Esercitazione: usare la cache di Azure per Redis come cache semantica
In questa esercitazione si usa la cache di Azure per Redis come cache semantica con un modello linguistico di grandi dimensioni (LLM) basato su IA. Si usa il servizio OpenAI di Azure per generare le risposte del modello LLM alle query e memorizzare nella cache tali risposte usando la cache di Azure per Redis, con risposte più veloci e una riduzione dei costi.
Poiché la cache di Azure per Redis offre funzionalità di ricerca vettoriale predefinite, è anche possibile eseguire la memorizzazione nella cache semantica. È possibile restituire risposte memorizzate nella cache per query identiche e di significato simile, anche se il testo non è lo stesso.
In questa esercitazione apprenderai a:
- Creare un'istanza della cache di Azure per Redis configurata per la memorizzazione nella cache semantica
- Usare LangChain o altre librerie Python più diffuse.
- Usare il servizio OpenAI di Azure per generare testo dai modelli di intelligenza artificiale e memorizzare nella cache i risultati.
- Osservare i miglioramenti delle prestazioni derivanti dall'uso della memorizzazione nella cache con modelli LLM.
Importante
Questa esercitazione illustra la creazione di un notebook Jupyter. È possibile seguire questa esercitazione con un file di codice Python (py) e ottenere risultati simili, ma è necessario aggiungere tutti i blocchi di codice in questa esercitazione nel file .py ed eseguirlo una volta per visualizzare i risultati. In altre parole, Jupyter Notebook fornisce risultati intermedi durante l'esecuzione delle celle, ma questo non è il comportamento previsto quando si lavora in un file di codice Python.
Importante
Se si vuole seguire la procedura in un notebook Jupyter completato, scaricare il file del notebook Jupyter denominato semanticcache.ipynb e salvarlo nella nuova cartella semanticcache.
Prerequisiti
Una sottoscrizione di Azure: creare un account gratuitamente
Accesso concesso ad Azure OpenAI nella sottoscrizione di Azure desiderata. È attualmente necessario richiedere l'accesso ad Azure OpenAI. È possibile richiedere l'accesso a OpenAI di Azure completando il modulo all'indirizzo https://aka.ms/oai/access.
Jupyter Notebook (facoltativo)
Una risorsa Azure OpenAI con i modelli text-embedding-ada-002 (versione 2) e gpt-35-turbo-instruct distribuiti. Questi modelli attualmente sono disponibili solo in determinate aree. Per istruzioni su come distribuire i modelli, vedere la guida alla distribuzione di risorse.
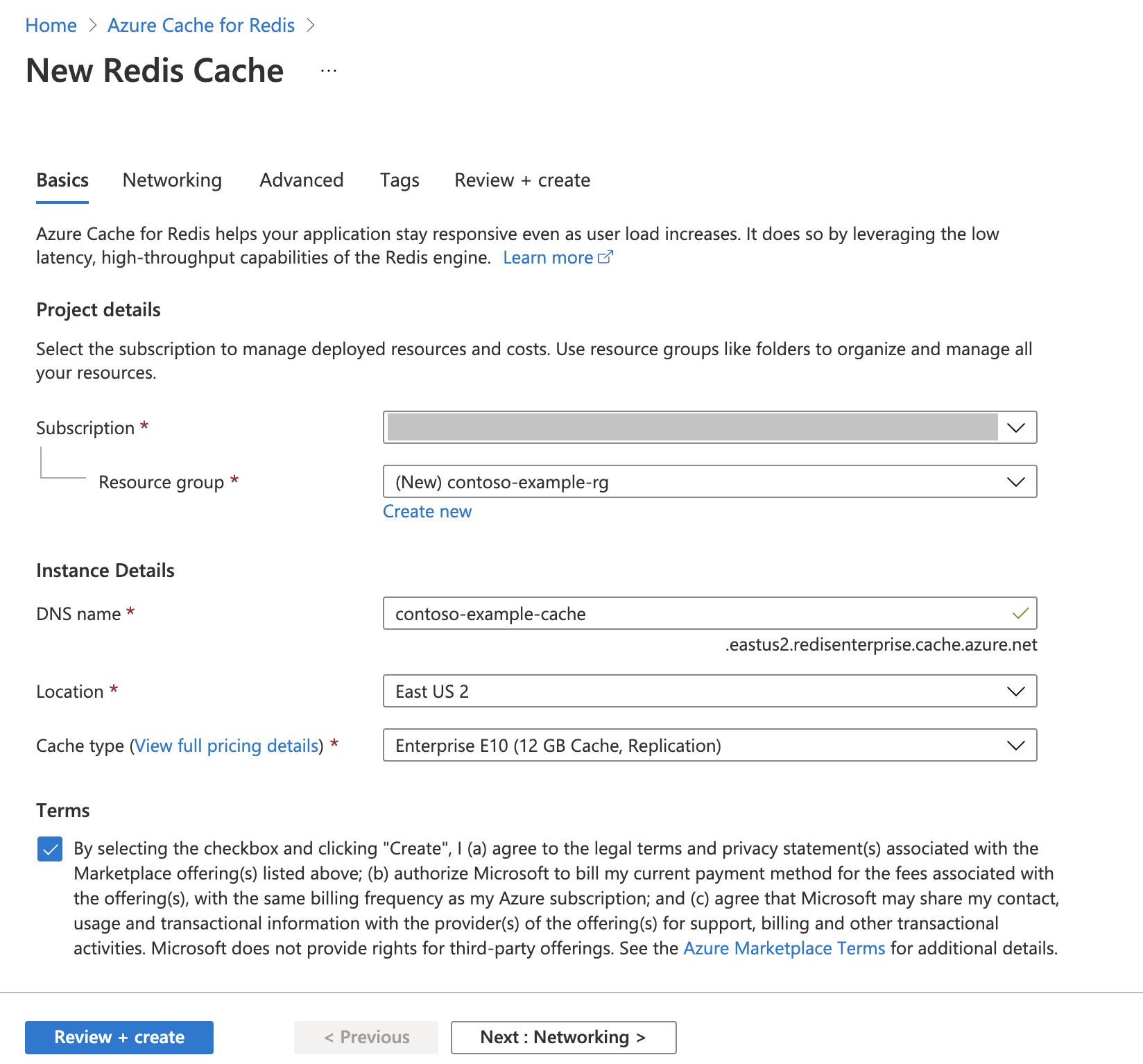
Creare un'istanza di Azure Cache per Redis
Seguire la Guida introduttiva: Creare una cache Redis Enterprise. Nella pagina Avanzate assicurarsi di aver aggiunto il modulo RediSearch e di scegliere i criteri cluster Enterprise. Tutte le altre impostazioni possono corrispondere alle impostazioni predefinite descritte nella guida introduttiva.
Per creare la cache, sono necessari alcuni minuti. Nel frattempo, è possibile proseguire con il passaggio successivo.
Configurare l'ambiente di sviluppo
Creare una cartella nel computer locale denominata semanticcache nel percorso in cui in genere si salvano i progetti.
Creare un nuovo file Python (tutorial.py) o un notebook Jupyter (tutorial.ipynb) nella cartella.
Installare i pacchetti Python necessari:
pip install openai langchain redis tiktoken
Creare modelli Azure OpenAI
Assicurarsi di avere due modelli distribuiti nella risorsa Azure OpenAI:
Un modello linguistico di grandi dimensioni che fornisce risposte di testo. Per questa esercitazione si userà il modello GPT-3.5-turbo-instruct.
Modello di incorporamenti che converte le query in vettori per consentire il confronto con le query precedenti. Per questa esercitazione si usa il modello text-embedding-ada-002 (versione 2).
Per istruzioni più dettagliate, vedere Distribuire un modello. Registrare il nome scelto per la distribuzione di ogni modello.
Importare le librerie e configurare le informazioni di connessione
Per effettuare correttamente una chiamata ad Azure OpenAI, sono necessari un endpoint e una chiave. Per connettersi alla cache di Azure per Redis, è necessario avere anche un endpoint e una chiave.
Passare alla risorsa Azure OpenAI nel portale di Azure.
Individuare Endpoint e chiavi nella sezione Gestione risorse della risorsa Azure OpenAI. Copiare l'endpoint e la chiave di accesso perché sono necessari entrambi per l'autenticazione delle chiamate API. Un endpoint di esempio è
https://docs-test-001.openai.azure.com. Puoi usare entrambiKEY1oKEY2.Passare alla pagina Panoramica della risorsa cache di Azure per Redis nel portale di Azure. Copiare l'endpoint.
Individuare Chiavi di accesso nella sezione Impostazioni. Copiare la chiave di accesso. Puoi usare entrambi
PrimaryoSecondary.Aggiungere il codice seguente in una nuova cella di codice:
# Code cell 2 import openai import redis import os import langchain from langchain.llms import AzureOpenAI from langchain.embeddings import AzureOpenAIEmbeddings from langchain.globals import set_llm_cache from langchain.cache import RedisSemanticCache import time AZURE_ENDPOINT=<your-openai-endpoint> API_KEY=<your-openai-key> API_VERSION="2023-05-15" LLM_DEPLOYMENT_NAME=<your-llm-model-name> LLM_MODEL_NAME="gpt-35-turbo-instruct" EMBEDDINGS_DEPLOYMENT_NAME=<your-embeddings-model-name> EMBEDDINGS_MODEL_NAME="text-embedding-ada-002" REDIS_ENDPOINT = <your-redis-endpoint> REDIS_PASSWORD = <your-redis-password>Aggiornare i valori di
API_KEYeRESOURCE_ENDPOINTcon i valori di chiave ed endpoint della distribuzione di Azure OpenAI.Impostare
LLM_DEPLOYMENT_NAMEeEMBEDDINGS_DEPLOYMENT_NAMEsui nomi dei due modelli distribuiti nel servizio OpenAI di Azure.Aggiornare
REDIS_ENDPOINTeREDIS_PASSWORDcon i valori di endpoint e chiave dell'istanza della cache di Azure per Redis.Importante
È consigliabile usare variabili di ambiente o un gestore dei segreti, ad esempio Azure Key Vault per passare le informazioni relative a chiave API, endpoint e nome della distribuzione. Queste variabili vengono impostate in testo non crittografato per semplicità.
Eseguire la cella di codice 2.
Inizializzare i modelli di IA
Successivamente, si inizializzano i modelli LLM e di incorporamenti
Aggiungere il codice seguente in una nuova cella di codice:
# Code cell 3 llm = AzureOpenAI( deployment_name=LLM_DEPLOYMENT_NAME, model_name="gpt-35-turbo-instruct", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION, ) embeddings = AzureOpenAIEmbeddings( azure_deployment=EMBEDDINGS_DEPLOYMENT_NAME, model="text-embedding-ada-002", openai_api_key=API_KEY, azure_endpoint=AZURE_ENDPOINT, openai_api_version=API_VERSION )Eseguire la cella di codice 3.
Configurare Redis come cache semantica
Successivamente, specificare Redis come cache semantica per il modello LLM.
Aggiungere il codice seguente in una nuova cella di codice:
# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.05))Importante
Il valore del parametro
score_thresholddetermina quanto devono essere simili due query al fine di restituire un risultato memorizzato nella cache. Minore è il numero, più simili devono essere le query. È possibile provare varie soluzioni per questo valore in modo da ottimizzarlo nell'applicazione.Eseguire la cella di codice 4.
Eseguire query e ottenere risposte dall'LLM
Infine, eseguire una query sull'LLM per ottenere una risposta generata dall'intelligenza artificiale. Se si usa un notebook Jupyter, è possibile aggiungere %%time nella parte superiore della cella per generare la quantità di tempo impiegato per eseguire il codice.
Aggiungere il codice seguente in una nuova cella di codice ed eseguirlo:
# Code cell 5 %%time response = llm("Please write a poem about cute kittens.") print(response)L'output dovrà essere simile al seguente:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 2.67 sWall timemostra un valore di 2,67 secondi. Questo è il tempo reale impiegato per eseguire una query sull'LLM e per ricevere una risposta.Eseguire di nuovo la cella 5. Dovrebbe essere generato esattamente lo stesso output, ma con un tempo totale di esecuzione ridotto:
Fluffy balls of fur, With eyes so bright and pure, Kittens are a true delight, Bringing joy into our sight. With tiny paws and playful hearts, They chase and pounce, a work of art, Their innocence and curiosity, Fills our hearts with such serenity. Their soft meows and gentle purrs, Are like music to our ears, They curl up in our laps, And take the stress away in a snap. Their whiskers twitch, they're always ready, To explore and be adventurous and steady, With their tails held high, They're a sight to make us sigh. Their tiny faces, oh so sweet, With button noses and paw-sized feet, They're the epitome of cuteness, ... Cute kittens, a true blessing, In our hearts, they'll always be reigning. CPU times: total: 0 ns Wall time: 575 msIl tempo totale di esecuzione sembra ridursi di cinque volte fino a 575 millisecondi.
Cambiare la query da
Please write a poem about cute kittensaWrite a poem about cute kittensed eseguire di nuovo la cella 5. Dovrebbe essere generato esattamente lo stesso output e un tempo totale di esecuzione inferiore rispetto alla query originale. Anche se la query è cambiata, il significato semantico della query è rimasto invariato per cui è stato restituito lo stesso output memorizzato nella cache. Questo è il vantaggio della memorizzazione nella cache semantica.
Cambiare la soglia di somiglianza
Provare a eseguire una query simile con un significato diverso, ad esempio
Please write a poem about cute puppies. Si noti che anche in questo caso viene restituito il risultato memorizzato nella cache. Il significato semantico della parolapuppiesè abbastanza simile a quello della parolakittens, per cui viene restituito il risultato memorizzato nella cache.La soglia di somiglianza può essere modificata per determinare quando la cache semantica deve restituire un risultato memorizzato nella cache e quando deve restituire un nuovo output dell'LLM. Nella cella di codice 4 cambiare
score_thresholdda0.05a0.01:# Code cell 4 redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT set_llm_cache(RedisSemanticCache(redis_url = redis_url, embedding=embeddings, score_threshold=0.01))Provare a eseguire di nuovo la query
Please write a poem about cute puppies. Si dovrebbe ricevere un nuovo output specifico per i cuccioli:Oh, little balls of fluff and fur With wagging tails and tiny paws Puppies, oh puppies, so pure The epitome of cuteness, no flaws With big round eyes that melt our hearts And floppy ears that bounce with glee Their playful antics, like works of art They bring joy to all they see Their soft, warm bodies, so cuddly As they curl up in our laps Their gentle kisses, so lovingly Like tiny, wet, puppy taps Their clumsy steps and wobbly walks As they explore the world anew Their curiosity, like a ticking clock Always eager to learn and pursue Their little barks and yips so sweet Fill our days with endless delight Their unconditional love, so complete ... For they bring us love and laughter, year after year Our cute little pups, in every way. CPU times: total: 15.6 ms Wall time: 4.3 sÈ probabile che sia necessario ottimizzare la soglia di somiglianza in base all'applicazione per assicurarsi che venga usata la sensibilità corretta per determinare quali query memorizzare nella cache.
Pulire le risorse
Per continuare a usare le risorse create in questo articolo, mantenere il gruppo di risorse.
In caso contrario, se le risorse sono state completate, per evitare addebiti è possibile eliminare il gruppo di risorse di Azure creato.
Importante
L'eliminazione di un gruppo di risorse è irreversibile. Quando si elimina un gruppo di risorse, tutte le risorse in esso contenute vengono eliminate in modo permanente. Assicurarsi di non eliminare accidentalmente il gruppo di risorse sbagliato o le risorse errate. Se le risorse sono state create all'interno di un gruppo di risorse esistente che contiene anche elementi da mantenere, è possibile eliminare ogni singolo elemento a sinistra anziché eliminare il gruppo di risorse.
Per eliminare un gruppo di risorse
Accedere al portale di Azure e selezionare Gruppi di risorse.
Scegliere il gruppo di risorse da eliminare.
Se sono presenti molti gruppi di risorse, usare la casella Filtro per qualsiasi campo... e digitare il nome del gruppo di risorse creato per questo articolo. Nell’elenco dei risultati selezionare il gruppo di risorse.
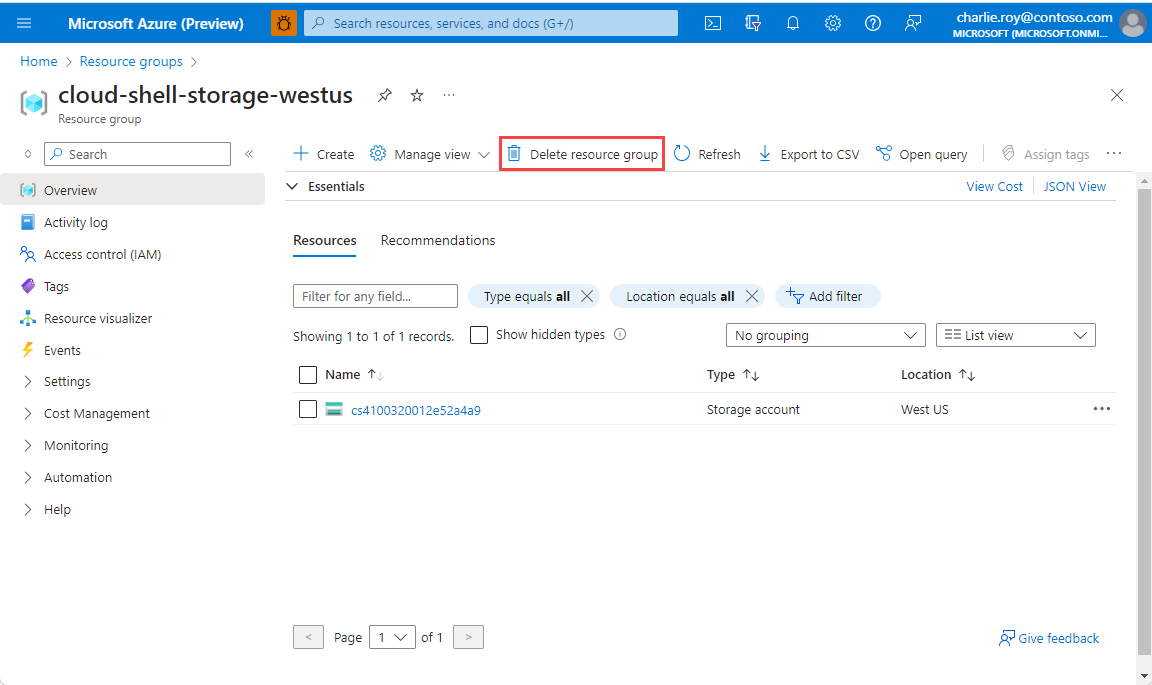
Selezionare Elimina gruppo di risorse.
Verrà chiesto di confermare l'eliminazione del gruppo di risorse. Digitare il nome del gruppo di risorse per confermare e quindi selezionare Elimina.
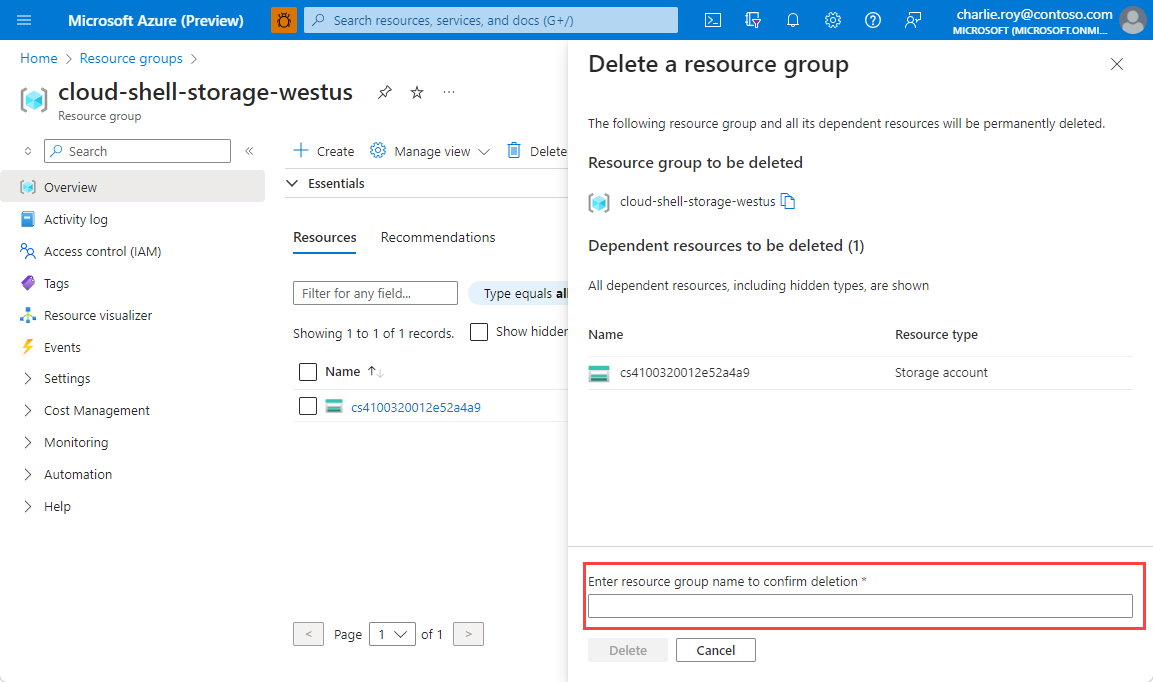
Dopo qualche istante, il gruppo di risorse e tutte le risorse che contiene vengono eliminati.
Contenuto correlato
- Scopri di più su Cache di Azure per Redis
- Vedere altre informazioni sulle funzionalità di ricerca vettoriale della cache di Azure per Redis
- Esercitazione: Usare la ricerca di somiglianza vettoriale nella cache di Azure per Redis
- Come creare un'app basata su intelligenza artificiale con OpenAI e Redis
- Creare un'app D&R con risposte semantiche