Completamento e completamento archiviati di Azure OpenAI (anteprima)
I completamenti archiviati consentono di acquisire la cronologia delle conversazioni dalle sessioni di completamento della chat da usare come set di dati per le valutazioni e l'ottimizzazione.
Supporto dei completamenti archiviati
Supporto dell'API
2024-10-01-preview
Supporto di modelli
gpt-4o-2024-08-06
Disponibilità a livello di area
- Svezia centrale
- Stati Uniti centro-settentrionali
- Stati Uniti Orientali 2
Configurare i completamenti archiviati
Per abilitare i completamenti archiviati per la distribuzione di Azure OpenAI, impostare il store parametro su True. Usare il metadata parametro per arricchire il set di dati di completamento archiviato con informazioni aggiuntive.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-01-preview"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
Dopo aver abilitato i completamenti archiviati per una distribuzione OpenAI di Azure, inizieranno a essere visualizzati nel portale di Azure AI Foundry nel riquadro Completamento archiviati.

Distillazione
La funzionalità di perfezionamento consente di trasformare i completamenti archiviati in un set di dati di ottimizzazione. Un caso d'uso comune consiste nell'usare i completamenti archiviati con un modello più potente per una determinata attività e quindi usare i completamenti archiviati per eseguire il training di un modello più piccolo su esempi di interazioni di modelli di alta qualità.
La duplicazione richiede almeno 10 completamenti archiviati, anche se è consigliabile fornire centinaia a migliaia di completamenti archiviati per ottenere risultati ottimali.
Nel riquadro Completamento archiviati nel portale di Azure AI Foundry usare le opzioni Filtro per selezionare i completamenti con cui si vuole eseguire il training del modello.
Per iniziare la topologia, selezionare Distill
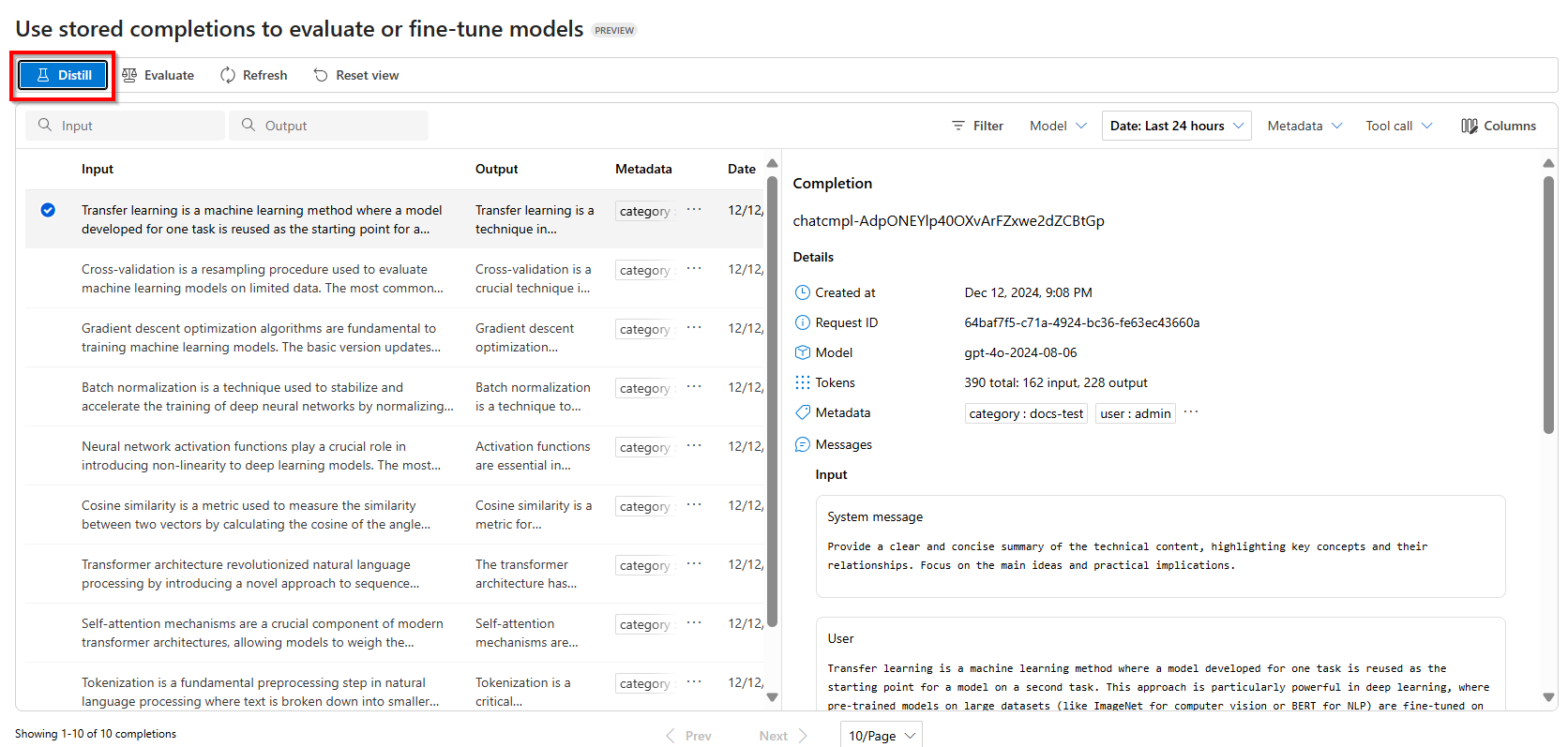
Selezionare il modello da ottimizzare con il set di dati di completamento archiviato.
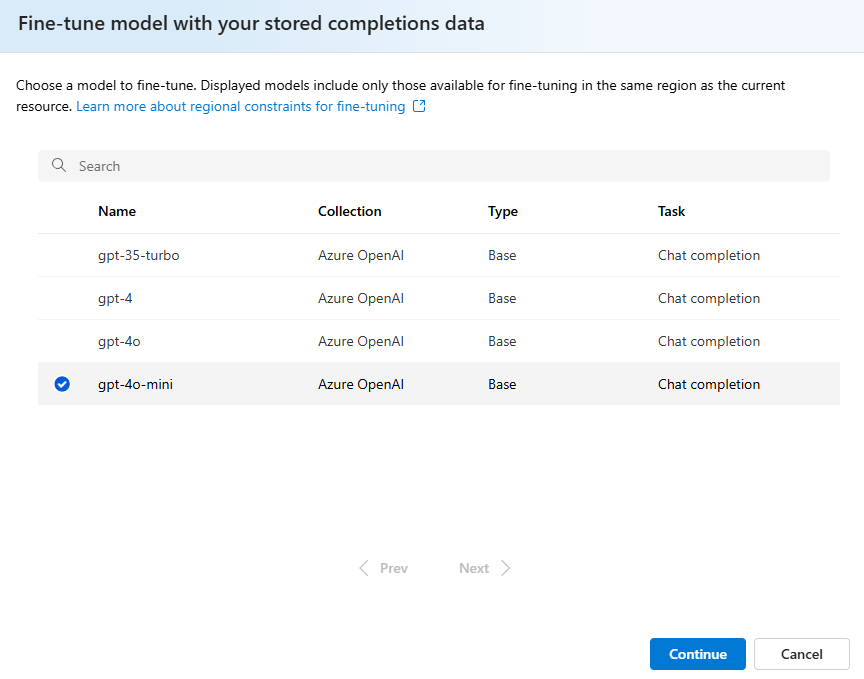
Verificare quale versione del modello si vuole ottimizzare:

Un
.jsonlfile con un nome generato in modo casuale verrà creato come set di dati di training dai completamenti archiviati. Selezionare il file >Avanti.Nota
I file di training di completamento archiviati non possono essere accessibili direttamente e non possono essere esportati esternamente/scaricati.





Il resto dei passaggi corrisponde ai tipici passaggi di ottimizzazione di Azure OpenAI. Per altre informazioni, vedere la guida introduttiva all'ottimizzazione.
Valutazione
La valutazione di modelli linguistici di grandi dimensioni è un passaggio fondamentale per misurare le prestazioni in diverse attività e dimensioni. Ciò è particolarmente importante per i modelli ottimizzati, in cui la valutazione dei miglioramenti delle prestazioni (o delle perdite) dal training è fondamentale. Valutazioni approfondite consentono di comprendere in che modo le diverse versioni del modello possono influire sull'applicazione o sullo scenario.
I completamenti archiviati possono essere usati come set di dati per l'esecuzione di valutazioni.
Nel riquadro Completamento archiviati nel portale di Azure AI Foundry usare le opzioni Filtro per selezionare i completamenti che si vuole far parte del set di dati di valutazione.
Per configurare la valutazione, selezionare Valuta
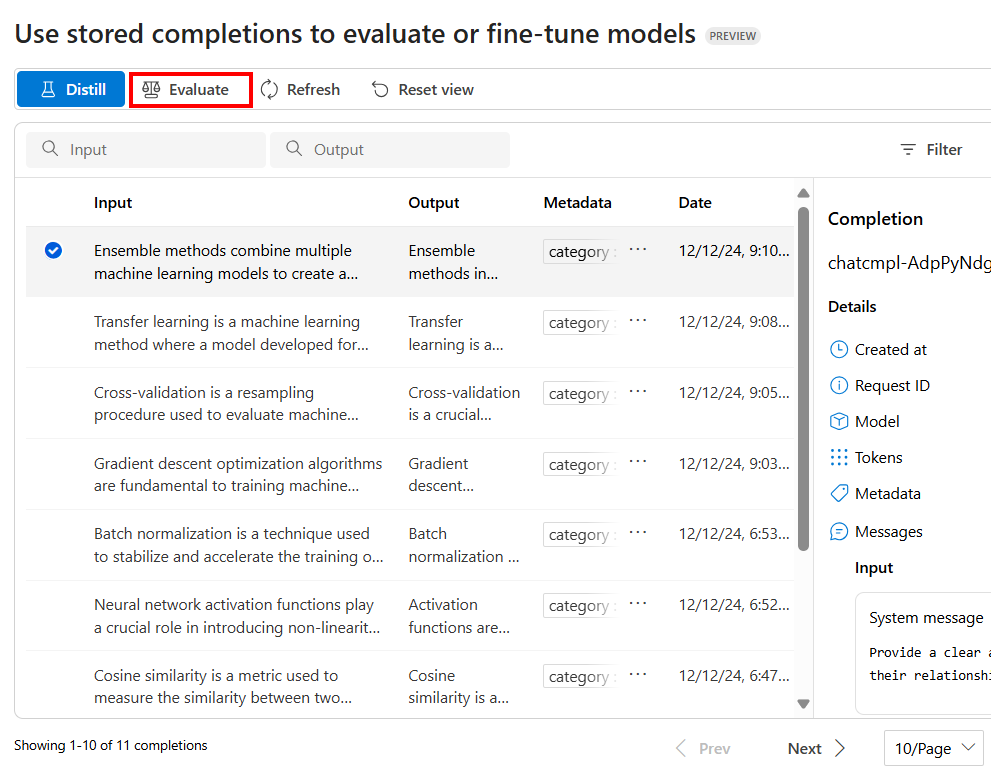
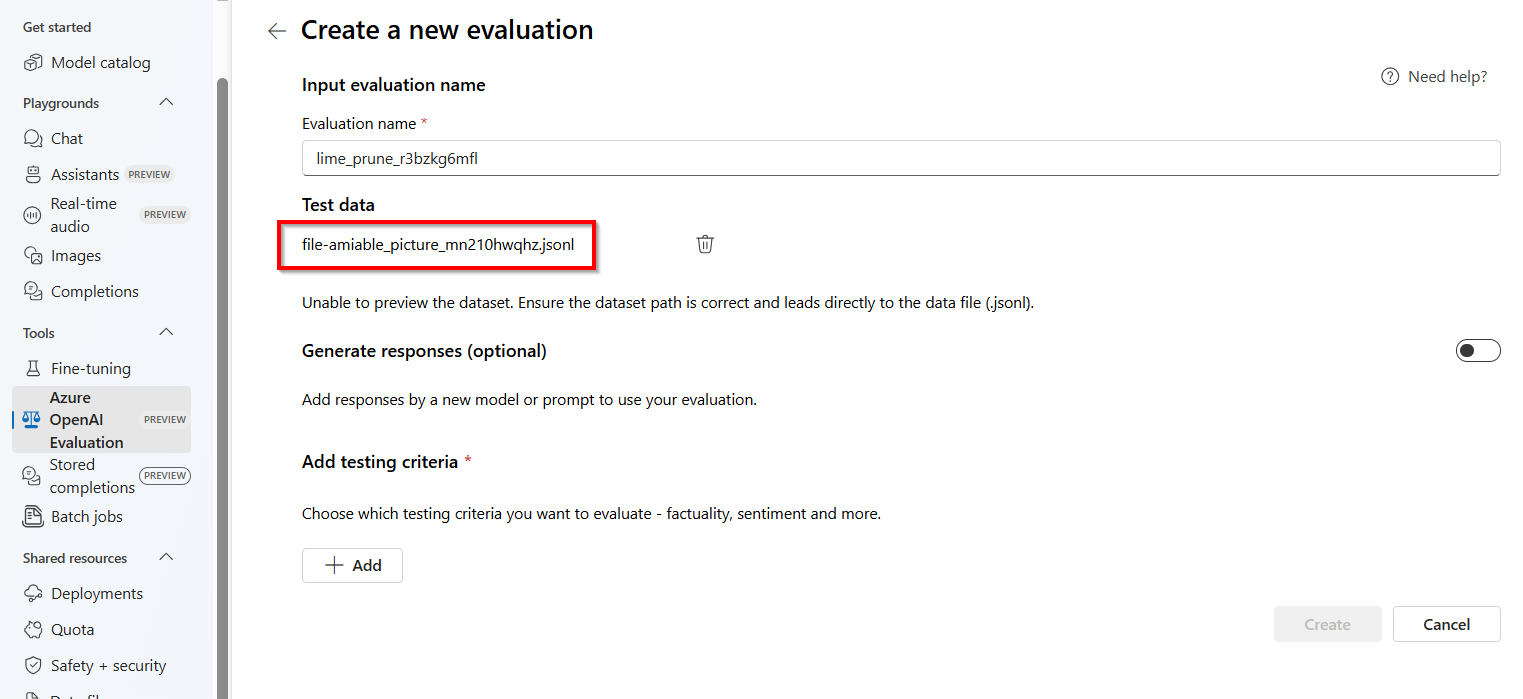
Verrà avviato il riquadro Valutazioni con un file prepopolato
.jsonlcon un nome generato in modo casuale creato come set di dati di valutazione dai completamenti archiviati.Nota
I file di dati di valutazione del completamento archiviati non possono essere accessibili direttamente e non possono essere esportati esternamente o scaricati.


Per altre informazioni sulla valutazione, vedere Introduzione alle valutazioni
Risoluzione dei problemi
Sono necessarie autorizzazioni speciali per usare i completamenti archiviati?
L'accesso ai completamenti archiviati viene controllato tramite due oggetti DataActions:
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
Per impostazione predefinita Cognitive Services OpenAI Contributor , è possibile accedere a entrambe le autorizzazioni seguenti:

Ricerca per categorie eliminare i dati archiviati?
I dati possono essere eliminati eliminando la risorsa OpenAI di Azure associata. Se si desidera eliminare solo i dati di completamento archiviati, è necessario aprire un caso con il supporto tecnico.
Quanti dati di completamento archiviati è possibile archiviare?
È possibile archiviare un massimo di 10 GB di dati.
È possibile impedire l'abilitazione dei completamenti archiviati in una sottoscrizione?
È necessario aprire un caso con il supporto tecnico per disabilitare i completamenti archiviati a livello di sottoscrizione.
TypeError: Completions.create() ha ottenuto un argomento imprevisto 'store'
Questo errore si verifica quando si esegue una versione precedente della libreria client OpenAI che precede la funzionalità di completamento archiviati rilasciata. Eseguire pip install openai --upgrade.