Analisi e inserimento in Microsoft Purview
Questo articolo offre una panoramica delle funzionalità di analisi e inserimento in Microsoft Purview. Queste funzionalità connettono l'account Microsoft Purview alle origini per popolare la mappa dati e Unified Catalog in modo da poter iniziare a esplorare e gestire i dati tramite Microsoft Purview.
- L'analisi acquisisce i metadati dalle origini dati e li porta in Microsoft Purview.
-
L'inserimento elabora i metadati e lo archivia in Unified Catalog da entrambi:
- Analisi dell'origine dati: i metadati analizzati vengono aggiunti alla Microsoft Purview Data Map.
- Connessioni di derivazione: le risorse di trasformazione aggiungono metadati relativi a origini, output e attività all'Microsoft Purview Data Map.
Analisi
Dopo la registrazione delle origini dati nell'account Microsoft Purview, il passaggio successivo consiste nell'analizzare le origini dati. Il processo di analisi stabilisce una connessione all'origine dati e acquisisce metadati tecnici come nomi, dimensioni del file, colonne e così via. Estrae anche lo schema per le origini dati strutturate, applica le classificazioni agli schemi e applica le etichette di riservatezza se il Microsoft Purview Data Map è connesso a un Portale di conformità di Microsoft Purview. Il processo di analisi può essere attivato per l'esecuzione immediata o può essere pianificato per l'esecuzione periodica per mantenere aggiornato l'account Microsoft Purview.
Per ogni analisi sono disponibili personalizzazioni che è possibile applicare in modo da analizzare solo le informazioni necessarie anziché l'intera origine.
Scegliere un metodo di autenticazione per le analisi
Microsoft Purview è sicuro per impostazione predefinita. Non vengono archiviate password o segreti direttamente in Microsoft Purview, quindi è necessario scegliere un metodo di autenticazione per le origini. Esistono diversi modi possibili per autenticare l'account Microsoft Purview, ma non tutti i metodi sono supportati per ogni origine dati.
- Identità gestita
- Entità servizio
- Autenticazione SQL
- Autenticazione di Windows
- RRN del ruolo
- Autenticazione delegata
- Chiave consumer
- Chiave dell'account o autenticazione di base
Quando possibile, un'identità gestita è il metodo di autenticazione preferito perché elimina la necessità di archiviare e gestire le credenziali per le singole origini dati. Ciò può ridurre notevolmente il tempo che l'utente e il team dedicano alla configurazione e alla risoluzione dei problemi di autenticazione per le analisi. Quando si abilita un'identità gestita per l'account Microsoft Purview, un'identità viene creata in Microsoft Entra ID ed è associata al ciclo di vita dell'account.
Definire l'ambito dell'analisi
Quando si esegue l'analisi di un'origine, è possibile scegliere di analizzare l'intera origine dati o di scegliere solo entità specifiche (cartelle/tabelle) da analizzare. Le opzioni disponibili dipendono dall'origine che si sta analizzando e possono essere definite sia per le analisi una tantum che per le analisi pianificate.
Ad esempio, quando si crea ed esegue un'analisi per un database Azure SQL, è possibile scegliere le tabelle da analizzare o selezionare l'intero database.
Per ogni entità (cartella/tabella), ci saranno tre stati di selezione: completamente selezionati, parzialmente selezionati e non selezionati. Nell'esempio seguente, se si seleziona "Department 1" nella gerarchia di cartelle, "Department 1" viene considerato come completamente selezionato. Le entità padre per "Department 1" come "Company" e "example" vengono considerate parzialmente selezionate in quanto sono presenti altre entità nello stesso elemento padre che non sono state selezionate, ad esempio "Department 2". Nell'interfaccia utente verranno usate icone diverse per le entità con stati di selezione diversi.
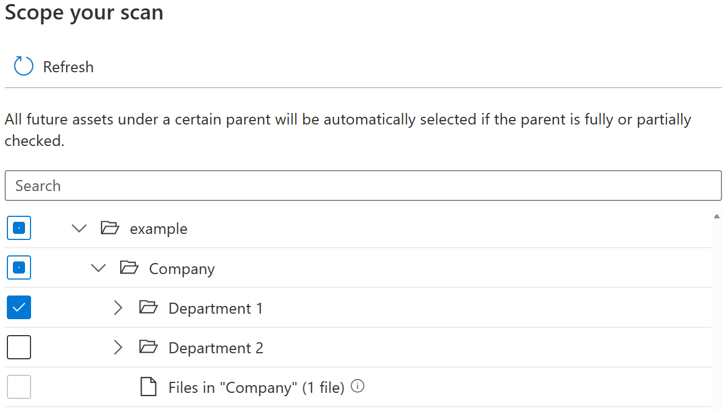
Dopo aver eseguito l'analisi, è probabile che nel sistema di origine vengano aggiunti nuovi asset. Per impostazione predefinita, gli asset futuri in un determinato elemento padre verranno selezionati automaticamente se l'elemento padre è completamente o parzialmente selezionato quando si esegue di nuovo l'analisi. Nell'esempio precedente, dopo aver selezionato "Department 1" ed eseguito l'analisi, tutti i nuovi asset nella cartella "Department 1" o in "Company" e "example" verranno inclusi quando si esegue di nuovo l'analisi.
Viene introdotto un pulsante di attivazione/disattivazione per consentire agli utenti di controllare l'inclusione automatica per i nuovi asset nell'elemento padre parzialmente selezionato. Per impostazione predefinita, l'interruttore verrà disattivato e il comportamento di inclusione automatica per l'elemento padre parzialmente selezionato è disabilitato. Nello stesso esempio con l'interruttore disattivato, tutti i nuovi asset in elementi padre parzialmente selezionati come "Società" e "esempio" non verranno inclusi quando si esegue di nuovo l'analisi, solo i nuovi asset in "Reparto 1" verranno inclusi nell'analisi futura.
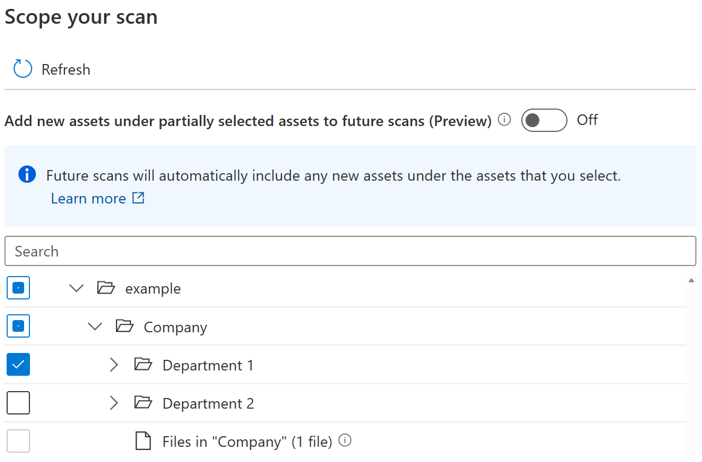
Se l'interruttore è attivato, i nuovi asset in un determinato elemento padre verranno selezionati automaticamente se l'elemento padre è completamente o parzialmente selezionato quando si esegue di nuovo l'analisi. Il comportamento di inclusione è lo stesso di prima dell'introduzione dell'interruttore.
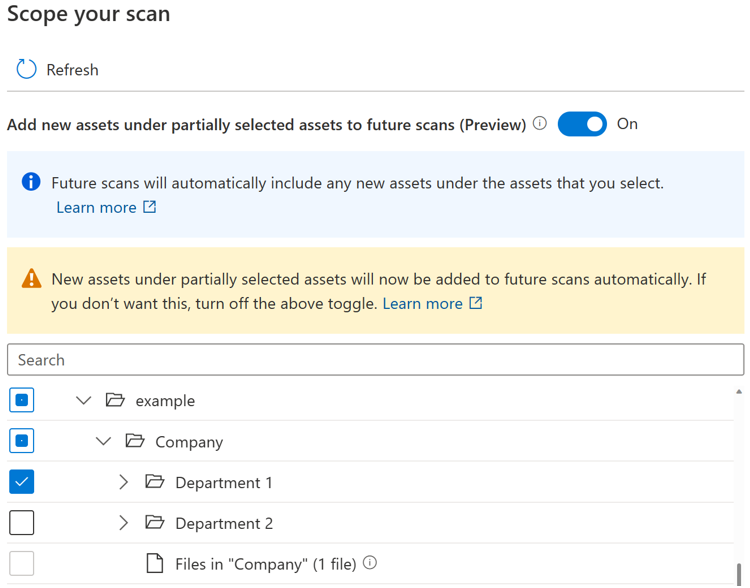
Nota
- La disponibilità dell'interruttore dipende dal tipo di origine dati. Attualmente è disponibile in anteprima pubblica per le origini, tra cui Archiviazione BLOB di Azure, Azure Data Lake Storage Gen 1, Azure Data Lake Storage Gen 2, File di Azure e il pool SQL dedicato di Azure (in precedenza SQL DW).
- Per le analisi create o pianificate prima dell'introduzione dell'interruttore, lo stato di attivazione/disattivazione è impostato su attivato e non può essere modificato. Per le analisi create o pianificate dopo l'introduzione dell'interruttore, lo stato di attivazione/disattivazione non può essere modificato dopo il salvataggio dell'analisi. È necessario creare una nuova analisi per modificare lo stato di attivazione/disattivazione.
- Quando l'interruttore è disattivato, per le origini di tipo di archiviazione come Azure Data Lake Storage Gen 2, possono essere richieste fino a 4 ore prima che l'esperienza di esplorazione per tipo di origine diventi completamente disponibile al termine del processo di analisi.
Limitazioni note
Quando l'interruttore è disattivato:
- Le entità file in un elemento padre parzialmente selezionato non verranno analizzate.
- Se tutte le entità esistenti in un elemento padre sono selezionate in modo esplicito, l'elemento padre viene considerato completamente selezionato e tutti i nuovi asset nell'elemento padre verranno inclusi quando si esegue di nuovo l'analisi.
Personalizzare il livello di analisi
Nella terminologia Microsoft Purview Data Map esistono tre diversi livelli di analisi in base all'ambito dei metadati e alle funzionalità:
- Analisi L1: estrae informazioni di base e metadati come nome file, dimensioni e nome completo
- Analisi L2: estrae lo schema per i tipi di file strutturati e le tabelle di database
- Analisi L3: estrae lo schema dove applicabile e sottopone il file campionato alle regole di classificazione del sistema e personalizzate
Quando si configura una nuova analisi o si modifica un'analisi esistente, è possibile personalizzare il livello di analisi per l'analisi delle origini dati che hanno già supportato la configurazione del livello di analisi.
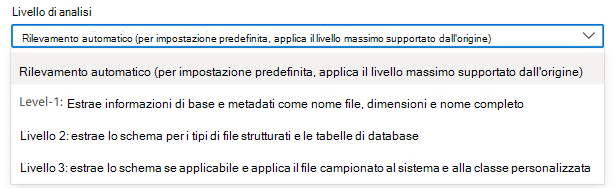
Per impostazione predefinita, verrà selezionato il "Rilevamento automatico", il che significa che Microsoft Purview applicherà il livello di analisi più alto disponibile per questa origine dati. Prendere Azure SQL database come esempio, il "rilevamento automatico" verrà risolto come "Livello 3" quando l'analisi viene eseguita perché l'origine dati ha già supportato la classificazione in Microsoft Purview. Il livello di analisi nel dettaglio dell'esecuzione dell'analisi mostra il livello effettivo applicato.
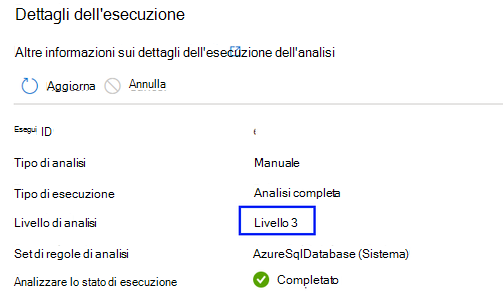
Per tutte le esecuzioni di analisi nella cronologia di analisi completate prima di personalizzare il livello di analisi come nuova funzionalità, per impostazione predefinita il livello di analisi verrà impostato e visualizzato come "Rilevamento automatico".
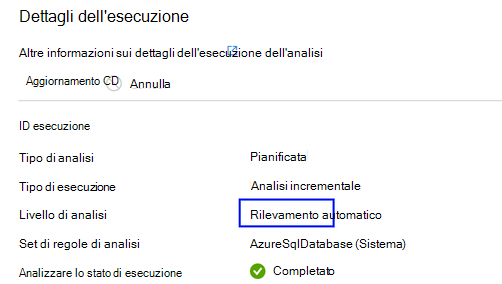
- Quando un livello di analisi superiore diventa disponibile per un'origine dati, le analisi salvate o pianificate con livello di analisi impostato su "Rilevamento automatico" applicano automaticamente il nuovo livello di analisi. Ad esempio, se la classificazione come nuova funzionalità è abilitata per una determinata origine dati, tutte le analisi esistenti in questa origine dati applicano automaticamente la classificazione.
- L'impostazione del livello di analisi viene visualizzata nell'interfaccia di monitoraggio dell'analisi per ogni esecuzione dell'analisi.
- Se si seleziona "Livello 1", l'analisi restituirà solo metadati tecnici di base come il nome dell'asset, le dimensioni dell'asset, il timestamp modificato e così via in base alla disponibilità di metadati esistente di un'origine dati specifica. Per Azure SQL database, le entità asset come le tabelle verranno create in Microsoft Purview Data Map ma senza estrazione dello schema di tabella. Nota: gli utenti possono comunque visualizzare lo schema della tabella tramite visualizzazione dinamica se dispongono delle autorizzazioni necessarie nel sistema di origine.
- Se si seleziona "Livello 2", l'analisi restituirà schemi di tabella e metadati tecnici di base, ma il campionamento e la classificazione dei dati non verranno eseguiti. Per Azure SQL database, le entità asset di tabella hanno lo schema di tabella acquisito senza informazioni di classificazione.
- Se si seleziona "Livello 3", l'analisi eseguirà il campionamento e la classificazione dei dati. Si tratta di una configurazione standard per Azure SQL'analisi del database prima dell'introduzione di una nuova funzionalità.
- Se un'analisi pianificata è impostata su un livello di analisi inferiore e successivamente modificata a un livello di analisi superiore, l'esecuzione dell'analisi successiva eseguirà automaticamente un'analisi completa e tutti gli asset di dati esistenti dall'origine dati verranno aggiornati con i metadati introdotti da un'impostazione di livello di analisi superiore. Ad esempio, quando un'analisi pianificata impostata con "Livello 2" in un database Azure SQL viene modificata in "Livello 3", l'esecuzione dell'analisi successiva sarà un'analisi completa e tutti gli asset di tabella/vista del database Azure SQL esistenti verranno aggiornati con le informazioni di classificazione e tutte le analisi riprenderanno successivamente come analisi incrementali impostate con "Livello 3".
- Se un'analisi pianificata è impostata su un livello di analisi superiore e successivamente modificata a un livello di analisi inferiore, l'esecuzione dell'analisi successiva continuerà a eseguire un'analisi incrementale e tutti i nuovi asset di dati dall'origine dati avranno solo metadati introdotti da un'impostazione di livello di analisi inferiore. Ad esempio, quando un'analisi pianificata impostata con "Livello 3" in un database Azure SQL viene modificata in "Livello 2", l'esecuzione dell'analisi successiva sarà un'analisi incrementale e tutti i nuovi asset di tabella/vista del database Azure SQL aggiunti in Microsoft Purview Data Map non avranno informazioni di classificazione. Tutti gli asset di dati esistenti mantengono comunque le informazioni di classificazione generate dal set di analisi precedente con "Livello 3".
Nota
- La personalizzazione del livello di analisi è attualmente disponibile per le origini dati seguenti: Azure SQL Database, Istanza gestita di SQL di Azure, Azure Cosmos DB per NoSQL, Database di Azure per PostgreSQL, Database di Azure per MySQL, Azure Data Lake Storage Gen2, Archiviazione BLOB di Azure, File di Azure, Azure Synapse Analytics, pool SQL dedicato di Azure (in precedenza SQL DW), Azure Esplora dati, Dataverse, Azure Multiple (sottoscrizione di Azure), Azure Multiple (Gruppo di risorse di Azure), Snowflake, Azure Databricks Unity Catalog
- Attualmente la funzionalità è disponibile solo nel runtime di integrazione di Azure e nel runtime di integrazione della rete virtuale gestita v2.
Set di regole di analisi
Un set di regole di analisi determina i tipi di informazioni che un'analisi cerca quando viene eseguita su una delle origini. Le regole disponibili dipendono dal tipo di origine che si sta analizzando, ma includono elementi come i tipi di file da analizzare e i tipi di classificazioni necessari.
Sono già disponibili set di regole di analisi di sistema per molti tipi di origine dati, ma è anche possibile creare set di regole di analisi personalizzati per personalizzare le analisi per l'organizzazione.
Pianificare l'analisi
Microsoft Purview offre la possibilità di eseguire l'analisi giornaliera, settimanale o mensile in un momento specifico scelto. Altre informazioni sulle opzioni di pianificazione supportate. Le analisi giornaliere o settimanali potrebbero essere appropriate per le origini dati con strutture attivamente in fase di sviluppo o di frequente modifica. L'analisi mensile è più appropriata per le origini dati che cambiano raramente. La procedura consigliata consiste nell'collaborare con l'amministratore dell'origine da analizzare per identificare un momento in cui le richieste di calcolo nell'origine sono basse.
Come le analisi rilevano gli asset eliminati
Un catalogo Microsoft Purview è a conoscenza dello stato di un archivio dati solo quando esegue un'analisi. Affinché il catalogo sappia se un file, una tabella o un contenitore è stato eliminato, confronta l'output dell'ultima analisi con l'output dell'analisi corrente. Si supponga, ad esempio, che l'ultima volta che è stato analizzato un account Azure Data Lake Storage Gen2 includa una cartella denominata folder1. Quando lo stesso account viene analizzato di nuovo, folder1 è mancante. Pertanto, il catalogo presuppone che la cartella sia stata eliminata.
Consiglio
A causa del modo in cui vengono rilevati i file eliminati, potrebbero essere necessarie più analisi riuscite per rilevare e risolvere gli asset eliminati. Se Unified Catalog non registra le eliminazioni per un'analisi con ambito, provare più analisi complete per risolvere il problema.
Rilevamento dei file eliminati
La logica per il rilevamento dei file mancanti funziona per più analisi da parte dello stesso utente e di utenti diversi. Si supponga, ad esempio, che un utente eseta un'analisi una tantum in un archivio dati Data Lake Storage Gen2 nelle cartelle A, B e C. In seguito, un utente diverso nello stesso account esegue un'analisi unica diversa nelle cartelle C, D ed E dello stesso archivio dati. Poiché la cartella C è stata analizzata due volte, il catalogo verifica la presenza di possibili eliminazioni. Le cartelle A, B, D ed E, tuttavia, sono state analizzate una sola volta e il catalogo non li controlla per gli asset eliminati.
Per mantenere i file eliminati fuori dal catalogo, è importante eseguire analisi regolari. L'intervallo di analisi è importante perché il catalogo non è in grado di rilevare gli asset eliminati finché non viene eseguita un'altra analisi. Pertanto, se si eseguono analisi una volta al mese in un determinato archivio, il catalogo non può rilevare gli asset di dati eliminati in tale archivio fino a quando non si esegue l'analisi successiva un mese dopo.
Quando si enumerano archivi dati di grandi dimensioni come Data Lake Storage Gen2, esistono diversi modi ,inclusi gli errori di enumerazione e gli eventi eliminati, per non ottenere informazioni. Un'analisi specifica potrebbe non riuscire a creare o eliminare un file. Pertanto, a meno che il catalogo non sia certo che un file sia stato eliminato, non lo eliminerà dal catalogo. Questa strategia significa che possono verificarsi errori quando nel catalogo esiste ancora un file che non esiste nell'archivio dati analizzato. In alcuni casi, un archivio dati potrebbe dover essere analizzato due o tre volte prima di intercettare determinati asset eliminati.
Nota
- Gli asset contrassegnati per l'eliminazione vengono eliminati dopo un'analisi riuscita. Gli asset eliminati potrebbero continuare a essere visibili nel catalogo per qualche tempo prima che vengano elaborati e rimossi.
- Il rilevamento dell'eliminazione è supportato solo per queste origini all'interno di Microsoft Purview: aree di lavoro di Azure Synapse Analytics, SQL Server abilitate per Azure Arc, Archiviazione BLOB di Azure, File di Azure, Azure Cosmos DB, Esplora dati di Azure, Database di Azure per MySQL, Database di Azure per PostgreSQL, pool SQL dedicato di Azure, Azure Machine Learning, database Azure SQL e Azure SQL istanza gestita. Per queste origini, quando un asset viene eliminato dall'origine dati, le analisi successive rimuoveranno automaticamente i metadati e la derivazione corrispondenti in Microsoft Purview.
Ingestione
L'inserimento è il processo responsabile del popolamento della mappa dati con i metadati raccolti tramite i vari processi.
Inserimento da scansioni
I metadati tecnici o le classificazioni identificate dal processo di analisi vengono quindi inviati all'inserimento. L'inserimento analizza l'input dall'analisi, applica modelli di set di risorse, popola le informazioni di derivazione disponibili e quindi carica automaticamente la mappa dati. Gli asset/schemi possono essere individuati o curati solo dopo il completamento dell'inserimento. Pertanto, se l'analisi è stata completata ma non sono stati visualizzati gli asset nella mappa dati o nel catalogo, è necessario attendere il completamento del processo di inserimento.
Inserimento da connessioni di derivazione
Risorse come Azure Data Factory e Azure Synapse possono essere connesse a Microsoft Purview per trasferire le informazioni sull'origine dati e sulla derivazione nel Microsoft Purview Data Map. Ad esempio, quando una pipeline di copia viene eseguita in un Azure Data Factory connesso a Microsoft Purview, i metadati relativi alle origini di input, all'attività e alle origini di output vengono inseriti in Microsoft Purview e le informazioni vengono aggiunte alla mappa dati.
Se un'origine dati è già stata aggiunta al mapping dei dati tramite un'analisi, le informazioni di derivazione sull'attività verranno aggiunte all'origine esistente. Se l'origine dati non è ancora stata aggiunta alla mappa dati, il processo di inserimento della derivazione lo aggiunge alla raccolta radice con le relative informazioni di derivazione.
Per altre informazioni sulle connessioni di derivazione disponibili, vedere la guida per l'utente di derivazione.
Passaggi successivi
Per altre informazioni o per istruzioni specifiche per l'analisi delle origini, seguire i collegamenti seguenti.
- Per informazioni sui set di risorse, vedere l'articolo sui set di risorse.
- Come gestire un database Azure SQL
- Derivazione in Microsoft Purview