I sistemi multi-tenant condividono le risorse tra due o più tenant. Poiché i tenant usano le stesse risorse condivise, l'attività di un tenant può avere un impatto negativo sull'uso del sistema da parte di un altro tenant.
Descrizione del problema
Quando si crea un servizio che deve essere condiviso da più clienti o tenant, è possibile crearlo in modo che sia multi-tenant. Un vantaggio dei sistemi multi-tenant è che le risorse possono essere inserite in un pool e condivise tra i tenant. Questo si traduce spesso in costi ridotti e maggiore efficienza. Se tuttavia un singolo tenant usa una quantità sproporzionata delle risorse disponibili nel sistema, le prestazioni complessive del sistema possono risentirne. Il problema di tipo noisy neighbor si verifica quando le prestazioni di un tenant sono ridotte a causa delle attività di un altro tenant.
Si consideri un sistema multi-tenant di esempio con due tenant. I modelli di utilizzo del tenant A e i modelli di utilizzo del tenant B coincidono. Nei momenti di picco, il tenant A usa tutte le risorse del sistema, il che significa che tutte le richieste eseguite dal tenant B hanno esito negativo. In altre parole, l'utilizzo totale delle risorse è superiore alla capacità del sistema:
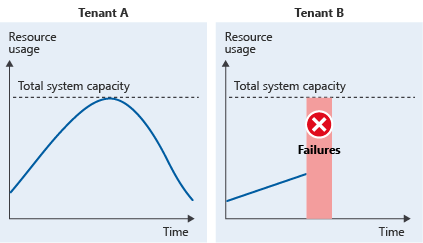
È probabile che la richiesta del tenant che arriva prima avrà la precedenza. Per l'altro tenant si verificherà quindi un problema di tipo noisy neighbor. In alternativa, entrambi i tenant potrebbero riscontrare problemi di prestazioni.
Il problema di tipo noisy neighbor si verifica anche quando ogni singolo tenant utilizza quantità relativamente ridotte della capacità del sistema, ma l'utilizzo collettivo delle risorse da parte di più tenant comporta un picco nell'utilizzo complessivo:
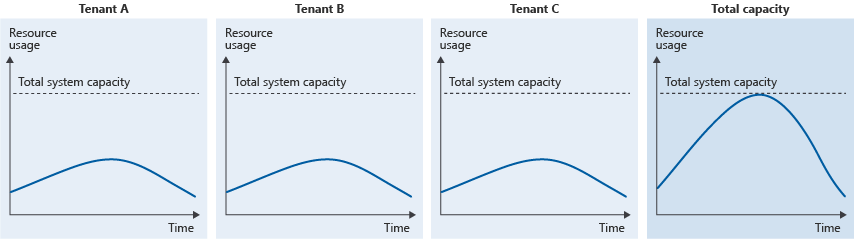
Questa situazione può verificarsi quando si dispone di più tenant con modelli di utilizzo simili o in cui non è stato effettuato il provisioning di capacità sufficiente per il carico collettivo nel sistema.
Come risolvere il problema
I problemi vicini rumorosi sono un rischio intrinseco quando si condivide una singola risorsa e non è possibile eliminare completamente la possibilità di essere colpiti da un vicino rumoroso. Esistono tuttavia alcuni passaggi che sia i client che i provider di servizi possono eseguire per ridurre la probabilità di problemi di prossimità rumorosi o per attenuarne gli effetti quando vengono osservati.
Azioni che i clienti possono intraprendere
- Assicurarsi che l'applicazione gestisca la limitazione del servizio, per ridurre l'esecuzione di richieste non necessarie al servizio. Assicurarsi che l'applicazione segua le procedure consigliate per ripetere le richieste che hanno ricevuto una risposta di errore temporaneo.
- Acquistare capacità riservata, se disponibile. Ad esempio, quando si usa Azure Cosmos DB, acquistare velocità effettiva riservata e quando si usa ExpressRoute, effettuare il provisioning di circuiti separati per gli ambienti sensibili alle prestazioni.
- Eseguire la migrazione a un'istanza a tenant singolo del servizio o a un livello di servizio con maggiori garanzie di isolamento. Quando, ad esempio, si usa il bus di servizio, eseguire la migrazione al livello Premium e, quando si usa la cache di Azure per Redis, effettuare il provisioning di una cache di livello Standard o Premium.
Azioni che i provider di servizi possono intraprendere
- Monitorare l'utilizzo delle risorse per il sistema. Monitorare sia l'utilizzo complessivo delle risorse che le risorse usate da ogni tenant. Configurare avvisi per rilevare i picchi nell'utilizzo delle risorse e, se possibile, configurare l'automazione per mitigare automaticamente i problemi noti aumentando le prestazioni o il numero di istanze.
- Applicare la governance delle risorse. Valutare la possibilità di applicare criteri che evitano un singolo tenant di sovraccaricare il sistema e ridurre la capacità disponibile ad altri utenti. Questo passaggio può essere eseguito come applicazione di quote, tramite il modello di limitazione o il modello di limitazione della velocità.
- Effettuare il provisioning di un'infrastruttura maggiore. Per questo processo potrebbe essere necessario aumentare le prestazioni aggiornando alcuni dei componenti della soluzione oppure aumentare il numero di istanze effettuando il provisioning di partizioni aggiuntive, se si segue il modello di partizionamento orizzontale, o di stamp, se si segue il modello degli stamp di distribuzione.
- Abilitare i tenant per acquistare capacità pre-provisioning o riservata. Questa capacità offre ai tenant maggiore certezza che la soluzione gestisca adeguatamente il carico di lavoro.
- Uniformare l'utilizzo delle risorse dei tenant. Ad esempio, è possibile provare uno degli approcci seguenti:
- Se si ospitano più istanze della soluzione, valutare l'opportunità di ribilanciare i tenant tra le istanze o gli stamp. Si consideri, ad esempio, di inserire tenant con modelli di utilizzo prevedibili e simili tra più timbri, per appiattire i picchi di utilizzo.
- Considerare se sono presenti processi in background o carichi di lavoro a elevato utilizzo di calcolo senza rigidi requisiti temporali. Eseguire questi carichi di lavoro in modo asincrono in orari di minore attività per mantenere la capacità massima delle risorse per i carichi di lavoro sensibili al tempo.
- Controllare se i servizi downstream forniscono controlli per attenuare i problemi dei vicini rumorosi. Quando, ad esempio, si usa Kubernetes, valutare l'opportunità di usare i limiti dei pod e, quando si usa Service Fabric, le funzionalità di governance predefinite.
- Limitare le operazioni che i tenant possono eseguire. Ad esempio, limitare i tenant dall'esecuzione di operazioni che eseguiranno query di database di grandi dimensioni, ad esempio specificando un numero massimo di record restituiti o un limite di tempo massimo per le query. Questa azione riduce il rischio che i tenant intraprendano azioni che potrebbero influire negativamente sugli altri tenant.
- Fornire un sistema QoS (Quality of Service). Quando si applica il sistema QoS, si classificare in ordine di priorità alcuni processi o carichi di lavoro rispetto ad altri. Includendo QoS nella progettazione e nell'architettura, è possibile assicurarsi che le operazioni con priorità elevata abbiano la precedenza nelle situazioni con notevole pressione sulle risorse.
Considerazioni
Nella maggior parte dei casi, i singoli tenant non intendono causare problemi con i vicini rumorosi. I singoli tenant potrebbero anche non essere consapevoli del fatto che i carichi di lavoro causano problemi di prossimità rumorosi per altri utenti. Tuttavia, è anche possibile che alcuni tenant possano sfruttare le vulnerabilità nei componenti condivisi per attaccare un servizio, singolarmente o eseguendo un attacco DDoS (Distributed Denial of Service).
Indipendentemente dalla causa, è importante considerare questi problemi come questioni di governance delle risorse e applicare quote di utilizzo, limitazioni e controlli di governance per attenuare il problema.
Nota
Assicurarsi di comunicare ai client le eventuali limitazioni applicate o le eventuali quote di utilizzo per il servizio. È importante che gestiscano in modo affidabile le richieste non riuscite e che non siano colti di sorpresa da eventuali limitazioni o quote applicate.
Come rilevare il problema
Dal punto di vista di un client, il problema del vicino rumoroso si manifesta in genere come richieste non riuscite al servizio o come richieste che richiedono molto tempo per il completamento. In particolare, se la stessa richiesta ha esito positivo in altri momenti e sembra avere esito negativo in modo casuale, potrebbe verificarsi un problema rumoroso adiacente. Le applicazioni client dovrebbero registrare i dati di telemetria per tenere traccia della percentuale di successo e delle prestazioni delle richieste ai servizi. Le applicazioni dovrebbero inoltre registrare le metriche delle prestazioni di base per poter eseguire confronti.
Dal punto di vista di un servizio, il problema rumoroso vicino potrebbe apparire in diversi modi:
- Picchi nell'utilizzo delle risorse. È importante avere una conoscenza chiara del normale utilizzo delle risorse di base e configurare il monitoraggio e gli avvisi per rilevare i picchi nell'utilizzo delle risorse. Assicurarsi di prendere in considerazione tutte le risorse che potrebbero influire sulle prestazioni o sulla disponibilità del servizio. Queste risorse includono metriche come l'utilizzo della CPU e della memoria del server, l'I/O su disco, l'utilizzo del database, il traffico di rete e le metriche esposte dai servizi gestiti, ad esempio il numero di richieste e le metriche delle prestazioni sintetiche e astratte, quali le unità richiesta di Azure Cosmos DB.
- Errori durante l'esecuzione di un'operazione per un tenant. In particolare, cercare gli errori che si verificano quando un tenant non usa una grande parte delle risorse del sistema. Un modello di questo tipo potrebbe indicare che il tenant è vittima del problema del vicino rumoroso. Valutare l'opportunità di tenere traccia dell'utilizzo delle risorse in base al tenant. Quando, ad esempio, si usa Azure Cosmos DB, valutare l'opportunità di registrare le unità usate per ogni richiesta e aggiungere l'identificatore del tenant come dimensione ai dati di telemetria, per poter aggregare il consumo di unità richiesta per ogni tenant.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- John Downs | Principal Software Engineer
Altri contributori:
- Chad Kittel | Principal Software Engineer
- Paolo Salvatori | Principal Customer Engineer, FastTrack per Azure
- Daniel Scott-Raynsford | Partner Technology Strategist
- Arsen Vladimirintune | Principal Customer Engineer, FastTrack per Azure
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.