Esercitazione: eseguire una ricerca di somiglianza vettoriale in incorporamenti OpenAI di Azure con Cache Redis di Azure
In questa esercitazione si esaminerà un caso d'uso di ricerca di somiglianza vettoriale di base. Si useranno incorporamenti generati dal servizio Azure OpenAI e le funzionalità di ricerca vettoriale predefinite del livello Enterprise di Cache Redis di Azure per eseguire query su un set di dati relativi a film per trovare la corrispondenza più pertinente.
L'esercitazione usa il set di dati Trame di film di Wikipedia, che include descrizioni di Wikipedia delle trame di oltre 35.000 film, dal 1901 al 2017. Il set di dati include un riepilogo della trama per ogni film, oltre a metadati quali l'anno di uscita, il/i regista/i, il cast principale e il genere. Si seguiranno i passaggi dell'esercitazione per generare incorporamenti in base al riepilogo della trama e usare gli altri metadati per eseguire query ibride.
In questa esercitazione apprenderai a:
- Creare un'istanza di Cache Redis di Azure configurata per la ricerca vettoriale
- Installare Azure OpenAI e altre librerie Python necessarie.
- Scaricare il set di dati del film e prepararlo per l'analisi.
- Usare il modello text-embedding-ada-002 (versione 2) per generare incorporamenti.
- Creare un indice vettoriale in Cache Redis di Azure
- Usare la somiglianza del coseno per classificare i risultati della ricerca.
- Usare la funzionalità di query ibrida tramite RediSearch per prefiltrare i dati e rendere la ricerca vettoriale ancora più efficace.
Importante
Questa esercitazione illustra come creare un notebook di Jupyter. È possibile seguire questa esercitazione con un file di codice Python (.py) e ottenere risultati simili, ma sarà necessario aggiungere tutti i blocchi di codice contenuti in questa esercitazione nel file .py ed eseguirli una volta per visualizzare i risultati. In altre parole, Jupyter Notebook fornisce risultati intermedi durante l'esecuzione delle celle, ma non si tratta del comportamento previsto quando si lavora in un file di codice Python.
Importante
Se invece si vuole seguire la procedura in un notebook Jupyter completato, scaricare il file del notebook Jupyter denominato tutorial.ipynb e salvarlo nella nuova cartella redis-vector.
Prerequisiti
- Una sottoscrizione di Azure: creare un account gratuitamente
- Accesso concesso ad Azure OpenAI nella sottoscrizione di Azure desiderata. È attualmente necessario richiedere l'accesso ad Azure OpenAI. È possibile richiedere l'accesso a OpenAI di Azure completando il modulo all'indirizzo https://aka.ms/oai/access.
- Python 3.7.1 o versioni successive
- Jupyter Notebook (facoltativo)
- Una risorsa OpenAI di Azure con il modello text-embedding-ada-002 (versione 2) distribuito. Questo modello è attualmente disponibile solo in determinate aree. Per istruzioni su come distribuire il modelio, vedere la guida alla distribuzione di risorse.
Creare un'istanza di Azure Cache per Redis
Seguire l’Avvio rapido: Creare una cache Redis Enterprise. Nella pagina Avanzate, assicurarsi di aver aggiunto il modulo RediSearch e di aver scelto i criteri cluster Enterprise. Tutte le altre impostazioni possono corrispondere alle impostazioni predefinite descritte nell’avvio rapido.
Per creare la cache, sono necessari alcuni minuti. Nel frattempo, è possibile proseguire con il passaggio successivo.
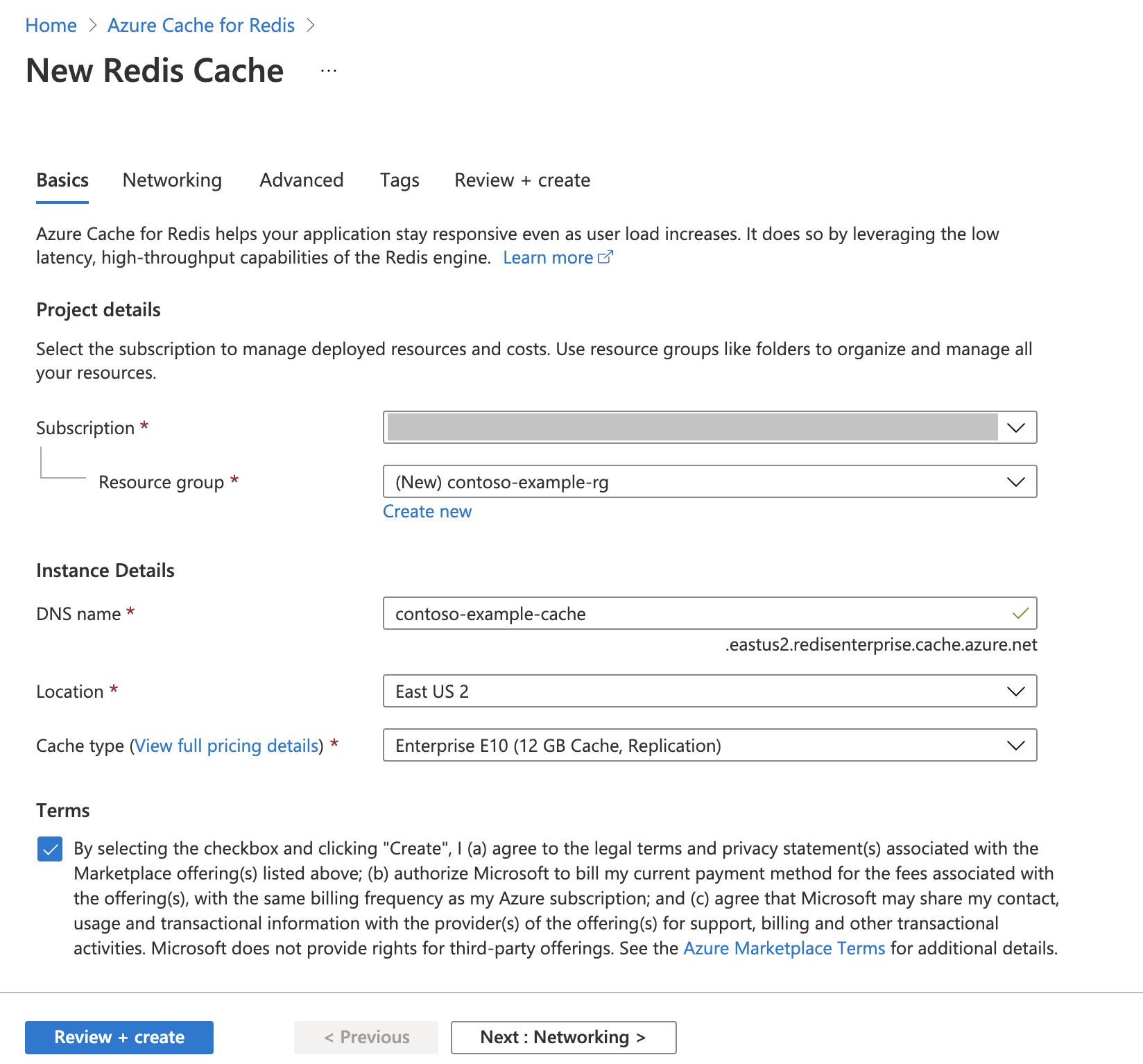
Configurare l'ambiente di sviluppo
Creare una cartella nel computer locale denominata redis-vector nel percorso in cui si salvano in genere i progetti.
Creare un nuovo file Python (tutorial.py) o un notebook Jupyter (tutorial.ipynb) nella cartella.
Installare i pacchetti Python necessari:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Scaricare il set di dati
In un Web browser accedere a https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Accedere o registrarsi con Kaggle. La registrazione è necessaria per scaricare il file.
Selezionare il collegamento di Download in Kaggle per scaricare il file archive.zip.
Estrarre il file archive.zip e spostare wiki_movie_plots_deduped.csv nella cartella redis-vector.
Importare le librerie e configurare le informazioni di connessione
Per effettuare correttamente una chiamata ad Azure OpenAI, sono necessari un endpoint e una chiave. Per connettersi alla cache di Azure per Redis, è necessario avere anche un endpoint e una chiave.
Passare alla risorsa Azure OpenAI nel portale di Azure.
Individuare Endpoint e chiavi nella sezione Gestione risorse. Copiare l'endpoint e la chiave di accesso in base alle esigenze per l'autenticazione delle chiamate API. Un endpoint di esempio è
https://docs-test-001.openai.azure.com. Puoi usare entrambiKEY1oKEY2.Passare alla pagina Panoramica della risorsa cache di Azure per Redis nel portale di Azure. Copiare l'endpoint.
Individuare Chiavi di accesso nella sezione Impostazioni. Copiare la chiave di accesso. Puoi usare entrambi
PrimaryoSecondary.Aggiungere il codice seguente in una nuova cella di codice:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Aggiornare i valori di
API_KEYeRESOURCE_ENDPOINTcon i valori di chiave ed endpoint della distribuzione di Azure OpenAI.DEPLOYMENT_NAMEdeve essere impostato sul nome della distribuzione usando il modello di incorporamentotext-embedding-ada-002 (Version 2)eMODEL_NAMEdeve essere il modello di incorporamento specifico usato.Aggiornare
REDIS_ENDPOINTeREDIS_PASSWORDcon i valori di endpoint e chiave dell'istanza della cache di Azure per Redis.Importante
È consigliabile usare variabili di ambiente o un gestore dei segreti, ad esempio Azure Key Vault per passare le informazioni relative a chiave API, endpoint e nome della distribuzione. Queste variabili vengono impostate in testo non crittografato per semplicità.
Eseguire la cella di codice 2.
Importare un set di dati in Pandas ed elaborare i dati
Successivamente, si leggerà il file CSV in un DataFrame Pandas.
Aggiungere il codice seguente in una nuova cella di codice:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfEseguire la cella di codice 3. Verrà visualizzato l'output seguente:
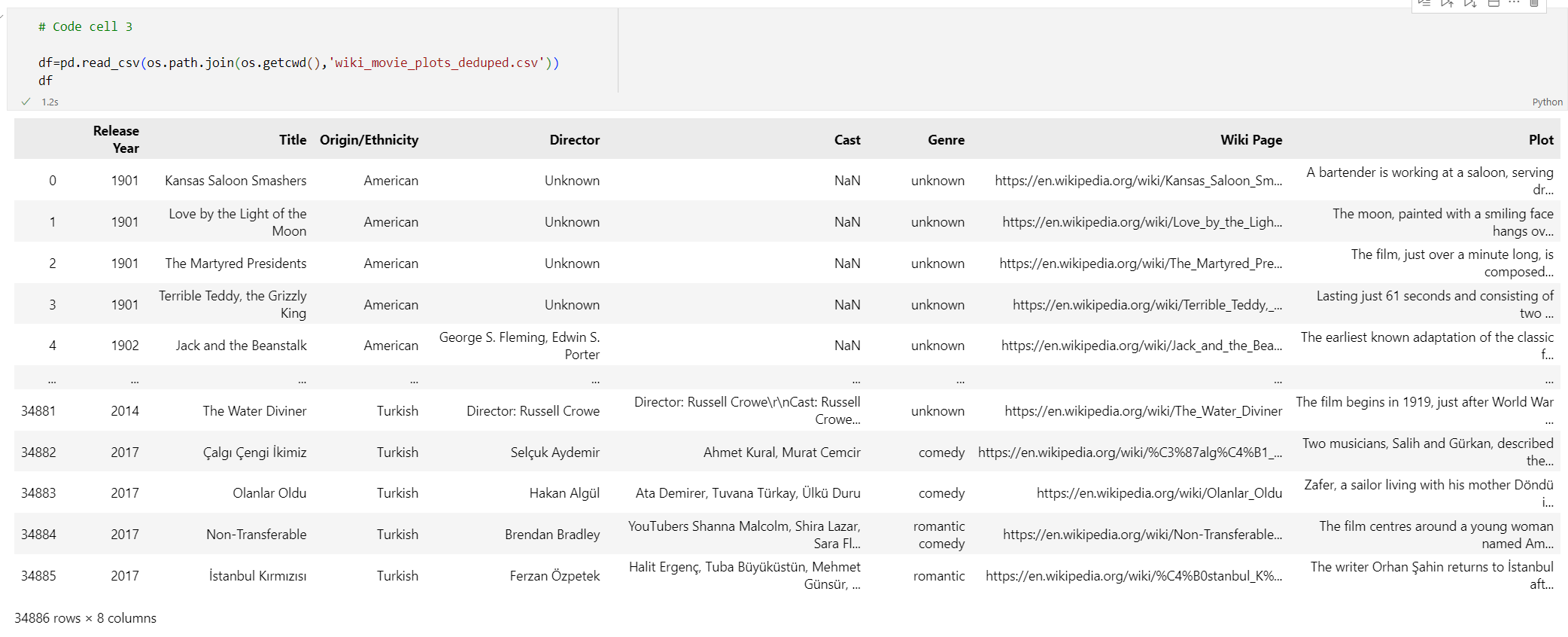
Successivamente, elaborare i dati aggiungendo un
idindice, rimuovendo gli spazi dai titoli delle colonne e filtrando i film per prendere solo i film realizzati dopo il 1970 e da paesi o aree di lingua inglese. Questo passaggio di filtraggio riduce il numero di film nel set di dati, riducendo di conseguenza il costo e il tempo necessari per generare incorporamenti. È possibile modificare o rimuovere i parametri di filtraggio in base alle preferenze.Per filtrare i dati, aggiungere il codice seguente a una nuova cella di codice:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfEseguire la cella di codice 4. Dovresti vedere i seguenti risultati:
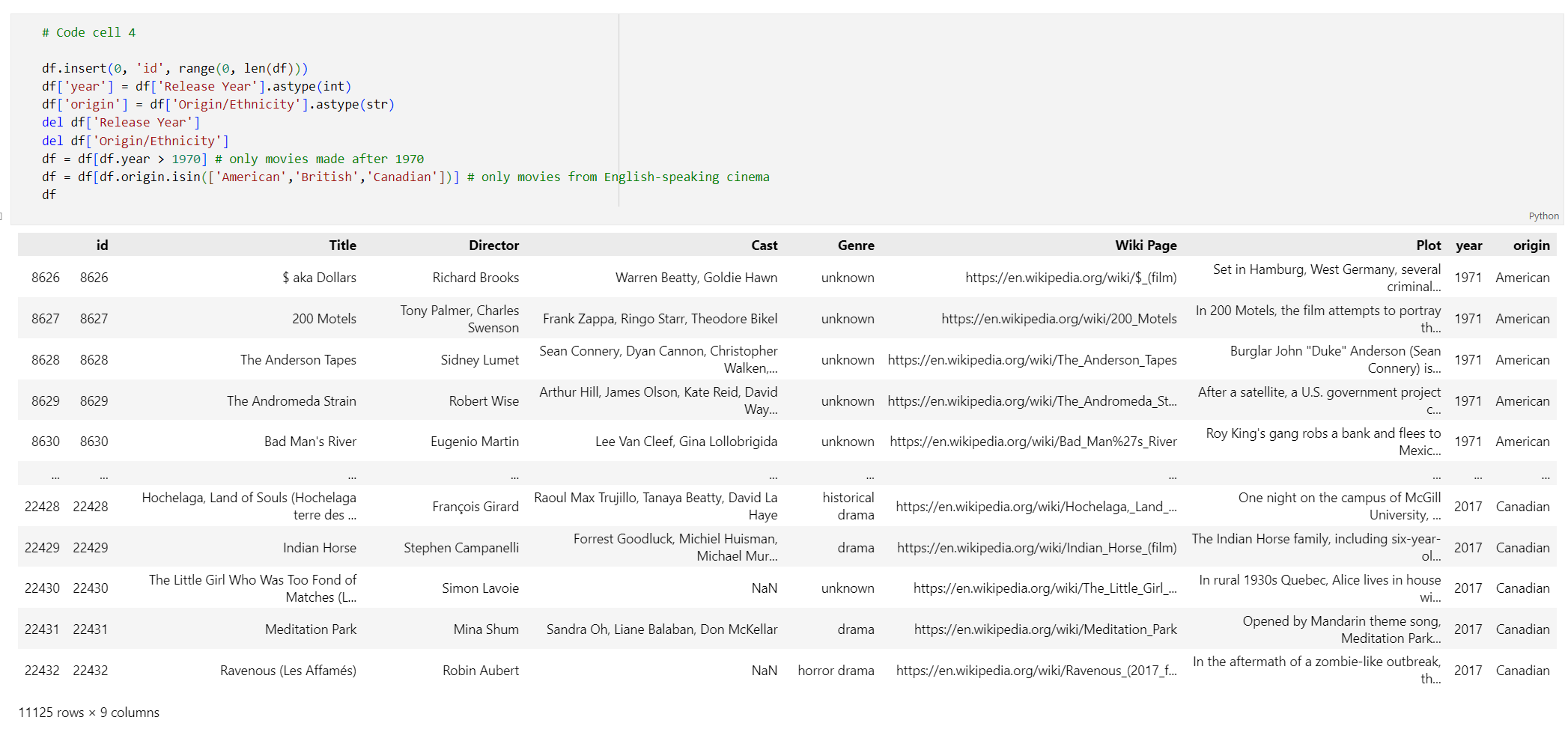
Creare una funzione per pulire i dati rimuovendo spazi vuoti e punteggiatura, quindi usarla sul DataFrame contenente la trama.
Aggiungere il codice seguente in una nuova cella di codice ed eseguirlo:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Infine, rimuovere tutte le voci che contengono descrizioni di trame troppo lunghe per il modello di incorporamento (in altre parole, quelle che richiedono più token rispetto al limite di 8192 token), quindi calcolare i numeri di token necessari per generare incorporamenti. Questa operazione influisce anche sui prezzi per la generazione di incorporamenti.
Aggiungere il codice seguente in una nuova cella di codice:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Eseguire la cella di codice 6. Dovrebbe essere visualizzato questo output:
Number of movies: 11125 Number of tokens required:7044844Importante
Fare riferimento ai prezzi del servizio OpenAI di Azure per calcolare il costo della generazione di incorporamenti in base al numero di token necessari.


Caricare DataFrame in LangChain
Caricare il DataFrame in LangChain usando la classe DataFrameLoader. Una volta che i dati si trovano in documenti LangChain, è molto più facile usare le librerie LangChain per generare incorporamenti ed eseguire ricerche in base alla somiglianza. Impostare Plot come in page_content_column modo che gli incorporamenti vengano generati in questa colonna.
Aggiungere il codice seguente in una nuova cella di codice ed eseguirlo:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Generare incorporamenti e caricarli in Redis
Ora che i dati sono stati filtrati e caricati in LangChain, si creeranno incorporamenti in modo da poter eseguire query sulla trama per ogni film. Il codice seguente configura Azure OpenAI, genera incorporamenti e carica i vettori di incorporamento in Cache Redis di Azure.
Aggiungere il codice seguente a una nuova cella di codice:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Eseguire la cella di codice 8. Il completamento di questa operazione può richiedere più di 30 minuti. Viene generato anche un file
redis_schema.yaml. Questo file è utile se ci si vuole connettere all'indice nell'istanza di Cache Redis di Azure senza generare nuovamente incorporamenti.
Importante
La velocità con cui vengono generati gli incorporamenti dipende dalla quota disponibile per il modello OpenAI di Azure. Con una quota di 240.000 token al minuto, l'elaborazione di 7M token nel set di dati richiede circa 30 minuti.
Eseguire query di ricerca vettoriale
Ora che il set di dati, l'API del servizio Azure OpenAI e l'istanza di Redis sono configurati, è possibile eseguire ricerche usando i vettori. In questo esempio vengono restituiti i primi 10 risultati per una determinata query.
Aggiungere il codice seguente al file di codice Python:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Eseguire la cella di codice 9. Verrà visualizzato l'output seguente:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Il punteggio di somiglianza viene restituito insieme alla classificazione ordinale dei film in base alla somiglianza. Notare che le query più specifiche hanno punteggi di somiglianza che diminuiscono più rapidamente man mano che si scende nell’elenco.
Ricerche ibride
Poiché RediSearch include anche funzionalità di ricerca avanzate sulla ricerca vettoriale, è possibile filtrare i risultati in base ai metadati nel set di dati, ad esempio genere del film, cast, anno di uscita o regista. In questo caso, filtrare in base al genere
comedy.Aggiungere il codice seguente in una nuova cella di codice:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Eseguire la cella di codice 10. Verrà visualizzato l'output seguente:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Con Cache Redis di Azure e il servizio Azure OpenAI, è possibile usare incorporamenti e ricerca vettoriale per aggiungere funzionalità di ricerca avanzate all'applicazione.
Pulire le risorse
Per continuare a usare le risorse create in questo articolo, mantenere il gruppo di risorse.
In caso contrario, se le risorse sono state completate, per evitare addebiti è possibile eliminare il gruppo di risorse di Azure creato.
Importante
L'eliminazione di un gruppo di risorse è irreversibile. Quando si elimina un gruppo di risorse, tutte le risorse in esso contenute vengono eliminate in modo permanente. Assicurarsi di non eliminare accidentalmente il gruppo di risorse sbagliato o le risorse errate. Se le risorse sono state create all'interno di un gruppo di risorse esistente che contiene anche elementi da mantenere, è possibile eliminare ogni singolo elemento a sinistra anziché eliminare il gruppo di risorse.
Per eliminare un gruppo di risorse
Accedere al portale di Azure e selezionare Gruppi di risorse.
Scegliere il gruppo di risorse da eliminare.
Se sono presenti molti gruppi di risorse, usare la casella Filtro per qualsiasi campo... e digitare il nome del gruppo di risorse creato per questo articolo. Nell’elenco dei risultati selezionare il gruppo di risorse.
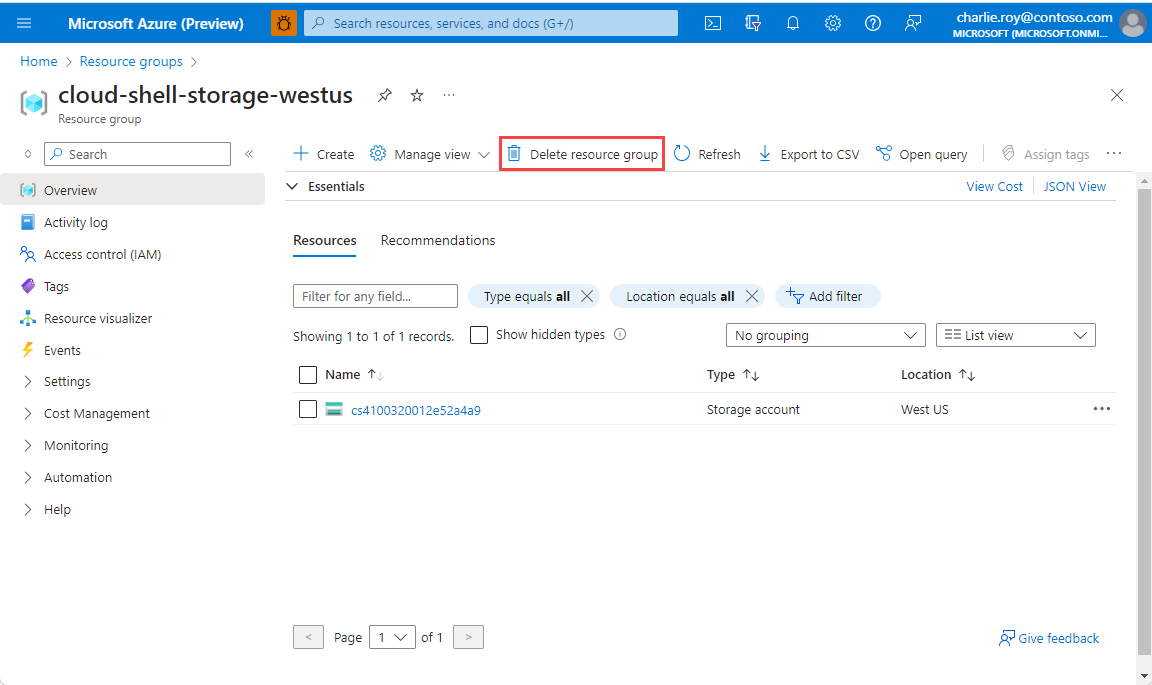
Selezionare Elimina gruppo di risorse.
Verrà chiesto di confermare l'eliminazione del gruppo di risorse. Digitare il nome del gruppo di risorse per confermare e quindi selezionare Elimina.
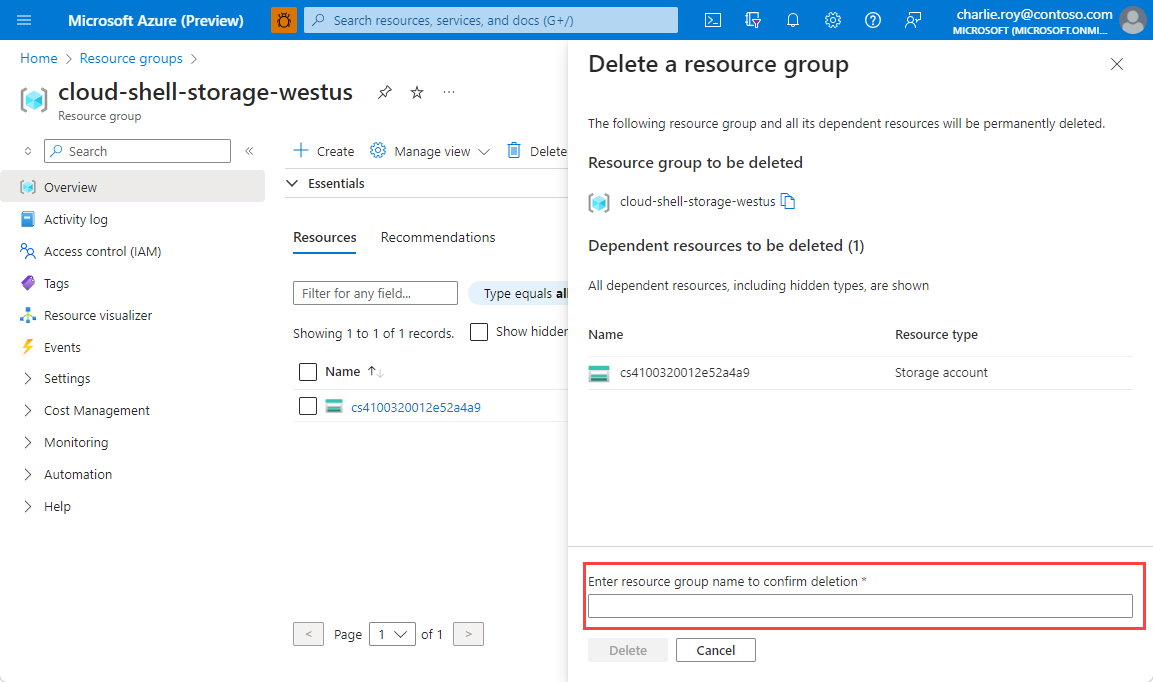
Dopo qualche istante, il gruppo di risorse e tutte le risorse che contiene vengono eliminati.
Contenuto correlato
- Scopri di più su Cache di Azure per Redis
- Vedere altre informazioni sulle funzionalità di ricerca vettoriale della cache di Azure per Redis
- Altre informazioni sugli incorporamenti generati dal servizio Azure OpenAI
- Altre informazioni sulla somiglianza del coseno
- Come creare un'app basata su intelligenza artificiale con OpenAI e Redis
- Creare un'app D&R con risposte semantiche