Come configurare i filtri di contenuto con Azure AI Foundry
Il sistema di filtro dei contenuti integrato in Azure AI Foundry viene eseguito insieme ai modelli di base, inclusi i modelli di generazione di immagini DALL-E. Usa un insieme di modelli di classificazione multiclasse per rilevare quattro categorie di contenuto dannoso (violenza, odio, sesso e autolesionismo) in base a quattro livelli di gravità (sicuro, basso, medio e alto) e classificatori binari facoltativi per rilevare il rischio di jailbreak, testo esistente e codice nei repository pubblici.
La configurazione di filtro del contenuto predefinita è impostata per filtrare in base alla soglia di gravità media per tutte e quattro le categorie di contenuti pericolosi sia per le richieste che per i completamenti. Ciò significa che il contenuto rilevato a livello di gravità medio o alto viene filtrato, mentre il contenuto rilevato a livello di gravità basso o sicuro non viene filtrato in base ai filtri di contenuto. Altre informazioni sulle categorie di contenuto, i livelli di gravità e il comportamento del sistema di filtro del contenuto sono disponibili qui.
Il rilevamento dei rischi jailbreak e i modelli di testo e codice protetti sono facoltativi e attivati per impostazione predefinita. Per il rilevamento dei rischi di jailbreak e i modelli di testo e codice protetti, la funzionalità di configurabilità consente a tutti i clienti di attivare e disattivare i modelli. I modelli sono attivati per impostazione predefinita e possono essere disattivati in base allo scenario. Per alcuni scenari è necessario che alcuni modelli siano attivati per mantenere la copertura in base all'Impegno per il copyright del cliente.
Nota
Tutti i clienti hanno la possibilità di modificare i filtri del contenuto e configurare le soglie di gravità (bassa, media, alta). L'approvazione è necessaria per disattivare parzialmente o completamente i filtri di contenuto. I clienti gestiti possono richiedere il controllo completo solo del filtro del contenuto tramite questo modulo: Verifica di accesso limitato di Azure OpenAI: filtri di contenuto modificati. In questo momento, non è possibile diventare un cliente gestito.
I filtri di contenuti possono essere configurati a livello di risorsa. Dopo aver creato una nuova configurazione, può essere associata a una o più distribuzioni. Per altre informazioni sulla distribuzione del modello, vedere la guida alla distribuzione delle risorse.
Prerequisiti
- È necessario disporre di una risorsa di Azure OpenAI e una distribuzione di un modello linguistico di grandi dimensioni per configurare i filtri di contenuti. Per iniziare, seguire una guida di avvio rapido.
Comprendere la configurabilità dei filtri di contenuti
Servizio OpenAI di Azure include le impostazioni di sicurezza predefinita applicata a tutti i modelli, escluso Whisper di Azure OpenAI. Queste configurazioni offrono un'esperienza responsabile per impostazione predefinita, tra cui modelli di filtro dei contenuti, elenchi di elementi bloccati, trasformazione di prompt, credenziali del contenuto e altro ancora. Per altre informazioni, leggere qui.
Tutti i clienti possono anche configurare filtri di contenuto e creare criteri di sicurezza personalizzati in base ai requisiti dei casi d'uso. La funzionalità di configurabilità consente ai clienti di modificare le impostazioni (separatamente per prompt e completamenti) in modo da filtrare contenuto per ogni categoria di contenuto a livelli di gravità diversi, come descritto nella tabella seguente. Il contenuto rilevato con il livello di gravità "sicuro" è etichettato nelle annotazioni, ma non è soggetto al filtro e non è configurabile.
| Intensità del filtro | Configurabile per richieste | Configurabile per completamenti | Descrizione |
|---|---|---|---|
| Basso, medio, elevato | Sì | Sì | Configurazione di filtraggio più intenso. Il contenuto rilevato a livelli di gravità basso, medio e alto viene filtrato. |
| Medio, alto | Sì | Sì | Il contenuto rilevato con livello di gravità basso non viene filtrato, il contenuto a livello medio e alto viene filtrato. |
| Alto | Sì | Sì | Il contenuto rilevato a livelli di gravità basso e medio non viene filtrato. Viene filtrato solo il contenuto a livello di gravità elevato. |
| Nessun filtro | Se approvato1 | Se approvato1 | Nessun contenuto viene filtrato indipendentemente dal livello di gravità rilevato. Richiede approvazione1. |
| Solo annotazione | Se approvato1 | Se approvato1 | Disabilita la funzionalità di filtro, quindi il contenuto non verrà bloccato, ma le annotazioni vengono restituite tramite risposta dell’API. Richiede approvazione1. |
1 Per i modelli di Azure OpenAI, solo i clienti che sono stati approvati per il filtro dei contenuti modificato hanno il controllo completo dei filtri dei contenuti e possono disattivarli. Applicare per i filtri di contenuto modificati tramite questo modulo: Verifica di accesso limitato di Azure OpenAI: Filtri di contenuto modificati. Per Azure per enti pubblici clienti, richiedere filtri di contenuto modificati tramite questo modulo: Azure per enti pubblici - Richiedi filtro contenuto modificato per il servizio OpenAI di Azure.
I filtri di contenuto configurabili per input (prompt) e output (completamenti) sono disponibili per tutti i modelli OpenAI di Azure.
Le configurazioni di filtro del contenuto vengono create all'interno di una risorsa nel portale di Azure AI Foundry e possono essere associate alle distribuzioni. Ulteriori informazioni sulla configurabilità sono disponibili qui.
I clienti sono tenuti ad accertarsi che le applicazioni che integrano Azure OpenAI siano conformi al Codice di comportamento.
Comprendere gli altri filtri
È possibile configurare le categorie di filtro seguenti oltre ai filtri di categoria di danni predefiniti.
| Categoria del filtro | Status | Impostazione predefinita | Applicato a prompt o completamento? | Descrizione |
|---|---|---|---|---|
| Prompt Shields per attacchi diretti (jailbreak) | Disponibilità generale | Attivato | Prompt utente | Filtra/annota i prompt degli utenti che potrebbero presentare un rischio di jailbreak. Per altre informazioni sulle annotazioni, vedere Filtro del contenuto di Azure AI Foundry. |
| Prompt Shields per attacchi indiretti | Disponibilità generale | Disattivato | Prompt utente | Filtra/annota gli attacchi indiretti, noti anche come attacchi con prompt indiretti o attacchi di prompt injection tra domini. Rappresentano una potenziale vulnerabilità in cui soggetti terzi inseriscono istruzioni dannose all'interno di documenti accessibili ed elaborabili dal sistema di intelligenza artificiale generativa. Richiede: incorporamento e formattazione dei documenti. |
| Materiale protetto - codice | Disponibilità generale | Attivato | Completamento | Filtra codice protetto o ottiene le informazioni di citazione e licenza di esempio nelle annotazioni per frammenti di codice che corrispondono a qualsiasi origine di codice pubblica, con tecnologia GitHub Copilot. Per altre informazioni sull'utilizzo delle annotazioni, vedere la guida sui concetti relativi al filtro del contenuto |
| Materiale protetto - testo | Disponibilità generale | Attivato | Completamento | Identifica e blocca la visualizzazione del contenuto di testo noto nell'output del modello (ad esempio, testi di brani musicali, ricette e contenuto Web selezionato). |
| Terra terra* | Anteprima | Disattivato | Completamento | Rileva se le risposte testuali dei modelli linguistici di grandi dimensioni (LLM) sono fondate sui materiali di origine forniti dagli utenti. L’espressione “non fondatezza” si riferisce a istanze in cui i modelli linguistici di grandi dimensioni producono informazioni non concrete o imprecise rispetto a ciò che era presente nei materiali di origine. Richiede: incorporamento e formattazione dei documenti. |
Creare un filtro di contenuto in Azure AI Foundry
Per qualsiasi distribuzione di modelli in Azure AI Foundry, è possibile usare direttamente il filtro contenuto predefinito, ma potrebbe essere necessario avere più controllo. Ad esempio, è possibile rendere un filtro più rigoroso o più indulgente o abilitare funzionalità più avanzate, ad esempio schermate di richiesta e rilevamento dei materiali protetti.
Suggerimento
Per indicazioni sui filtri di contenuto nel progetto Azure AI Foundry, vedere Filtri del contenuto di Azure AI Foundry.
Per creare un filtro di contenuto, seguire questa procedura:
Passare ad Azure AI Foundry e passare al progetto. Selezionare quindi la pagina Sicurezza e sicurezza dal menu a sinistra e selezionare la scheda Filtri contenuto.
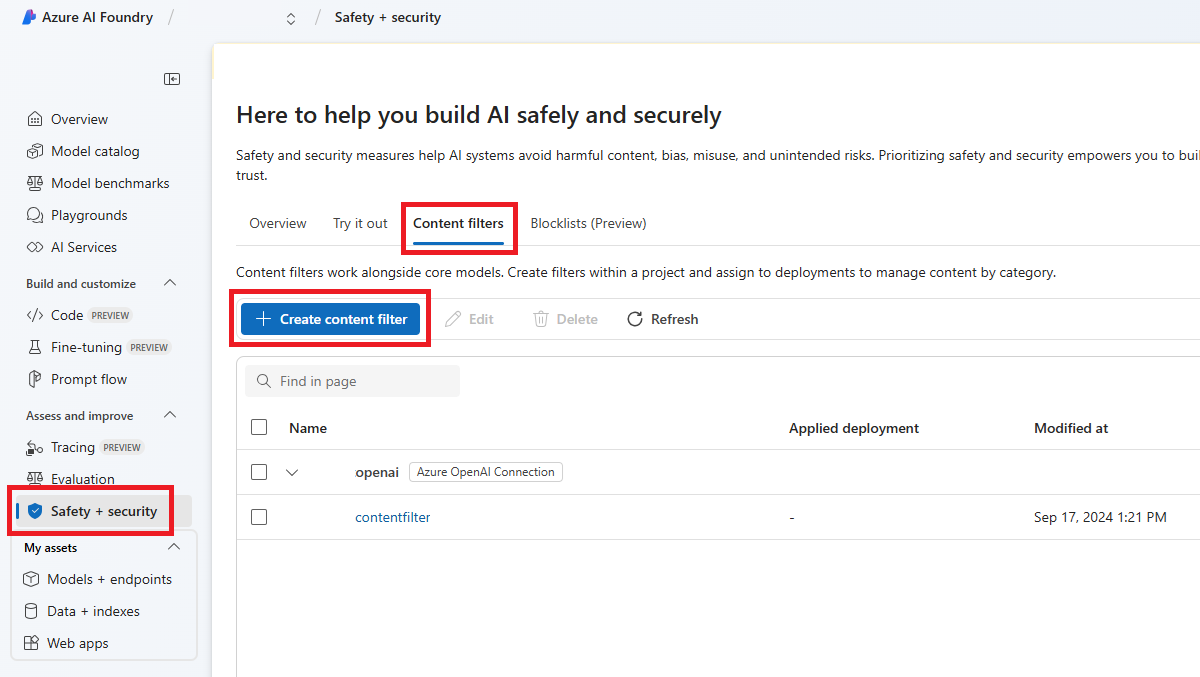
Selezionare + Crea filtro contenuto.
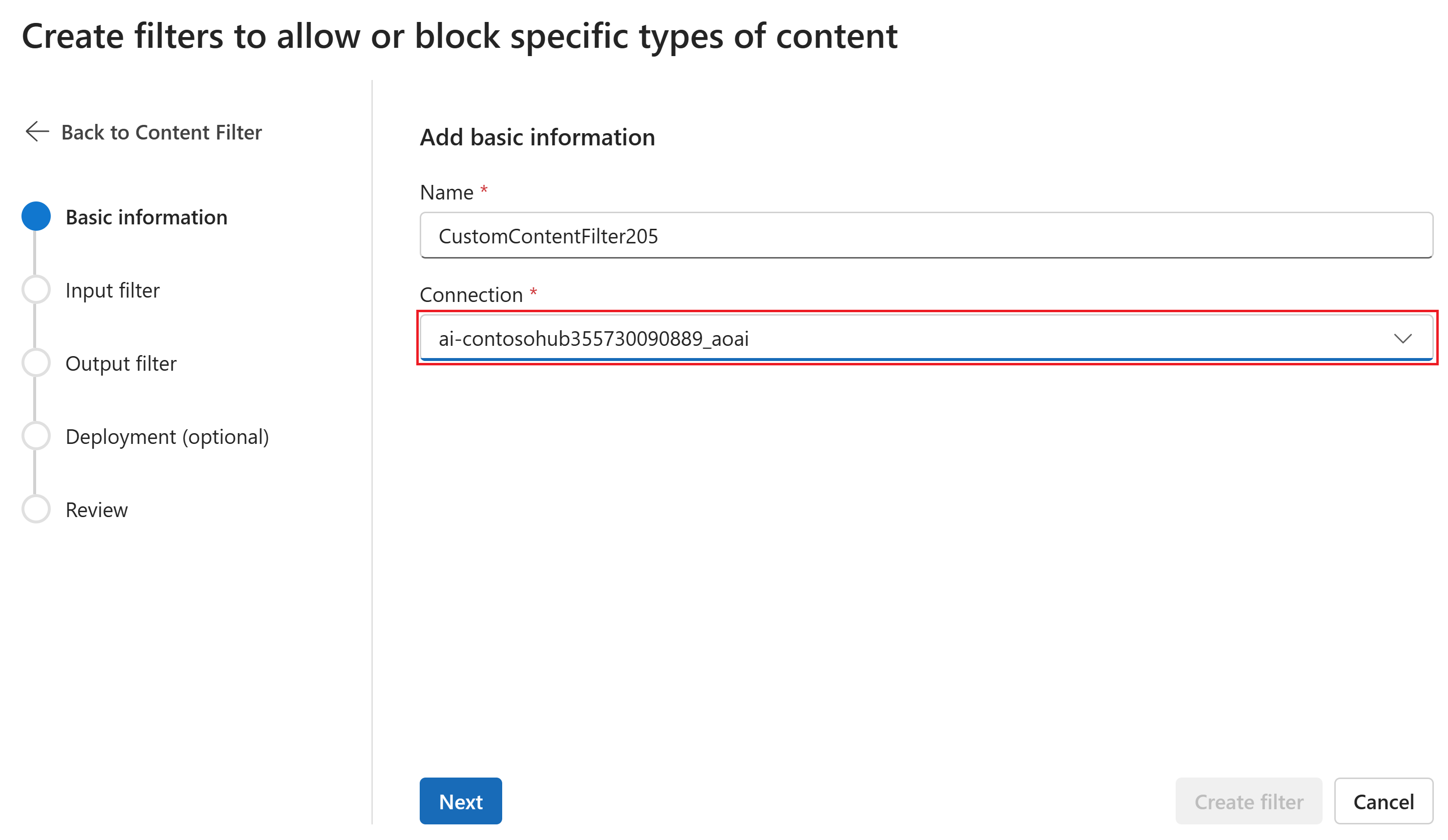
Nella pagina Informazioni di base immettere un nome per la configurazione del filtro del contenuto. Selezionare una connessione da associare al filtro di contenuto. Quindi seleziona Avanti.
È ora possibile configurare i filtri di input (per le richieste degli utenti) e i filtri di output (per il completamento del modello).
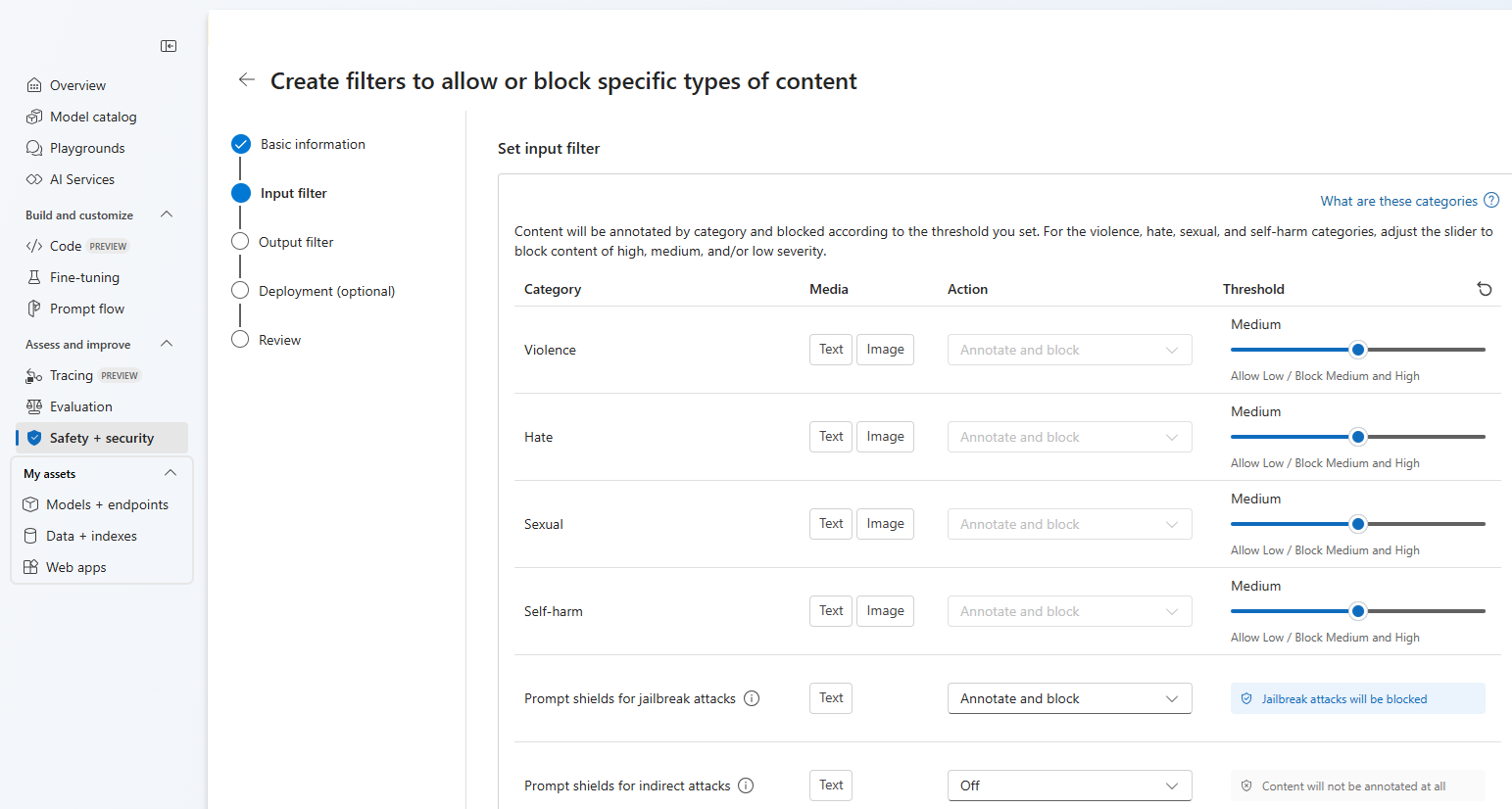
Nella pagina Filtri di input è possibile impostare il filtro per il prompt di input. Per le prime quattro categorie di contenuto sono disponibili tre livelli di gravità configurabili: basso, medio e alto. È possibile usare i dispositivi di scorrimento per impostare la soglia di gravità se si determina che l'applicazione o lo scenario di utilizzo richiede filtri diversi rispetto ai valori predefiniti. Alcuni filtri, ad esempio Prompt Shields e Protected material detection, consentono di determinare se il modello deve annotare e/o bloccare il contenuto. Selezionando Annotazioni viene eseguito solo il rispettivo modello e vengono restituite annotazioni tramite risposta API, ma non verrà filtrato il contenuto. Oltre a aggiungere annotazioni, è anche possibile scegliere di bloccare il contenuto.
Se il caso d'uso è stato approvato per i filtri di contenuto modificati, si riceve il controllo completo sulle configurazioni di filtro dei contenuti e può scegliere di disattivare parzialmente o completamente il filtro oppure abilitare l'annotazione solo per le categorie di danni al contenuto (violenza, odio, sesso e autolesionismo).
Il contenuto verrà annotato per categoria e bloccato in base alla soglia impostata. Per le categorie violenza, odio, sesso e autolesionismo, regolare il dispositivo di scorrimento per bloccare i contenuti di gravità alta, media o bassa.
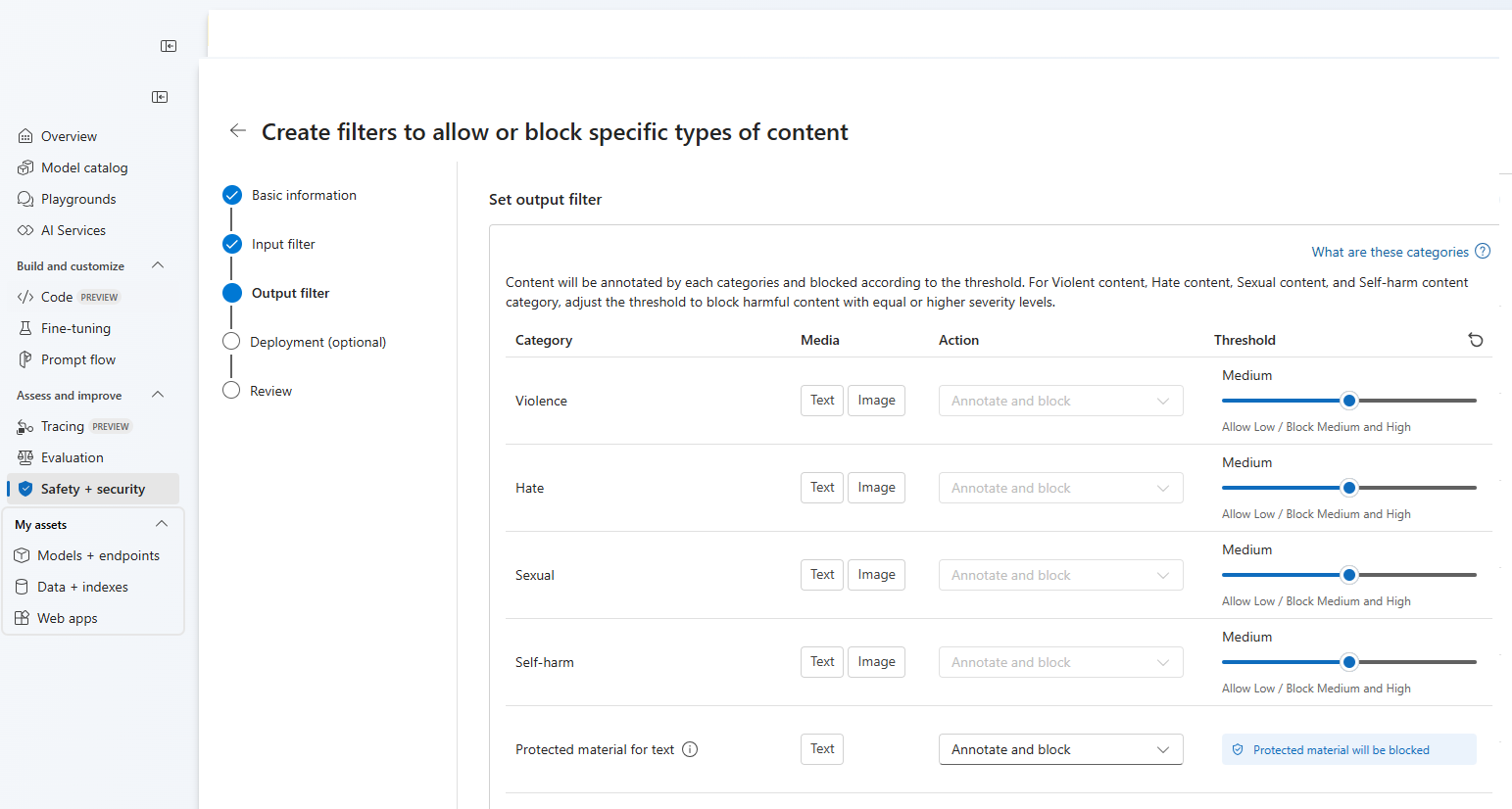
Nella pagina Filtri di output è possibile configurare il filtro di output, che verrà applicato a tutto il contenuto di output generato dal modello. Configurare i singoli filtri come in precedenza. Questa pagina offre anche l'opzione Modalità streaming, che consente di filtrare i contenuti quasi in tempo reale mentre vengono generati dal modello, riducendo la latenza. Al termine, fare clic su Avanti.
Il contenuto verrà annotato per ogni categoria e bloccato in base alla soglia. Per i contenuti violenti, i contenuti di odio, i contenuti sessuali e i contenuti autolesionistici, regolare la soglia per bloccare i contenuti dannosi con livelli di gravità uguali o superiori.
Facoltativamente, nella pagina Distribuzione è possibile associare il filtro di contenuto a una distribuzione. Se una distribuzione selezionata include già un filtro associato, è necessario confermare che si vuole sostituirlo. È anche possibile associare il filtro di contenuto a una distribuzione in un secondo momento. Seleziona Crea.
Le configurazioni di filtro del contenuto vengono create a livello di hub nel portale di Azure AI Foundry. Altre informazioni sulla configurabilità sono disponibili nella documentazione del servizio Azure OpenAI.
Nella pagina Rivedi esaminare le impostazioni e quindi selezionare Crea filtro.



Usare un elenco di blocchi come filtro
È possibile applicare un elenco di elementi bloccati come filtro di input o output o entrambi. Abilitare l'opzione Elenco di elementi bloccati nella pagina Filtro input e/o Filtro output. Selezionare uno o più elenchi di elementi bloccati dall'elenco a discesa, oppure usare l'elenco di elementi bloccati dei contenuti volgari integrato. È possibile combinare più elenchi di elementi bloccati nello stesso filtro.
Applicare un filtro contenuto
Il processo di creazione del filtro offre la possibilità di applicare il filtro alle distribuzioni desiderate. È anche possibile modificare o rimuovere filtri di contenuto dalle distribuzioni in qualsiasi momento.
Per applicare un filtro di contenuto a una distribuzione, seguire questa procedura:
Passare ad Azure AI Foundry e selezionare un progetto.
Selezionare Modelli e endpoint nel riquadro sinistro e scegliere una delle distribuzioni e quindi selezionare Modifica.

Nella finestra Distribuzione aggiornamenti selezionare il filtro di contenuto da applicare alla distribuzione. Successivamente, selezionare Salva e chiudi.

Se necessario, è anche possibile modificare ed eliminare una configurazione del filtro contenuto. Prima di eliminare una configurazione di filtro del contenuto, è necessario annullare l'assegnazione e sostituirla da qualsiasi distribuzione nella scheda Distribuzioni .


È ora possibile passare al playground per verificare se il filtro del contenuto funziona come previsto.
Commenti e suggerimenti sui filtri dei contenuti del report
Se si verifica un problema di filtro del contenuto, selezionare il pulsante Filtri commenti e suggerimenti nella parte superiore del playground. Questa opzione è abilitata nel playground Immagini, Chat e Completamenti dopo aver inviato una richiesta.
Quando viene visualizzata la finestra di dialogo, selezionare il problema di filtro del contenuto appropriato. Includere il maggior numero di dettagli possibile relativi al problema di filtro del contenuto, ad esempio l'errore specifico di filtro del contenuto e prompt. Non includere informazioni private o riservate.
Per il supporto, inviare un ticket di supporto.
Seguire le procedura consigliate
È consigliabile informare le decisioni di configurazione del filtro del contenuto tramite un'identificazione iterativa (ad esempio, test red team, test di stress e analisi) e un processo di misurazione per risolvere i potenziali danni rilevanti per uno scenario specifico di modello, applicazione e distribuzione. Dopo aver implementato mitigazioni come il filtro del contenuto, ripetere la misurazione per testare l'efficacia. Le raccomandazioni e le procedure consigliate per l'intelligenza artificiale responsabile per Azure OpenAI, riportate in Microsoft Responsible AI Standard sono disponibili nella Panoramica dell'intelligenza artificiale responsabile per Azure OpenAI.
Contenuto correlato
- Altre informazioni sulle procedure di intelligenza artificiale responsabile per Azure OpenAI: Panoramica delle procedure di intelligenza artificiale responsabili per i modelli OpenAI di Azure.
- Altre informazioni sul filtro dei contenuti e sui livelli di gravità con Azure AI Foundry.
- Per altre informazioni sul red teaming, vedere l'articolo Introduzione al red teaming di modelli di linguaggio di grandi dimensioni.