Azure OpenAI On Your Data
Usare questo articolo per informazioni su Azure OpenAI on Your Data, che semplifica la connessione, l'inserimento e l'inserimento dei dati aziendali da parte degli sviluppatori per creare rapidamente copiloti personalizzati (anteprima). Migliora la comprensione dell'utente, accelera il completamento delle attività, migliora l'efficienza operativa e aiuta il processo decisionale.
Che cosa è Azure OpenAI On Your Data?
Azure OpenAI On Your Data consente di eseguire modelli di IA avanzati, ad esempio GPT-35-Turbo e GPT-4 sui dati Enterprise senza dover eseguire il training od ottimizzare i modelli. È possibile chattare e analizzare i dati con maggiore precisione. È possibile specificare le origini per supportare le risposte in base alle informazioni più recenti disponibili nelle origini dati designate. È possibile accedere ad Azure OpenAI On Your Data usando un'API REST, tramite l'SDK o l'interfaccia basata sul Web in Studio del Servizio OpenAI di Azure. È anche possibile creare un'app Web che si connette ai dati per abilitare una soluzione di chat avanzata o distribuirla direttamente come copilota in Copilot Studio (anteprima).
Sviluppo con Azure OpenAI On Your Data
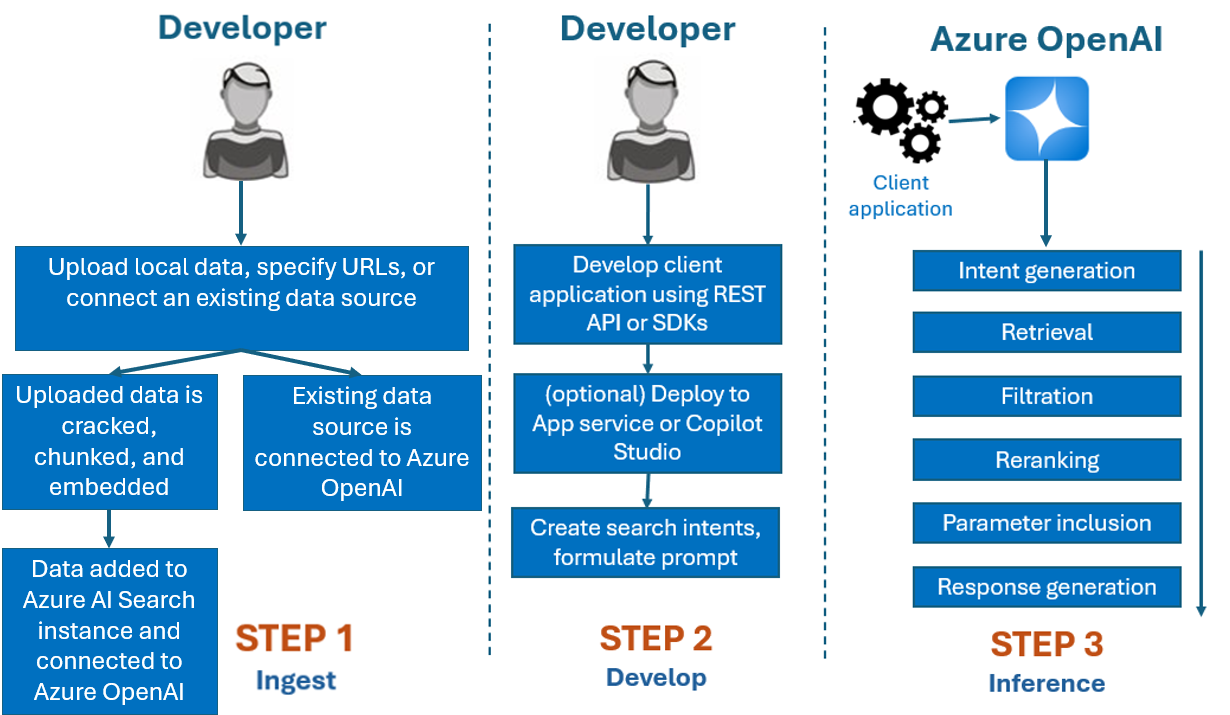
In genere, il processo di sviluppo usato con Azure OpenAI On Your Data è il seguente:
Inserimento: caricare file usando Azure OpenAI Studio o l'API di inserimento. Ciò consente di suddividere, suddividere e incorporare i dati in un'istanza di Ricerca di intelligenza artificiale di Azure che può essere usata dai modelli OpenAI di Azure. Se si ha un'origine dati supportata esistente, è anche possibile connetterla direttamente.
Sviluppo: dopo aver provato Azure OpenAI On Your Data, iniziare a sviluppare l'applicazione usando l'API REST e gli SDK, disponibili in diversi linguaggi. Verranno create richieste e finalità di ricerca da passare al Servizio OpenAI di Azure.
Inferenza: dopo la distribuzione dell'applicazione nell'ambiente preferito, verranno inviate richieste ad Azure OpenAI, che eseguirà diversi passaggi prima di restituire una risposta:
Generazione di finalità: il servizio determinerà la finalità della richiesta dell'utente per determinare una risposta corretta.
Recupero: il servizio recupera blocchi rilevanti di dati disponibili dall'origine dati connessa eseguendo una query su di essa. Ad esempio, usando una ricerca semantica o vettoriale. I parametri, ad esempio la rigidità e il numero di documenti da recuperare, vengono utilizzati per influenzare il recupero.
Applicazione di filtri e riclassificazione : i risultati della ricerca dal passaggio di recupero vengono migliorati classificando e filtrando i dati per perfezionare la pertinenza.
Generazione della risposta: i dati risultanti vengono inviati insieme ad altre informazioni, ad esempio il messaggio di sistema al modello linguistico di grandi dimensioni (LLM), e la risposta viene inviata all'applicazione.
Per iniziare, connettere l'origine dati usando Azure OpenAI Studio e iniziare a porre domande e chattare sui dati.
Controlli degli accessi in base al ruolo di Azure per l'aggiunta di origini dati
Per usare completamente Azure OpenAI On Your Data, è necessario impostare uno o più ruoli controllo degli accessi in base al ruolo di Azure. Per altre informazioni, vedere Usare Azure OpenAI On Your Data in modo sicuro.
Formati di dati e tipi di file
Azure OpenAI On Your Data supporta i tipi di file seguenti:
.txt.md.html.docx.pptx.pdf
Sono presenti un limite di caricamento e alcune avvertenze sulla struttura dei documenti e su come potrebbero influire sulla qualità delle risposte del modello:
Se si converte dati da un formato non supportato in un formato supportato, ottimizzare la qualità della risposta del modello assicurando la conversione:
- Non comporta una perdita significativa di dati.
- Non aggiunge rumore imprevisto ai dati.
Se i file hanno una formattazione speciale, ad esempio tabelle e colonne o punti elenco, preparare i dati con lo script di preparazione dei dati disponibile in GitHub.
Per documenti e set di dati con testo lungo, è bene usare lo script di preparazione dei dati disponibile. Lo script suddivide i dati in modo che le risposte del modello siano più accurate. Questo script supporta anche file e immagini PDF analizzati.
Origini dati supportate
È necessario connettersi a un'origine dati per caricare i dati. Quando si vogliono usare i dati per chattare con un modello OpenAI di Azure, i dati vengono suddivisi in blocchi in un indice di ricerca in modo che i dati pertinenti possano essere trovati in base alle query utente.
Il database vettoriale integrato in Azure Cosmos DB for MongoDB basato su vCore supporta in modo nativo l'integrazione con Azure OpenAI on Your Data.
Per alcune origini dati, ad esempio il caricamento di file dal computer locale (anteprima) o i dati contenuti in un account di archiviazione BLOB (anteprima), viene usato Azure AI Search. Quando si scelgono le origini dati seguenti, i dati vengono inseriti in un indice di Azure AI Search.
| Dati inseriti tramite Azure AI Search | Descrizione |
|---|---|
| Azure AI Search | Usare un indice di Azure AI Search esistente con Azure OpenAI On Your Data. |
| Caricare file (anteprima) | Caricare i file dal computer locale per essere archiviati in un database di Archiviazione BLOB di Azure e inseriti in Azure AI Search. |
| URL/Indirizzo Web (anteprima) | Il contenuto Web degli URL viene archiviato in Archiviazione BLOB di Azure. |
| Archivio BLOB di Azure (anteprima) | Caricare file da Archiviazione BLOB di Azure da inserire in un indice di Azure AI Search. |

- Azure AI Search
- Database vettoriale in Azure Cosmos DB for MongoDB
- Archivio BLOB di Azure (anteprima)
- Caricare file (anteprima)
- URL/Indirizzo Web (anteprima)
- Elasticsearch (anteprima)
- MongoDB Atlas (anteprima)
È possibile prendere in considerazione l'uso di un indice di Ricerca intelligenza artificiale di Azure quando si desidera:
- Personalizzare il processo di creazione dell'indice.
- Riutilizzare un indice creato prima inserendo dati da altre origini dati.
Nota
- Per usare un indice esistente, deve avere almeno un campo ricercabile.
- Impostare l'opzione CORS Consenti tipo di origine su
alle l'opzione Origini consentite su*.
Tipi di ricerca
Azure OpenAI On Your Data fornisce i tipi di ricerca seguenti che è possibile usare quando si aggiunge l'origine dati.
Ricerca vettoriale con i modelli di incorporamento di Ada , disponibili nelle aree selezionate
Per abilitare la ricerca vettoriale, è necessario un modello di incorporamento esistente distribuito nella risorsa OpenAI di Azure. Selezionare la distribuzione di incorporamento durante la connessione dei dati, quindi selezionare uno dei tipi di ricerca vettoriali in Gestione dati. Se si usa Azure AI Search come origine dati, assicurarsi di avere una colonna vettoriale nell'indice.
Se si usa un indice personalizzato, è possibile personalizzare il mapping dei campi quando si aggiunge l'origine dati per definire i campi di cui verrà eseguito il mapping durante la risposta alle domande. Per personalizzare il mapping dei campi, selezionare Usa mapping dei campi personalizzati nella pagina Origine dati quando si aggiunge l'origine dati.
Importante
- La ricerca semantica è soggetta a prezzi aggiuntivi. È necessario scegliere SKU Basic o superiore per abilitare la ricerca semantica o la ricerca vettoriale. Per altre informazioni, vedere Differenze del piano tariffario e Limiti del servizio.
- Per migliorare la qualità della risposta al recupero e al modello delle informazioni, è consigliabile abilitare la ricerca semantica per le seguenti lingue di origine dati: inglese, francese, spagnolo, portoghese, italiano, tedesco, cinese(Zh), giapponese, coreano, russo e arabo.
| Opzione di ricerca | Tipo di recupero | Prezzi aggiuntivi? | Vantaggi |
|---|---|---|---|
| keyword | Ricerca per parole chiave | Nessun prezzo aggiuntivo. | Esegue l'analisi e l'abbinamento di query in modo veloce e flessibile su campi ricercabili, usando termini o frasi in qualsiasi linguaggio supportato, con o senza operatori. |
| semantico | Ricerca semantica | Prezzi aggiuntivi per l'utilizzo della ricerca semantica. | Migliora la precisione e la pertinenza dei risultati della ricerca usando un reranker (con i modelli di intelligenza artificiale) per comprendere il significato semantico dei termini di query e dei documenti restituiti dal ranker di ricerca iniziale |
| vector | Ricerca vettoriale | Prezzi aggiuntivi per l'account Azure OpenAI dalla chiamata al modello di incorporamento. | Consente di trovare documenti simili a un determinato input di query in base agli incorporamenti vettoriali del contenuto. |
| ibrido (vettore + parola chiave) | Un ibrido di ricerca vettoriale e ricerca di parole chiave | Prezzi aggiuntivi per l'account Azure OpenAI dalla chiamata al modello di incorporamento. | Esegue una ricerca di somiglianza sui campi vettoriali usando incorporamenti vettoriali, supportando anche l'analisi flessibile delle query e la ricerca full-text su campi alfanumerici usando query di termini. |
| ibrido (vettore + parola chiave) + semantico | Un ibrido di ricerca vettoriale, ricerca semantica e ricerca di parole chiave. | Prezzi aggiuntivi per l'account Azure OpenAI dalla chiamata al modello di incorporamento e prezzi aggiuntivi per l'uso della ricerca semantica. | Usa incorporamenti vettoriali, comprensione del linguaggio e analisi flessibile delle query per creare esperienze di ricerca avanzate e app di intelligenza artificiale generative in grado di gestire scenari complessi e diversificati di recupero delle informazioni. |
Ricerca intelligente
Azure OpenAI On Your Data ha abilitato la ricerca intelligente per i dati. La ricerca semantica è abilitata per impostazione predefinita se si dispone sia della ricerca semantica che della ricerca di parole chiave. Se si hanno modelli di incorporamento, per impostazione predefinita la ricerca intelligente è ibrida e semantica.
Controllo di accesso a livello di documento
Nota
Il controllo di accesso a livello di documento è supportato quando si seleziona Azure AI Search come origine dati.
Azure OpenAI per i dati consente di limitare i documenti che possono essere usati nelle risposte per utenti diversi con filtri di sicurezza di Azure AI Search. Quando si abilita l'accesso a livello di documento, i risultati della ricerca restituiti da Azure AI Search e usati per generare una risposta sono eliminati in base all'appartenenza al gruppo Microsoft Entra dell'utente. Per altre informazioni, è possibile abilitare l'accesso a livello di documento solo sugli indici di Azure AI Search esistenti. Per altre informazioni, vedere Usare Azure OpenAI On Your Data in modo sicuro.
Mapping dei campi indice
Se si usa un indice personalizzato, verrà richiesto in Azure OpenAI Studio di definire i campi di cui si desidera eseguire il mapping per rispondere alle domande quando si aggiunge l'origine dati. È possibile specificare più campi per i Dati contenutoe includere tutti i campi con testo relativo al caso d'uso.

In questo esempio, i campi mappati a Dati contenuto e Titolo forniscono informazioni al modello per rispondere alle domande. Il titolo viene usato anche per assegnare un titolo al testo della citazione. Il campo mappato al Nome file genera i nomi di citazione nella risposta.
Il mapping corretto di questi campi consente di garantire che il modello abbia una migliore qualità di risposta e citazione. È anche possibile configurarlo nell'API usando il parametro fieldsMapping.
Filtro di ricerca (API)
Se si vogliono implementare criteri aggiuntivi basati su valori per l'esecuzione di query, è possibile configurare un filtro di ricerca usando il parametro filternell'API REST.
Come vengono inseriti i dati in Azure AI Search
A partire da settembre 2024, le API di inserimento sono passate alla vettorizzazione integrata. Questo aggiornamento non modifica i contratti API esistenti. La vettorializzazione integrata, una nuova offerta di Ricerca di intelligenza artificiale di Azure, usa competenze predefinite per la suddivisione in blocchi e l'incorporamento dei dati di input. Azure OpenAI nel servizio di inserimento dati non usa più competenze personalizzate. Dopo la migrazione alla vettorializzazione integrata, il processo di inserimento ha subito alcune modifiche e di conseguenza vengono creati solo gli asset seguenti:
{job-id}-index{job-id}-indexer, se viene specificata una pianificazione oraria o giornaliera, in caso contrario, l'indicizzatore viene pulito alla fine del processo di inserimento.{job-id}-datasource
Il contenitore blocchi non è più disponibile, poiché questa funzionalità è ora gestita intrinsecamente da Ricerca di intelligenza artificiale di Azure.
Connessione dati
È necessario selezionare la modalità di autenticazione della connessione da Azure OpenAI, Azure AI Search e archiviazione BLOB di Azure. È possibile scegliere un'identità gestita assegnata dal sistema o una chiave API. Selezionando la chiave API come tipo di autenticazione, il sistema popola automaticamente la chiave API per connettersi con le risorse di Azure AI Search, Azure OpenAI e Archiviazione BLOB di Azure. Selezionando Identità gestita assegnata dal sistema, l'autenticazione sarà basata sull'assegnazione di ruolo. L'identità gestita assegnata dal sistema è selezionata per impostazione predefinita per la sicurezza.

Dopo aver selezionato il pulsante Avanti, il programma di installazione verrà convalidato automaticamente per l'uso del metodo di autenticazione selezionato. Se si verifica un errore, vedere l'articolo sulle assegnazioni di ruolo per aggiornare la configurazione.
Dopo aver corretto l'installazione, selezionare nuovamente Avanti per convalidare e continuare. Gli utenti dell'API possono anche configurare l'autenticazione con chiavi API e identità gestite assegnate.









Eseguire la distribuzione in un copilota (anteprima), in un’app Teams (anteprima) o in un'app Web
Dopo aver connesso Azure OpenAI ai dati, è possibile distribuirlo usando il pulsante Distribuisci in Studio di Azure OpenAI.

In questo modo sono disponibili più opzioni per la distribuzione della soluzione.
È possibile eseguire la distribuzione in copilota in Copilot Studio (anteprima) direttamente da Studio di Azure OpenAI, consentendo di portare esperienze di conversazione in vari canali, ad esempio Microsoft Teams, siti Web, Dynamics 365 e altri canali del servizio Azure Bot. Il tenant usato nel servizio Azure OpenAI e Copilot Studio (anteprima) deve essere lo stesso. Per altre informazioni, vedere Usare una connessione ad Azure OpenAI On Your Data.
Nota
La distribuzione in copilota in Copilot Studio (anteprima) è disponibile solo nelle aree degli Stati Uniti.
Uso di Azure OpenAI On Your Data in modo sicuro
È possibile usare Azure OpenAI On Your Data in modo sicuro proteggendo i dati e le risorse con il controllo degli accessi in base al ruolo, le reti virtuali e gli endpoint privati di Microsoft Entra ID. È anche possibile limitare i documenti che possono essere usati nelle risposte per utenti diversi con filtri di sicurezza di Ricerca intelligenza artificiale di Azure. Vedere Uso di Azure OpenAI On Your Data in modo sicuro.
Procedure consigliate
Usare le sezioni seguenti per informazioni su come migliorare la qualità delle risposte fornite dal modello.
Parametro di inserimento
Quando i dati vengono inseriti in Azure AI Search, è possibile modificare le impostazioni aggiuntive seguenti in Studio o nell'API di inserimento.
Dimensioni blocco (anteprima)
Azure OpenAI On Your Data elabora i documenti suddividendoli in blocchi prima di inserirli. La dimensione del blocco è la dimensione massima in termini di numero di token di qualsiasi blocco nell'indice di ricerca. Le dimensioni dei blocchi e il numero di documenti recuperati insieme controllano la quantità di informazioni (token) incluse nella richiesta inviata al modello. In generale, la dimensione del blocco moltiplicata per il numero di documenti recuperati è il numero totale di token inviati al modello.
Impostazione delle dimensioni del blocco per il caso d'uso
La dimensione predefinita del blocco è 1.024 token. Tuttavia, data l'univocità dei dati, è possibile che si trovino dimensioni di blocco diverse (ad esempio 256, 512 o 1.536 token) più efficaci.
La regolazione delle dimensioni del blocco può migliorare le prestazioni del chatbot. Anche se la ricerca delle dimensioni ottimali dei blocchi richiede una prova e un errore, iniziare considerando la natura del set di dati. Una dimensione di blocco più piccola è in genere migliore per i set di dati con fatti diretti e meno contesto, mentre una dimensione di blocchi più grande potrebbe essere utile per informazioni più contestuali, anche se potrebbe influire sulle prestazioni di recupero.
Una piccola dimensione di blocco come 256 produce blocchi più granulari. Questa dimensione significa anche che il modello utilizzerà meno token per generare il relativo output (a meno che il numero di documenti recuperati non sia molto elevato), potenzialmente costa meno. I blocchi più piccoli indicano anche che il modello non deve elaborare e interpretare sezioni lunghe di testo, riducendo il rumore e la distrazione. Questa granularità e messa a fuoco rappresentano tuttavia un potenziale problema. Le informazioni importanti potrebbero non essere tra i blocchi recuperati in alto, soprattutto se il numero di documenti recuperati è impostato su un valore basso come 3.
Suggerimento
Tenere presente che la modifica delle dimensioni del blocco richiede che i documenti vengano reinseriti, quindi è utile prima modificare i parametri di runtime come la rigidità e il numero di documenti recuperati. Valutare la possibilità di modificare le dimensioni del blocco se non si ottengono ancora i risultati desiderati:
- Se si riscontra un numero elevato di risposte, ad esempio "Non so" per le domande con risposte che devono trovarsi nei documenti, è consigliabile ridurre le dimensioni del blocco a 256 o 512 per migliorare la granularità.
- Se il chatbot fornisce alcuni dettagli corretti ma mancano altri, che diventa evidente nelle citazioni, aumentando le dimensioni del blocco a 1.536 potrebbe aiutare a acquisire informazioni più contestuali.
Parametri del runtime
È possibile modificare le impostazioni aggiuntive seguenti nella sezione Parametri di dati in Azure OpenAI Studio e nell'API. Non è necessario eseguire il ripristino dei dati quando si aggiornano questi parametri.
| Nome parametro | Descrizione |
|---|---|
| Limitare le risposte ai dati | Questo flag configura l'approccio del chatbot alla gestione delle query non correlate all'origine dati o quando i documenti di ricerca non sono sufficienti per una risposta completa. Quando questa impostazione è disabilitata, il modello integra le risposte con le proprie conoscenze oltre ai documenti. Quando questa impostazione è abilitata, il modello tenta di basarsi solo sui documenti per le risposte. Si tratta del parametro inScope nell'API e impostato su true per impostazione predefinita. |
| Documenti recuperati | Questo parametro è un numero intero che può essere impostato su 3, 5, 10 o 20 e controlla il numero di blocchi di documento forniti al modello linguistico di grandi dimensioni per simulare la risposta finale. Per impostazione predefinita, il valore è impostato su 5. Il processo di ricerca può essere rumoroso e talvolta, a causa della suddivisione in blocchi, le informazioni rilevanti potrebbero essere distribuite tra più blocchi nell'indice di ricerca. La selezione di un numero top-K, ad esempio 5, garantisce che il modello possa estrarre informazioni rilevanti, nonostante le limitazioni intrinseche della ricerca e della suddivisione in blocchi. Tuttavia, l'aumento del numero troppo elevato può potenzialmente distrarre il modello. Inoltre, il numero massimo di documenti che possono essere usati in modo efficace dipende dalla versione del modello, in quanto ognuno ha una diversa dimensione del contesto e capacità per la gestione dei documenti. Se si ritiene che le risposte non siano presenti contesto importante, provare ad aumentare questo parametro. Questo è il parametro topNDocuments nell'API e è 5 per impostazione predefinita. |
| Rigore | Determina l'aggressività del sistema nell'applicazione di filtri ai documenti di ricerca in base ai punteggi di somiglianza. Il sistema esegue query in Ricerca di Azure o in altri archivi documenti, quindi decide quali documenti fornire a modelli linguistici di grandi dimensioni, ad esempio ChatGPT. L'applicazione di filtri ai documenti irrilevanti può migliorare significativamente le prestazioni del chatbot end-to-end. Alcuni documenti vengono esclusi dai risultati top-K se hanno punteggi di somiglianza bassi prima di inoltrarli al modello. Questo controllo è controllato da un valore intero compreso tra 1 e 5. L'impostazione di questo valore su 1 indica che il sistema filtra in modo minimo i documenti in base alla somiglianza della ricerca con la query utente. Viceversa, un'impostazione di 5 indica che il sistema filtra in modo aggressivo i documenti, applicando una soglia di somiglianza molto elevata. Se si scopre che il chatbot omette informazioni rilevanti, ridurre la rigidità del filtro (impostare il valore più vicino a 1) per includere più documenti. Viceversa, se documenti irrilevanti distraggono le risposte, aumentare la soglia (impostare il valore più vicino a 5). Si tratta del parametro strictness nell'API e impostato su 3 per impostazione predefinita. |
Riferimenti non autorizzati
È possibile che il modello restituisca "TYPE":"UNCITED_REFERENCE" anziché "TYPE":CONTENT nell'API per i documenti recuperati dall'origine dati, ma non inclusi nella citazione. Ciò può essere utile per il debug ed è possibile controllare questo comportamento modificando i parametri di esecuzione rigidità e runtime dei documenti recuperati descritti in precedenza.
Messaggio di sistema
È possibile definire un messaggio di sistema per indirizzare la risposta del modello quando si usa Azure OpenAI On Your Data. Questo messaggio consente di personalizzare le risposte oltre al modello di generazione aumentata (RAG) di recupero usato da Azure OpenAI On Your Data. Il messaggio di sistema viene usato oltre a un prompt di base interno per fornire l'esperienza. Per supportare questo problema, il messaggio di sistema viene troncato dopo un numero specifico di token per garantire che il modello possa rispondere alle domande usando i dati. Se si definisce un comportamento aggiuntivo oltre all'esperienza predefinita, assicurarsi che la richiesta di sistema sia dettagliata e spiega la personalizzazione esatta prevista.
Dopo aver selezionato aggiungi il set di dati, è possibile usare la sezione Messaggio di sistema in Azure OpenAI Studio o il role_informationparametro nell'API.

Modelli di utilizzo potenziali
Definire un ruolo
È possibile definire un ruolo che si desidera usare per l'assistente. Ad esempio, se si sta creando un bot di supporto, è possibile aggiungere "Si è un addetto all'assistenza clienti esperto di incidenti che aiuta gli utenti a risolvere nuovi problemi".
Definire il tipo di dati da recuperare
È anche possibile aggiungere la natura dei dati che si sta fornendo all'assistente.
- Definire l'argomento o l'ambito del set di dati, ad esempio "report finanziario", "documento accademico" o "report degli incidenti". Ad esempio, per il supporto tecnico, è possibile aggiungere "È possibile rispondere alle query usando informazioni provenienti da incidenti simili nei documenti recuperati".
- Se i dati hanno determinate caratteristiche, è possibile aggiungere questi dettagli al messaggio di sistema. Ad esempio, se i documenti sono in giapponese, è possibile aggiungere "Recuperare i documenti giapponesi e leggerli attentamente in giapponese e rispondere in giapponese".
- Se i documenti includono dati strutturati come tabelle di un report finanziario, è anche possibile aggiungere questo fatto alla richiesta di sistema. Ad esempio, se i dati contengono tabelle, è possibile aggiungere "Vengono forniti dati sotto forma di tabelle relative ai risultati finanziari ed è necessario leggere la riga della tabella in base alla riga per eseguire calcoli per rispondere alle domande dell'utente".
Definire il sink di output
È anche possibile modificare l'output del modello definendo un messaggio di sistema. Ad esempio, se si desidera assicurarsi che le risposte dell'assistente siano in francese, è possibile aggiungere un prompt come "Si è un assistente IA che aiuta gli utenti che capiscono il francese a trovare informazioni. Le domande dell'utente possono essere in inglese o francese. Leggere attentamente i documenti recuperati e rispondere in francese. Tradurre le informazioni dai documenti in francese per garantire che tutte le risposte siano in francese".
Riconfermare il comportamento critico
Azure OpenAI On Your Data funziona inviando istruzioni a un modello linguistico di grandi dimensioni sotto forma di richieste di risposta alle query utente usando i dati. Se esiste un determinato comportamento critico per l'applicazione, è possibile ripetere il comportamento nel messaggio di sistema per aumentarne l'accuratezza. Ad esempio, per guidare il modello a rispondere solo dai documenti, è possibile aggiungere "Rispondere solo usando documenti recuperati e senza usare le proprie conoscenze. Generare citazioni per i documenti recuperati per ogni attestazione nella risposta. Se non è possibile rispondere alla domanda dell'utente usando documenti recuperati, spiegare il motivo per cui i documenti sono rilevanti per le query utente. In ogni caso, non rispondere usando le proprie conoscenze".
Trucchi sulla progettazione delle richieste
Ci sono molti trucchi nella progettazione prompt che è possibile provare a migliorare l'output. Un esempio è la richiesta concatenazione in cui è possibile aggiungere "Si considerino le informazioni dettagliate nei documenti recuperati per rispondere alle query dell'utente. Estrarre le informazioni pertinenti per le query utente dai documenti passo dopo passo e formare una risposta di tipo bottom-up dalle informazioni estratte dai documenti pertinenti".
Nota
Il messaggio di sistema viene usato per modificare il modo in cui l'assistente GPT risponde a una domanda dell'utente in base alla documentazione recuperata. Non influisce sul processo di recupero. Se vuoi fornire istruzioni per il processo di recupero, è preferibile includerli nelle domande. Il messaggio di sistema è solo materiale sussidiario. Il modello potrebbe non essere conforme a tutte le istruzioni specificate perché è stato avviato con determinati comportamenti, ad esempio l'obiettività, ed evitando affermazioni controverse. Potrebbe verificarsi un comportamento imprevisto se il messaggio di sistema è in contrasto con questi comportamenti.
Risposta massima
Impostare un limite per il numero di token per risposta al modello. Il limite massimo per Azure OpenAI On Your Data è 1500. Equivale a impostare il parametro in API max_tokens.
Limitare le risposte ai dati
Questa opzione incoraggia il modello a rispondere solo usando i propri dati ed è selezionata per impostazione predefinita. Se si deseleziona questa opzione, il modello potrebbe applicare più facilmente le proprie conoscenze interne per rispondere. Determinare la selezione corretta in base al caso d'uso e allo scenario.
Interazione con il modello
Usare le procedure seguenti per ottenere risultati ottimali durante la chat con il modello.
Cronologia conversazioni
- Prima di avviare una nuova conversazione (o porre una domanda non correlata a quelle precedenti), cancellare la cronologia delle chat.
- È possibile ottenere risposte diverse per la stessa domanda tra il primo turno di conversazione e i turni successivi perché la cronologia delle conversazioni modifica lo stato corrente del modello. Se si ricevono risposte non corrette, segnalarlo come bug di qualità.
Risposta del modello
Se non si è soddisfatti della risposta del modello per una domanda specifica, provare a rendere la domanda più specifica o più generica per verificare la risposta del modello e rimodulare la domanda di conseguenza.
Il Prompt Chain-of-Thought (a catena di pensieri) si è dimostrato efficace per ottenere il modello di produzione di output desiderati per domande/attività complesse.
Lunghezza della domanda
Evitare di porre domande lunghe e suddividerle in più domande, se possibile. I modelli GPT hanno limiti al numero di token che possono accettare. I limiti dei token vengono conteggiati per: la domanda dell'utente, il messaggio di sistema, i documenti di ricerca recuperati (blocchi), i prompt interni, la cronologia delle conversazioni (se presente) e la risposta. Se la domanda supera il limite di token, verrà troncata.
Supporto multilingue
Attualmente, la ricerca di parole chiave e la ricerca semantica in Azure OpenAI On Your Data supportano query nella stessa lingua dei dati nell'indice. Ad esempio, se i dati sono in giapponese, anche le query immesse devono essere in giapponese. Per il recupero di documenti multilingue, è consigliabile compilare l'indice con la ricerca vettoriale abilitata.
Per migliorare la qualità della risposta al recupero e al modello delle informazioni, è consigliabile abilitare la ricerca semantica per le seguenti lingue: inglese, francese, spagnolo, portoghese, italiano, tedesco, cinese(Zh), giapponese, coreano, russo e arabo
È consigliabile usare un messaggio di sistema per informare il modello che i dati si trovano in un'altra lingua. Ad esempio:
*"*Si è un assistente IA progettato per aiutare gli utenti a estrarre informazioni dai documenti giapponesi recuperati. Esaminare attentamente i documenti giapponesi prima di formulare una risposta. La query dell'utente sarà in giapponese ed è necessario rispondere anche in giapponese".
Se si dispone di documenti in più lingue, è consigliabile creare un nuovo indice per ogni lingua e creare connessioni separate a OpenAI di Azure.
Streaming di dati
È possibile inviare una richiesta di streaming usando il parametro stream, consentendo l'invio e la ricezione incrementale dei dati, senza attendere l'intera risposta API. Ciò può migliorare le prestazioni e l'esperienza utente, in particolare per dati di grandi dimensioni o dinamici.
{
"stream": true,
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": "'$AZURE_AI_SEARCH_ENDPOINT'",
"key": "'$AZURE_AI_SEARCH_API_KEY'",
"indexName": "'$AZURE_AI_SEARCH_INDEX'"
}
}
],
"messages": [
{
"role": "user",
"content": "What are the differences between Azure Machine Learning and Azure AI services?"
}
]
}
Cronologia conversazioni per risultati migliori
Quando si chatta con un modello, fornendo una cronologia della chat, il modello restituirà risultati di qualità più elevati. Non è necessario includere la proprietà context dei messaggi di assistente nelle richieste API per ottenere una migliore qualità della risposta. Per informazioni dettagliate, vedere la documentazione di riferimento API.
Chiamata di funzione
Alcuni modelli OpenAI di Azure consentono di definire strumenti e parametri tool_choice per abilitare la chiamata di funzioni. È possibile configurare la chiamata di funzione tramite l'API REST /chat/completions. Se entrambe le origini dati tools e sono incluse nella richiesta, vengono applicati i criteri seguenti.
- Se
tool_choiceènone, gli strumenti vengono ignorati e vengono usate solo le origini dati per generare la risposta. - In caso contrario, se
tool_choicenon viene specificato o specificato comeautoo un oggetto, le origini dati vengono ignorate e la risposta conterrà il nome delle funzioni selezionate e gli argomenti, se presenti. Anche se il modello decide che non è selezionata alcuna funzione, le origini dati vengono comunque ignorate.
Se i criteri precedenti non soddisfano le esigenze, prendere in considerazione altre opzioni, ad esempio flusso di richieste o API assistenti.
Stima dell'utilizzo dei token per Azure OpenAI On Your Data
Azure OpenAI on Your Data Retrieval Augmented Generation (RAG) è un servizio che sfrutta sia un servizio di ricerca (ad esempio Azure AI Search) che la generazione (modelli OpenAI di Azure) per consentire agli utenti di ottenere risposte per le proprie domande in base ai dati forniti.
Come parte di questa pipeline RAG, esistono tre passaggi a livello generale:
Riformula la query dell'utente in un elenco di finalità di ricerca. A tale scopo, effettuare una chiamata al modello con un prompt che include istruzioni, la domanda dell'utente e la cronologia delle conversazioni. Chiamiamo questo prompt di finalità.
Per ogni finalità, più blocchi di documenti vengono recuperati dal servizio di ricerca. Dopo aver filtrato blocchi irrilevanti in base alla soglia specificata dall'utente di rigidità e reranking/aggregazione dei blocchi in base alla logica interna, viene scelto il numero specificato dall'utente di blocchi di documento.
Questi blocchi di documenti, insieme alla domanda dell'utente, alla cronologia delle conversazioni, alle informazioni sul ruolo e alle istruzioni vengono inviate al modello per generare la risposta finale del modello. Chiamare questo prompt di generazione.
In totale, esistono due chiamate effettuate al modello:
Per l'elaborazione della finalità: la stima del token per il prompt di finalità include quelle per la domanda dell'utente, la cronologia delle conversazioni e le istruzioni inviate al modello per la generazione delle finalità.
Per generare la risposta: la stima del token per il prompt di generazione include quelle per la domanda dell'utente, la cronologia delle conversazioni, l'elenco recuperato di blocchi di documenti, le informazioni sul ruolo e le istruzioni inviate per la generazione.
I token di output generati dal modello (finalità e risposta) devono essere presi in considerazione per la stima totale dei token. Sommando tutte le quattro colonne seguenti, vengono restituiti i token totali medi usati per generare una risposta.
| Modello | Numero di token di richiesta di generazione | Conteggio dei token di richiesta delle finalità | Numero di token di risposta | Conteggio dei token di finalità |
|---|---|---|---|---|
| gpt-35-turbo-16k | 4297 | 1366 | 111 | 25 |
| gpt-4-0613 | 3997 | 1385 | 118 | 18 |
| gpt-4, 1106-Preview | 4538 | 811 | 119 | 27 |
| gpt-35-turbo-1106 | 4854 | 1372 | 110 | 26 |
I numeri precedenti si basano sul test su un set di dati con:
- 191 conversazioni
- 250 domande
- 10 token medi per domanda
- 4 turni di conversazione per conversazione in media
E i parametri seguenti.
| Impostazione | Valore |
|---|---|
| Numero di documenti recuperati | 5 |
| Rigore | 3 |
| Dimensioni blocco | 1024 |
| Limitare le risposte ai dati inseriti? | Vero |
Queste stime variano in base ai valori impostati per i parametri precedenti. Ad esempio, se il numero di documenti recuperati è impostato su 10 e la rigidità è impostata su 1, il numero di token andrà in alto. Se le risposte restituite non sono limitate ai dati inseriti, al modello vengono fornite meno istruzioni e il numero di token scenderà.
Le stime dipendono anche dalla natura dei documenti e delle domande poste. Ad esempio, se le domande sono aperte, è probabile che le risposte siano più lunghe. Analogamente, un messaggio di sistema più lungo contribuirà a un prompt più lungo che utilizza più token e, se la cronologia delle conversazioni è lunga, la richiesta sarà più lunga.
| Modello | Numero massimo di token per il messaggio di sistema |
|---|---|
| GPT-35-0301 | 400 |
| GPT-35-0613-16K | 1000 |
| GPT-4-0613-8K | 400 |
| GPT-4-0613-32K | 2000 |
| GPT-35-turbo-0125 | 2000 |
| GPT-4-turbo-0409 | 4000 |
| GPT-4o | 4000 |
| GPT-4o-mini | 4000 |
La tabella precedente mostra il numero massimo di token che possono essere usati per il messaggio di sistema. Per visualizzare i token massimi per la risposta del modello, vedere l'articolo sui modelli. Inoltre, gli elementi seguenti usano anche i token:
Il meta prompt: se si limitano le risposte dal modello al contenuto dei dati di base (
inScope=Truenell'API), il numero massimo di token più alto. In caso contrario (ad esempio seinScope=False) il valore massimo è inferiore. Questo numero è variabile a seconda della lunghezza del token della domanda dell'utente e della cronologia delle conversazioni. Questa stima include il prompt di base e le richieste di riscrittura delle query per il recupero.Domanda e cronologia utente: variabile ma limitata a 2.000 token.
Documenti recuperati (blocchi): il numero di token usati dai blocchi di documenti recuperati dipende da più fattori. Il limite superiore per questo è il numero di blocchi di documenti recuperati moltiplicati per le dimensioni del blocco. Verrà tuttavia troncato in base ai token disponibili per il modello specifico usato dopo aver conteggiato il resto dei campi.
Il 20% dei token disponibili è riservato per la risposta del modello. Il rimanente 80% dei token disponibili include il meta prompt, la cronologia delle domande e delle conversazioni dell'utente e il messaggio di sistema. Il budget del token rimanente viene usato dai blocchi di documento recuperati.
Per calcolare il numero di token utilizzati dall'input ,ad esempio la domanda, le informazioni sul messaggio/ruolo di sistema, usare l'esempio di codice seguente.
import tiktoken
class TokenEstimator(object):
GPT2_TOKENIZER = tiktoken.get_encoding("gpt2")
def estimate_tokens(self, text: str) -> int:
return len(self.GPT2_TOKENIZER.encode(text))
token_output = TokenEstimator.estimate_tokens(input_text)
Risoluzione dei problemi
Per risolvere i problemi relativi alle operazioni non riuscite, cercare sempre gli errori o gli avvisi specificati nella risposta api o in Studio di Azure OpenAI. Ecco alcuni degli errori e degli avvisi comuni:
Processi di inserimento non riusciti
Problemi sulle limitazioni di quota
Non è stato possibile creare un indice con il nome X nel servizio Y. La quota di indice è stata superata per questo servizio. È necessario prima eliminare gli indici inutilizzati, aggiungere un ritardo tra le richieste di creazione dell'indice o aggiornare il servizio per limiti più elevati.
La quota dell'indicizzatore standard di X è stata superata per questo servizio. Attualmente sono disponibili indicizzatori X standard. È necessario prima eliminare gli indicizzatori inutilizzati, modificare l'indicizzatore 'executionMode' o aggiornare il servizio per limiti più elevati.
Risoluzione:
Eseguire l'aggiornamento a un piano tariffario superiore o eliminare asset inutilizzati.
Problemi di timeout di pre-elaborazione
Impossibile eseguire la competenza perché la richiesta dell'API Web non è riuscita
Impossibile eseguire la competenza perché la risposta della competenza dell'API Web non è valida
Risoluzione:
Suddividere i documenti di input in documenti più piccoli e riprovare.
Problemi con le autorizzazioni
Questa richiesta non è autorizzata a eseguire questa operazione
Risoluzione:
Ciò significa che l'account di archiviazione non è accessibile con le credenziali specificate. In questo caso, esaminare le credenziali dell'account di archiviazione passate all'API e assicurarsi che l'account di archiviazione non sia nascosto dietro un endpoint privato (se un endpoint privato non è configurato per questa risorsa).
Errori 503 durante l'invio di query con Azure AI Search
Ogni messaggio utente può tradurre in più query di ricerca, tutte inviate alla risorsa di ricerca in parallelo. Questo può produrre un comportamento di limitazione quando il numero di repliche di ricerca e partizioni è basso. Il numero massimo di query al secondo che una singola partizione e una singola replica possono supportare potrebbe non essere sufficiente. In questo caso, prendere in considerazione l'aumento delle repliche e delle partizioni o l'aggiunta della logica di sospensione/ripetizione dei tentativi nell'applicazione. Per altre informazioni, vedere la documentazione di Azure AI Search.
Supporto di modelli e disponibilità a livello di area
| Paese | gpt-35-turbo-16k (0613) |
gpt-35-turbo (1106) |
gpt-4-32k (0613) |
gpt-4 (1106-preview) |
gpt-4 (0125-preview) |
gpt-4 (0613) |
gpt-4o** |
gpt-4 (turbo-2024-04-09) |
|---|---|---|---|---|---|---|---|---|
| Australia orientale | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Canada orientale | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Stati Uniti orientali | ✅ | ✅ | ✅ | |||||
| Stati Uniti orientali 2 | ✅ | ✅ | ✅ | ✅ | ||||
| Francia centrale | ✅ | ✅ | ✅ | ✅ | ✅ | |||
| Giappone orientale | ✅ | |||||||
| Stati Uniti centro-settentrionali | ✅ | ✅ | ✅ | |||||
| Norvegia orientale | ✅ | ✅ | ||||||
| Stati Uniti centro-meridionali | ✅ | ✅ | ||||||
| India meridionale | ✅ | ✅ | ||||||
| Svezia centrale | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Svizzera settentrionale | ✅ | ✅ | ✅ | |||||
| Regno Unito meridionale | ✅ | ✅ | ✅ | ✅ | ||||
| Stati Uniti occidentali | ✅ | ✅ | ✅ |
**Si tratta di un'implementazione di sola testo
Se la risorsa OpenAI di Azure si trova in un'altra area, non sarà possibile usare Azure OpenAI On Your Data.