connettori Azure SQL e Microsoft SQL Server Microsoft Graph
I connettori Microsoft SQL Server o Azure SQL Microsoft Graph consentono all'organizzazione di individuare e indicizzare i dati da un database SQL Server locale o da un database ospitato nell'istanza di Azure SQL nel cloud. Il connettore indicizza il contenuto specificato in Microsoft Search e Microsoft 365 Copilot. Per mantenere aggiornato l'indice con i dati di origine, supporta ricerche per indicizzazione periodiche complete e incrementali. Con questi connettori SQL, è anche possibile limitare l'accesso ai risultati della ricerca per determinati utenti.
Questo articolo è destinato agli amministratori di Microsoft 365 o a chiunque configura, esegue e monitora un Azure SQL o un connettore Microsoft SQL Server Microsoft Graph.
Funzionalità
- Indicizzare i record dal server MS SQL o Azure SQL database usando una query SQL.
- Specificare le autorizzazioni di accesso per ogni record con l'elenco di utenti o gruppi aggiunti nella query SQL.
- Abilitare gli utenti finali per porre domande relative ai record indicizzati in Copilot.
- Usare la ricerca semantica in Copilot per consentire agli utenti di trovare contenuti pertinenti in base a parole chiave, preferenze personali e connessioni di social networking.
Limitazioni
- Connettore Microsoft SQL Server: il database locale deve essere eseguito SQL Server versione 2008 o successiva.
- connettore Azure SQL: la sottoscrizione di Microsoft 365 e la sottoscrizione di Azure (che ospitano Azure SQL database) devono trovarsi all'interno dello stesso Microsoft Entra ID. Il flusso di dati tra tenant non è supportato.
- Per supportare una velocità di ricerca per indicizzazione elevata e prestazioni migliori, il connettore è progettato per supportare solo carichi di lavoro OLTP (Online Transaction Processing). Carichi di lavoro OLAP (Online Analytical Processing) che non eseguono la query SQL fornita nel timeout di 40 secondi e non sono supportati.
- Gli elenchi di controllo di accesso sono supportati solo tramite un nome dell'entità utente (UPN), Microsoft Entra ID o sicurezza di Active Directory.
- L'indicizzazione di contenuto avanzato all'interno di colonne di database non è supportata. Esempi di tali contenuti sono HTML, JSON, XML, BLOB e analisi di documenti esistenti come collegamenti all'interno delle colonne del database.
Prerequisiti
- È necessario essere l'amministratore della ricerca per il tenant di Microsoft 365 dell'organizzazione.
- Installare l'agente connettore Microsoft Graph (applicabile solo per il connettore MS SQL): per accedere a Microsoft SQL Server, è necessario installare e configurare l'agente connettore. Per altre informazioni, vedere Installare l'agente connettore Microsoft Graph .
- Account del servizio: per connettersi al database SQL e consentire a Microsoft Graph Connector di aggiornare regolarmente i record, è necessario un account del servizio con autorizzazioni di lettura concesse all'account del servizio.
Nota
Se si usa autenticazione di Windows durante la configurazione del connettore microsoft SQL Server, l'utente con cui si sta tentando di accedere deve disporre di diritti di accesso interattivi al computer in cui è installato l'agente del connettore. Per altre informazioni, vedere Gestione dei criteri di accesso.
Introduzione all'installazione
1. Nome visualizzato
Un nome visualizzato viene usato per identificare ogni citazione in Copilot, consentendo agli utenti di riconoscere facilmente il file o l'elemento associato. Il nome visualizzato indica anche contenuto attendibile. Il nome visualizzato viene usato anche come filtro dell'origine di contenuto. Per questo campo è presente un valore predefinito, ma è possibile personalizzarlo in base a un nome riconosciuto agli utenti dell'organizzazione.
server 2. SQL
Per connettersi ai dati SQL, sono necessari l'indirizzo e il nome del database di SQL Server.
3. Tipo di autenticazione
Azure SQL connettore supporta solo Microsoft Entra ID autenticazione OIDC (OpenID Connect) per connettersi al database.
Registrare un'app (solo per Azure SQL connettore Microsoft Graph)
Per Azure SQL connettore, è necessario registrare un'app in Microsoft Entra ID per consentire all'app Microsoft Search e Microsoft 365 Copilot di accedere ai dati per l'indicizzazione. Per altre informazioni sulla registrazione di un'app, vedere la documentazione di Microsoft Graph su come registrare un'app.
Dopo aver completato la registrazione dell'app e aver preso nota del nome dell'app, dell'ID applicazione (client) e dell'ID tenant, è necessario generare un nuovo segreto client. Il client viene visualizzato una sola volta. Tenere presente & archiviare il segreto client in modo sicuro. Usare l'ID client e il segreto client durante la configurazione di una nuova connessione in Microsoft Search e Microsoft 365 Copilot.
Per aggiungere l'app registrata al database Azure SQL, è necessario:
- Accedere al database Azure SQL.
- Aprire una nuova finestra di query.
- Creare un nuovo utente eseguendo il comando 'CREATE USER [nome app] FROM EXTERNAL PROVIDER'.
- Aggiungere l'utente al ruolo eseguendo il comando 'exec sp_addrolemember 'db_datareader', [nome app]' o 'ALTER ROLE db_datareader ADD MEMBER [nome app]'.
Per altre informazioni sulla revoca dell'accesso a qualsiasi app registrata in Microsoft Entra ID, vedere Rimozione di un'app registrata.
Impostazioni del firewall (solo per Azure SQL connettore Microsoft Graph)
Per una maggiore sicurezza, è possibile configurare le regole del firewall IP per il server o il database Azure SQL. Per altre informazioni sulla configurazione delle regole del firewall IP, vedere la documentazione sulle regole del firewall IP. Aggiungere gli intervalli IP client seguenti nelle impostazioni del firewall.
| Area geografica | Microsoft 365 Enterprise | Microsoft 365 Per enti pubblici |
|---|---|---|
| NAM | 52.250.92.252/30, 52.224.250.216/30 | 52.245.230.216/30, 20.141.117.64/30 |
| EUR | 20.54.41.208/30, 51.105.159.88/30 | ND |
| APC | 52.139.188.212/30, 20.43.146.44/30 | ND |
4. Distribuire a un pubblico limitato
Distribuire questa connessione a una base di utenti limitata se si vuole convalidarla in Copilot e in altre aree di ricerca prima di espandere l'implementazione a un pubblico più ampio. Per altre informazioni sull'implementazione limitata, fare clic qui.
Contenuto
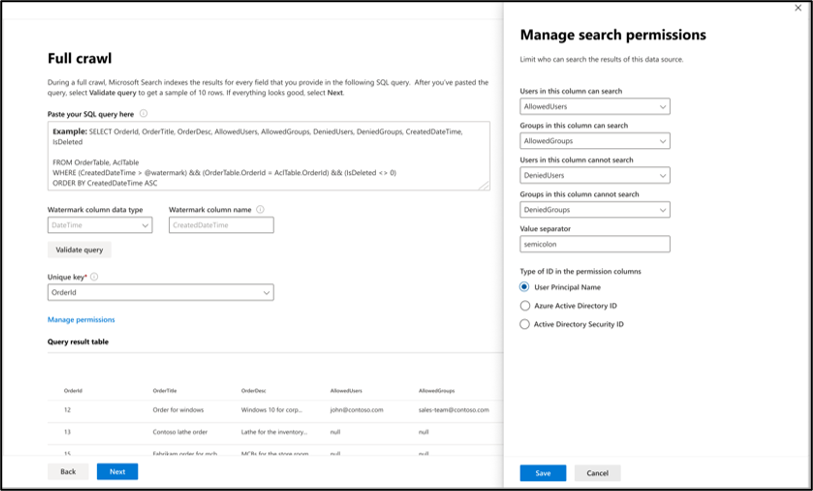
Per eseguire ricerche nel contenuto del database, è necessario specificare query SQL quando si configura il connettore. Queste query SQL devono denominare tutte le colonne di database da indicizzare (proprietà di origine). Sono inclusi tutti i join SQL che devono essere eseguiti per ottenere tutte le colonne. Per limitare l'accesso ai risultati della ricerca, è necessario specificare Controllo di accesso Elenchi (ACL) nelle query SQL quando si configura il connettore.
1. Ricerca per indicizzazione completa (obbligatorio)
a.
Selezionare colonne di dati (obbligatorio) e colonne ACL (facoltativo)
[Fare clic per espandere] Selezione delle colonne di dati per la query di ricerca per indicizzazione completa.
In questo passaggio viene configurata la query SQL che esegue una ricerca per indicizzazione completa del database. La ricerca per indicizzazione completa seleziona tutte le colonne o le proprietà che devono essere presentate in Microsoft Copilot o Ricerca. È anche possibile specificare colonne ACL per limitare l'accesso ai risultati della ricerca a utenti o gruppi specifici.
Consiglio
Per ottenere tutte le colonne necessarie, è possibile unire più tabelle.

Nell'esempio viene illustrata una selezione di cinque colonne di dati che contengono i dati per la ricerca: OrderId, OrderTitle, OrderDesc, CreatedDateTime e IsDeleted. Per impostare le autorizzazioni di visualizzazione per ogni riga di dati, è possibile selezionare facoltativamente queste colonne ACL: AllowedUsers, AllowedGroups, DeniedUsers e DeniedGroups. Tutte queste colonne di dati hanno anche le opzioni Query, Search, Retrieve o Refine.
Selezionare le colonne di dati come illustrato in questa query di esempio: SELECT orderId, orderTitle, orderDesc, allowedUsers, allowedGroups, deniedUsers, deniedGroups, createdDateTime, isDeleted
I connettori SQL non consentono nomi di colonna con caratteri non alfanumerici nella clausola SELECT. Rimuovere eventuali caratteri non alfanumerici dai nomi di colonna usando un alias. Esempio : SELECT column_name AS columnName
Per gestire l'accesso ai risultati della ricerca, è possibile specificare una o più colonne ACL nella query. Il connettore SQL consente di controllare l'accesso a livello di record. È possibile scegliere di avere lo stesso controllo di accesso per tutti i record in una tabella. Se le informazioni ACL vengono archiviate in una tabella separata, potrebbe essere necessario eseguire un join con tali tabelle nella query.
L'uso di ognuna delle colonne ACL nella query precedente è descritto di seguito. L'elenco seguente illustra i quattro meccanismi di controllo di accesso.
- AllowedUsers: questa colonna specifica l'elenco di ID utente che possono accedere ai risultati della ricerca. Nell'esempio seguente, un elenco di utenti: john@contoso.com, keith@contoso.come lisa@contoso.com avrebbe accesso solo a un record con OrderId = 12.
- AllowedGroups: questa colonna specifica il gruppo di utenti che potranno accedere ai risultati della ricerca. Nell'esempio seguente, il gruppo sales-team@contoso.com avrebbe accesso al record solo con OrderId = 12.
- DeniedUsers: questa colonna specifica l'elenco di utenti che non hanno accesso ai risultati della ricerca. Nell'esempio seguente gli utenti john@contoso.com e keith@contoso.com non hanno accesso al record con OrderId = 13, mentre tutti gli altri utenti hanno accesso a questo record.
- DeniedGroups: questa colonna specifica il gruppo di utenti che non hanno accesso ai risultati della ricerca. Nell'esempio seguente i gruppi engg-team@contoso.com e pm-team@contoso.com non hanno accesso a un record con OrderId = 15, mentre tutti gli altri utenti hanno accesso a questo record.

b.
Tipi di dati supportati
[Fare clic per espandere] Elenco dei tipi di dati supportati.
La tabella riepiloga i tipi di dati SQL supportati nei connettori MS SQL e Azure SQL. La tabella riepiloga anche il tipo di dati di indicizzazione per il tipo di dati SQL supportato. Per altre informazioni sui connettori di Microsoft Graph supportati dai tipi di dati per l'indicizzazione, vedere la documentazione sui tipi di risorse di proprietà.
| Categoria | Tipo di dati di origine | Tipo di dati di indicizzazione |
|---|---|---|
| Data e ora | data datetime datetime2 smalldatetime |
datetime |
| Numerico esatto | bigint int smallint tinyint |
int64 |
| Numerico esatto | pezzo | booleano |
| Numerico approssimativo | galleggiare real |
doppio |
| Stringa di caratteri | Char varchar Testo |
stringa |
| Stringhe di caratteri Unicode | nchar nvarchar ntext |
stringa |
| Raccolta di stringhe | Char varchar Testo |
stringcollection* |
| Altri tipi di dati | uniqueidentifier | stringa |
*Per indicizzare una colonna come StringCollection, è necessario eseguire il cast di una stringa al tipo di raccolta di stringhe. A tale scopo, fare clic sul collegamento "Modifica tipi di dati" in Impostazioni di ricerca per indicizzazione complete e selezionare le colonne appropriate come StringCollection, oltre a specificare un delimitatore per dividere la stringa.
Per qualsiasi altro tipo di dati attualmente non supportato direttamente, è necessario eseguire il cast esplicito della colonna a un tipo di dati supportato.
c.
Filigrana (obbligatorio)
[Fare clic per espandere] Specifica della colonna filigrana nella query di ricerca per indicizzazione completa
Per evitare l'overload del database, il connettore crea un batch e riprende le query con ricerca per indicizzazione completa con una colonna filigrana a ricerca per indicizzazione completa. Usando il valore della colonna filigrana, ogni batch successivo viene recuperato e l'esecuzione di query viene ripresa dall'ultimo checkpoint. Essenzialmente questo meccanismo controlla l'aggiornamento dei dati per le ricerche per indicizzazione complete.
Creare frammenti di query per le filigrane, come illustrato negli esempi seguenti:
-
WHERE (CreatedDateTime > @watermark). Citare il nome della colonna filigrana con la parola chiave@watermarkriservata . Se l'ordinamento della colonna filigrana è crescente, utilizzare>; in caso contrario, utilizzare<. -
ORDER BY CreatedDateTime ASC. Ordinare la colonna filigrana in ordine crescente o decrescente.
Nella configurazione illustrata nell'immagine CreatedDateTime seguente è la colonna filigrana selezionata. Per recuperare il primo batch di righe, specificare il tipo di dati della colonna filigrana. In questo caso, il tipo di dati è DateTime.

La prima query recupera il primo numero N di righe usando: "CreatedDateTime > 1 gennaio 1753 00:00:00" (valore minimo del tipo di dati DateTime). Dopo il recupero del primo batch, il valore più alto di CreatedDateTime restituito nel batch viene salvato come checkpoint se le righe vengono ordinate in ordine crescente. Un esempio è il 1° marzo 2019 03:00:00. Il batch successivo di N righe viene quindi recuperato usando "CreatedDateTime > 1 marzo 2019 03:00:00" nella query.
2. Gestire le proprietà
Il connettore SQL seleziona tutte le colonne specificate nella query SQL per indicizzazione completa come proprietà di origine per l'inserimento. In questo passaggio è possibile definire lo schema di ricerca per il contenuto. Ciò comporta la definizione delle annotazioni di ricerca, ad esempio ricerca, recupero, query e affinamento per le proprietà di origine selezionate. Ciò include anche l'assegnazione di etichette semantiche e alias per migliorare la rilevanza della ricerca. Per altre informazioni sullo schema di ricerca, vedere la documentazione sulle linee guida per "gestire le proprietà".
3. Ricerca per indicizzazione incrementale (facoltativo)
a.
Query di sincronizzazione incrementale
In questo passaggio facoltativo specificare una query SQL per eseguire una ricerca per indicizzazione incrementale del database. Con questa query, il connettore SQL determina eventuali modifiche ai dati dopo l'ultima ricerca per indicizzazione incrementale. Come nella ricerca per indicizzazione completa, selezionare tutte le colonne in cui si desidera selezionare le opzioni Query, Search, Retrieve o Refine. Specificare lo stesso set di colonne ACL specificato nella query di ricerca per indicizzazione completa.
I componenti nell'immagine seguente sono simili ai componenti di ricerca per indicizzazione completi con un'eccezione. In questo caso, "ModifiedDateTime" è la colonna di filigrana selezionata. Esaminare i passaggi completi della ricerca per indicizzazione per informazioni su come scrivere la query di ricerca per indicizzazione incrementale e vedere l'immagine seguente come esempio.

b. Istruzioni per l'eliminazione temporanea (facoltativo)
In un sistema di record SQL, un'eliminazione temporanea è una tecnica in cui, invece di rimuovere fisicamente un record da un database, lo si contrassegna come "eliminato" impostando un flag o una colonna specifica. Questo consente al record di rimanere nel database, ma è logicamente escluso dalla maggior parte delle operazioni. Per eliminare le righe eliminate temporaneamente nel database durante la ricerca per indicizzazione incrementale, specificare il nome e il valore della colonna di eliminazione temporanea che indicano che la riga viene eliminata.

Utenti
È possibile scegliere di usare l'opzione Only people with access to this data source (Solo persone con accesso a questa origine dati ) per limitare l'accesso a utenti o gruppi come selezionato nella query di ricerca per indicizzazione completa oppure è possibile eseguirne l'override per rendere visibile il contenuto a Tutti.
1. Eseguire il mapping di colonne contenenti informazioni sulle autorizzazioni di accesso
Scegliere le varie colonne di controllo di accesso (ACL) che specificano il meccanismo di controllo di accesso. Selezionare il nome di colonna specificato nella query SQL per indicizzazione completa. Si noti che "deny" ha la precedenza sulle autorizzazioni "allow".
Ogni colonna ACL deve essere una colonna multivalore. Questi valori ID multipli possono essere separati da separatori, ad esempio punto e virgola (;), virgola (,) e così via. È necessario specificare questo separatore nel campo separatore di valori .
I tipi di ID seguenti sono supportati per l'uso come ACL:
- Nome entità utente (UPN): un nome dell'entità utente (UPN) è il nome di un utente di sistema in formato indirizzo di posta elettronica. Un UPN (ad esempio: john.doe@domain.com) è costituito dal nome utente (nome di accesso), dal separatore (simbolo @) e dal nome di dominio (suffisso UPN).
- Microsoft Entra ID: in Microsoft Entra ID, ogni utente o gruppo ha un ID oggetto simile a "e0d3ad3d-0000-1111-2222-3c5f5c52ab9b".
- ID di sicurezza di Active Directory (AD): in un'installazione di Active Directory locale, ogni utente e gruppo ha un identificatore di sicurezza univoco non modificabile simile a "S-1-5-21-3878594291-2115959936-132693609-65242".
Sincronizza
L'intervallo di aggiornamento determina la frequenza con cui i dati vengono sincronizzati tra l'origine dati e l'indice del connettore Graph.
È possibile configurare ricerche per indicizzazione complete e incrementali in base alle opzioni di pianificazione disponibili qui. Per impostazione predefinita, la ricerca per indicizzazione incrementale (se configurata) viene impostata per ogni 15 minuti e la ricerca per indicizzazione completa viene impostata per ogni giorno. Se necessario, è possibile modificare queste pianificazioni in base alle esigenze di aggiornamento dei dati.
A questo punto, è possibile creare la connessione per Azure SQL o MS SQL. È possibile fare clic sul pulsante "Crea" per pubblicare i dati di connessione e indice dal database.
Risoluzione dei problemi
Dopo aver pubblicato la connessione, è possibile esaminare lo stato nella scheda Origini datinell'interfaccia di amministrazione. Per informazioni su come eseguire aggiornamenti ed eliminazioni, vedere Gestire il connettore. È possibile trovare i passaggi per la risoluzione dei problemi più comuni qui.
In caso di problemi o se si desidera fornire commenti e suggerimenti, contattare Microsoft Graph | Supporto.