Dividere un archivio dati in un set di partizioni orizzontali. Questa operazione può migliorare la scalabilità per l'archiviazione e l'accesso a grandi volumi di dati.
Contesto e problema
Un archivio dati ospitato in un singolo server può essere soggetto alle limitazioni seguenti:
Spazio di archiviazione. Un archivio dati per un'applicazione cloud su larga scala è progettato per contenere un'enorme quantità di dati che può aumentare considerevolmente nel tempo. In un server, la quantità di spazio di archiviazione su disco è in genere limitata, ma è possibile sostituire i dischi esistenti con versioni più capienti o aggiungere altri dischi in un computer man mano che i volumi di dati aumentano. Il sistema finirà tuttavia per raggiungere un limite in cui non è più possibile aumentare facilmente la capacità di archiviazione di un server specifico.
Risorse di calcolo. Un'applicazione cloud è progettata per supportare un numero elevato di utenti simultanei, ognuno dei quali esegue query che recuperano informazioni dall'archivio dati. Un singolo server che ospita l'archivio dati potrebbe non essere in grado di fornire la potenza di calcolo necessaria per supportare questo carico, causando tempi di risposta estesi per gli utenti e errori frequenti quando le applicazioni che tentano di archiviare e recuperare il timeout dei dati. Potrebbe essere possibile aggiungere processori di memoria o di aggiornamento, ma il sistema raggiungerà un limite quando non è possibile aumentare ulteriormente le risorse di calcolo.
Larghezza di banda della rete. Le prestazioni di un archivio dati in esecuzione in un server singolo solo sostanzialmente governate dalla frequenza con cui il server può ricevere richieste e inviare risposte. È possibile che il volume di traffico della rete superi la capacità della rete usata per la connessione al server e che pertanto le richieste non riescano.
Geografia. Potrebbe essere necessario archiviare i dati generati da utenti specifici nella stessa area degli utenti stessi per motivi legali, di conformità o di prestazioni o per ridurre la latenza dell'accesso ai dati. Se gli utenti sono distribuiti in più aree o paesi diversi, potrebbe non essere possibile archiviare tutti i dati per l'applicazione in un unico archivio dati.
La scalabilità verticale tramite l'aggiunta di capacità del disco, potenza di elaborazione, memoria e connessioni di rete può rimandare gli effetti di alcune di queste limitazioni, ma è probabilmente una soluzione solo temporanea. Un'applicazione cloud commerciale in grado di supportare un numero elevato di utenti e i volumi elevati di dati deve essere in grado di scalare pressoché indefinitamente, pertanto la scalabilità verticale non è necessariamente la soluzione migliore.
Soluzione
È possibile dividere un archivio dati in partizioni orizzontali. Ogni partizione ha lo stesso schema, ma contiene il proprio subset di dati distinto. Una partizione è un archivio dati a sé stante (può contenere i dati per molte entità di tipi diversi), in esecuzione in un server che funge da nodo di archiviazione.
Questo modello offre i vantaggi seguenti:
È possibile scalare il sistema orizzontalmente aggiungendo altre partizioni che vengono eseguite in altri nodi di archiviazione.
Un sistema può usare hardware preconfigurato anziché computer specializzati e costosi per ogni nodo di archiviazione.
È possibile ridurre la contesa e migliorare le prestazioni bilanciando il carico di lavoro tra le partizioni.
Nel cloud, le partizioni possono essere situate fisicamente vicino agli utenti che accedono ai dati.
Quando si divide un archivio dati in partizioni, decidere quali dati devono essere inseriti in ognuna. Una partizione contiene, in genere, elementi che rientrano in un intervallo specificato, determinato da uno o più attributi dei dati. Questi attributi costituiscono la chiave di partizione. La chiave di partizione deve essere statica. Non deve essere basata su dati che potrebbero cambiare.
Il partizionamento orizzontale organizza fisicamente i dati. Quando un'applicazione archivia e recupera i dati, la logica di partizionamento orizzontale indirizza l'applicazione verso la partizione appropriata. Questa logica di partizionamento può essere implementata come parte del codice di accesso ai dati nell'applicazione. Può, in alternativa, essere implementata dal sistema di archiviazione dei dati se supporta il partizionamento orizzontale in modo trasparente.
L'astrazione della posizione fisica dei dati nella logica di partizionamento orizzontale offre un elevato livello di controllo su quali partizioni contengono quali dati. Consente inoltre la migrazione dei dati tra le partizioni senza dover rielaborare la logica di business di un'applicazione nel caso in cui i dati nelle partizioni debbano essere ridistribuiti in un secondo momento (ad esempio, se le partizioni diventano sbilanciate). Il compromesso è il sovraccarico nell'accesso ai dati aggiuntivo necessario per determinare la posizione di ogni elemento dati che viene recuperato.
Per assicurare prestazioni e scalabilità ottimali, è importante suddividere i dati in un modo appropriato ai tipi di query che vengono eseguite dall'applicazione. In molti casi, è improbabile che lo schema di partizionamento corrisponda esattamente ai requisiti di ogni query. Ad esempio, in un sistema multi-tenant un'applicazione potrebbe dover recuperare i dati del tenant usando l'ID tenant, ma potrebbe anche dover cercare questi dati in base ad altri attributi, ad esempio il nome o la posizione del tenant. Per gestire queste situazioni, implementare una strategia di partizionamento orizzontale con una chiave di partizione che supporti le query di uso più comune.
Se le query recuperano regolarmente i dati usando una combinazione di valori di attributo, è probabilmente possibile definire una chiave di partizione composita collegando insieme gli attributi. In alternativa, usare un modello, ad esempio Tabella dell'indice per offrire una ricerca veloce dei dati in base ad attributi che non sono coperti dalla chiave di partizione.
Strategie di partizionamento
Quando si seleziona una chiave di partizionamento e si decide come distribuire i dati tra le partizioni, si usano in genere tre strategie. Si noti che non è necessario che esista una corrispondenza uno-a-uno tra le partizioni e i server che li ospitano. Un singolo server può ospitare più partizioni. Le strategie sono:
Strategia di ricerca. In questa strategia la logica di partizionamento orizzontale implementa una mappa che esegue il routing di una richiesta di dati verso la partizione che contiene quei dati usando la chiave di partizione. In un'applicazione multi-tenant tutti i dati per un tenant possono essere archiviati insieme in una partizione usando l'ID tenant come chiave di partizione. Più tenant possono condividere la stessa partizione, ma i dati per un singolo tenant non vengono distribuiti tra più partizioni. Nella figura seguente viene illustrato il partizionamento dei dati di tenant in base agli ID tenant.
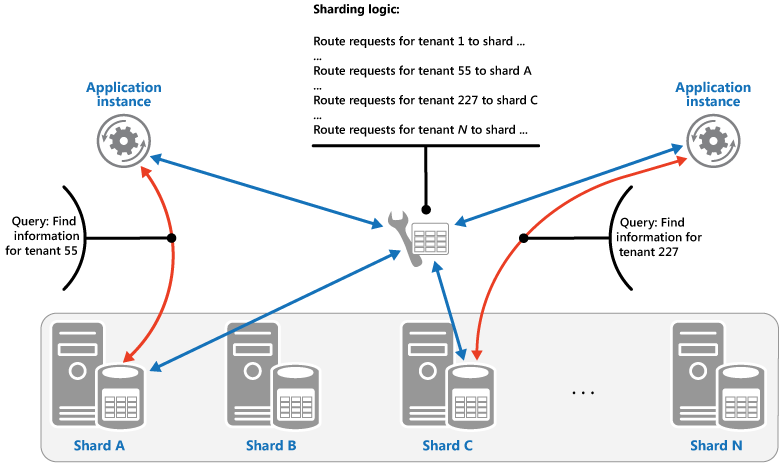
Il mapping tra il valore della chiave di partizione e l'archiviazione fisica su cui i dati esistono possono essere basati su partizioni fisiche in cui ogni valore della chiave di partizione è mappato a una partizione fisica. In alternativa, una tecnica più flessibile per il ribilanciamento delle partizioni è il partizionamento virtuale, in cui i valori delle chiavi di partizione vengono mappati allo stesso numero di partizioni virtuali, che a loro volta eseguono il mapping a un minor numero di partizioni fisiche. In questo approccio, un'applicazione individua i dati usando un valore di chiave di partizione che fa riferimento a una partizione virtuale e il sistema esegue il mapping trasparente delle partizioni virtuali alle partizioni fisiche. Il mapping tra una partizione virtuale e una partizione fisica può cambiare senza che sia necessario modificare il codice dell'applicazione per usare un set diverso di valori di chiave di partizione.
Strategia di intervallo. Questa strategia raggruppa gli elementi correlati nella stessa partizione e li ordina in base alla chiave di partizione. Le chiavi di partizione sono sequenziali. Questa strategia è utile per le applicazioni che recuperano spesso set di elementi usando query di intervallo, vale a dire query che restituiscono un set di dati per una chiave di partizione che rientra in un intervallo specificato. Se, ad esempio, un'applicazione deve regolarmente trovare tutti gli ordini effettuati in un determinato mese, questi dati possono essere recuperati più rapidamente se sono archiviati in ordine di data e ora nella stessa partizione. Se ogni ordine fosse archiviato in una partizione diversa, lo si dovrebbe recuperare individualmente mediante l'esecuzione di un numero elevato di query di tipo punto, vale a dire di query che restituiscono un singolo elemento dati. La figura successiva illustra l'archiviazione di set sequenziali (intervalli) di dati in partizioni.
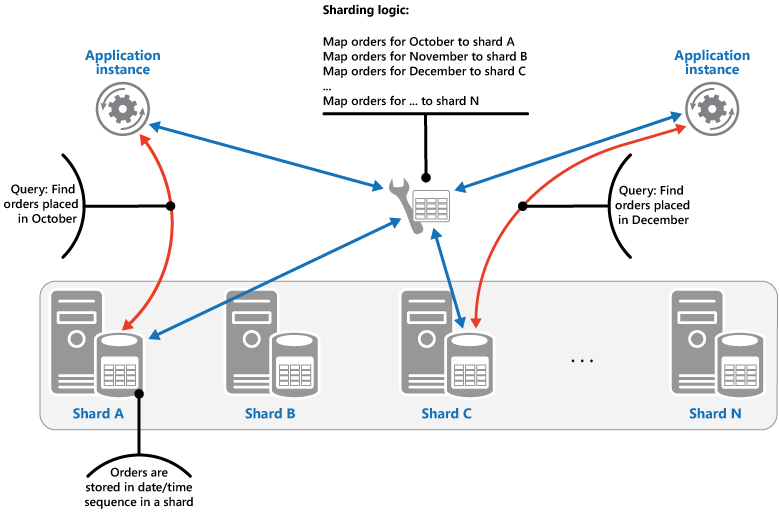
In questo esempio, la chiave di partizione è una chiave composta contenente il mese degli ordini come elemento più significativo, seguito dal giorno e dall'ora degli ordini. I dati degli ordini vengono ordinati naturalmente quando nuovi ordini vengono creati e aggiunti a una partizione. Alcuni archivi dati supportano chiavi di partizionamento in due parti contenenti un elemento di chiave di partizione che identifica la partizione e una chiave di riga che identifica in modo univoco un elemento nella partizione. I dati vengono in genere conservati in ordine di chiave di riga nella partizione. Gli elementi che sono soggetti a query di intervallo e devono essere raggruppati possono usare una chiave di partizione che ha lo stesso valore per la chiave di partizione, ma un valore univoco per la chiave di riga.
Strategia Hash. Lo scopo di questa strategia consiste nel ridurre l'eventualità che si creino aree sensibili, vale a dire partizioni che ricevono una quantità sproporzionata di carico. Questa strategia distribuisce i dati tra le partizioni in modo da ottenere un equilibrio tra la dimensione di ogni partizione e il carico medio che interessa ogni partizione. La logica di partizionamento calcola la partizione per archiviare un elemento in base a un hash di uno o più attributi dei dati. La funzione hash scelta deve distribuire i dati uniformemente tra le partizioni, possibilmente introducendo un elemento casuale nel calcolo. Nella figura riportata di seguito viene illustrato il partizionamento dei dati di tenant in base a un hash di ID tenant.
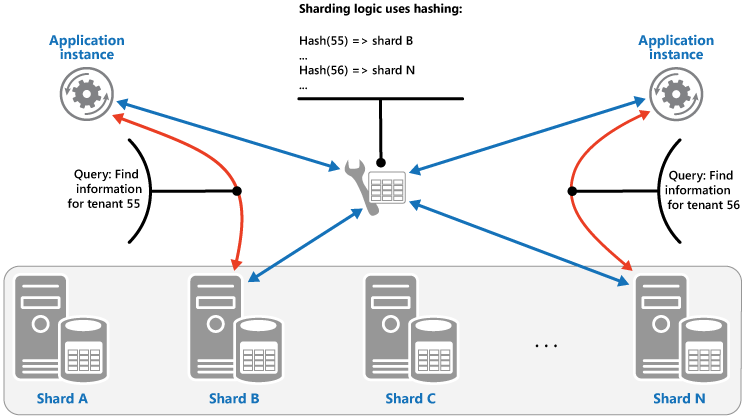
Per comprendere il vantaggio della strategia hash rispetto ad altre strategie di partizionamento orizzontale, considerare come un'applicazione multi-tenant che registra i nuovi tenant in sequenza potrebbe assegnare i tenant alle partizioni nell'archivio dati. Quando si usa la strategia di intervallo, i dati per i tenant da 1 a n vengono memorizzato nella partizione A, quelli per i tenant da n+1 a m vengono memorizzati nella partizione B e così via. Se i tenant registrati più di recente sono anche i più attivi, la maggior parte delle attività di dati si verificherà in un numero ridotto di partizioni, creando così aree sensibili. La strategia Hash, al contrario, alloca i tenant alle partizioni in base a un hash dei relativi ID tenant. Ciò significa che i tenant sequenziali sono probabilmente da allocare in partizioni diverse, con conseguente distribuzione del carico tra di loro. La figura precedente mostra questa situazione per i tenant 55 e 56.
Le tre strategie di partizionamento orizzontale presentano i vantaggi e le considerazioni seguenti:
Ricerca. Questa strategia offre maggiore controllo sulle modalità di configurazione e di utilizzo delle partizioni. L'utilizzo di partizioni virtuali riduce l'impatto durante il ribilanciamento dei dati poiché consente di aggiungere nuove partizioni fisiche per bilanciare il carico di lavoro. Il mapping tra una partizione virtuale e le partizioni fisiche che implementano la partizione può essere modificato senza influire sul codice dell'applicazione che usa una chiave di partizione per archiviare e recuperare i dati. La ricerca delle posizioni delle partizioni può imporre un sovraccarico aggiuntivo.
Intervallo. Questa strategia è facile da implementare ed è ideale con le query di intervallo, in quanto possono spesso recuperare più elementi dati da una singola partizione con una singola operazione. Questa strategia offre una gestione dei dati più semplice. Se, ad esempio, gli utenti nella stessa area si trovano nella stessa partizione, è possibile programmare gli aggiornamenti in ogni fuso orario in base al modello di carico e richiesta locale. Questa strategia, tuttavia, non fornisce il bilanciamento ottimale tra le partizioni. Il ribilanciamento delle partizioni è difficile e potrebbe non risolvere il problema di carico non uniforme se la maggior parte delle attività è per le chiavi di partizione adiacenti.
Hash. Questa strategia offre più possibilità di distribuire i dati e il carico in modo uniforme. Il routing delle richieste può essere eseguito direttamente tramite la funzione hash. Non è necessario mantenere una mappa. Si noti che il calcolo dell'hash impone un sovraccarico aggiuntivo. Il ribilanciamento delle partizioni risulta inoltre difficile.
I sistemi più comuni di partizionamento orizzontale implementano uno degli approcci descritti in precedenza, ma occorre anche considerare i requisiti aziendali delle applicazioni e i relativi modelli di utilizzo dei dati. Ad esempio, in un'applicazione multi-tenant:
È possibile partizionare i dati in base al carico di lavoro. È possibile separare i dati per i tenant altamente volatili in partizioni separate. La velocità di accesso ai dati per altri tenant potrebbe essere migliorata di conseguenza.
È possibile partizionare i dati in base alla posizione dei tenant. È possibile portare i dati di tenant in un'area geografica specifica offline per la manutenzione e il backup durante le ore non di punta nell'area, mentre i dati dei tenant in altre aree restano online e accessibili durante le ore lavorative.
È possibile assegnare tenant di valore elevato ai propri tenant privati, ad alte prestazioni, partizioni caricate in modo leggero, mentre i tenant con valore inferiore potrebbero essere tenuti a condividere partizioni più dense e occupate.
I dati dei tenant che richiedono un elevato grado di isolamento dei dati e di privacy possono essere archiviati in un server completamente separato.
Operazioni di spostamento dei dati e scalabilità
Ognuna delle strategie di partizionamento orizzontale implica funzionalità e livelli di complessità diversi per la gestione della scalabilità orizzontale e verticale, lo spostamento dei dati e la gestione dello stato.
La strategia di ricerca consente di eseguire operazioni di spostamento dei dati e scalabilità a livello di utente, online o offline. La tecnica consiste nel sospendere alcune o tutte le attività dell'utente (ad esempio durante i periodi non di punta), spostare i dati nella nuova partizione virtuale o fisica, modificare i mapping, invalidare o aggiornare tutte le cache che contengono questi dati e successivamente consentire all'utente la ripresa dell'attività. Questo tipo di operazione spesso può essere gestito centralmente. La strategia di ricerca richiede che lo stato sia altamente memorizzabile nella cache e replicabile.
La strategia di intervallo impone alcune limitazioni sulle operazioni di spostamento dei dati e di scalabilità, che in genere devono essere effettuate quando l'archivio dati o una parte di esso è offline, poiché i dati devono essere suddivisi e uniti tra le partizioni. Lo spostamento dei dati per ribilanciare le partizioni potrebbe non risolvere il problema di carico non uniforme se la maggior parte delle attività avviene per le chiavi di partizione adiacenti o gli identificatori di dati che rientrano nello stesso intervallo. La strategia di intervallo potrebbe anche richiedere il mantenimento dello stato per eseguire il mapping degli intervalli nelle partizioni fisiche.
La strategia Hash rende più complesse le operazioni di spostamento dei dati e di scalabilità perché le chiavi di partizione sono hash degli identificatori di dati o delle chiavi di partizione. La nuova posizione di ciascuna partizione deve essere determinata dalla funzione hash o dalla funzione modificata per creare i mapping corretti. La strategia Hash non richiede invece la manutenzione dello stato.
Considerazioni e problemi
Prima di decidere come implementare questo modello, considerare quanto segue:
Il partizionamento orizzontale è complementare ad altre forme di partizionamento, ad esempio il partizionamento verticale e il partizionamento funzionale. Una singola partizione, ad esempio, può contenere entità che sono state partizionate verticalmente e una partizione funzionale può essere implementata come più partizioni. Per altre informazioni sul partizionamento, vedere Linee guida di partizionamento di dati.
Mantenere le partizioni equilibrate in modo che tutte gestiscano un volume di I/O simile. Dal momento che i dati vengono inseriti ed eliminati, è necessario ribilanciare periodicamente le partizioni per garantire una distribuzione uniforme e per ridurre le possibilità che si creino aree sensibili. Il ribilanciamento può essere un'operazione costosa. Per ridurre la necessità di ribilanciamento, pianificare la crescita assicurando che ogni partizione contenga spazio libero sufficiente per gestire il volume previsto di modifiche. Occorre inoltre sviluppare strategie e script da usare per ribilanciare rapidamente le partizioni in caso di necessità.
Usare dati stabili per la chiave di partizione. Se la chiave di partizione cambia, è possibile che l'elemento dati corrispondente debba essere spostato tra partizioni, aumentando la quantità di lavoro eseguito dalle operazioni di aggiornamento. Per questo motivo, evitare di basare la chiave di partizione su informazioni potenzialmente volatili. Cercare invece attributi che siano invariabili o che formino una chiave naturalmente.
Assicurarsi che le chiavi di partizione siano univoche. Evitare, ad esempio, di usare campi a incremento automatico come chiavi di partizione. In alcuni sistemi, i campi autoincremented non possono essere coordinati tra partizioni, con conseguente conseguente presenza di elementi in partizioni diverse con la stessa chiave di partizione.
Anche i valori che vengono incrementati automaticamente in altri campi che non sono chiavi di partizione possono causare problemi. Se, ad esempio, si usano campi a incremento automatico per generare ID univoci, è possibile che a due diversi elementi posti in partizioni diverse venga assegnato lo stesso ID.
Potrebbe non essere possibile progettare una chiave di partizione che corrisponde ai requisiti di ogni possibile query sui dati. Partizionare i dati per supportare le query di uso più comune e, se necessario, creare tabelle dell'indice secondarie per supportare le query che recuperano i dati usando criteri basati su attributi che non fanno parte della chiave di partizione. Per altre informazioni, vedere Index Table pattern (Modello di tabella dell'indice).
Le query che accedono solo a una singola partizione sono più efficienti di quelle che recuperano i dati da più partizioni. È pertanto consigliabile evitare di implementare un sistema di partizionamento orizzontale che comporta da parte delle applicazioni l'esecuzione di un numero elevato di query che creano un join con i dati contenuti in partizioni diverse. Ricordare che una singola partizione può contenere i dati di più tipi di entità. Considerare la denormalizzazione dei dati per mantenere le entità correlate comunemente soggette a query (ad esempio i dettagli di clienti e ordini inseriti) nella stessa partizione per ridurre il numero di letture separate eseguite da un'applicazione.
Se un'entità in una partizione fa riferimento a un'entità memorizzata in un'altra partizione, includere la chiave di partizione della seconda entità come parte dello schema della prima entità. Questa operazione può contribuire a migliorare le prestazioni delle query che fanno riferimento a dati correlati tra partizioni.
Se un'applicazione deve eseguire query che recuperano dati da più partizioni, potrebbe essere possibile recuperare questi dati tramite attività in parallelo. Un esempio sono le query di tipo fan-out, in cui i dati di più partizioni vengono recuperati in parallelo e quindi aggregati in un singolo risultato. Questo approccio aumenta tuttavia inevitabilmente il livello di complessità della logica di accesso ai dati di una soluzione.
Per molte applicazioni, la creazione di un numero elevato di partizioni di piccole dimensioni può essere più efficiente rispetto all'utilizzo di un numero ridotto di partizioni di grandi dimensioni, perché può offrire maggiori opportunità di bilanciamento del carico. Questo approccio può essere utile anche quando si prevede di dover migrare le partizioni da una posizione fisica a un'altra. Lo spostamento di una partizione di piccole dimensioni è più rapido rispetto allo spostamento di una di grandi dimensioni.
Verificare che le risorse disponibili in ogni nodo di archiviazione della partizione siano sufficienti per gestire i requisiti di scalabilità in termini di dimensioni dei dati e di velocità effettiva. Per altre informazioni, vedere la sezione "Progettazione di partizioni per la scalabilità" in Indicazioni sul partizionamento dei dati.
Prendere in considerazione di replicare i dati di riferimento in tutte le partizioni. Se un'operazione che recupera i dati da una partizione fa anche riferimento a dati statici o lenti come parte della stessa query, aggiungere questi dati alla partizione. L'applicazione può quindi recuperare facilmente tutti i dati per la query, senza dover eseguire un round trip aggiuntivo in un archivio dati separato.
Se i dati di riferimento contenuti in più partizioni cambiano, il sistema deve sincronizzare le modifiche tra tutte le partizioni. Il sistema può essere soggetto a un livello di incoerenza durante la sincronizzazione. In questo caso, è consigliabile progettare le applicazioni in modo che possano gestire questa situazione.
Può essere difficile mantenere l'integrità referenziale e la coerenza tra le partizioni, pertanto è necessario ridurre al minimo le operazioni che influiscono sui dati in più partizioni. Se un'applicazione deve modificare i dati tra partizioni, valutare se la coerenza dei dati completa è effettivamente necessaria. Al contrario, un approccio comune nel cloud consiste nell'implementare la coerenza finale. I dati in ogni partizione vengono aggiornati separatamente e la logica dell'applicazione deve garantire che tutti gli aggiornamenti vengano completati correttamente, nonché gestire le incoerenze che possono sorgere dalle query sui dati durante l'esecuzione di un'operazione con coerenza finale. Per altre informazioni sull'implementazione della coerenza finale, vedere Data Consistency Primer (Informazioni relative alla coerenza dei dati).
La configurazione e la gestione di un numero elevato di partizioni possono risultare difficili. Le attività, quali il monitoraggio, il backup, il controllo della coerenza e la registrazione o il controllo, devono essere eseguite in più partizioni e server, possibilmente contenuti in più posizioni. Queste attività vengono implementate usando script o altre soluzioni di automazione, ma ciò potrebbe non eliminare completamente i requisiti amministrativi aggiuntivi.
Le partizioni possono essere posizionate geograficamente in modo che i dati in esse contenuti siano vicini alle istanze di un'applicazione che li usano. Questo approccio consente di migliorare notevolmente le prestazioni, ma richiede considerazioni aggiuntive sulle attività che devono accedere a più partizioni in posizioni diverse.
Quando usare questo modello
Usare questo modello quando un archivio dati deve essere ridimensionato oltre le risorse disponibili a un singolo nodo di archiviazione o per migliorare le prestazioni riducendo la contesa in un archivio dati.
Nota
L'obiettivo principale del partizionamento orizzontale è di migliorare le prestazioni e la scalabilità di un sistema, ma come sottoprodotto può anche migliorare la disponibilità a causa della modalità di suddivisione dei dati in partizioni distinte. Un errore in una partizione non impedisce necessariamente a un'applicazione di accedere ai dati contenuti in altre partizioni e un operatore può eseguire la manutenzione o il ripristino di una o più partizioni senza rendere inaccessibili tutti i dati a un'applicazione. Per altre informazioni, vedere Linee guida di partizionamento di dati.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello di partizionamento orizzontale può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Ad esempio:
| Concetto fondamentale | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | Poiché i dati o l'elaborazione sono isolati nella partizione, un malfunzionamento in una partizione rimane isolato in tale partizione. - PARTIZIONAMENTO dei dati RE:06 - RE:07 Conservazione automatica |
| L'ottimizzazione dei costi è incentrata sul mantenimento e sul miglioramento del ritorno del carico di lavoro sugli investimenti. | Un sistema che implementa le partizioni spesso trae vantaggio dall'uso di più istanze di risorse di calcolo o archiviazione meno costose anziché da una singola risorsa più costosa. In molti casi, questa configurazione può risparmiare denaro. - Costi dei componenti CO:07 |
| L'efficienza delle prestazioni consente al carico di lavoro di soddisfare in modo efficiente le richieste tramite ottimizzazioni in termini di scalabilità, dati, codice. | Quando si usa il partizionamento orizzontale nella strategia di ridimensionamento, i dati o l'elaborazione sono isolati in una partizione, quindi competono per le risorse solo con altre richieste indirizzate a tale partizione. È anche possibile usare il partizionamento orizzontale per ottimizzare in base all'area geografica. - PE:05 Ridimensionamento e partizionamento - Prestazioni dei dati PE:08 |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
Si consideri un sito Web che presenta una vasta raccolta di informazioni sui libri pubblicati in tutto il mondo. Il numero di libri possibili catalogati in questo carico di lavoro e i modelli di query/utilizzo tipici indicano l'utilizzo di un singolo database relazionale per archiviare le informazioni del libro. L'architetto del carico di lavoro decide di partizionare i dati in più istanze di database, usando il numero isBN (International Standard Book Number) statico dei libri per la chiave di partizione. In particolare, usano la cifra di spunta (0 - 10) del codice ISBN, in quanto fornisce 11 possibili partizioni logiche e i dati verranno equilibrati in ogni partizione. Per iniziare, decide di raggruppare le 11 partizioni logiche in tre database di partizioni fisiche. Usano l'approccio di partizionamento orizzontale della ricerca e archiviano le informazioni di mapping da chiave a server in un database della mappa partizioni.
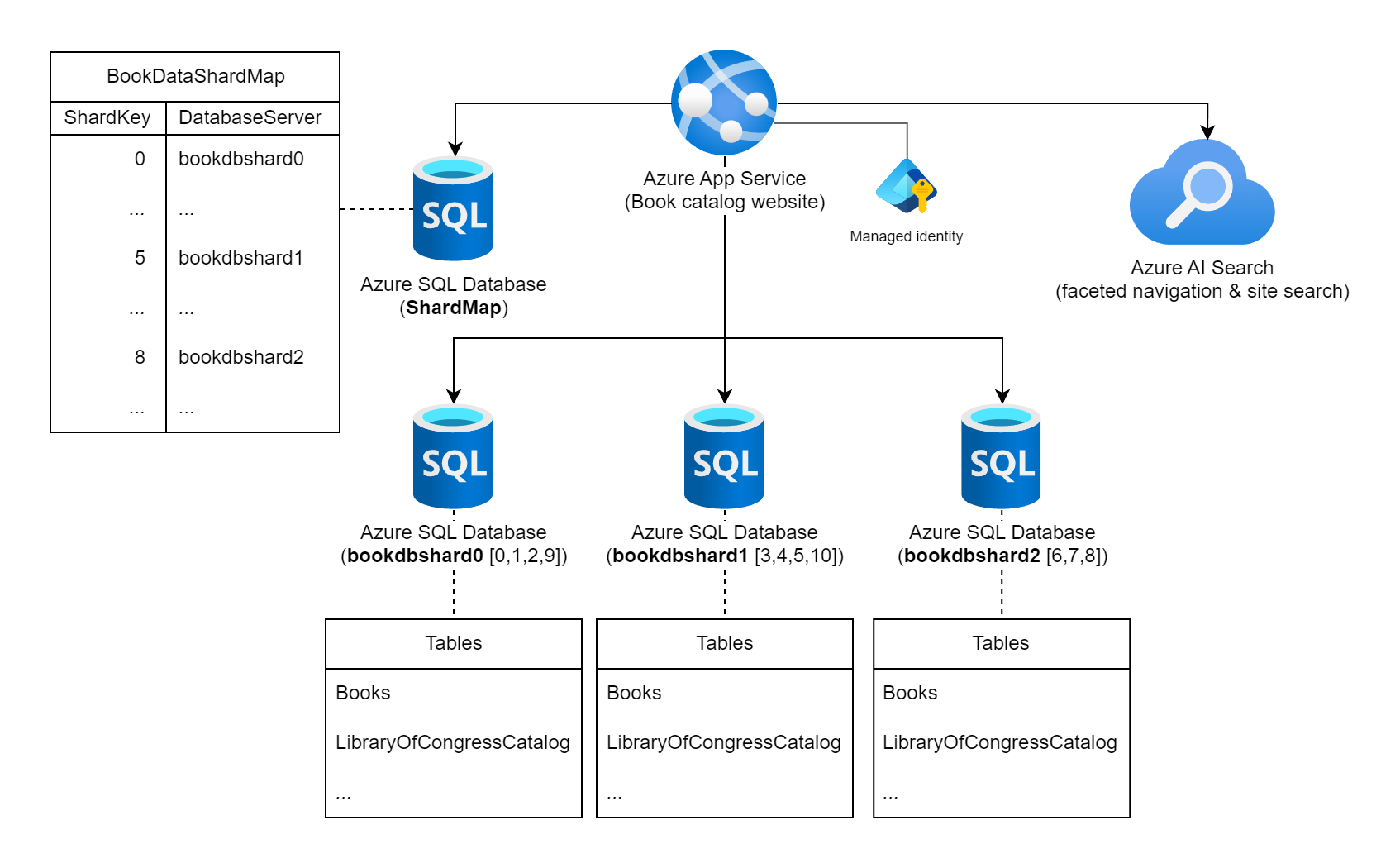
Diagramma che mostra un servizio app Azure etichettato come "Sito Web del catalogo libri" connesso a più istanze di database SQL di Azure e a un'istanza di Ricerca di intelligenza artificiale di Azure. Uno dei database è etichettato come database ShardMap e include una tabella di esempio che rispecchia una parte della tabella di mapping elencata ulteriormente in questo documento. Sono elencate anche tre istanze di database partizioni: bookdbshard0, bookdbshard1 e bookdbshard2. Ognuno dei database include un elenco di esempi di tabelle sottostanti. Tutti e tre gli esempi sono identici, elencando le tabelle "Books" e "LibraryOfCongressCatalog" e un indicatore di più tabelle. L'icona ricerca di Intelligenza artificiale di Azure indica che viene usata per la navigazione in base a facet e la ricerca nei siti. L'identità gestita viene visualizzata associata al servizio app Azure.
Mappa partizioni di ricerca
Il database della mappa partizioni contiene la tabella e i dati di mapping partizioni seguenti.
SELECT ShardKey, DatabaseServer
FROM BookDataShardMap
| ShardKey | DatabaseServer |
|----------|----------------|
| 0 | bookdbshard0 |
| 1 | bookdbshard0 |
| 2 | bookdbshard0 |
| 3 | bookdbshard1 |
| 4 | bookdbshard1 |
| 5 | bookdbshard1 |
| 6 | bookdbshard2 |
| 7 | bookdbshard2 |
| 8 | bookdbshard2 |
| 9 | bookdbshard0 |
| 10 | bookdbshard1 |
Codice del sito Web di esempio - Accesso a partizione singola
Il sito Web non è a conoscenza del numero di database di partizioni fisici (tre in questo caso) né della logica che esegue il mapping di una chiave di partizione a un'istanza del database, ma il sito Web sa che la cifra di controllo dell'ISBN di un libro deve essere considerata la chiave di partizione. Il sito Web ha accesso in sola lettura al database della mappa partizioni e all'accesso in lettura/scrittura a tutti i database partizioni. In questo esempio, il sito Web usa l'identità gestita del sistema del servizio app Azure che ospita il sito Web per l'autorizzazione a mantenere i segreti fuori dai stringa di connessione.
Il sito Web è configurato con i stringa di connessione seguenti, in un appsettings.json file, ad esempio in questo esempio, o tramite le impostazioni dell'app servizio app.
{
...
"ConnectionStrings": {
"ShardMapDb": "Data Source=tcp:<database-server-name>.database.windows.net,1433;Initial Catalog=ShardMap;Authentication=Active Directory Default;App=Book Site v1.5a",
"BookDbFragment": "Data Source=tcp:SHARD.database.windows.net,1433;Initial Catalog=Books;Authentication=Active Directory Default;App=Book Site v1.5a"
},
...
}
Con le informazioni di connessione al database della mappa partizioni disponibile, un esempio di query di aggiornamento eseguita dal sito Web nel pool di partizioni del database del carico di lavoro sarà simile al codice seguente.
...
// All data for this book is stored in a shard based on the book's ISBN check digit,
// which is converted to an integer 0 - 10 (special value 'X' becomes 10).
int isbnCheckDigit = book.Isbn.CheckDigitAsInt;
// Establish a pooled connection to the database shard for this specific book.
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: isbnCheckDigit, cancellationToken))
{
// Update the book's Library of Congress catalog information
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"UPDATE LibraryOfCongressCatalog
SET ControlNumber = @lccn,
...
Classification = @lcc
WHERE BookID = @bookId";
cmd.Parameters.AddWithValue("@lccn", book.LibraryOfCongress.Lccn);
...
cmd.Parameters.AddWithValue("@lcc", book.LibraryOfCongress.Lcc);
cmd.Parameters.AddWithValue("@bookId", book.Id);
await cmd.ExecuteNonQueryAsync(cancellationToken);
}
...
Nel codice di esempio precedente, se book.Isbn è 978-8-1130-1024-6, isbnCheckDigit allora deve essere 6. La chiamata a OpenShardConnectionForKeyAsync(6) verrebbe in genere implementata con un approccio cache-aside. Esegue una query sul database della mappa partizioni identificato con il stringa di connessione ShardMapDb se non contiene informazioni sulla partizione memorizzate nella cache per la chiave di partizione 6. Dalla cache dell'applicazione o dal database di partizione, il valore bookdbshard2 ha il posto di SHARD nella BookDbFragment stringa di connessione. Una connessione in pool viene stabilita (nuovamente) per bookdbshard2.database.windows.net, aperta e restituita al codice chiamante. Il codice aggiorna quindi il record esistente nell'istanza del database.
Codice del sito Web di esempio - Accesso a più partizioni
Nel raro caso in cui una query tra partizioni diretta sia richiesta dal sito Web, l'applicazione esegue una query di fanout parallela in tutte le partizioni.
...
// Retrieve all shard keys
var shardKeys = shardedDatabaseConnections.GetAllShardKeys();
// Execute the query, in a fan-out style, against each shard in the shard list.
Parallel.ForEachAsync(shardKeys, async (shardKey, cancellationToken) =>
{
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: shardKey, cancellationToken))
{
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"SELECT ...
FROM ...
WHERE ...";
SqlDataReader reader = await cmd.ExecuteReaderAsync(cancellationToken);
while (await reader.ReadAsync(cancellationToken))
{
// Read the results in to a thread-safe data structure.
}
reader.Close();
}
});
...
In alternativa alle query tra partizioni in questo carico di lavoro potrebbe usare un indice gestito esternamente in Ricerca di intelligenza artificiale di Azure, ad esempio per la ricerca di siti o la funzionalità di spostamento in base a facet.
Aggiunta di istanze di partizione
Il team del carico di lavoro è consapevole che se il catalogo dati o l'utilizzo simultaneo aumenta notevolmente di più di tre istanze di database potrebbe essere necessario. Il team del carico di lavoro non prevede l'aggiunta dinamica di server di database e subirà tempi di inattività del carico di lavoro se una nuova partizione deve essere online. L'inserimento online di una nuova istanza di partizione richiede lo spostamento di dati dalle partizioni esistenti alla nuova partizione insieme a un aggiornamento alla tabella della mappa partizioni. Questo approccio abbastanza statico consente al carico di lavoro di memorizzare nella cache il mapping del database delle chiavi di partizione nel codice del sito Web.
La logica della chiave di partizione in questo esempio ha un limite massimo massimo di 11 partizioni fisiche. Se il team del carico di lavoro esegue test di stima del carico e valuta che alla fine saranno necessarie più di 11 istanze di database, sarebbe necessario apportare una modifica invasiva alla logica della chiave di partizione. Questa modifica comporta un'attenta pianificazione delle modifiche del codice e della migrazione dei dati alla nuova logica chiave.
Funzionalità dell'SDK
Anziché scrivere codice personalizzato per la gestione delle partizioni e il routing delle query alle istanze di database SQL di Azure, valutare la libreria client del database elastico. Questa libreria supporta la gestione delle mappe partizioni, il routing delle query dipendenti dai dati e le query tra partizioni in C# e Java.
Passaggi successivi
Per l'implementazione di questo modello possono risultare utili le informazioni aggiuntive seguenti:
- Nozioni di base sulla coerenza dei dati. Potrebbe essere necessario mantenere la coerenza dei dati distribuiti tra partizioni diverse. Questo argomento riepiloga i problemi da affrontare per mantenere la coerenza dei dati distribuiti e descrive i vantaggi e i compromessi di diversi modelli di coerenza.
- Linee guida di partizionamento di dati. Il partizionamento orizzontale di un archivio dati può introdurre una gamma di problemi aggiuntivi. Descrive questi problemi in relazione al partizionamento di archivi dati nel cloud per migliorare la scalabilità, ridurre la contesa e ottimizzare le prestazioni.
Risorse correlate
Quando si implementa questo modello, possono essere rilevanti anche i modelli seguenti:
- Modello di tabella degli indici. In alcuni casi, non è possibile supportare completamente le query solo tramite la progettazione della chiave di partizione. Consente a un'applicazione di recuperare rapidamente i dati da un archivio dati di grandi dimensioni, specificando una chiave diversa dalla chiave di partizione.
- Modello di vista materializzata. Per mantenere le prestazioni di alcune operazioni di query, è utile creare viste materializzate grado di aggregare e riepilogare i dati, soprattutto se questi dati di riepilogo si basano su informazioni distribuite in più partizioni. Descrive come generare e popolare queste viste.