Esercitazione: Inviare dati da un server OPC UA ad Azure Data Lake Storage Gen 2
Nella guida introduttiva è stato creato un flusso di dati che invia dati da Operazioni IoT di Azure a Hub eventi e quindi a Microsoft Fabric tramite EventStreams.
Tuttavia, è anche possibile inviare i dati direttamente a un endpoint di archiviazione senza usare Hub eventi. Questo approccio richiede la creazione di uno schema Delta Lake che rappresenta i dati, il caricamento dello schema nelle operazioni IoT di Azure e la creazione di un flusso di dati che legge i dati dal server OPC UA e lo scrive nell'endpoint di archiviazione.
Questa esercitazione si basa sulla configurazione di avvio rapido e illustra come biforcare i dati in Azure Data Lake Storage Gen 2. Questo approccio consente di archiviare i dati direttamente in un data lake scalabile e sicuro, che può essere usato per ulteriori analisi ed elaborazione.
Prerequisiti
Completare il secondo passaggio dell'avvio rapido che consente di ottenere i dati dal server OPC UA al broker MQTT per le operazioni IoT di Azure. Assicurarsi di visualizzare i dati in Hub eventi.
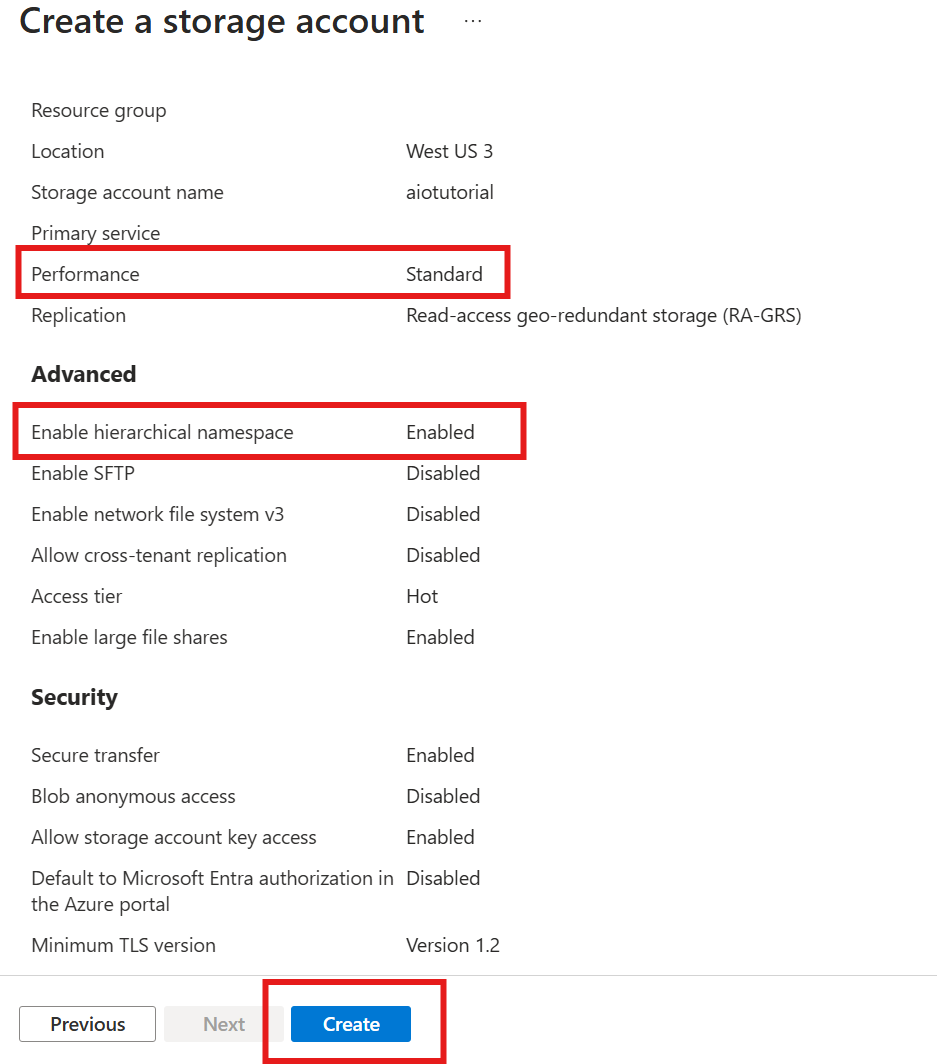
Creare un account di archiviazione con la funzionalità Data Lake Storage
Prima di tutto, seguire la procedura per creare un account di archiviazione con la funzionalità Data Lake Storage Gen 2.
- Scegliere un nome memorabile ma univoco per l'account di archiviazione, perché è necessario nei passaggi successivi.
- Per ottenere risultati ottimali, usare una posizione vicina al cluster Kubernetes in cui è in esecuzione Operazioni IoT di Azure.
- Durante il processo di creazione abilitare l'impostazione Spazio dei nomi gerarchico. Questa impostazione è necessaria per le operazioni IoT di Azure per scrivere nell'account di archiviazione.
- È possibile lasciare le altre impostazioni come predefinite.
Nel passaggio Rivedi verificare le impostazioni e selezionare Crea per creare l'account di archiviazione.
Ottenere il nome dell'estensione di Operazioni IoT di Azure
In portale di Azure trovare l'istanza di Operazioni IoT di Azure creata nella guida introduttiva. Nel pannello Panoramica individuare la sezione Estensione Arc e visualizzare il nome dell'estensione. L'aspetto dovrebbe essere simile a azure-iot-operations-xxxxx.
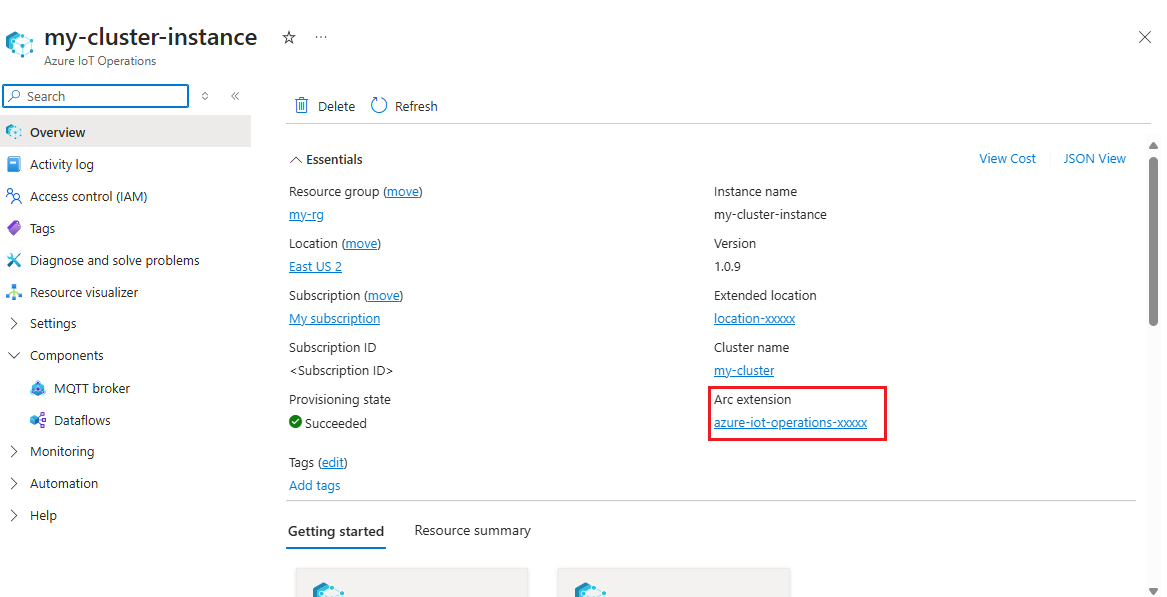
Questo nome di estensione viene usato nei passaggi successivi per assegnare le autorizzazioni all'account di archiviazione.
Assegnare l'autorizzazione alle operazioni IoT di Azure per scrivere nell'account di archiviazione
In primo luogo, nell'account di archiviazione passare al pannello Controllo di accesso (IAM) e selezionare + Aggiungi assegnazione di ruolo. Nel pannello Aggiungi assegnazione di ruolo cercare il ruolo Collaboratore dati BLOB di archiviazione e selezionarlo.
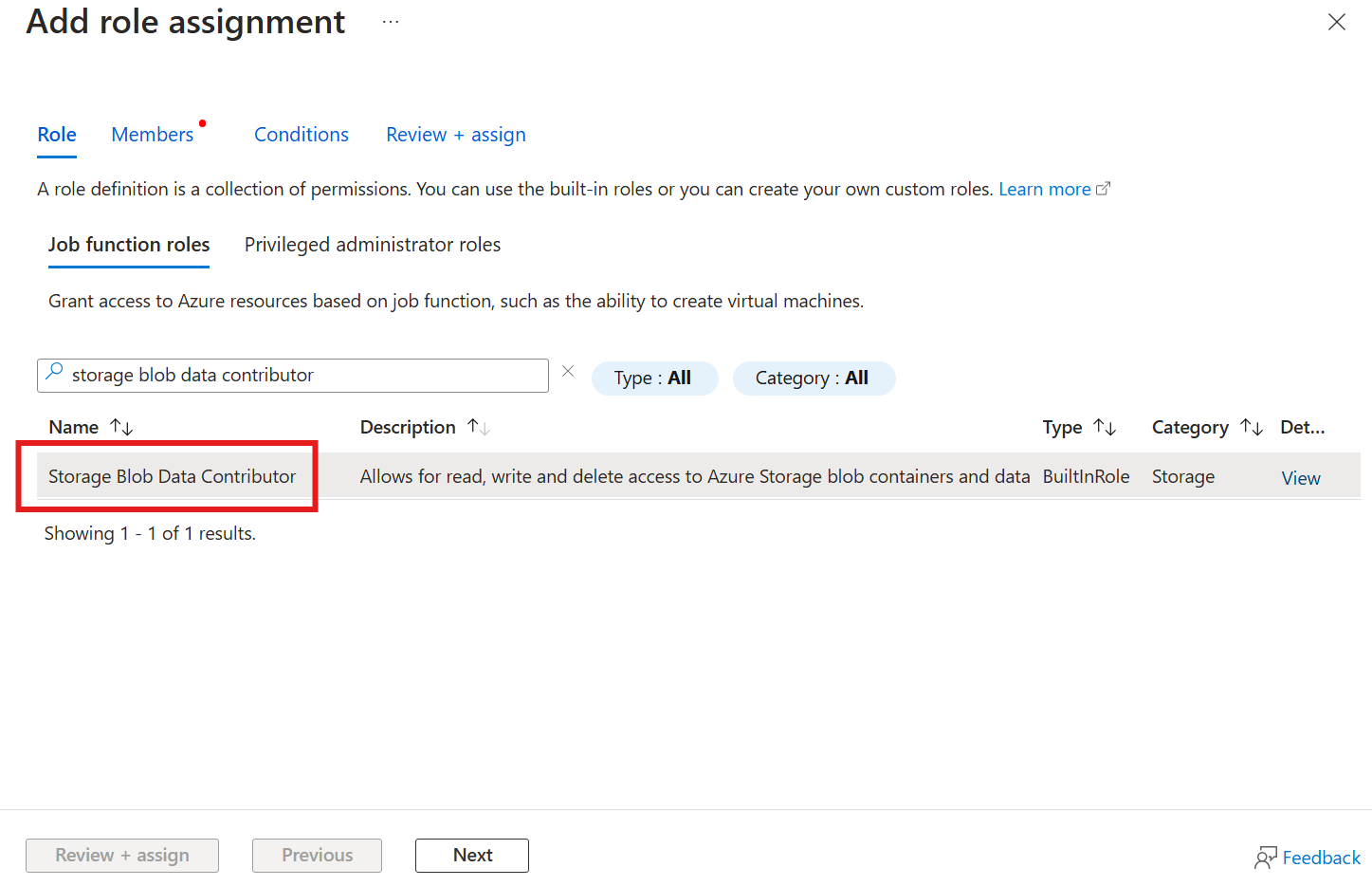
Selezionare quindi Avanti per passare alla sezione Membri .
Scegliere quindi Seleziona membri e nella casella Seleziona cercare l'identità gestita dell'estensione Azure IoT Operations Arc denominata azure-iot-operations-xxxxx e selezionarla.
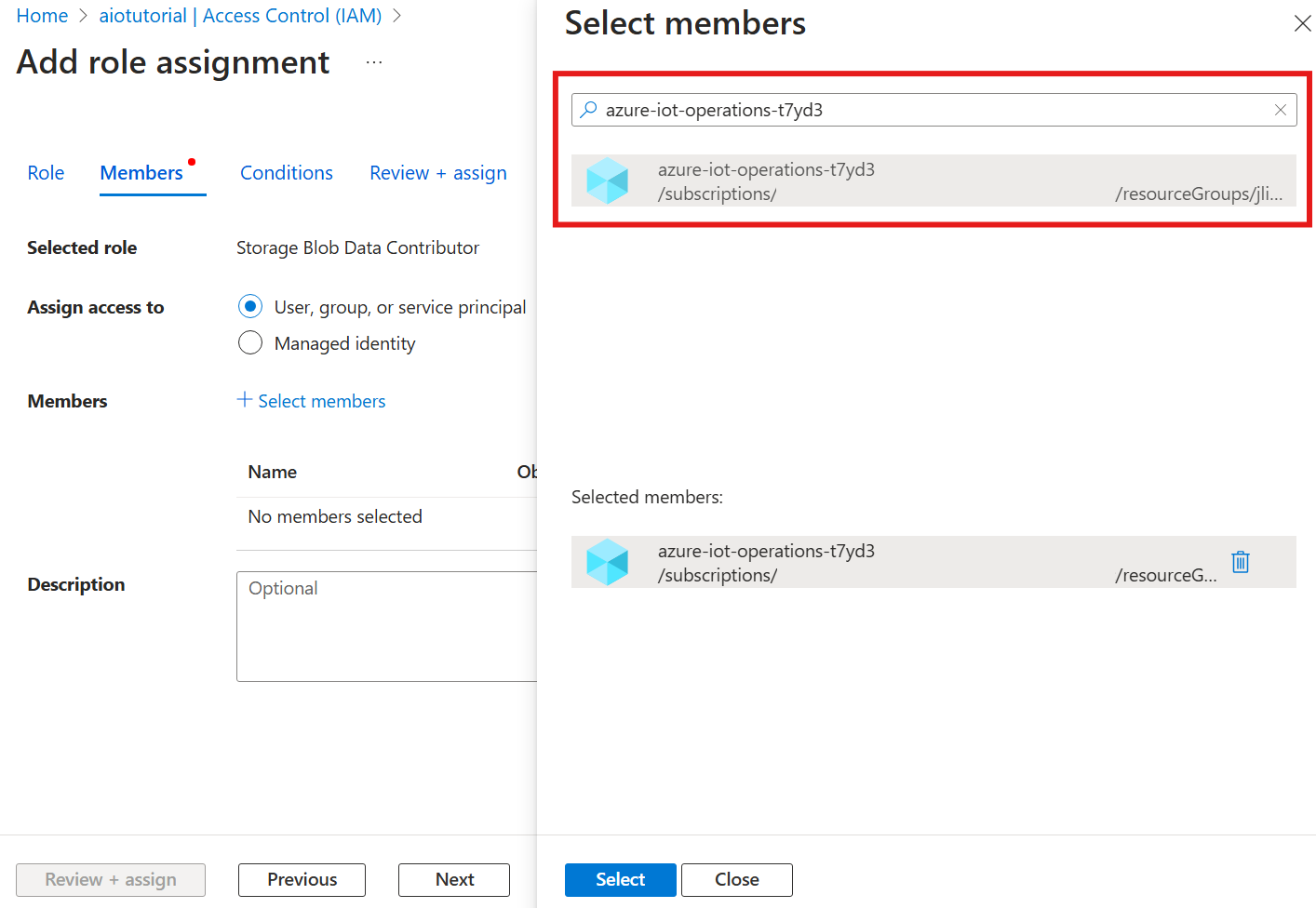
Completare l'assegnazione con Rivedi e assegna.
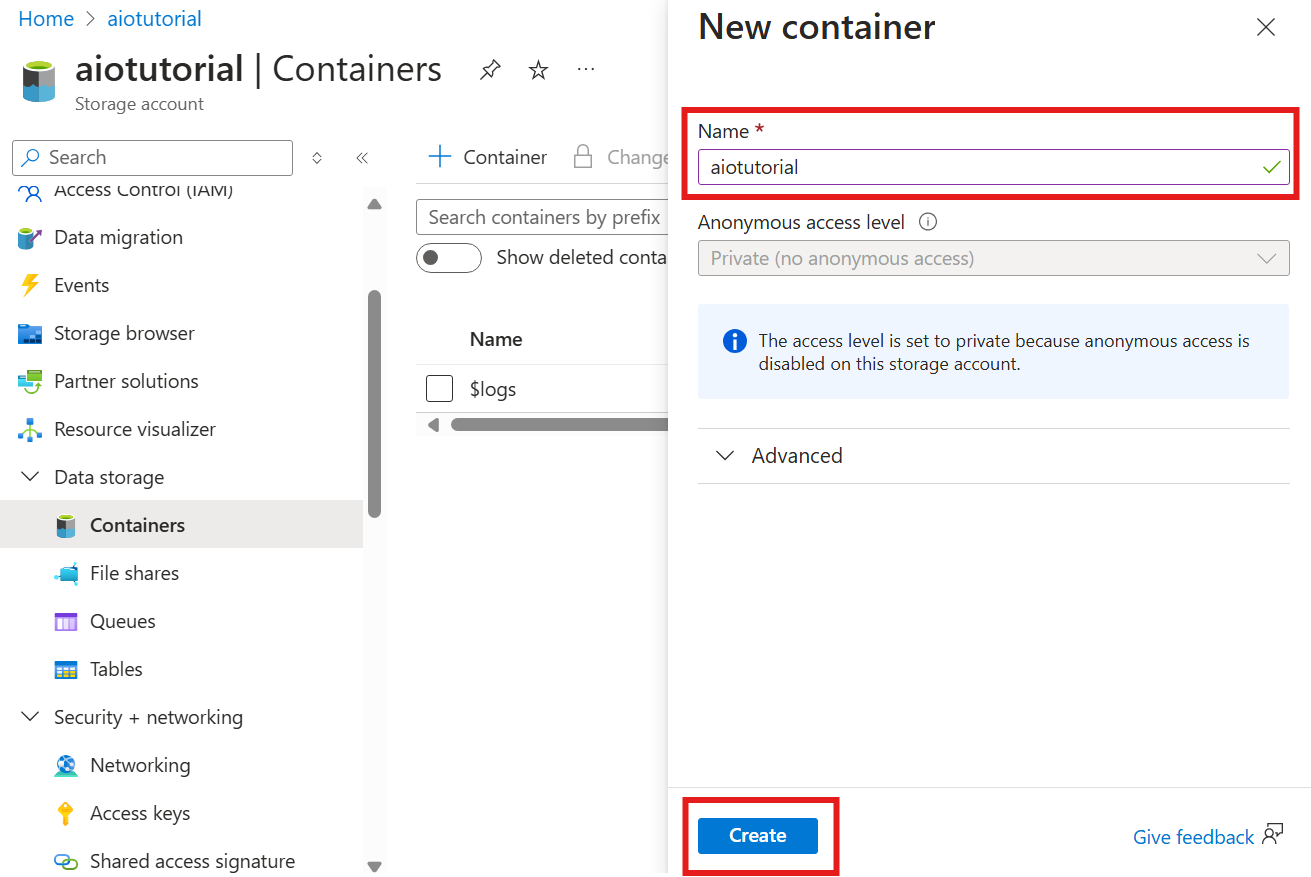
Creare un contenitore nell'account di archiviazione
Nell'account di archiviazione passare al pannello Contenitori e selezionare + Contenitore. Per questa esercitazione assegnare al contenitore aiotutorialil nome . Selezionare Crea per creare il contenitore.
Ottenere il nome e lo spazio dei nomi del Registro di sistema dello schema
Per caricare lo schema in Operazioni IoT di Azure, è necessario conoscere il nome e lo spazio dei nomi del Registro di sistema dello schema. È possibile ottenere queste informazioni usando l'interfaccia della riga di comando di Azure.
Eseguire il comando seguente per ottenere il nome e lo spazio dei nomi del Registro di sistema dello schema. Sostituire i segnaposto con i valori.
az iot ops schema registry list -g <RESOURCE_GROUP> --query "[0].{name: name, namespace: properties.namespace}" -o tsv
L'output dovrebbe essere simile al seguente:
<REGISTRY_NAME> <SCHEMA_NAMESPACE>
Salvare i valori per i passaggi successivi.
Caricare lo schema in Operazioni IoT di Azure
Nell'argomento di avvio rapido i dati provenienti dall'asset forno hanno un aspetto simile al seguente:
{
"Temperature": {
"SourceTimestamp": "2024-11-15T21:40:28.5062427Z",
"Value": 6416
},
"FillWeight": {
"SourceTimestamp": "2024-11-15T21:40:28.5063811Z",
"Value": 6416
},
"EnergyUse": {
"SourceTimestamp": "2024-11-15T21:40:28.506383Z",
"Value": 6416
}
}
Il formato dello schema richiesto per Delta Lake è un oggetto JSON che segue il formato di serializzazione dello schema Delta Lake. Lo schema deve definire la struttura dei dati, inclusi i tipi e le proprietà di ogni campo. Per altri dettagli sul formato dello schema, vedere la documentazione relativa al formato di serializzazione dello schema Delta Lake.
Suggerimento
Per generare lo schema da un file di dati di esempio, usare l'helper di generazione dello schema.
Per questa esercitazione, lo schema per i dati è simile al seguente:
{
"$schema": "Delta/1.0",
"type": "object",
"properties": {
"type": "struct",
"fields": [
{
"name": "Temperature",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
},
{
"name": "FillWeight",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
},
{
"name": "EnergyUse",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
}
]
}
}
Salvarlo come file denominato opcua-schema.json.
Caricare quindi lo schema in Operazioni IoT di Azure usando l'interfaccia della riga di comando di Azure. Sostituire i segnaposto con i valori.
az iot ops schema create -n opcua-schema -g <RESOURCE_GROUP> --registry <REGISTRY_NAME> --format delta --type message --version-content opcua-schema.json --ver 1
In questo modo viene creato uno schema denominato opcua-schema nel Registro di sistema delle operazioni di Azure IoT con la versione 1.
Per verificare che lo schema sia caricato, elencare le versioni dello schema usando l'interfaccia della riga di comando di Azure.
az iot ops schema version list -g <RESOURCE_GROUP> --schema opcua-schema --registry <REGISTRY_NAME>
Creare un endpoint del flusso di dati
L'endpoint del flusso di dati è la destinazione in cui vengono inviati i dati. In questo caso, i dati vengono inviati ad Azure Data Lake Storage Gen 2. Il metodo di autenticazione è l'identità gestita assegnata dal sistema, configurata per avere le autorizzazioni appropriate per la scrittura nell'account di archiviazione.
Creare un endpoint del flusso di dati usando Bicep. Sostituire i segnaposto con i valori.
// Replace with your values
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
// Tutorial specific values
param endpointName string = 'adls-gen2-endpoint'
param host string = 'https://<ACCOUNT>.blob.core.windows.net'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
resource adlsGen2Endpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' = {
parent: aioInstance
name: endpointName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
endpointType: 'DataLakeStorage'
dataLakeStorageSettings: {
host: host
authentication: {
method: 'SystemAssignedManagedIdentity'
systemAssignedManagedIdentitySettings: {}
}
}
}
}
Salvare il file con adls-gen2-endpoint.bicep nome e distribuirlo usando l'interfaccia della riga di comando di Azure
az deployment group create -g <RESOURCE_GROUP> --template-file adls-gen2-endpoint.bicep
Creazione di un flusso di dati
Per inviare dati ad Azure Data Lake Storage Gen 2, è necessario creare un flusso di dati che legge i dati dal server OPC UA e lo scrive nell'account di archiviazione. In questo caso non è necessaria alcuna trasformazione, quindi i dati vengono scritti così come sono.
Creare un flusso di dati usando Bicep. Sostituire i segnaposto con i valori.
// Replace with your values
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
param schemaNamespace string = '<SCHEMA_NAMESPACE>'
// Tutorial specific values
param schema string = 'opcua-schema'
param schemaVersion string = '1'
param dataflowName string = 'tutorial-adls-gen2'
param assetName string = 'oven'
param endpointName string = 'adls-gen2-endpoint'
param containerName string = 'aiotutorial'
param serialFormat string = 'Delta'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
// Pointer to the default dataflow profile
resource defaultDataflowProfile 'Microsoft.IoTOperations/instances/dataflowProfiles@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource adlsEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: endpointName
}
resource defaultDataflowEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource asset 'Microsoft.DeviceRegistry/assets@2024-11-01' existing = {
name: assetName
}
resource dataflow 'Microsoft.IoTOperations/instances/dataflowProfiles/dataflows@2024-11-01' = {
// Reference to the parent dataflow profile, the default profile in this case
// Same usage as profileRef in Kubernetes YAML
parent: defaultDataflowProfile
name: dataflowName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
mode: 'Enabled'
operations: [
{
operationType: 'Source'
sourceSettings: {
endpointRef: defaultDataflowEndpoint.name
assetRef: asset.name
dataSources: ['azure-iot-operations/data/${assetName}']
}
}
// Transformation optional
{
operationType: 'BuiltInTransformation'
builtInTransformationSettings: {
serializationFormat: serialFormat
schemaRef: 'aio-sr://${schemaNamespace}/${schema}:${schemaVersion}'
map: [
{
type: 'PassThrough'
inputs: [
'*'
]
output: '*'
}
]
}
}
{
operationType: 'Destination'
destinationSettings: {
endpointRef: adlsEndpoint.name
dataDestination: containerName
}
}
]
}
}
Salvare il file con adls-gen2-dataflow.bicep nome e distribuirlo usando l'interfaccia della riga di comando di Azure
az deployment group create -g <RESOURCE_GROUP> --template-file adls-gen2-dataflow.bicep
Verificare i dati in Azure Data Lake Storage Gen 2
Nell'account di archiviazione passare al pannello Contenitori e selezionare il contenitore aiotutorial creato. Verrà visualizzata una cartella denominata aiotutorial e al suo interno dovrebbero essere visualizzati file Parquet con i dati del server OPC UA. I nomi di file sono nel formato part-00001-44686130-347f-4c2c-81c8-eb891601ef98-c000.snappy.parquet.
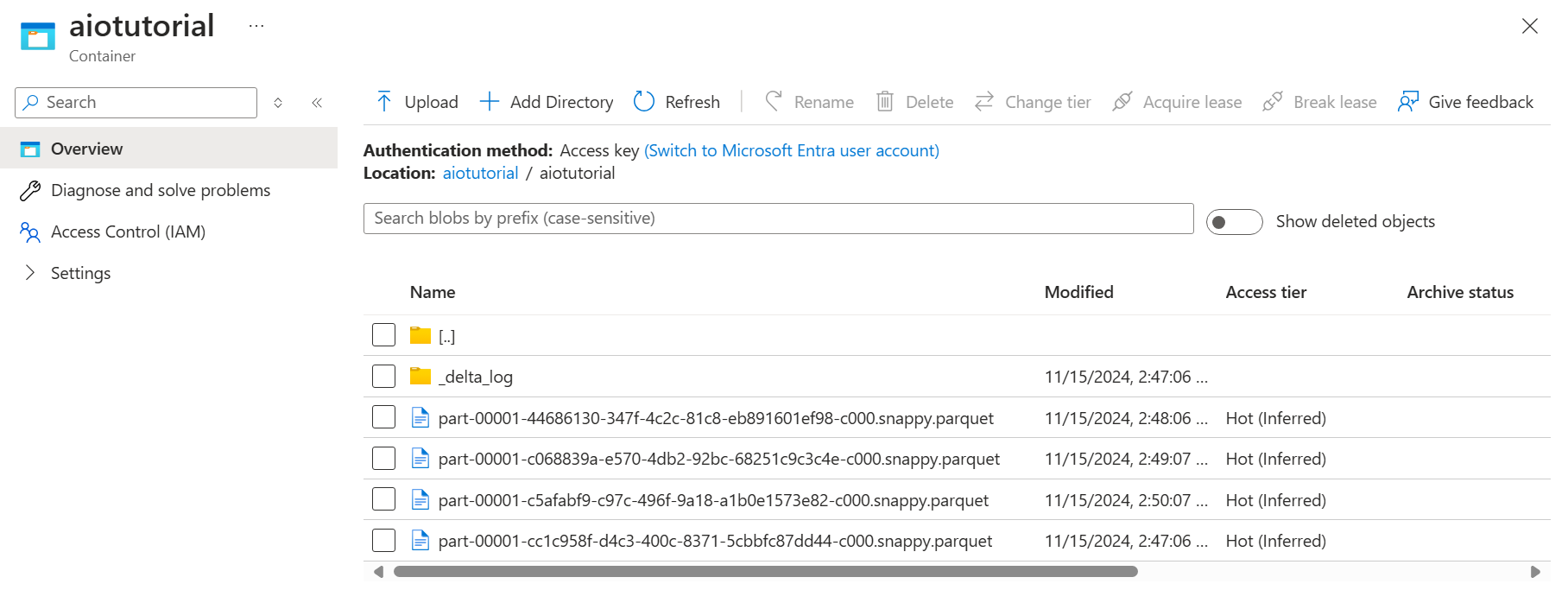
Per visualizzare il contenuto dei file, selezionare ogni file e selezionare Modifica.
Il rendering del contenuto non viene eseguito correttamente nella portale di Azure, ma è possibile scaricare il file e aprirlo in uno strumento come Parquet Viewer.