Valutazione OpenAI di Azure (anteprima)
La valutazione di modelli linguistici di grandi dimensioni è un passaggio fondamentale per misurare le prestazioni in diverse attività e dimensioni. Ciò è particolarmente importante per i modelli ottimizzati, in cui la valutazione dei miglioramenti delle prestazioni (o delle perdite) dal training è fondamentale. Valutazioni approfondite consentono di comprendere in che modo le diverse versioni del modello possono influire sull'applicazione o sullo scenario.
La valutazione OpenAI di Azure consente agli sviluppatori di creare esecuzioni di valutazione per testare le coppie di input/output previste, valutando le prestazioni del modello in metriche chiave, ad esempio accuratezza, affidabilità e prestazioni complessive.
Supporto delle valutazioni
Disponibilità a livello di area
- Stati Uniti Orientali 2
- Stati Uniti centro-settentrionali
- Svezia centrale
- Svizzera occidentale
Tipi di distribuzione supportati
- Standard
- Standard globale
- Standard della zona dati
- Provisioning gestito
- Gestito con provisioning globale
- Area dati con provisioning gestito
Pipeline di valutazione
Dati di test
È necessario assemblare un set di dati di verità sul terreno che si vuole testare. La creazione di set di dati è in genere un processo iterativo che garantisce che le valutazioni rimangano rilevanti per gli scenari nel tempo. Questo set di dati di verità di base viene in genere creato manualmente e rappresenta il comportamento previsto dal modello. Il set di dati viene anche etichettato e include le risposte previste.
Nota
Alcuni test di valutazione, ad esempio Sentiment e JSON o XML validi, non richiedono dati di verità di base.
L'origine dati deve essere in formato JSONL. Di seguito sono riportati due esempi dei set di dati di valutazione JSONL:
Formato di valutazione
{"question": "Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.", "subject": "abstract_algebra", "A": "0", "B": "4", "C": "2", "D": "6", "answer": "B", "completion": "B"}
{"question": "Let p = (1, 2, 5, 4)(2, 3) in S_5 . Find the index of <p> in S_5.", "subject": "abstract_algebra", "A": "8", "B": "2", "C": "24", "D": "120", "answer": "C", "completion": "C"}
{"question": "Find all zeros in the indicated finite field of the given polynomial with coefficients in that field. x^5 + 3x^3 + x^2 + 2x in Z_5", "subject": "abstract_algebra", "A": "0", "B": "1", "C": "0,1", "D": "0,4", "answer": "D", "completion": "D"}
Quando si carica e si seleziona il file di valutazione, verrà restituita un'anteprima delle prime tre righe:


È possibile scegliere qualsiasi set di dati caricato in precedenza esistente o caricare un nuovo set di dati.
Creare risposte (facoltativo)
La richiesta usata nella valutazione deve corrispondere alla richiesta che si prevede di usare nell'ambiente di produzione. Queste istruzioni forniscono le istruzioni per il modello da seguire. Analogamente alle esperienze del playground, è possibile creare più input per includere esempi di pochi scatti nel prompt. Per altre informazioni, vedere prompt engineering techniques for details on some advanced techniques in prompt design and prompt engineering .For more information, see prompt engineering techniques for details on some advanced techniques in prompt design and prompt engineering.
È possibile fare riferimento ai dati di input all'interno delle richieste usando il {{input.column_name}} formato , dove column_name corrisponde ai nomi delle colonne nel file di input.
Gli output generati durante la valutazione verranno indicati nei passaggi successivi usando il {{sample.output_text}} formato .
Nota
È necessario usare parentesi graffe doppie per assicurarsi di fare riferimento correttamente ai dati.
Distribuzione di modelli
Nell'ambito della creazione di valutazioni è possibile scegliere quali modelli usare durante la generazione di risposte (facoltative) e quali modelli usare durante la classificazione dei modelli con criteri di test specifici.
In Azure OpenAI si assegneranno distribuzioni di modelli specifiche da usare come parte delle valutazioni. È possibile confrontare più distribuzioni di modelli in una singola esecuzione di valutazione.
È possibile valutare le distribuzioni di modelli di base o ottimizzate. Le distribuzioni disponibili nell'elenco dipendono da quelle create all'interno della risorsa OpenAI di Azure. Se non è possibile trovare la distribuzione desiderata, è possibile crearne una nuova dalla pagina Valutazione OpenAI di Azure.
Criteri di test
I criteri di test vengono usati per valutare l'efficacia di ogni output generato dal modello di destinazione. Questi test confrontano i dati di input con i dati di output per garantire la coerenza. È possibile configurare criteri diversi per testare e misurare la qualità e la pertinenza dell'output a livelli diversi.

Introduzione
Selezionare Azure OpenAI Evaluation (ANTEPRIMA) nel portale di Azure AI Foundry. Per visualizzare questa visualizzazione come opzione potrebbe essere necessario selezionare prima una risorsa OpenAI di Azure esistente in un'area supportata.
Selezionare Nuova valutazione

Immettere un nome per la valutazione. Per impostazione predefinita, viene generato automaticamente un nome casuale, a meno che non venga modificato e sostituito. Selezionare Carica nuovo set di dati.
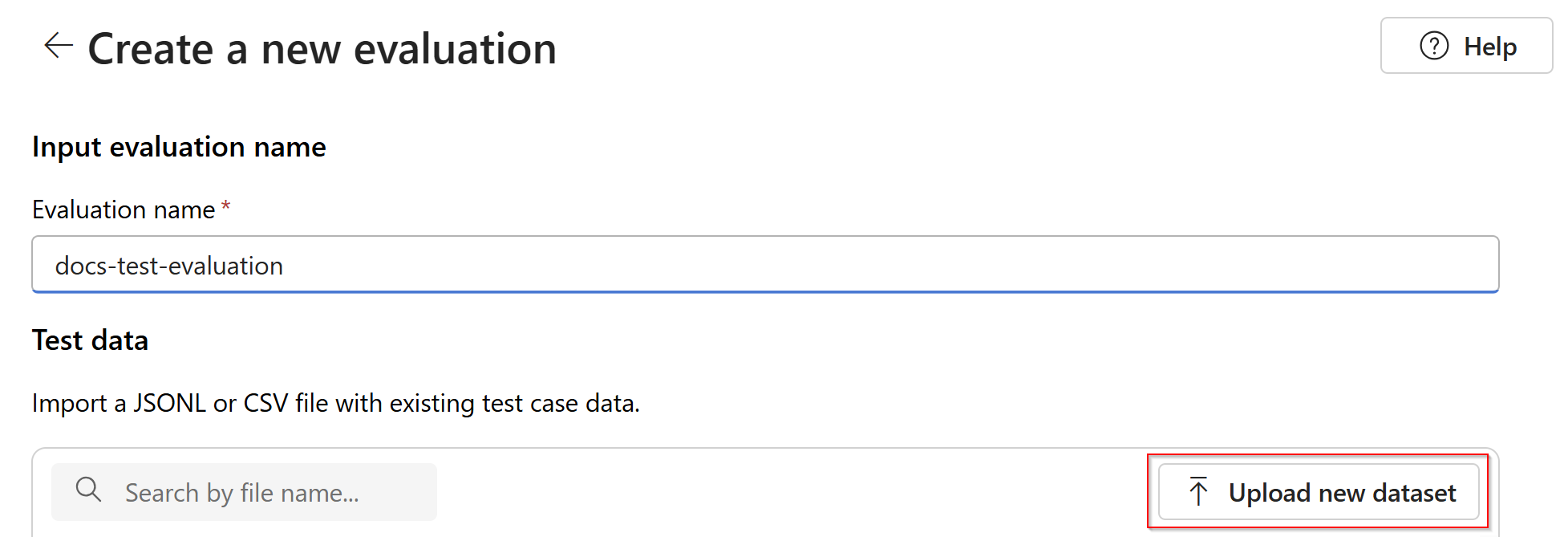
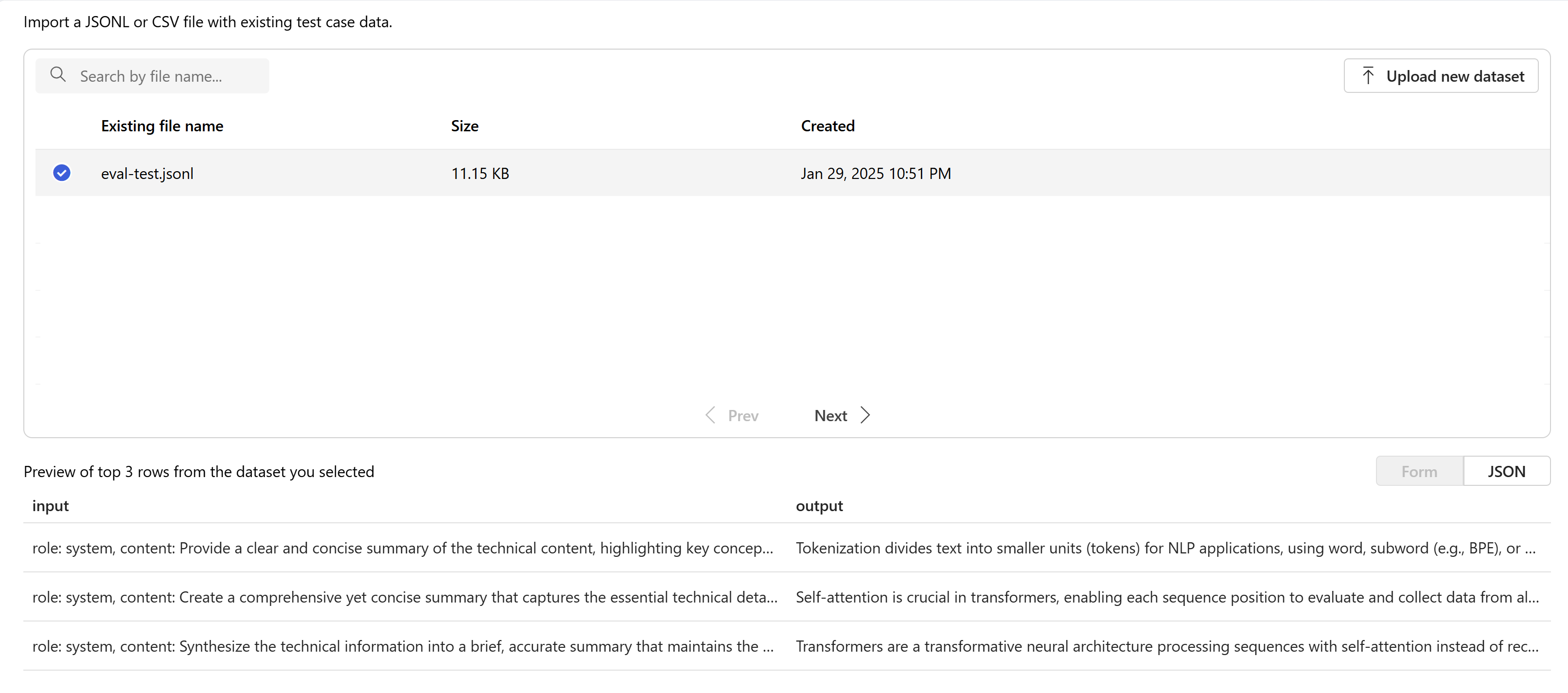
Selezionare la valutazione che sarà in
.jsonlformato. Se è necessario un file di test di esempio, è possibile salvare queste 10 righe in un file denominatoeval-test.jsonl:{"input": [{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."}, {"role": "user", "content": "Tokenization is a key step in preprocessing for natural language processing, involving the division of text into smaller components called tokens. These can be words, subwords, or characters, depending on the method chosen. Word tokenization divides text at word boundaries, while subword techniques like Byte Pair Encoding (BPE) or WordPiece can manage unknown words by breaking them into subunits. Character tokenization splits text into individual characters, useful for multiple languages and misspellings. The tokenization method chosen greatly affects model performance and its capacity to handle various languages and vocabularies."}], "output": "Tokenization divides text into smaller units (tokens) for NLP applications, using word, subword (e.g., BPE), or character methods. Each has unique benefits, impacting model performance and language processing capabilities."} {"input": [{"role": "system", "content": "Create a comprehensive yet concise summary that captures the essential technical details and significance of the topic."}, {"role": "user", "content": "Self-attention mechanisms are vital in modern transformer models, allowing them to evaluate the relevance of different parts of an input sequence when processing each element. In self-attention, each position in a sequence learns to focus on all other positions, forming a weighted sum of their values. Attention weights are derived using queries, keys, and values, with compatibility between a query and key determining attention to each value. This mechanism enables capturing long-range dependencies and relationships within a sequence, making it effective for tasks needing context understanding and inter-part relationships."}], "output": "Self-attention is crucial in transformers, enabling each sequence position to evaluate and collect data from all others. It uses queries, keys, and values for attention weights, effectively capturing long-range dependencies and contextual links."} {"input": [{"role": "system", "content": "Synthesize the technical information into a brief, accurate summary that maintains the core concepts and their significance."}, {"role": "user", "content": "The transformer architecture significantly changed natural language processing by introducing a new method for sequence processing. Unlike recurrent neural networks, transformers process whole sequences at once using self-attention. The architecture consists of an encoder and decoder, each with multiple layers of multi-head attention, feed-forward networks, and normalization layers. The encoder processes the input sequence, and the decoder produces the output sequence. Positional encodings are added to retain sequence order information since the model lacks inherent sequence position awareness. This architecture underlies many leading language models like BERT and GPT."}], "output": "Transformers are a transformative neural architecture processing sequences with self-attention instead of recurrence. Their encoder-decoder design, with multi-head attention and position encodings, is fundamental to modern language models like BERT and GPT."} {"input": [{"role": "system", "content": "Distill the technical content into a clear, concise summary that preserves the most important concepts and their practical applications."}, {"role": "user", "content": "Cosine similarity is a metric for measuring similarity between vectors by calculating the cosine of the angle between them. The outcome ranges from -1 to 1, with 1 indicating identical orientation, 0 orthogonality, and -1 opposite orientation. In machine learning and NLP, cosine similarity is useful for comparing document vectors, word embeddings, or any high-dimensional representations. It's often preferred over Euclidean distance because it's invariant to vector magnitude, focusing instead on orientation. This makes it particularly useful for comparing documents or embeddings of various lengths or scales."}], "output": "Cosine similarity evaluates vector similarity by computing their angle's cosine, with values from -1 to 1. It's widely used in ML and NLP for comparing document vectors and embeddings due to its magnitude-invariant nature."} {"input": [{"role": "system", "content": "Provide a succinct summary that captures the key technical concepts and their relationships while maintaining clarity and accuracy."}, {"role": "user", "content": "Neural network activation functions are crucial for introducing non-linearity to deep learning models. Commonly used activation functions include ReLU (Rectified Linear Unit), which outputs the input directly if positive and zero otherwise, sigmoid, which compresses values between 0 and 1, and tanh, which normalizes values between -1 and 1. Each function has specific benefits and applications: ReLU avoids vanishing gradients and enables sparse activation, sigmoid is useful for binary classification, and tanh is often used in hidden layers for its zero-centered output. The activation function choice greatly affects model training dynamics and ultimate performance."}], "output": "Activation functions introduce non-linearity to neural networks, with ReLU, sigmoid, and tanh being the most common. Each serves distinct purposes: ReLU prevents vanishing gradients, sigmoid is suitable for binary classification, and tanh offers zero-centered output, all affecting model performance differently."} {"input": [{"role": "system", "content": "Create a focused summary that emphasizes the main technical concepts and their practical implications while maintaining accuracy."}, {"role": "user", "content": "Batch normalization is a technique that stabilizes and accelerates deep neural network training by normalizing each layer's inputs. It normalizes activations using the mean and variance computed over the current data batch. This normalization reduces internal covariate shift, where the input distribution changes during training. Batch normalization includes learnable parameters (gamma and beta) allowing the network to reverse normalization if necessary. Benefits include enabling higher learning rates, lessening the importance of precise parameter initialization, and serving as a regularizer, potentially removing the need for dropout."}], "output": "Batch normalization stabilizes neural network training by normalizing layer inputs using batch statistics. It addresses internal covariate shift with learnable parameters, allowing higher learning rates and improved training dynamics, while offering regularization benefits."} {"input": [{"role": "system", "content": "Summarize the technical content while preserving the essential concepts and their interconnections, ensuring clarity and precision."}, {"role": "user", "content": "Gradient descent optimization algorithms are foundational to training machine learning models. The basic version updates parameters in the steepest descent direction of the loss function. Variants like Stochastic Gradient Descent (SGD) use random samples to estimate gradients, enhancing computational efficiency. Advanced optimizers like Adam combine momentum (helping overcome local minima) and RMSprop (adapting learning rates for each parameter). These optimizers maintain running averages of gradients and their squares, enabling adaptive learning rates and more efficient training. The optimizer choice can significantly influence model convergence speed and final performance."}], "output": "Gradient descent algorithms optimize ML models by updating parameters based on loss gradients. Variants like SGD use sampling for efficiency, while advanced optimizers like Adam combine momentum with adaptive learning rates for improved training performance."} {"input": [{"role": "system", "content": "Deliver a concise yet comprehensive summary that highlights the key technical aspects and their practical significance."}, {"role": "user", "content": "Cross-validation is a resampling method used to evaluate machine learning models on limited data. The most common form, k-fold cross-validation, involves dividing the dataset into k equal parts, training the model on k-1 folds while validating on the remaining fold, and rotating through all combinations. This provides a more robust model performance assessment than a single train-test split, helping detect overfitting and estimate model generalization to unseen data. Variations include stratified k-fold (maintaining class distribution), leave-one-out (k equals dataset size), and time series cross-validation for temporal data."}], "output": "Cross-validation evaluates ML models by training and testing on different data splits, typically using k-fold methodology. This approach offers better performance assessment than single splits, with variations for different data types and requirements."} {"input": [{"role": "system", "content": "Generate a clear and focused summary that captures the essential technical details while maintaining their relationships and significance."}, {"role": "user", "content": "Transfer learning is a machine learning method where a model developed for one task is reused as the starting point for a model on a second task. This approach is powerful in deep learning, where pre-trained models on large datasets (like ImageNet for computer vision or BERT for NLP) are fine-tuned on specific downstream tasks. Transfer learning reduces the need for large amounts of task-specific training data and computational resources, as the model has already learned useful features from the source domain. Common strategies include feature extraction (freezing pre-trained layers) and fine-tuning (updating all or some pre-trained weights)."}], "output": "Transfer learning reuses models trained on one task for different tasks, particularly effective in deep learning. It leverages pre-trained models through feature extraction or fine-tuning, reducing data and computational needs for new tasks."} {"input": [{"role": "system", "content": "Provide a precise and informative summary that distills the key technical concepts while maintaining their relationships and practical importance."}, {"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random data subsets), boosting (sequentially training models to correct earlier errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree correcting the errors of previous ones. These methods often outperform single models by reducing overfitting and variance while capturing different data aspects."}], "output": "Ensemble methods enhance prediction accuracy by combining multiple models through techniques like bagging, boosting, and stacking. Popular implementations include Random Forests (using multiple trees with random features) and Gradient Boosting (sequential error correction), offering better performance than single models."}Le prime tre righe del file verranno visualizzate come anteprima:
In Risposte selezionare il pulsante Crea . Selezionare
{{item.input}}dall'elenco a discesa Crea con un modello . In questo modo i campi di input del file di valutazione verranno inseriti in singole richieste di esecuzione di un nuovo modello che si vuole confrontare con il set di dati di valutazione. Il modello accetta tale input e genera i propri output univoci che in questo caso verranno archiviati in una variabile denominata{{sample.output_text}}. Verrà quindi usato il testo di output di esempio più avanti come parte dei criteri di test. In alternativa, è possibile fornire manualmente un messaggio di sistema personalizzato e singoli esempi di messaggi.Selezionare il modello che si vuole generare risposte in base alla valutazione. Se non si ha un modello, è possibile crearne uno. Ai fini di questo esempio viene usata una distribuzione standard di
gpt-4o-mini.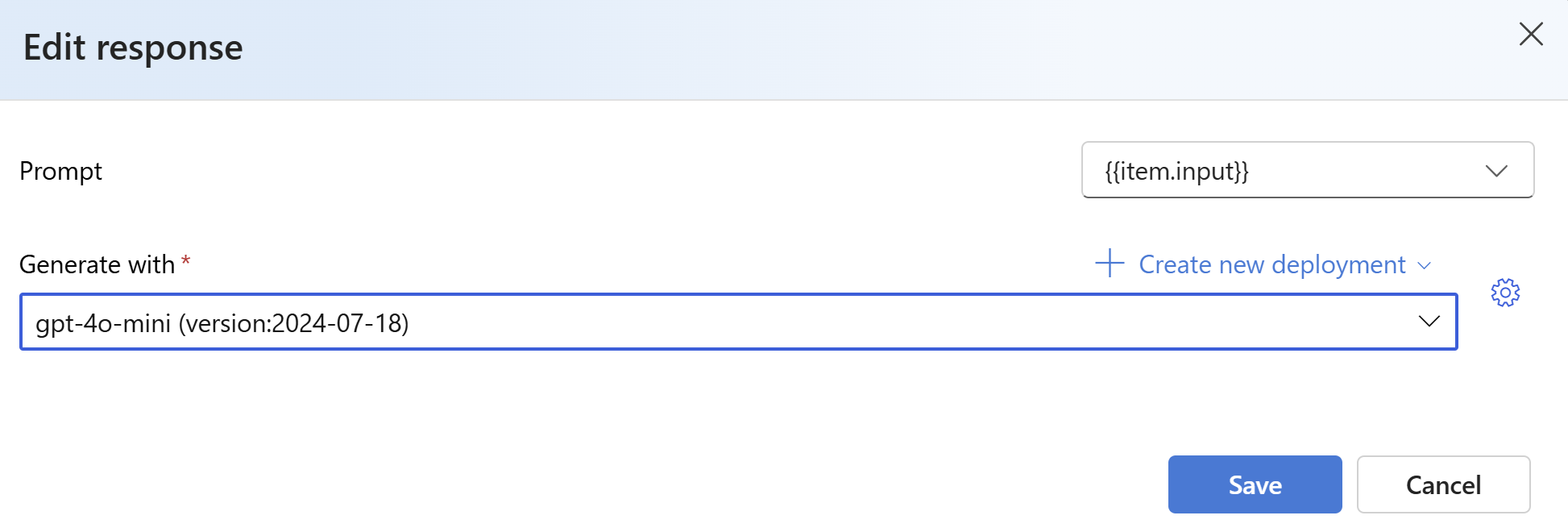
Il simbolo settings/sprocket controlla i parametri di base passati al modello. Al momento sono supportati solo i parametri seguenti:




- Temperatura
- Lunghezza massima
- P superiore
La lunghezza massima è attualmente limitata a 2048 indipendentemente dal modello selezionato.
Selezionare Aggiungi criteri di test selezionare Aggiungi.
Selezionare Somiglianza> semantica in Confronta aggiungi
{{item.output}}in Con aggiungi{{sample.output_text}}. In questo modo, l'output di riferimento originale del file di valutazione.jsonlverrà confrontato con l'output che verrà generato fornendo i prompt del modello in{{item.input}}base all'oggetto .
Selezionare Aggiungi> a questo punto per aggiungere altri criteri di test oppure selezionare Crea per avviare l'esecuzione del processo di valutazione.
Dopo aver selezionato Crea , verrà visualizzata una pagina di stato per il processo di valutazione.
Dopo aver creato il processo di valutazione, è possibile selezionare il processo per visualizzare i dettagli completi del processo:
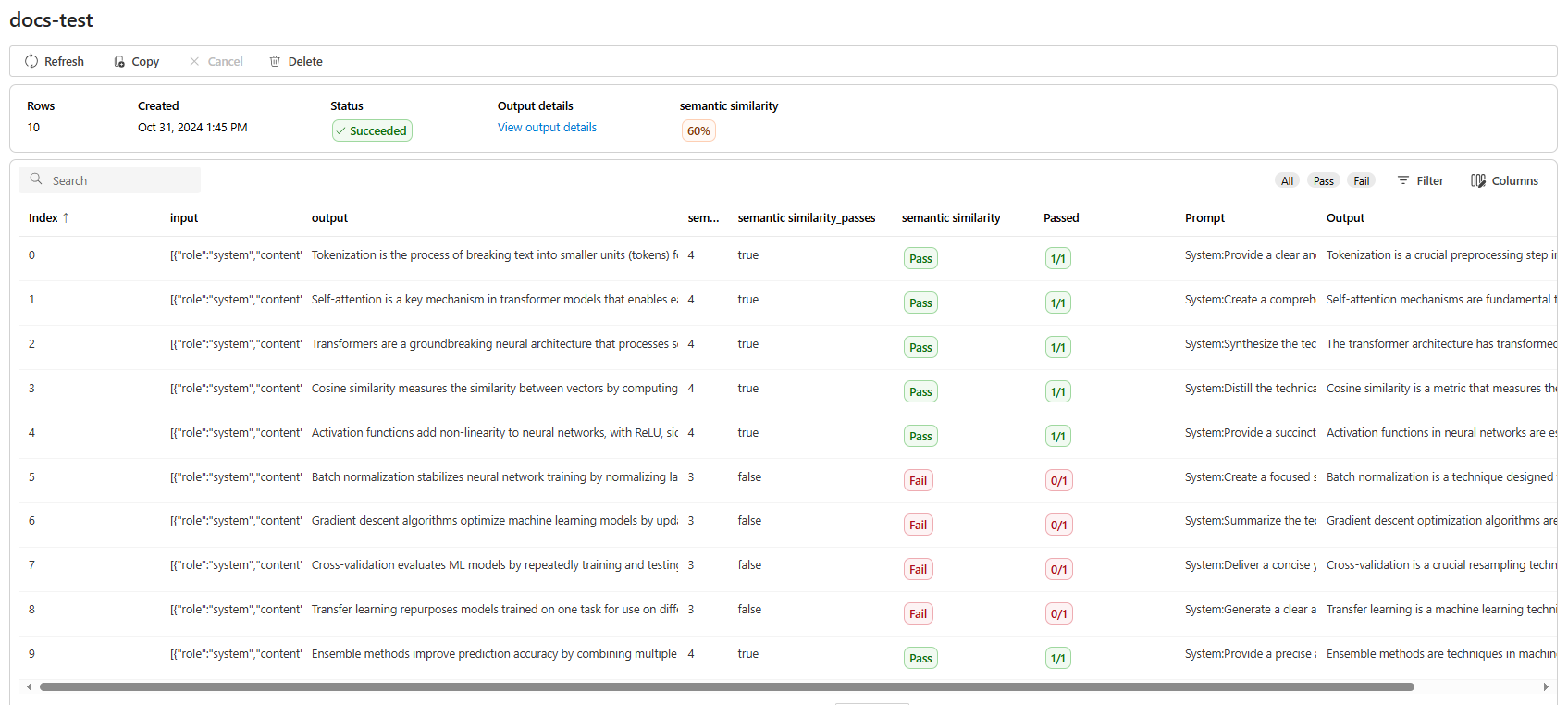
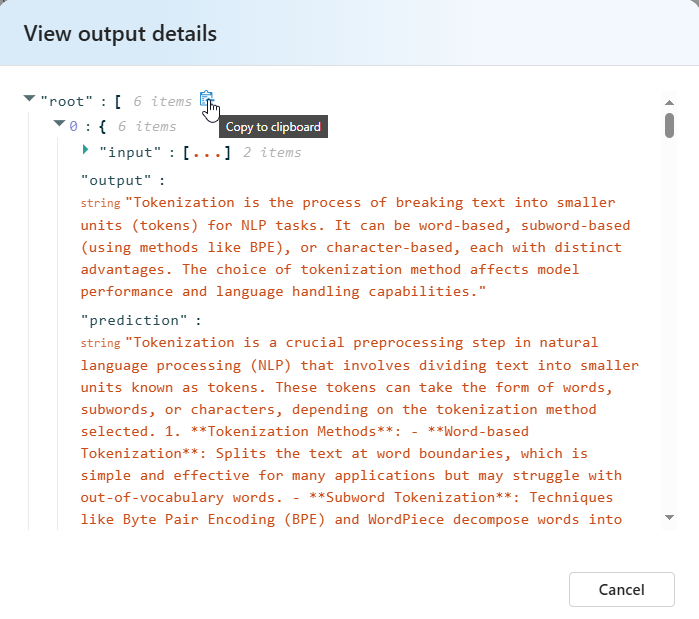
Per la somiglianza semantica Visualizzare i dettagli dell'output contiene una rappresentazione JSON che è possibile copiare/incollare dei test superati.




Dettagli dei criteri di test
Valutazione OpenAI di Azure offre più opzioni di criteri di test. La sezione seguente fornisce dettagli aggiuntivi su ogni opzione.
Fattualità
Valuta l'accuratezza effettiva di una risposta inviata confrontandola con una risposta esperta.
La realtà valuta l'accuratezza effettiva di una risposta inviata confrontandola con una risposta esperta. Utilizzando un prompt dettagliato della catena di pensiero (CoT), il grader determina se la risposta inviata è coerente con, un subset di, un superset di o in conflitto con la risposta dell'esperto. Ignora le differenze nello stile, nella grammatica o nella punteggiatura, concentrandosi esclusivamente sul contenuto effettivo. I fatti possono essere utili in molti scenari, tra cui la verifica del contenuto e gli strumenti didattici, garantendo l'accuratezza delle risposte fornite dall'IA.

È possibile visualizzare il testo del prompt usato come parte di questi criteri di test selezionando l'elenco a discesa accanto al prompt. Il testo del prompt corrente è:
Prompt
You are comparing a submitted answer to an expert answer on a given question.
Here is the data:
[BEGIN DATA]
************
[Question]: {input}
************
[Expert]: {ideal}
************
[Submission]: {completion}
************
[END DATA]
Compare the factual content of the submitted answer with the expert answer. Ignore any differences in style, grammar, or punctuation.
The submitted answer may either be a subset or superset of the expert answer, or it may conflict with it. Determine which case applies. Answer the question by selecting one of the following options:
(A) The submitted answer is a subset of the expert answer and is fully consistent with it.
(B) The submitted answer is a superset of the expert answer and is fully consistent with it.
(C) The submitted answer contains all the same details as the expert answer.
(D) There is a disagreement between the submitted answer and the expert answer.
(E) The answers differ, but these differences don't matter from the perspective of factuality.
Somiglianza semantica
Misura il grado di somiglianza tra la risposta del modello e il riferimento.
Grades: 1 (completely different) - 5 (very similar).

Valutazione
Tenta di identificare il tono emotivo dell'output.

È possibile visualizzare il testo del prompt usato come parte di questi criteri di test selezionando l'elenco a discesa accanto al prompt. Il testo del prompt corrente è:
Prompt
You will be presented with a text generated by a large language model. Your job is to rate the sentiment of the text. Your options are:
A) Positive
B) Neutral
C) Negative
D) Unsure
[BEGIN TEXT]
***
[{text}]
***
[END TEXT]
First, write out in a step by step manner your reasoning about the answer to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character (without quotes or punctuation) on its own line corresponding to the correct answer. At the end, repeat just the letter again by itself on a new line
Controllo stringa
Verifica se l'output corrisponde esattamente alla stringa prevista.

Il controllo stringa esegue varie operazioni binarie su due variabili stringa che consentono criteri di valutazione diversi. Consente di verificare varie relazioni tra stringhe, tra cui uguaglianza, contenimento e modelli specifici. Questo analizzatore consente confronti senza distinzione tra maiuscole e minuscole o senza distinzione tra maiuscole e minuscole. Fornisce inoltre voti specificati per risultati true o false, consentendo risultati di valutazione personalizzati in base al risultato del confronto. Ecco il tipo di operazioni supportate:
-
equals: controlla se la stringa di output è esattamente uguale alla stringa di valutazione. -
contains: controlla se la stringa di valutazione è una sottostringa della stringa di output. -
starts-with: controlla se la stringa di output inizia con la stringa di valutazione. -
ends-with: controlla se la stringa di output termina con la stringa di valutazione.
Nota
Quando si impostano determinati parametri nei criteri di test, è possibile scegliere tra la variabile e il modello. Selezionare la variabile se si vuole fare riferimento a una colonna nei dati di input. Scegliere il modello se si vuole specificare una stringa fissa.
JSON o XML valido
Verifica se l'output è JSON o XML valido.

Corrisponde allo schema
Assicura che l'output segua la struttura specificata.

Corrispondenza dei criteri
Valutare se la risposta del modello corrisponde ai criteri. Grade: pass o fail.

È possibile visualizzare il testo del prompt usato come parte di questi criteri di test selezionando l'elenco a discesa accanto al prompt. Il testo del prompt corrente è:
Prompt
Your job is to assess the final response of an assistant based on conversation history and provided criteria for what makes a good response from the assistant. Here is the data:
[BEGIN DATA]
***
[Conversation]: {conversation}
***
[Response]: {response}
***
[Criteria]: {criteria}
***
[END DATA]
Does the response meet the criteria? First, write out in a step by step manner your reasoning about the criteria to be sure that your conclusion is correct. Avoid simply stating the correct answers at the outset. Then print only the single character "Y" or "N" (without quotes or punctuation) on its own line corresponding to the correct answer. "Y" for yes if the response meets the criteria, and "N" for no if it does not. At the end, repeat just the letter again by itself on a new line.
Reasoning:
Qualità del testo
Valutare la qualità del testo confrontandolo con il testo di riferimento.

Riepilogo:
- Punteggio BLEU: valuta la qualità del testo generato confrontandolo con una o più traduzioni di riferimento di alta qualità usando il punteggio BLEU.
- SCORE ROUGE: valuta la qualità del testo generato confrontandolo con i riepiloghi di riferimento usando i punteggi ROUGE.
- Coseno: noto anche come somiglianza coseno misura il modo in cui due incorporamenti di testo, ad esempio output di modelli e testi di riferimento, allineano in senso, aiutando a valutare la somiglianza semantica tra di essi. Questa operazione viene eseguita misurando la distanza nello spazio vettoriale.
Dettagli:
Il punteggio DI VALUTAZIONE BILINGUAL (BiLingual Evaluation Understudy) viene comunemente usato nell'elaborazione del linguaggio naturale (NLP) e nella traduzione automatica. Viene ampiamente usato nei casi d'uso di riepilogo del testo e generazione di testo. Valuta quanto il testo generato corrisponda al testo di riferimento. Il punteggio BLEU è compreso tra 0 e 1, con punteggi più alti che indicano una migliore qualità.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) è un set di metriche usate per valutare il riepilogo automatico e la traduzione automatica. Misura la sovrapposizione tra testo generato e riepiloghi di riferimento. ROUGE è incentrato sulle misure orientate al richiamo per valutare la frequenza con cui il testo generato copre il testo di riferimento. Il punteggio ROUGE fornisce varie metriche, tra cui: • ROUGE-1: Sovrapposizione di unigrammi (singole parole) tra testo generato e di riferimento. • ROUGE-2: Sovrapposizione di bigrams (due parole consecutive) tra testo generato e di riferimento. • ROUGE-3: Sovrapposizione di trigrammi (tre parole consecutive) tra il testo generato e quello di riferimento. • ROUGE-4: Sovrapposizione di quattro grammi (quattro parole consecutive) tra testo generato e di riferimento. • ROUGE-5: Sovrapposizione di cinque grammi (cinque parole consecutive) tra testo generato e di riferimento. • ROUGE-L: Sovrapposizione di L-grammi (parole consecutive L) tra testo generato e di riferimento. Il riepilogo del testo e il confronto dei documenti sono tra i casi d'uso ottimali per ROUGE, in particolare negli scenari in cui la coerenza e la pertinenza del testo sono fondamentali.
La somiglianza del coseno misura il modo in cui due incorporamenti di testo, ad esempio output del modello e testi di riferimento, allineano in senso, aiutando a valutare la somiglianza semantica tra di esse. Come gli altri analizzatori basati su modello, è necessario fornire una distribuzione del modello usando per la valutazione.
Importante
Per questo analizzatore sono supportati solo i modelli di incorporamento:
text-embedding-3-smalltext-embedding-3-largetext-embedding-ada-002
Richiesta personalizzata
Usa il modello per classificare l'output in un set di etichette specificate. Questo analizzatore usa un prompt personalizzato che sarà necessario definire.
