Questo articolo descrive il processo di progettazione, i principi e le scelte tecnologiche per l'uso di Azure Synapse per creare una soluzione data lakehouse sicura. Ci concentriamo sulle considerazioni sulla sicurezza e sulle decisioni tecniche chiave.
Apache®, Apache Spark® e il logo con la fiamma sono marchi o marchi registrati di Apache Software Foundation negli Stati Uniti e/o in altri Paesi. L'uso di questi marchi non implica alcuna approvazione da parte di Apache Software Foundation.
Architettura
Il diagramma seguente illustra l'architettura della soluzione di data lakehouse. È progettato per controllare le interazioni tra i servizi per attenuare le minacce alla sicurezza. Le soluzioni variano a seconda dei requisiti funzionali e di sicurezza.

Scaricare un file di Visio di questa architettura.
Flusso di dati
Il diagramma seguente illustra il flusso dei dati in questa soluzione:

- I dati vengono caricati dall'origine dati nella zona di destinazione dei dati, in archiviazione BLOB di Azure o in una condivisione file fornita da File di Azure. I dati vengono caricati da un programma o da un sistema di caricamento batch. I dati di streaming vengono acquisiti e archiviati nell'archiviazione BLOB usando la funzionalità di acquisizione di Hub eventi di Azure. Possono essere presenti più origini dati. Ad esempio, diverse factory possono caricare i dati delle operazioni. Per informazioni sulla protezione dell'accesso all'archiviazione BLOB, alle condivisioni file e ad altre risorse di archiviazione, consultare le sezioni Raccomandazioni sulla sicurezza per l'archiviazione BLOB e Pianificazione per una distribuzione file di Azure.
- L'arrivo del file di dati attiva Azure Data Factory per elaborare i dati e archiviarli nel data lake nella zona dati principale. Il caricamento dei dati nella zona dati principale in Azure Data Lake protegge dall'esfiltrazione di dati.
- Azure Data Lake archivia i dati non elaborati ottenuti da origini diverse. È protetto da regole del firewall e reti virtuali. Blocca tutti i tentativi di connessione provenienti dalla rete Internet pubblica.
- L'arrivo dei dati nel data lake attiva la pipeline di Azure Synapse o un trigger timed esegue un processo di elaborazione dati. Apache Spark in Azure Synapse viene attivato ed esegue un processo o un notebook Spark. Orchestra anche il flusso del processo di dati nella data lakehouse. Le pipeline di Azure Synapse converte i dati dalla zona Bronze alla zona Silver e quindi nella zona Gold.
- Un processo Spark o un notebook esegue il processo di elaborazione dati. La cura dei dati o un processo di training di Machine Learning può essere eseguita anche in Spark. I dati strutturati nella zona Gold vengono archiviati in formato Delta Lake.
- Un pool SQL serverless crea tabelle esterne che usano i dati archiviati in Delta Lake. Il pool SQL serverless offre un motore di query SQL potente ed efficiente e può supportare account utente SQL tradizionali o account utente Microsoft Entra.
- Power BI si connette al pool SQL serverless per visualizzare i dati. Crea report o dashboard usando i dati nella data lakehouse.
- Analista dei dati o scienziati possono accedere ad Azure Synapse Studio per:
- Migliorare ulteriormente i dati.
- Analizzare per ottenere informazioni dettagliate aziendali.
- Eseguire il training del modello di Machine Learning.
- Le applicazioni aziendali si connettono a un pool SQL serverless e usano i dati per supportare altri requisiti operativi aziendali.
- Pipeline di Azure esegue il processo CI/CD che compila, testa e distribuisce automaticamente la soluzione. È progettato per ridurre al minimo l'intervento umano durante il processo di distribuzione.
Componenti
Di seguito sono riportati i componenti chiave di questa soluzione data lakehouse:
- Azure Synapse
- File di Azure
- Hub eventi
- Archiviazione BLOB
- Archiviazione di Azure Data Lake
- Azure DevOps
- Power BI
- Data Factory
- Azure Bastion
- Monitoraggio di Azure
- Microsoft Defender per il cloud
- Azure Key Vault
Alternative
- Se è necessaria l'elaborazione dei dati in tempo reale, invece di archiviare singoli file nella zona di destinazione dei dati, usare Apache Structured Streaming per ricevere il flusso di dati da Hub eventi ed elaborarlo.
- Se i dati hanno una struttura complessa e richiedono query SQL complesse, è consigliabile archiviarli in un pool SQL dedicato anziché in un pool SQL serverless.
- Se i dati contengono molte strutture di dati gerarchici, ad esempio con una struttura JSON di grandi dimensioni, è possibile archiviarla in Esplora dati di Azure Synapse.
Dettagli dello scenario
Azure Synapse Analytics è una piattaforma di dati versatile che supporta il data warehousing aziendale, l'analisi dei dati in tempo reale, le pipeline, l'elaborazione dei dati delle serie temporali, l'apprendimento automatico e la governance dei dati. Per supportare queste funzionalità, integra diverse tecnologie, ad esempio:
- Data warehousing aziendale
- Pool SQL serverless
- Apache Spark
- Pipeline
- Esplora dati
- Funzionalità di Machine Learning
- Governance dei dati unificata di Microsoft Purview
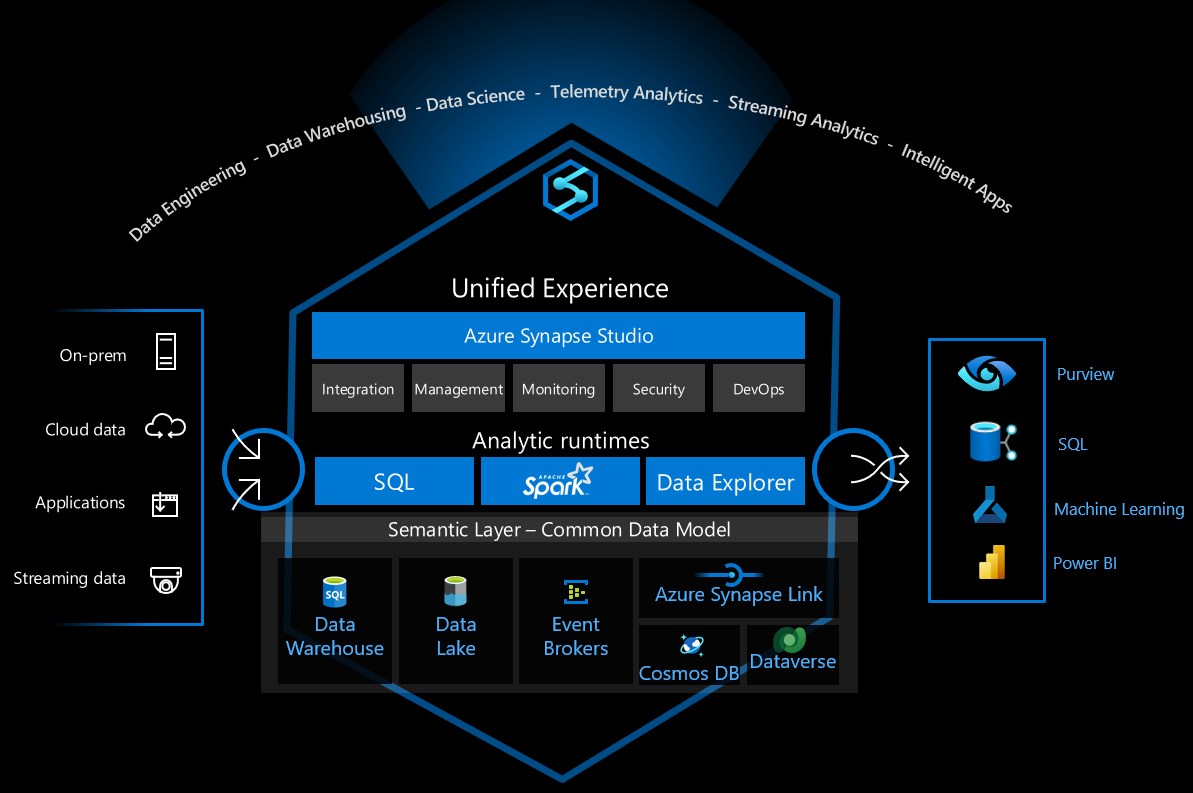
Queste funzionalità aprono molte possibilità, ma esistono molte scelte tecniche per configurare in modo sicuro l'infrastruttura per l'uso sicuro.
Questo articolo descrive il processo di progettazione, i principi e le scelte tecnologiche per l'uso di Azure Synapse per creare una soluzione data lakehouse sicura. Ci concentriamo sulle considerazioni sulla sicurezza e sulle decisioni tecniche chiave. La soluzione usa questi servizi di Azure:
- Azure Synapse
- Pool SQL serverless di Azure Synapse
- Apache Spark in Azure Synapse Analytics
- Pipeline di Azure Synapse
- Azure Data Lake
- Azure DevOps.
L'obiettivo è fornire indicazioni sulla creazione di una piattaforma data lakehouse sicura e conveniente per l'uso aziendale e sulla collaborazione delle tecnologie in modo trasparente e sicuro.
Potenziali casi d'uso
Un data lakehouse è un'architettura moderna di gestione dei dati che combina le funzionalità di efficienza, scalabilità e flessibilità di un data lake con le funzionalità di gestione dei dati e delle transazioni di un data warehouse. Un data lakehouse può gestire una grande quantità di dati e supportare scenari di Business Intelligence e Machine Learning. Può anche elaborare dati da diverse strutture di dati e origini dati. Per maggiori informazioni, consultare la sezione Informazioni su Databricks Lakehouse.
Ecco alcuni casi d'uso comuni per la soluzione descritta di seguito:
- Analisi dei dati di telemetria di Internet delle cose (IoT)
- Automazione di smart factory (per la produzione)
- Tenere traccia delle attività e del comportamento dei consumatori (per la vendita al dettaglio)
- Gestione degli incidenti e degli eventi di sicurezza
- Monitoraggio dei log applicazioni e del comportamento dell'applicazione
- Elaborazione e analisi aziendale di dati semistrutturati
Progettazione di alto livello
Questa soluzione è incentrata sulle procedure di progettazione e implementazione della sicurezza nell'architettura. Il pool SQL serverless, Apache Spark in Azure Synapse, le pipeline di Azure Synapse, Data Lake Storage e Power BI sono i servizi chiave usati per implementare il modello di data lakehouse.
Ecco l'architettura di progettazione di soluzioni di alto livello:

Scegliere lo stato attivo per la sicurezza
È stata avviata la progettazione della sicurezza usando Threat Modeling Tool. Lo strumento ci ha aiutato:
- Comunicare con gli stakeholder del sistema sui potenziali rischi.
- Definire il limite di attendibilità nel sistema.
In base ai risultati della modellazione delle minacce, sono state effettuate le aree di sicurezza seguenti:
- Gestione delle identità e controllo di accesso
- Protezione di rete
- Sicurezza di DevOps
Sono state progettate le funzionalità di sicurezza e le modifiche dell'infrastruttura per proteggere il sistema attenuando i principali rischi di sicurezza identificati con queste priorità principali.
Per informazioni dettagliate sugli elementi da controllare e considerare, vedere:
- Sicurezza in Microsoft Cloud Adoption Framework per Azure
- Controllo di accesso
- Protezione degli asset
- Sicurezza dell'innovazione
Piano di protezione di rete e asset
Uno dei principi chiave di sicurezza in Cloud Adoption Framework è il principio Zero Trust: quando si progetta la sicurezza per qualsiasi componente o sistema, ridurre il rischio di attacchi che espandono l'accesso presupponendo che altre risorse dell'organizzazione vengano compromesse.
In base al risultato della modellazione delle minacce, la soluzione adotta la raccomandazione di distribuzione della micro-segmentazione e definisce diversi limiti di sicurezza. Rete virtuale di Azure e la protezione dell'esfiltrazione dei dati Azure Synapse sono le tecnologie chiave usate per implementare il limite di sicurezza per proteggere gli asset di dati e i componenti critici.
Poiché Azure Synapse è costituito da diverse tecnologie, è necessario:
Identificare i componenti di Synapse e i servizi correlati usati nel progetto.
Azure Synapse è una piattaforma dati versatile che può gestire molte esigenze di elaborazione dei dati diverse. Prima di tutto, è necessario decidere quali componenti in Azure Synapse vengono usati nel progetto in modo da poter pianificare come proteggerli. È anche necessario determinare quali altri servizi comunicano con questi componenti di Azure Synapse.
Nell'architettura del data lakehouse, i componenti chiave sono:
- SQL serverless di Azure Synapse
- Apache Spark on Azure Synapse
- Pipeline di Azure Synapse
- Data Lake Storage
- Azure DevOps
Definire i comportamenti di comunicazione legale tra i componenti.
È necessario definire i comportamenti di comunicazione consentiti tra i componenti. Ad esempio, si vuole che il motore Spark comunichi direttamente con l'istanza SQL dedicata oppure si vuole che comunichi tramite un proxy, ad esempio Azure Synapse Integrazione dei dati pipeline o Data Lake Storage?
In base al principio Zero Trust, blocchiamo la comunicazione se non c'è bisogno di business per l'interazione. Ad esempio, viene bloccato un motore Spark che si trova in un tenant sconosciuto per comunicare direttamente con Data Lake Storage.
Scegliere la soluzione di sicurezza appropriata per applicare i comportamenti di comunicazione definiti.
In Azure diverse tecnologie di sicurezza possono applicare i comportamenti di comunicazione del servizio definiti. Ad esempio, in Data Lake Storage è possibile usare un elenco di indirizzi IP consentiti per controllare l'accesso a un data lake, ma è anche possibile scegliere quali reti virtuali, servizi di Azure e istanze di risorse sono consentite. Ogni metodo di protezione offre una protezione di sicurezza diversa. Scegliere in base alle esigenze aziendali e alle limitazioni ambientali. La configurazione usata in questa soluzione è descritta nella sezione successiva.
Implementare il rilevamento delle minacce e le difese avanzate per le risorse critiche.
Per le risorse critiche, è consigliabile implementare il rilevamento delle minacce e le difese avanzate. I servizi consentono di identificare le minacce e attivare gli avvisi, in modo che il sistema possa notificare agli utenti le violazioni della sicurezza.
Prendere in considerazione le tecniche seguenti per proteggere meglio le reti e gli asset:
Distribuire reti perimetrali per fornire zone di sicurezza per le pipeline di dati
Quando un carico di lavoro della pipeline di dati richiede l'accesso a dati esterni e alla zona di destinazione dei dati, è consigliabile implementare una rete perimetrale e separarla con una pipeline di estrazione, trasformazione, caricamento (ETL).
Abilitare Azure Defender per il cloud per tutti gli account di archiviazione.
Defender per il cloud attiva avvisi di sicurezza quando rileva tentativi insoliti e potenzialmente dannosi di accedere o sfruttare gli account di archiviazione. Per altre informazioni, vedere Configurare Microsoft Defender for Storage.
Bloccare un account di archiviazione per evitare l'eliminazione o l'esecuzione di modifiche alla configurazione in modo accidentale o malintenzionato
Per altre informazioni, vedere Applicare un blocco di Azure Resource Manager a un account di archiviazione.
Architettura con rete e protezione degli asset
Nella tabella seguente vengono descritti i comportamenti di comunicazione definiti e le tecnologie di sicurezza scelte per questa soluzione. Le scelte sono basate sui metodi descritti in Piano di protezione delle risorse e della rete.
| Da (Cliente) | A (Servizio) | Comportamento | Impostazione | Note | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | Rifiuta tutto | Regola del firewall - Negazione predefinita | Impostazione predefinita: "Nega" | Regola del firewall - Negazione predefinita |
| Pipeline/Spark di Azure Synapse | Data Lake Storage | Consenti (istanza) | Rete virtuale - Endpoint privato gestito (Data Lake Storage) | ||
| Synapse SQL | Data Lake Storage | Consenti (istanza) | Regola del firewall - Istanze di risorse (Synapse SQL) | Synapse SQL deve accedere a Data Lake Storage usando le identità gestite | |
| Agente di Azure Pipelines | Data Lake Storage | Consenti (istanza) | Regola del firewall - Reti virtuali selezionate Endpoint servizio - Archiviazione |
Per i test di integrazione bypass: 'AzureServices' (regola del firewall) |
|
| Internet | Area di lavoro Synapse | Rifiuta tutto | Regola del firewall | ||
| Agente di Azure Pipelines | Area di lavoro Synapse | Consenti (istanza) | Rete virtuale - endpoint privato | Richiede tre endpoint privati (Sviluppo, SQL serverless e SQL dedicato) | |
| Rete virtuale gestita di Synapse | Internet o tenant di Azure non autorizzato | Rifiuta tutto | Rete virtuale - Protezione dell'esfiltrazione dei dati synapse | ||
| Pipeline/Spark di Synapse | Insieme di credenziali delle chiavi di | Consenti (istanza) | Rete virtuale - Endpoint privato gestito (Key Vault) | Impostazione predefinita: "Nega" | |
| Agente di Azure Pipelines | Insieme di credenziali delle chiavi di | Consenti (istanza) | Regola del firewall - Reti virtuali selezionate * Endpoint di servizio - Key Vault |
bypass: 'AzureServices' (regola del firewall) | |
| Funzioni di Azure | SQL serverless di Synapse | Consenti (istanza) | Rete virtuale - Endpoint privato (SQL serverless di Synapse) | ||
| Pipeline/Spark di Synapse | Monitoraggio di Azure | Consenti (istanza) | Rete virtuale - Endpoint privato (Monitoraggio di Azure) |
Ad esempio, nel piano, si desidera:
- Creare un'area di lavoro di Azure Synapse con una rete virtuale gestita.
- Proteggere i dati in uscita dalle aree di lavoro di Azure Synapse usando la protezione esfiltrazione dei dati delle aree di lavoro di Azure Synapse.
- Gestire l'elenco dei tenant di Microsoft Entra approvati per l'area di lavoro Azure Synapse.
- Configurare le regole di rete per concedere il traffico all'account di archiviazione dalle reti virtuali selezionate, accedere solo e disabilitare l'accesso alla rete pubblica.
- Usare endpoint privati gestiti per connettere la rete virtuale gestita da Azure Synapse al data lake.
- Usare Istanza di risorse per connettere in modo sicuro Azure Synapse SQL al data lake.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Microsoft Azure Well-Architected Framework.
Sicurezza
Per informazioni sul pilastro della sicurezza di Well-Architected Framework, consultare la sezione Sicurezza.
Identità e controllo di accesso
Nel sistema sono presenti diversi componenti. Ognuno richiede una configurazione di gestione delle identità e degli accessi (IAM) diversa. Queste configurazioni devono collaborare per offrire un'esperienza utente semplificata. Di conseguenza, vengono usate le linee guida di progettazione seguenti quando si implementa il controllo delle identità e degli accessi.
Scegliere una soluzione di gestione delle identità per diversi livelli di controllo di accesso
- Nel sistema sono presenti quattro diverse soluzioni di gestione delle identità.
- Account SQL (SQL Server)
- Entità servizio (Microsoft Entra ID)
- Identità gestita (Microsoft Entra ID)
- Account utente (Microsoft Entra ID)
- Nel sistema sono presenti quattro diversi livelli di controllo di accesso.
- Livello di accesso dell'applicazione: scegliere la soluzione di gestione delle identità per i ruoli AP.
- Il livello di accesso ad Azure Synapse DB/Tabella: scegliere la soluzione di gestione delle identità per i ruoli nei database.
- Azure Synapse accede al livello di risorse esterne: scegliere la soluzione di gestione delle identità per accedere alle risorse esterne.
- Livello di accesso di Data Lake Storage: scegliere la soluzione di gestione delle identità per controllare l'accesso ai file nell'archiviazione.

Una parte fondamentale del controllo delle identità e degli accessi è la scelta della soluzione di gestione delle identità appropriata per ogni livello di controllo di accesso. I principi di progettazione della sicurezza di Azure Well-Architected Framework suggeriscono l'uso dei controlli nativi e la semplicità di guida. Pertanto, questa soluzione usa l'account utente Microsoft Entra dell'utente finale nei livelli di accesso dell'applicazione e azure Synapse DB. Usa le soluzioni IAM native e fornisce un controllo di accesso granulare. Il livello di accesso alle risorse esterne e al livello di accesso di Data Lake di Azure Synapse usano l'identità gestita in Azure Synapse per semplificare il processo di autorizzazione.
- Nel sistema sono presenti quattro diverse soluzioni di gestione delle identità.
Valutare l’accesso con privilegi minimi.
Un principio guida Zero Trust suggerisce di fornire just-in-time e un accesso sufficiente alle risorse critiche. Per migliorare la sicurezza in futuro, consultare la sezione Privileged Identity management (PIM) di Microsoft Entra.
Proteggere il servizio collegato
I servizi collegati definiscono le informazioni di connessione necessarie per consentire di connettersi alle risorse esterne. È importante proteggere le configurazioni dei servizi collegati.
- Creare un servizio collegato Azure Data Lake con Collegamento privato.
- Usare l'identità gestita come metodo di autenticazione nei servizi collegati.
- Usare Azure Key Vault per proteggere le credenziali per l'accesso al servizio collegato.

Valutazione del punteggio di sicurezza e rilevamento delle minacce
Per comprendere lo stato di sicurezza del sistema, la soluzione usa Microsoft Defender per il cloud per valutare la sicurezza dell'infrastruttura e rilevare i problemi di sicurezza. Microsoft Defender per il cloud è uno strumento per la gestione della postura di sicurezza e per la protezione dalle minacce. Può proteggere i carichi di lavoro in esecuzione in Azure, ibrido e in altre piattaforme cloud.

Il piano gratuito di Defender per il cloud viene abilitato automaticamente in tutte le sottoscrizioni di Azure quando si visitano per la prima volta le pagine di Defender per il cloud nel portale di Azure. È consigliabile abilitarlo per ottenere la valutazione e i suggerimenti relativi al comportamento di sicurezza cloud. Microsoft Defender per il cloud fornirà il punteggio di sicurezza e alcune linee guida per la protezione avanzata per le sottoscrizioni.
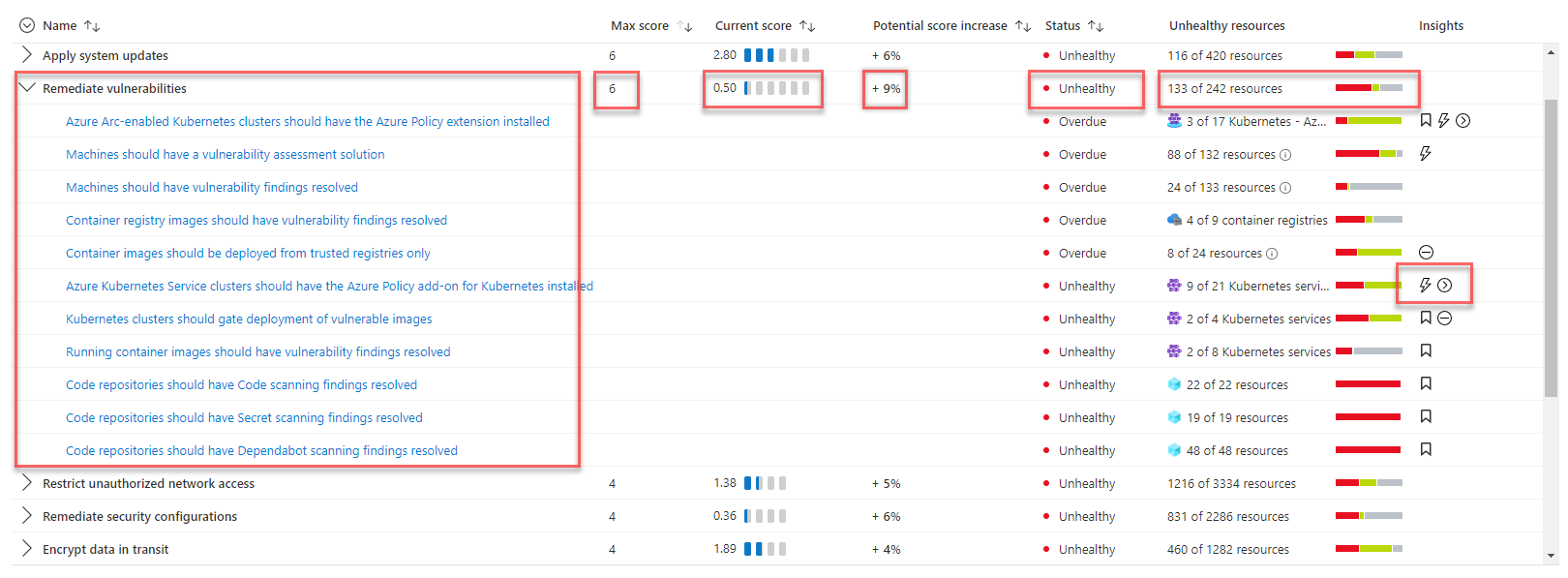
Se la soluzione richiede funzionalità avanzate di gestione della sicurezza e rilevamento delle minacce, ad esempio il rilevamento e l'invio di avvisi di attività sospette, è possibile abilitare la protezione del carico di lavoro cloud singolarmente per risorse diverse.
Ottimizzazione dei costi
Per informazioni sul pilastro dell'ottimizzazione dei costi di Well-Architected Framework, consultare la sezione Ottimizzazione dei costi.
Un vantaggio fondamentale della soluzione data lakehouse è l'architettura scalabile e l'efficienza dei costi. La maggior parte dei componenti della soluzione usa la fatturazione basata sul consumo e la scalabilità automatica. In questa soluzione tutti i dati vengono archiviati in Data Lake Storage. Si paga solo per archiviare i dati se non si eseguono query o elaborano dati.
I prezzi per questa soluzione dipendono dall'utilizzo delle risorse chiave seguenti:
- Azure Synapse Serverless SQL: usare la fatturazione basata sul consumo, pagare solo per ciò che si usa.
- Apache Spark in Azure Synapse: usare la fatturazione basata sul consumo, pagare solo per ciò che si usa.
- Azure Synapse Pipelines: usare la fatturazione basata sul consumo, pagare solo per ciò che si usa.
- Azure Data Lake: usare la fatturazione basata sul consumo, pagare solo per ciò che si usa.
- Power BI: il costo è basato sulla licenza acquistata.
- Collegamento privato: usare la fatturazione basata sul consumo, pagare solo per ciò che si usa.
Diverse soluzioni di protezione della sicurezza hanno diverse modalità di costo. È consigliabile scegliere la soluzione di sicurezza in base alle esigenze aziendali e ai costi della soluzione.
È possibile usare il calcolatore prezzi di Azure per stimare il costo della soluzione.
Eccellenza operativa
Per informazioni sul pilastro dell'eccellenza operativa del framework ben progettato, consultare la sezione Eccellenza operativa.
Usare un agente della pipeline self-hosted abilitato per la rete virtuale per i servizi CI/CD
L'agente della pipeline di Azure DevOps predefinito non supporta la comunicazione di rete virtuale perché usa un intervallo di indirizzi IP molto ampio. Questa soluzione implementa un agente self-hosted di Azure DevOps nella rete virtuale in modo che i processi DevOps possano comunicare senza problemi con gli altri servizi nella soluzione. Le stringhe di connessione e i segreti per l'esecuzione dei servizi CI/CD vengono archiviati in un insieme di credenziali delle chiavi indipendente. Durante il processo di distribuzione, l'agente self-hosted accede all'insieme di credenziali delle chiavi nell'area dati principale per aggiornare le configurazioni delle risorse e i segreti. Per maggiori informazioni, consultare il documento Uso di insiemi di credenziali delle chiavi separati. Questa soluzione usa anche set di scalabilità di macchine virtuali di Microsoft Azure per garantire che il motore DevOps possa aumentare e ridurre automaticamente le prestazioni in base al carico di lavoro.

Implementare l'analisi della sicurezza dell'infrastruttura e i smoke test di sicurezza nella pipeline CI/CD
Uno strumento di analisi statica per l'analisi dell'infrastruttura come file di codice (IaC) può aiutare a rilevare e prevenire errori di configurazione che possono causare problemi di sicurezza o conformità. I test di smoke test di sicurezza assicurano che le misure di sicurezza del sistema essenziali siano abilitate correttamente, proteggendo da errori di distribuzione.
- Usare uno strumento di analisi statica per analizzare i modelli di infrastruttura come codice (IaC) per rilevare e prevenire errori di configurazione che possono causare problemi di sicurezza o conformità. Usare strumenti come Checkov o Terrascan per rilevare e prevenire i rischi per la sicurezza.
- Assicurarsi che la pipeline CD gestisca correttamente gli errori di distribuzione. Qualsiasi errore di distribuzione correlato alle funzionalità di sicurezza deve essere considerato come un errore critico. La pipeline deve ritentare l'azione non riuscita o mantenere la distribuzione.
- Convalidare le misure di sicurezza nella pipeline di distribuzione eseguendo smoke test di sicurezza. I test di smoke test di sicurezza, ad esempio la convalida dello stato di configurazione delle risorse distribuite o dei test case che esaminano gli scenari di sicurezza critici, possono garantire che la progettazione della sicurezza funzioni come previsto.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Herman Wu | Senior Software Engineer
Altri contributori:
- Ian Chen | Principal Software Engineer Lead
- Jose Contreras | Principal Software Engineering
- Roy Chan | Principal Software Engineer Manager
Passaggi successivi
- Documentazione dei prodotti Azure
- Altri articoli
- Che cos'è Azure Synapse Analytics?
- Pool SQL serverless in Azure Synapse Analytics
- Apache Spark in Azure Synapse Analytics
- Pipeline e attività in Azure Data Factory e Azure Synapse Analytics
- Che cos'è Esplora dati di Azure Synapse? (anteprima)
- Funzionalità di Machine Learning in Azure Synapse Analytics
- Che cos'è Microsoft Purview?
- Azure Synapse Analytics e Azure Purview funzionano meglio insieme
- Introduzione ad Azure Data Lake Storage Gen2
- Che cos'è Azure Data Factory?
- Serie di blog di modelli di dati correnti: Data Lakehouse
- Che cos'è Microsoft Defender for Cloud?
- Architettura della piattaforma Data Lakehouse, Data warehouse e Modern Data
- Procedure consigliate per l'organizzazione di aree di lavoro e lakehouse di Azure Synapse
- Informazioni sugli endpoint privati di Azure Synapse
- Azure Synapse Analytics - Nuove informazioni dettagliate sulla sicurezza dei dati
- Baseline di sicurezza per Azure per pool SQL di Azure Synapse dedicato (in precedenza SQL Data Warehouse)
- Cloud Network Security 101: endpoint di servizio di Azure vs endpoint privati
- Come configurare il controllo di accesso per l'area di lavoro di Azure Synapse
- Connettersi ad Azure Synapse Studio usando hub di collegamento privato di Azure
- Procedura: distribuire gli artefatti dell'area di lavoro di Azure Synapse in un'area di lavoro di Azure Synapse di rete virtuale gestita
- Integrazione e recapito continui per un'area di lavoro Azure Synapse Analytics
- Punteggio di sicurezza in Microsoft Defender for Cloud
- Procedure consigliate per Azure Key Vault
- Scenario di Adatum Corporation per la gestione e l'analisi dei dati in Azure