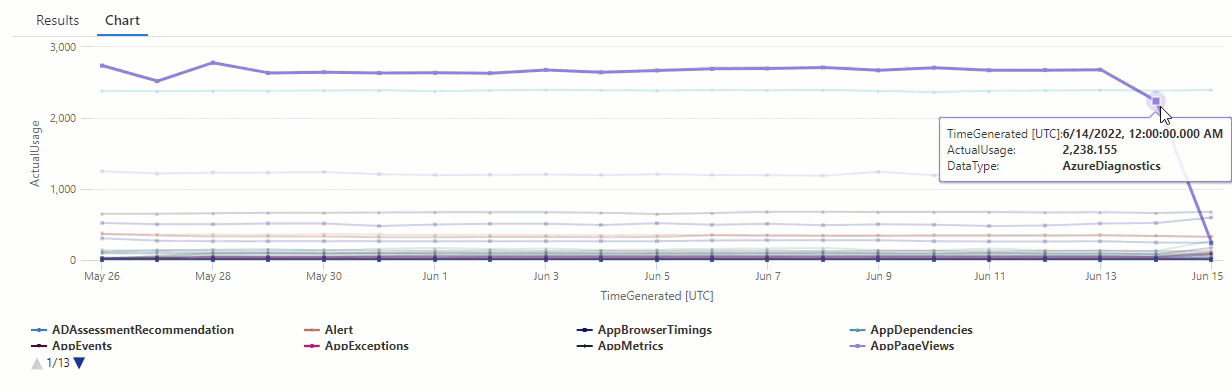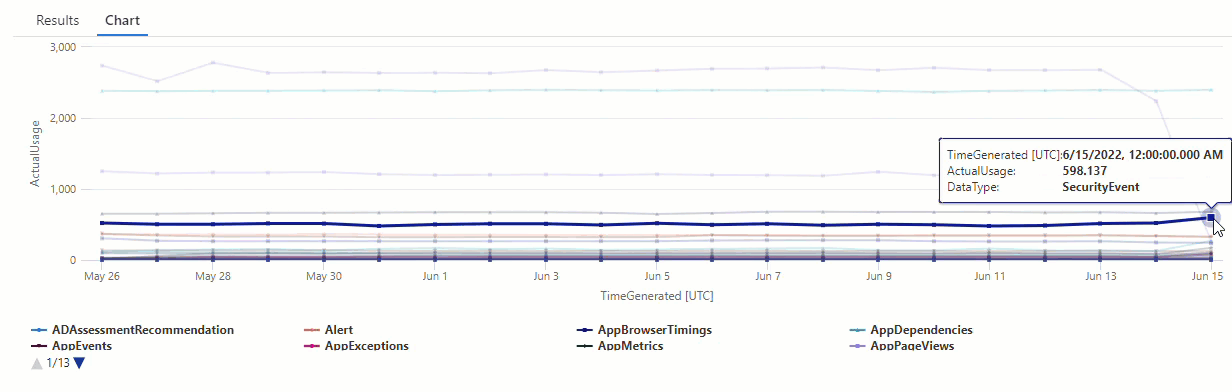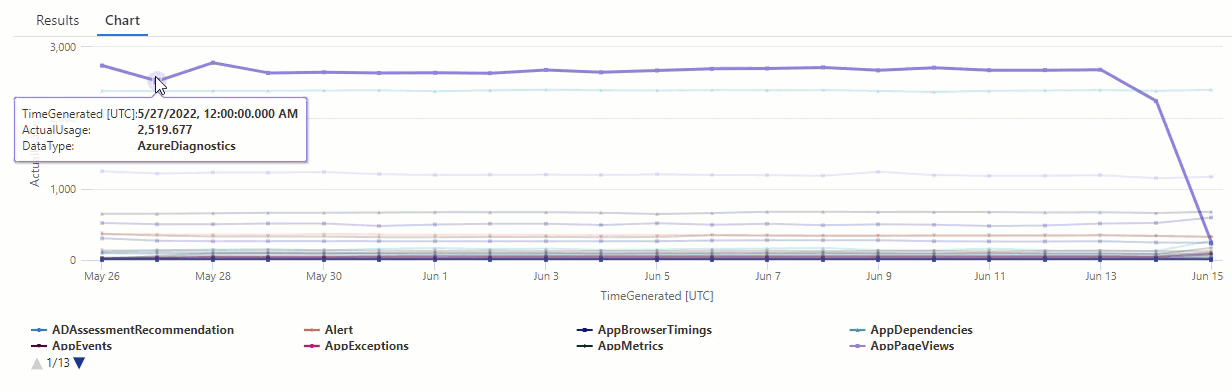
Si userà quindi una funzione KQL per elencare tutte le anomalie in una serie temporale.
Nota
Per altre informazioni sulla sintassi e sull'utilizzo make-series, vedere operatore make-series.
Trovare anomalie in una serie temporale
La funzione series_decompose_anomalies() accetta una serie di valori come input ed estrae anomalie.
Assegnare ora il set di risultati della query serie temporale come input alla funzione series_decompose_anomalies():
Fare clic per eseguire la query
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Questa query restituisce tutte le anomalie di utilizzo per tutte le tabelle nelle ultime tre settimane:

Esaminando i risultati della query, è possibile osservare che la funzione :
- Calcola un utilizzo giornaliero previsto per ogni tabella.
- Confronta l'utilizzo giornaliero effettivo con l'utilizzo previsto.
- Assegna un punteggio di anomalia a ogni punto dati, che indica l'estensione della deviazione dell'utilizzo effettivo rispetto all'utilizzo previsto.
- Identifica anomalie positive (
1) e negative (-1) in ogni tabella.
Nota
Per altre informazioni sulla sintassi e sull'utilizzo series_decompose_anomalies(), vedere series_decompose_anomalies().
Modificare le impostazioni di rilevamento anomalie per perfezionare i risultati
È consigliabile esaminare i risultati iniziali delle query e apportare modifiche alla query, se necessario. Gli outlier nei dati di input possono influire sull'apprendimento della funzione e potrebbe essere necessario modificare le impostazioni di rilevamento anomalie della funzione per ottenere risultati più accurati.
Filtrare i risultati della query series_decompose_anomalies() per individuare le anomalie nel tipo di dati AzureDiagnostics:

I risultati mostrano due anomalie il 14 giugno e il 15 giugno. Confrontare questi risultati con il grafico della prima query make-series, in cui è possibile visualizzare altre anomalie il 27 maggio e il 28:

La differenza nei risultati si verifica perché la funzione series_decompose_anomalies() assegna punteggi di anomalie rispetto al valore di utilizzo previsto, che la funzione calcola in base all'intervallo completo di valori nella serie di input.
Per ottenere risultati più raffinati dalla funzione, escludere l'utilizzo il 15 giugno, ovvero un outlier rispetto agli altri valori della serie, dal processo di apprendimento della funzione.
La sintassi della funzione series_decompose_anomalies() è:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points specifica il numero di punti alla fine della serie da escludere dal processo di apprendimento (regressione).
Per escludere l'ultimo punto dati, impostare Test_points su 1:
Fare clic per eseguire la query
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filtrare i risultati per il tipo di dati AzureDiagnostics:

Tutte le anomalie nel grafico della prima query make-series vengono ora visualizzate nel set di risultati.
Analizzare la causa radice delle anomalie
Il confronto dei valori previsti con valori anomali consente di comprendere la causa delle differenze tra i due set.
Il plug-in diffpatterns() KQL confronta due set di dati della stessa struttura e trova modelli che caratterizzano le differenze tra i due set di dati.
Questa query confronta l'utilizzo di AzureDiagnostics il 15 giugno, l'outlier estremo nell'esempio, con l'utilizzo della tabella in altri giorni:
Fare clic per eseguire la query
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
La query identifica ogni voce della tabella come si verifica in AnomalyDate (15 giugno) o OtherDates. Il plug-in diffpatterns() suddivide quindi questi set di dati, denominati A (OtherDates nell'esempio) e B (AnomalyDate nell'esempio) e restituisce alcuni modelli che contribuiscono alle differenze nei due set:

Esaminando i risultati della query, è possibile visualizzare le differenze seguenti:
- Sono presenti 24.892.147 istanze di inserimento dalla risorsa CH1-GEARAMAAKS in tutti gli altri giorni nell'intervallo di tempo della query e nessun inserimento di dati da questa risorsa il 15 giugno. I dati della risorsa CH1-GEARAMAAKS sono pari al 73,36% dell'inserimento totale in altri giorni nell'intervallo di tempo della query e al 0% dell'inserimento totale il 15 giugno.
- Sono presenti 2.168.448 istanze di inserimento dalla risorsa NSG-TESTSQLMI519 in tutti gli altri giorni nell'intervallo di tempo della query e 110.544 istanze di inserimento da questa risorsa il 15 giugno. I dati della risorsa NSG-TESTSQLMI519 sono pari al 6,39% dell'inserimento totale in altri giorni nell'intervallo di tempo della query e al 25,61% dell'inserimento il 15 giugno.
Si noti che, in media, sono presenti 108.422 istanze di inserimento dalla risorsa NSG-TESTSQLMI519 durante i 20 giorni che costituiscono il periodo altri giorni (dividere 2.168.448 per 20). Di conseguenza, l'inserimento dalla risorsa NSG-TESTSQLMI519 il 15 giugno non è significativamente diverso dall'inserimento da questa risorsa in altri giorni. Tuttavia, poiché non è presente alcun inserimento da CH1-GEARAMAAKS il 15 giugno, l'inserimento da NSG-TESTSQLMI519 costituisce una percentuale significativamente maggiore dell'inserimento totale sulla data di anomalia rispetto agli altri giorni.
La colonna PercentDiffAB mostra la differenza del punto percentuale assoluto tra A e B (|PercentA - PercentB|), ovvero la misura principale della differenza tra i due set. Per impostazione predefinita, il plug-in diffpatterns() restituisce la differenza di oltre il 5% tra i due set di dati, ma è possibile modificare questa soglia. Ad esempio, per restituire solo le differenze del 20% o più tra i due set di dati, è possibile impostare | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) nella query precedente. La query restituisce ora un solo risultato:

Nota
Per altre informazioni sulla sintassi e sull'utilizzo diffpatterns(), vedere plug-in modelli diff.
Passaggi successivi
Altre informazioni su: